Os conetores personalizados permitem-lhe integrar origens de dados externas que não fazem parte da biblioteca de conetores padrão do Gemini Enterprise, tornando os dados únicos da sua organização pesquisáveis e acessíveis através de linguagem natural, com tecnologia do Gemini e da inteligência de pesquisa avançada da Google. O conetor personalizado interage diretamente com a API Discovery Engine, o que permite um armazenamento de dados robusto, indexação e capacidades de pesquisa inteligentes. O conetor converte as informações de origem no formato de documento baseado em JSON padronizado (estruturando o conteúdo, os metadados e as listas de controlo de acesso [ACLs]) e garante que estes dados são organizados em armazenamentos de dados. Estas lojas funcionam como repositórios lógicos, representando idealmente um único formato de documento, cada um com o seu próprio índice de pesquisa e configurações dedicados.
Como funcionam os conetores personalizados
Os conetores personalizados funcionam através de um pipeline de dados automatizado para realizar três ações principais: obter, transformar e sincronizar. Este processo garante que os dados externos são preparados e carregados corretamente para o Gemini Enterprise.
Obter: o conector extrai dados, incluindo documentos, metadados e autorizações, do sistema externo através das respetivas APIs, bases de dados ou formatos de ficheiros.
Transformação: o conector converte dados não processados no formato de documento do motor de descoberta, estrutura o conteúdo e os metadados e atribui um ID globalmente único a cada documento. Para controlos de acesso, pode usar diretamente identidades reconhecidas pela Google ou o mapeamento de identidades para utilizadores externos ou grupos personalizados.
Sincronização: o conetor carrega os documentos para os repositórios de dados do Gemini Enterprise e mantém-nos atualizados através de tarefas agendadas. A sincronização de dados é realizada através de um armazenamento de dados criado para uma entidade. Para mais informações sobre a criação de um arquivo de dados, consulte o Processo de criação do arquivo de dados. Escolha um modo de sincronização com base nas suas necessidades: o modo Incremental adiciona e atualiza dados, enquanto o modo Completo substitui o conjunto de dados completo.
LCAs e mapeamento da identidade
Para gerir o acesso ao nível do documento, escolha entre dois métodos: listas de controlo de acesso (ACLs) puras ou mapeamento de identidades, consoante o formato de identidade usado pelos dados.
LCAs puras (AclInfo): este método é usado quando a origem de dados usa identidades baseadas em email reconhecidas por (Google Cloud). Esta abordagem é ideal para definir diretamente quem tem acesso.
Mapeamento de identidades: este método é usado quando a origem de dados usa nomes de utilizador, IDs antigos ou outros sistemas de identidade externos. Estabelece uma associação clara e individual entre grupos de identidades externas (por exemplo, EXT1) e utilizadores ou grupos do fornecedor de identidade (IDP) interno (por exemplo, IDPUser1@example.com). Permite ao sistema compreender e aplicar controlos de acesso baseados em grupos a partir do sistema de origem, o que é útil quando uma API devolve etiquetas de grupos sem associações de utilizadores completas ou para dimensionar eficientemente as ACLs sem listar milhares de utilizadores por documento. O processo requer a resolução de todas as estruturas de identidade aninhadas ou hierárquicas numa lista simples de mapeamentos diretos, normalmente num formato JSON especificado. Use IDs de grupos de identidades externos únicos (por exemplo, EXT1) para identidades externas para manter a integridade do sistema. Para mais informações e exemplos, consulte o artigo Mapeamento de identidades.
Processo de criação do armazenamento de dados
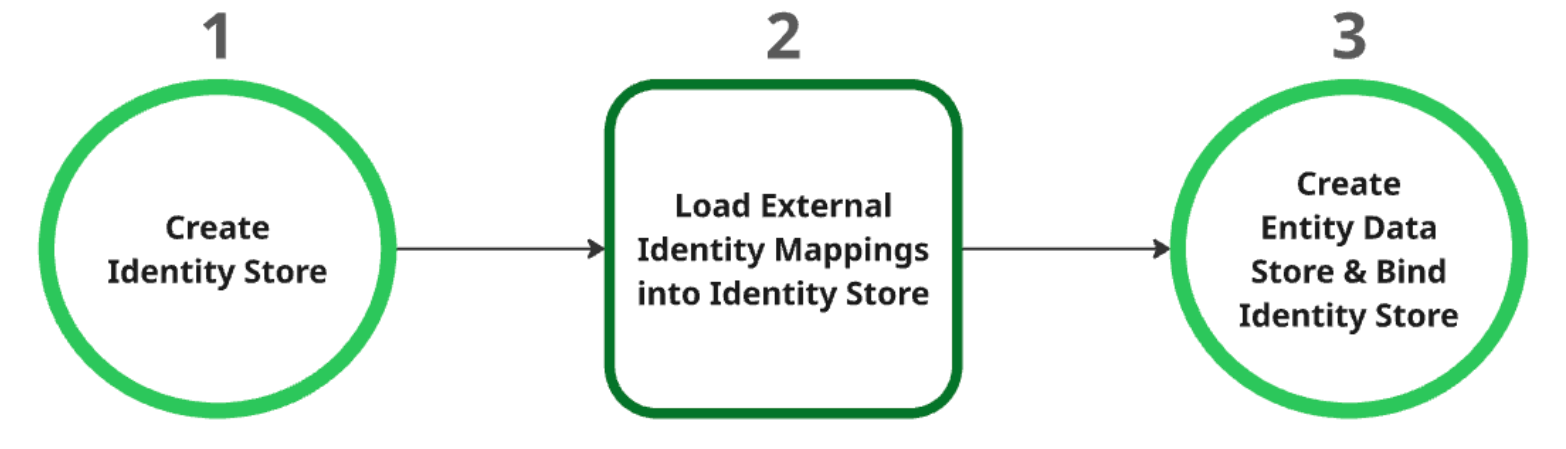
Crie o arquivo de identidades: este arquivo funciona como o recurso principal para todos os mapeamentos de identidade. Após a criação, as definições do Fornecedor de identidade (IDP) ao nível do projeto são obtidas automaticamente. Para mais informações, consulte o artigo Recupere ou crie um arquivo de identidades.
Carregue mapeamentos de identidade externos na loja de identidades: depois de criar a loja de identidades, carregue os dados de identidade externos na mesma. Para mais informações, consulte o artigo Carregue o mapeamento de identidades no arquivo de identidades.
Crie e associe o repositório de dados de entidades: o repositório de dados de entidades só pode ser criado depois de o repositório de identidades ser criado com êxito e os mapeamentos de identidades serem carregados. Tem de associar o arquivo de identidades ao arquivo de dados da entidade durante a respetiva criação. Para mais informações sobre como criar um arquivo de dados de entidades, consulte o artigo Crie um arquivo de dados.
Sincronização de dados
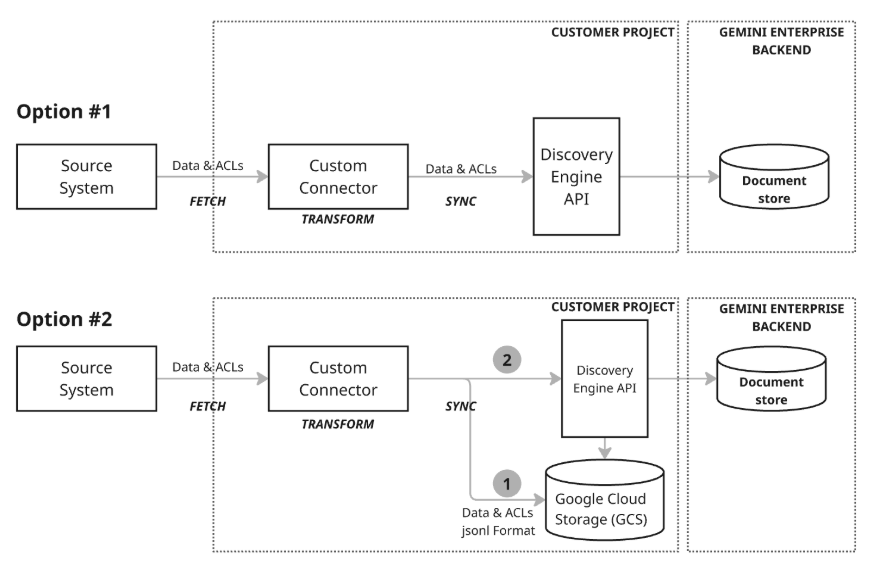
Existem dois modelos de arquitetura diferentes para sincronizar dados:
Modelo de arquitetura 1: inserção/atualização incremental: a abordagem de inserção/atualização incremental é mais adequada para cenários em que os dados estão a ser transmitidos e requerem atualizações em tempo real. O conetor tira partido da API Discovery Engine para realizar inserções/atualizações eficientes e incrementais (inserindo ou atualizando dados) chamando as funções adequadas com pequenas alterações à medida que ocorrem. Este foco em tamanhos de alterações mínimos e atrasos mínimos mantém o arquivo de documentos altamente atualizado, mesmo com dados que mudam rapidamente.
Modelo de arquitetura 2: sincronização abrangente com o Google Cloud Storage: esta abordagem recomendada oferece um conjunto abrangente de funcionalidades de gestão de dados e uma elevada flexibilidade. É compatível com sincronizações completas, que permitem a inserção, a atualização e a eliminação de dados em todo o conjunto de dados, e sincronizações incrementais, que processam apenas inserções e atualizações através do envio de alterações. Isto torna a abordagem robusta para uma vasta gama de necessidades de dados, particularmente para gerir operações de dados maiores ou mais complexas. Este modelo usa um processo de preparação (passo 1 no diagrama) em que o conetor escreve primeiro os dados no Google Cloud armazenamento (GCS) e, em seguida, tira partido da API Discovery Engine para atualizar a loja de documentos chamando as funções de importação necessárias a partir da localização do GCS preparada.
Os conetores personalizados são suficientemente flexíveis para suportar uma arquitetura híbrida, o que lhe permite implementar a inserção/atualização incremental para dados que mudam rapidamente e a sincronização abrangente para atualizações ou eliminações de dados completas agendadas.