

Esta página descreve como criar um conector personalizado.
Antes de começar
Antes de começar, certifique-se de que tem o seguinte:
Verifique se a faturação está ativada no seu Google Cloud projeto.
Instale e inicialize a Google Cloud CLI. Certifique-se de que está autenticado para o seu projeto.
Obtenha acesso de administrador do motor de descoberta para o seu Google Cloud projeto.
Obtenha credenciais de acesso para a sua origem de dados de terceiros (como chaves de API ou autenticação de base de dados).
Crie um plano de mapeamento de dados claro. Isto tem de incluir os campos a indexar e como representar o controlo de acesso, incluindo identidades de terceiros.
Crie um conetor básico
Esta secção demonstra a criação de um conetor personalizado no idioma escolhido. Os princípios e os padrões apresentados aqui aplicam-se a qualquer sistema externo. Basta adaptar as chamadas API e as transformações de dados para a sua origem específica no idioma escolhido para criar um conetor básico.
Obtenha dados
Para começar, obtenha dados da sua origem de dados de terceiros. Neste exemplo, demonstramos como obter publicações através da paginação. Para ambientes de produção, recomendamos a utilização de uma abordagem de streaming para grandes conjuntos de dados. Isto evita problemas de memória que podem ocorrer quando todos os dados são carregados de uma só vez.
Descanso
def fetch_posts(base_url: str, per_page: int = 15) -> List[dict]:
#Fetch all posts from the given site.#
url = base_url.rstrip("/") + "/wp-json/wp/v2/posts"
posts: List[dict] = []
page = 1
while True:
resp = requests.get(
url,
params={"page": page, "per_page": per_page},
)
resp.raise_for_status()
batch = resp.json()
posts.extend(batch)
if len(batch) < per_page:
break
page += 1
return posts
Transforme dados
Para converter os dados de origem no formato de documento do motor de descoberta, estruture-os conforme mostrado no payload de exemplo seguinte. Pode incluir tantos pares de chave-valor quantos os necessários. Por exemplo, pode incluir o conteúdo completo para uma pesquisa abrangente. Em alternativa, pode incluir campos estruturados para uma pesquisa detalhada ou uma combinação de ambos.
Descanso
def convert_posts_to_documents(posts: List[dict]) -> List[discoveryengine.Document]:
# Convert WP posts into Discovery Engine Document messages.
docs: List[discoveryengine.Document] = []
for post in posts:
payload = {
"title": post.get("title", {}).get("rendered"),
"body": post.get("content", {}).get("rendered"),
"url": post.get("link"),
"author": post.get("author"),
"categories": post.get("categories"),
"tags": post.get("tags"),
"date": post.get("date"),
}
doc = discoveryengine.Document(
id=str(post["id"]),
json_data=json.dumps(payload),
)
docs.append(doc)
return docs
Recupere ou crie um repositório de identidades
Para gerir identidades de utilizadores e grupos para controlo de acesso, tem de obter ou criar um repositório de identidades. Esta função obtém um arquivo de identidades existente pelo respetivo ID, projeto e localização. Se o arquivo de identidades não existir, cria e devolve um novo arquivo de identidades vazio.
Descanso
def get_or_create_ims_data_store(
project_id: str,
location: str,
identity_mapping_store_id: str,
) -> discoveryengine.DataStore:
"""Get or create a DataStore."""
# Initialize the client
client_ims = discoveryengine.IdentityMappingStoreServiceClient()
# Construct the parent resource name
parent_ims = client_ims.location_path(project=project_id, location=location)
try:
# Create the request object
name = f"projects/{project_id}/locations/{location}/identityMappingStores/{identity_mapping_store_id}"
request = discoveryengine.GetIdentityMappingStoreRequest(
name=name,
)
return client_ims.get_identity_mapping_store(request=request)
except:
# Create the IdentityMappingStore object (it can be empty for basic creation)
identity_mapping_store = discoveryengine.IdentityMappingStore()
# Create the request object
request = discoveryengine.CreateIdentityMappingStoreRequest(
parent=parent_ims,
identity_mapping_store=identity_mapping_store,
identity_mapping_store_id=identity_mapping_store_id,
)
return client_ims.create_identity_mapping_store(request=request)
A função get_or_create_ims_data_store usa as seguintes variáveis principais:
project_id: o ID do seu projeto Google Cloud .location: a Google Cloud localização do armazenamento do mapeamento de identidades.identity_mapping_store_id: um identificador exclusivo da loja de identidades.client_ims: uma instância de discoveryengine.IdentityMappingStoreServiceClient usada para interagir com a API Identity Store.parent_ims: o nome do recurso da localização principal, construído com client_ims.location_path.name: o nome completo do recurso do armazenamento de mapeamento de identidades, usado para GetIdentityMappingStoreRequest.
Carregue o mapeamento da identidade no arquivo de identidades
Para carregar entradas de mapeamento da identidade na loja de identidades especificada, use esta função. Aceita uma lista de entradas de mapeamento de identidades e inicia uma operação de importação inline. Isto é fundamental para estabelecer as relações de utilizadores, grupos e identidades externas necessárias para o controlo de acesso e a personalização.
Descanso
def load_ims_data(
ims_store: discoveryengine.DataStore,
id_mapping_data: list[discoveryengine.IdentityMappingEntry],
) -> discoveryengine.DataStore:
"""Get the IMS data store."""
# Initialize the client
client_ims = discoveryengine.IdentityMappingStoreServiceClient()
# Create the InlineSource object
inline_source = discoveryengine.ImportIdentityMappingsRequest.InlineSource(
identity_mapping_entries=id_mapping_data
)
# Create the main request object
request_ims = discoveryengine.ImportIdentityMappingsRequest(
identity_mapping_store=ims_store.name,
inline_source=inline_source,
)
try:
# Create the InlineSource object, which holds your list of entries
operation = client_ims.import_identity_mappings(
request=request_ims,
)
result = operation.result()
return result
except Exception as e:
print(f"IMS Load Error: {e}")
result = operation.result()
return result
A função load_ims_data usa as seguintes variáveis principais:
ims_store: o objeto discoveryengine.DataStore que representa o armazenamento de mapeamento de identidade onde os dados vão ser carregados.id_mapping_data: uma lista de objetos discoveryengine.IdentityMappingEntry, cada um contendo uma identidade externa e o respetivo ID de utilizador ou grupo.result: valor de retorno do tipo discoveryengine.DataStore.
Crie um armazenamento de dados
Para usar um conector personalizado, tem de inicializar um repositório de dados para o seu conteúdo. Use o default_collection para conectores personalizados. O parâmetro IndustryVertical personaliza o comportamento do armazenamento de dados para exemplos de utilização específicos. GENERIC é adequado para a maioria dos cenários. No entanto, pode escolher um valor diferente para uma indústria específica, como MEDIA ou HEALTHCARE_FHIR. Configure o nome a apresentar e outras propriedades para se alinharem com as convenções de nomenclatura e os requisitos do seu projeto.
Descanso
def get_or_create_data_store(
project_id: str,
location: str,
display_name: str,
data_store_id: str,
identity_mapping_store: str,
) -> discoveryengine.DataStore:
"""Get or create a DataStore."""
client = discoveryengine.DataStoreServiceClient()
ds_name = client.data_store_path(project_id, location, data_store_id)
try:
result = client.get_data_store(request={"name": ds_name})
return result
except:
parent = client.collection_path(project_id, location, "default_collection")
operation = client.create_data_store(
request={
"parent": parent,
"data_store": discoveryengine.DataStore(
display_name=display_name,
acl_enabled=True,
industry_vertical=discoveryengine.IndustryVertical.GENERIC,
identity_mapping_store=identity_mapping_store,
),
"data_store_id": data_store_id,
}
)
result = operation.result()
return result
A função get_or_create_data_store usa as seguintes variáveis principais:
project_id: o ID do seu projeto Google Cloud .location: a Google Cloud localização da loja de dados.display_name: o nome a apresentar legível por humanos da loja de dados.data_store_id: um identificador exclusivo para o armazenamento de dados.identity_mapping_store: o nome do recurso da loja de mapeamento de identidades a associar.result: valor de retorno do tipo discoveryengine.DataStore.
Carregue documentos inline
Para enviar documentos diretamente para o motor de descoberta, use o carregamento inline. Este método usa o modo de conciliação incremental por predefinição e não suporta o modo de conciliação total. No modo incremental, são adicionados novos documentos e os existentes são atualizados, mas os documentos que já não estão na origem não são eliminados. O modo de conciliação total sincroniza o repositório de dados com os dados de origem, incluindo a eliminação de documentos que já não estão presentes na origem.
A conciliação incremental é ideal para sistemas como um CRM que processam alterações pequenas e frequentes aos dados. Em vez de sincronizar toda a base de dados, envie apenas alterações específicas, o que torna o processo mais rápido e eficiente.
Como prática recomendada, faça uma sincronização completa inicial, seguida de sincronizações incrementais mais frequentes.
Descanso
def upload_documents_inline(
project_id: str,
location: str,
data_store_id: str,
branch_id: str,
documents: List[discoveryengine.Document],
) -> discoveryengine.ImportDocumentsMetadata:
"""Inline import of Document messages."""
client = discoveryengine.DocumentServiceClient()
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch=branch_id,
)
request = discoveryengine.ImportDocumentsRequest(
parent=parent,
inline_source=discoveryengine.ImportDocumentsRequest.InlineSource(
documents=documents,
),
)
operation = client.import_documents(request=request)
operation.result()
result = operation.metadata
return result
A função upload_documents_inline usa as seguintes variáveis principais:
project_id: o ID do seu projeto Google Cloud .location: a Google Cloud localização da loja de dados.data_store_id: o ID do armazenamento de dados.branch_id: o ID da ramificação no arquivo de dados (normalmente "0").documents: uma lista de objetos discoveryengine.Document a carregar.result: valor de retorno do tipo discoveryengine.ImportDocumentsMetadata.
O campo uri no objeto discoveryengine.Document é usado para apontar para a própria origem do conteúdo carregado, como bytes não processados ou um URI no Google Cloud Storage. Isto é diferente do URI do conteúdo de origem de terceiros. O URI do conteúdo de origem de terceiros deve ser definido como um campo na carga útil json_data do documento. Por exemplo, na função convert_posts_to_documents, o campo url na carga útil serve este propósito.
Valide o conector
Para validar se o conector está a funcionar conforme esperado, execute um teste para garantir o fluxo de dados adequado da origem para o Discovery Engine.
Descanso
SITE = "https://altostrat.com"
PROJECT_ID = "ucs-3p-connectors-testing"
LOCATION = "global"
IDENTITY_MAPPING_STORE_ID = "your-unique-ims-id17" # A unique ID for your new store
DATA_STORE_ID = "my-acl-ds-id1"
BRANCH_ID = "0"
posts = fetch_posts(SITE)
docs = convert_posts_to_documents(posts)
print(f"Fetched {len(posts)} posts and converted to {len(docs)} documents.")
try:
# Step #1: Retrieve an existing identity mapping store or create a new identity mapping store
ims_store = get_or_create_ims_data_store(PROJECT_ID, LOCATION, IDENTITY_MAPPING_STORE_ID)
print(f"STEP #1: IMS Store Retrieval/Creation: {ims_store}")
RAW_IDENTITY_MAPPING_DATA = [
discoveryengine.IdentityMappingEntry(
external_identity="external_id_1",
user_id="testuser1@example.com",
),
discoveryengine.IdentityMappingEntry(
external_identity="external_id_2",
user_id="testuser2@example.com",
),
discoveryengine.IdentityMappingEntry(
external_identity="external_id_2",
group_id="testgroup1@example.com",
)
]
# Step #2: Load IMS Data
response = load_ims_data(ims_store, RAW_IDENTITY_MAPPING_DATA)
print(
"\nStep #2: Load Data in IMS Store successful.", response
)
# Step #3: Create Entity Data Store & Bind IMS Data Store
data_store = get_or_create_data_store(PROJECT_ID, LOCATION, "my-acl-datastore", DATA_STORE_ID, ims_store.name)
print("\nStep #3: Entity Data Store Create Result: ", data_store)
metadata = upload_documents_inline(
PROJECT_ID, LOCATION, DATA_STORE_ID, BRANCH_ID, docs
)
print(f"Uploaded {metadata.success_count} documents inline.")
except gcp_exceptions.GoogleAPICallError as e:
print(f"\n--- API Call Failed ---")
print(f"Server Error Message: {e.message}")
print(f"Status Code: {e.code}")
except Exception as e:
print(f"An error occurred: {e}")
Valide se o código do conetor usa as seguintes variáveis principais:
SITE: o URL de base da origem de dados de terceiros.PROJECT_ID: o ID do seu Google Cloud projeto.LOCATION: A Google Cloud localização dos recursos.IDENTITY_MAPPING_STORE_ID: um ID exclusivo para a sua loja de mapeamento da identidade.DATA_STORE_ID: um ID exclusivo para o seu armazenamento de dados.BRANCH_ID: o ID da ramificação no armazenamento de dados.posts: armazena as publicações obtidas da origem de terceiros.docs: armazena os documentos convertidos no formato discoveryengine.Document.ims_store: o objeto discoveryengine.DataStore obtido ou criado para o mapeamento de identidades.RAW_IDENTITY_MAPPING_DATA: uma lista de objetos discoveryengine.IdentityMappingEntry.
Resultado esperado:
Shell
Fetched 20 posts and converted to 20 documents.
STEP #1: IMS Store Retrieval/Creation: "projects/ <Project Number>/locations/global/identityMappingStores/your-unique-ims-id17"
Step #2: Load Data in IMS Store successful.
Step #3: Entity Data Store Create Result: "projects/ <Project Number>/locations/global/collections/default_collection/dataStores/my-acl-ds-id1"
display_name: "my-acl-datastore"
industry_vertical: GENERIC
create_time {
seconds: 1760906997
nanos: 192641000
}
default_schema_id: "default_schema"
acl_enabled: true
identity_mapping_store: "projects/ <Project Number>/locations/global/identityMappingStores/your-unique-ims-id17".
Uploaded 20 documents inline.
Neste ponto, também pode ver o seu repositório de dados na consola Google Cloud Google:
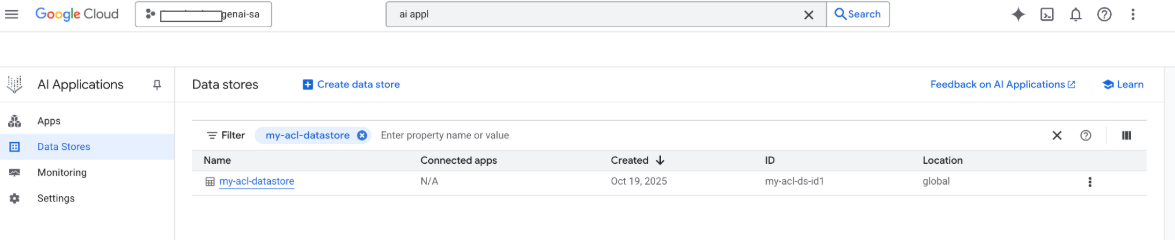
Quando é realizada uma pesquisa, os campos do payload são usados para a pesquisa e o campo URI do payload é usado para citações. Os três campos de propriedades principais que o Gemini Enterprise identifica são title, description e uri. Os campos de documentos correspondentes podem ter nomes diferentes e o respetivo mapeamento pode ser feito através da opção Esquema -> Editar na Google Cloud consola.
Crie um conetor com o Google Cloud carregamento de armazenamento
Embora a importação inline funcione bem para o desenvolvimento, os conetores de produção devem usar o Google Cloud armazenamento para uma melhor escalabilidade e para ativar o modo de conciliação total. Esta abordagem processa grandes conjuntos de dados de forma eficiente e suporta a eliminação automática de documentos que já não estão presentes na origem de dados de terceiros.
Converta documentos em JSONL
Para preparar documentos para a importação em massa para o Discovery Engine, converta-os para o formato JSON Lines.
Descanso
def convert_documents_to_jsonl(
documents: List[discoveryengine.Document],
) -> str:
"""Serialize Document messages to JSONL."""
return "\n".join(
discoveryengine.Document.to_json(doc, indent=None)
for doc in documents
) + "\n"
A função convert_documents_to_jsonl usa a seguinte variável:
documents: Uma lista de objetos discoveryengine.Document a serem convertidos.
Carregue para o Google Cloud Storage
Para ativar a importação em massa eficiente, organize os seus dados no Google Cloud armazenamento.
Descanso
def upload_jsonl_to_gcs(jsonl: str, bucket_name: str, blob_name: str) -> str:
"""Upload JSONL content to Google Cloud Storage."""
client = storage.Client()
bucket = client.bucket(bucket_name)
blob = bucket.blob(blob_name)
blob.upload_from_string(jsonl, content_type="application/json")
return f"gs://{bucket_name}/{blob_name}"
A função upload_jsonl_to_gcs usa as seguintes variáveis principais:
jsonl: o conteúdo da string formatada em JSONL a carregar.bucket_name: o nome do Google Cloud contentor de armazenamento.blob_name: o nome do blob (objeto) no contentor especificado.
Importação do Google Cloud Storage com conciliação completa
Para fazer uma sincronização de dados completa através do modo de conciliação total, use este método. Isto garante que o seu repositório de dados reflete exatamente a origem de dados de terceiros, removendo automaticamente todos os documentos que já não existam.
Quando importar do Google Cloud Storage, tenha em atenção as seguintes limitações:
- Um único pedido de importação pode conter, no máximo,100 ficheiros ou 100 000 ficheiros se o parâmetro
dataSchemaestiver definido comocontent. Cada ficheiro pode ter até 2 GB ou 100 MB se o parâmetro
dataSchemaestiver definido comocontent.
Descanso
def import_documents_from_gcs(
project_id: str,
location: str,
data_store_id: str,
branch_id: str,
gcs_uri: str,
) -> discoveryengine.ImportDocumentsMetadata:
"""Bulk-import documents from Google Cloud Storage with FULL reconciliation mode."""
client = discoveryengine.DocumentServiceClient()
parent = client.branch_path(
project=project_id,
location=location,
data_store=data_store_id,
branch=branch_id,
)
gcs_source = discoveryengine.GcsSource(input_uris=[gcs_uri])
request = discoveryengine.ImportDocumentsRequest(
parent=parent,
gcs_source=gcs_source,
reconciliation_mode=
discoveryengine.ImportDocumentsRequest
.ReconciliationMode.FULL,
)
operation = client.import_documents(request=request)
operation.result()
return operation.metadata
A função import_documents_from_gcs usa as seguintes variáveis de chave:
project_id: o ID do seu projeto Google Cloud .location: a Google Cloud localização da loja de dados.data_store_id: o ID do armazenamento de dados.branch_id: o ID da ramificação no arquivo de dados (normalmente "0").gcs_uri: o Google Cloud URI de armazenamento que aponta para o ficheiro JSONL.
Teste o carregamento Google Cloud para o armazenamento
Para validar o Google Cloud fluxo de trabalho de importação baseado no armazenamento, execute o seguinte:
Descanso
BUCKET = "your-existing-bucket"
BLOB = "path-to-any-blob/wp/posts.jsonl"
SITE = "https://altostrat.com"
PROJECT_ID = "ucs-3p-connectors-testing"
LOCATION = "global"
IDENTITY_MAPPING_STORE_ID = "your-unique-ims-id17" # A unique ID for your new store
DATA_STORE_ID = "your-data-store-id"
BRANCH_ID = "0"
jsonl_payload = convert_documents_to_jsonl(docs)
gcs_uri = upload_jsonl_to_gcs(jsonl_payload, BUCKET, BLOB)
posts = fetch_posts(SITE)
docs = convert_posts_to_documents(posts)
print(f"Fetched {len(posts)} posts and converted to {len(docs)} documents.")
print("Uploaded to:", gcs_uri)
metadata = import_documents_from_gcs(
PROJECT_ID, LOCATION, DATA_STORE_ID, BRANCH_ID, gcs_uri
)
print(f"Imported: {metadata.success_count} documents")
As seguintes variáveis principais são usadas nos testes do Google Cloud carregamento de armazenamento:
BUCKET: o nome do Google Cloud contentor de armazenamento.BLOB: o caminho para o objeto binário grande dentro do contentor.SITE: o URL de base da origem de dados de terceiros.PROJECT_ID: o ID do seu Google Cloud projeto.LOCATION: A Google Cloud localização dos recursos (por exemplo, "global").IDENTITY_MAPPING_STORE_ID: um ID exclusivo para a sua loja de mapeamento da identidade.DATA_STORE_ID: um ID exclusivo para o seu armazenamento de dados.BRANCH_ID: o ID da ramificação no arquivo de dados (normalmente "0").jsonl_payload: os documentos convertidos para o formato JSONL.gcs_uri: o Google Cloud URI de armazenamento do ficheiro JSONL carregado.
Resultado esperado:
Shell
Fetched 20 posts and converted to 20 documents.
Uploaded to: gs://alex-de-bucket/wp/posts.jsonl
Imported: 20 documents
Gerir autorizações
Para gerir o acesso ao nível do documento em ambientes empresariais, o Gemini Enterprise suporta listas de controlo de acesso (ACLs) e mapeamento de identidades, o que ajuda a limitar o conteúdo que os utilizadores podem ver.
Ative as ACLs no arquivo de dados
Para ativar as ACLs quando criar o seu repositório de dados, execute o seguinte:
Descanso
# get_or_create_data_store()
"data_store": discoveryengine.DataStore(
display_name=data_store_id,
industry_vertical=discoveryengine.IndustryVertical.GENERIC,
acl_enabled=True, # ADDED
)
Adicione LCAs a documentos
Para calcular e incluir AclInfo ao transformar os documentos, execute o seguinte:
Descanso
# convert_posts_to_documents()
doc = discoveryengine.Document(
id=str(post["id"]),
json_data=json.dumps(payload),
acl_info=discoveryengine.Document.AclInfo(
readers=[{
"principals": [
{"user_id": "baklavainthebalkans@gmail.com"},
{"user_id": "cloudysanfrancisco@gmail.com"}
]
}]
),
)
Tornar o conteúdo público
Para tornar um documento acessível publicamente, defina o campo readers da seguinte forma:
Descanso
readers=[{"idp_wide": True}]
Valide as LCAs
Para validar se as configurações da LCA estão a funcionar como esperado, considere o seguinte:
Pesquise como um utilizador que não tem acesso ao documento.
Inspecione a estrutura do documento carregado no Cloud Storage e compare-a com uma referência.
JSON
{
"id": "108",
"jsonData": "{...}",
"aclInfo": {
"readers": [
{
"principals": [
{ "userId": "baklavainthebalkans@gmail.com" },
{ "userId": "cloudysanfrancisco@gmail.com" }
],
"idpWide": false
}
]
}
}
Use o mapeamento da identidade
Use o mapeamento de identidades para os seguintes cenários:
A sua origem de dados de terceiros usa identidades não pertencentes à Google
Quer fazer referência a grupos personalizados (por exemplo, wp-admins) em vez de utilizadores individuais
A sua API devolve apenas nomes de grupos
Tem de agrupar manualmente os utilizadores para obter escala ou consistência
O seu sistema de terceiros implementa LCAs através de grupos não baseados em IDPs e quer respeitar essas LCAs através do arquivo de dados personalizado no Gemini Enterprise.
Para realizar o mapeamento de identidades, siga estes passos:
- Crie e associe o arquivo de dados de identidade.
Importe identidades externas (por exemplo, external_group:wp-admins). Não inclua o prefixo external_group: quando importar, por exemplo:
JSON
{ "externalIdentity": "wp-admins", "userId": "user@example.com" }Nas informações da ACL do seu documento, defina o ID da entidade externa em
principal identifier. Quando fizer referência a grupos personalizados, use o prefixoexternal_group:no campogroupId.O prefixo
external_group:é necessário para os IDs de grupos nas informações da ACL do documento durante a importação, mas não é usado quando importa identidades para a loja de mapeamentos. Exemplo de documento com mapeamento da identidade:JSON
{ "id": "108", "aclInfo": { "readers": [ { "principals": [ { "userId": "cloudysanfrancisco@gmail.com" }, { "groupId": "external_group:wp-admins" } ] } ] }, "structData": { "id": 108, "date": "2025-04-24T18:16:04", ... } }
O que se segue?
- Para fornecer uma interface do utilizador para consultar os seus dados, crie uma app no Gemini Enterprise e associe-a ao arquivo de dados do conector personalizado existente.