I connettori personalizzati ti consentono di integrare origini dati esterne che non rientrano nella libreria di connettori standard di Gemini Enterprise, rendendo i dati unici della tua organizzazione ricercabili e accessibili utilizzando il linguaggio naturale, grazie a Gemini e alla tecnologia di ricerca avanzata di Google. Il connettore personalizzato interagisce direttamente con l'API Discovery Engine, che consente funzionalità di archiviazione, indicizzazione e ricerca intelligenti e solide. Il connettore converte le informazioni di origine nel formato del documento standardizzato basato su JSON (strutturando i contenuti, i metadati e le liste di controllo degli accessi (ACL)) e garantisce che questi dati siano organizzati in data store. Questi archivi fungono da repository logici, idealmente rappresentando un singolo formato di documento, ciascuno con il proprio indice di ricerca e le proprie configurazioni dedicati.
Come funzionano i connettori personalizzati
I connettori personalizzati funzionano utilizzando una pipeline di dati automatizzata per eseguire tre azioni chiave: recupero, trasformazione e sincronizzazione. Questo processo garantisce che i dati esterni vengano preparati e caricati correttamente in Gemini Enterprise.
Recupero: il connettore estrae i dati, inclusi documenti, metadati e autorizzazioni, dal sistema esterno utilizzando le relative API, i database o i formati di file.
Trasformazione: il connettore converte i dati non elaborati nel formato del documento di Discovery Engine, struttura i contenuti e i metadati e assegna un ID univoco globale a ogni documento. Per i controlli dell'accesso, puoi utilizzare direttamente le identità riconosciute da Google o la mappatura delle identità per utenti esterni o gruppi personalizzati.
Sincronizzazione: il connettore carica i documenti nei datastore di Gemini Enterprise e li mantiene aggiornati tramite job pianificati. La sincronizzazione dei dati viene eseguita utilizzando un datastore creato per un'entità. Per saperne di più sulla creazione di datastore, consulta Procedura di creazione del datastore. Scegli una modalità di sincronizzazione in base alle tue esigenze: Incrementale aggiunge e aggiorna i dati, mentre Completa sostituisce l'intero set di dati.
ACL e mappatura delle identità
Per gestire l'accesso a livello di documento, scegli tra due metodi: ACL pure o mappatura delle identità, a seconda del formato dell'identità utilizzato dai dati.
ACL pure (AclInfo): questo metodo viene utilizzato quando l'origine dati utilizza identità basate su indirizzi email riconosciute da (Google Cloud). Questo approccio è ideale per definire direttamente chi ha accesso.
Mappatura delle identità: questo metodo viene utilizzato quando l'origine dati utilizza nomi utente, ID legacy o altri sistemi di identità esterni:
Stabilisce un'associazione chiara e univoca tra i gruppi di identità esterni (ad es. EXT1) e utenti o gruppi del provider di identità (IdP) interno (ad es.
IDPUser1@example.com).Consente al sistema di comprendere e applicare i controlli di accesso basati sui gruppi dal sistema di origine, il che è utile quando un' API restituisce etichette di gruppo senza appartenenze complete degli utenti o per scalare in modo efficiente le ACL senza elencare migliaia di utenti per documento.
Il processo di mappatura delle identità richiede la risoluzione di tutte le strutture di identità nidificate o gerarchiche in un elenco piatto di mappature dirette, in genere in un formato JSON specificato.
Utilizza ID gruppo di identità esterne univoci (ad es. EXT1) per le identità esterne per mantenere l'integrità del sistema. Per ulteriori informazioni ed esempi, vedi Mappare identità esterne.
Procedura di creazione del datastore
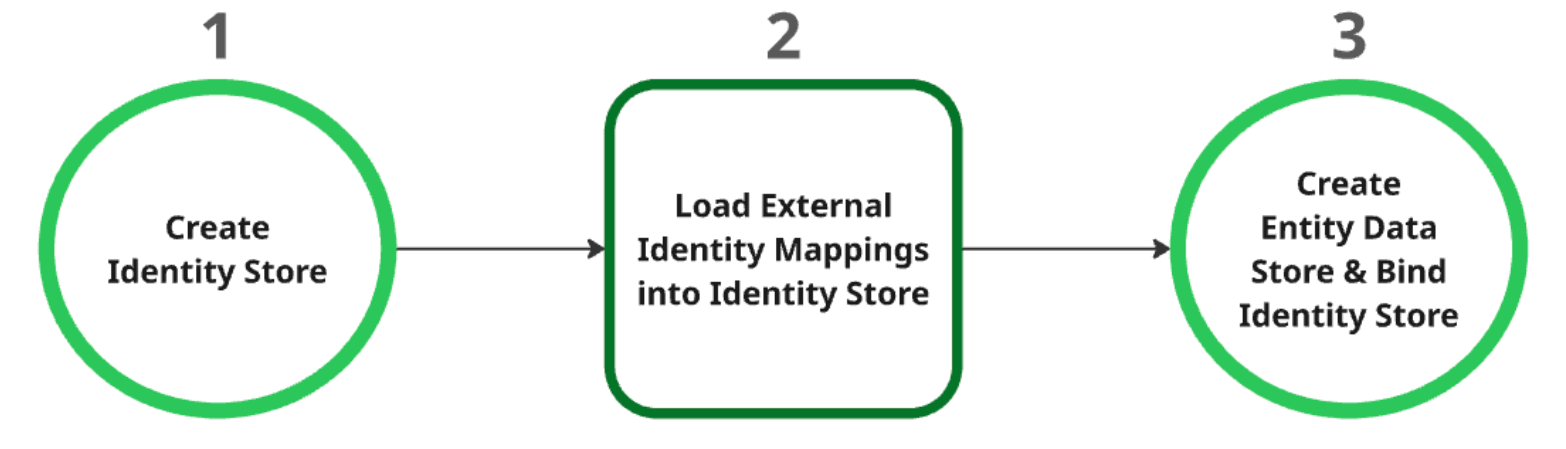
Crea l'archivio delle identità:questo archivio funge da risorsa principale per tutte le mappature delle identità. Al momento della creazione, le impostazioni del provider di identità (IDP) a livello di progetto vengono recuperate automaticamente. Per saperne di più, consulta Recuperare o creare un archivio identità.
Carica le mappature delle identità esterne nell'archivio delle identità:dopo aver creato l'archivio delle identità, carica i dati delle identità esterne. Per maggiori informazioni, consulta Importare la mappatura delle identità nell'archivio delle identità.
Crea e associa il datastore delle entità:il datastore delle entità può essere creato solo dopo la creazione corretta dell'identity store e il caricamento dei mapping delle identità. Devi associare l'identity store al datastore delle entità durante la creazione. Per saperne di più sulla creazione di un datastore di entità, consulta Creare datastore.
Sincronizzazione dati
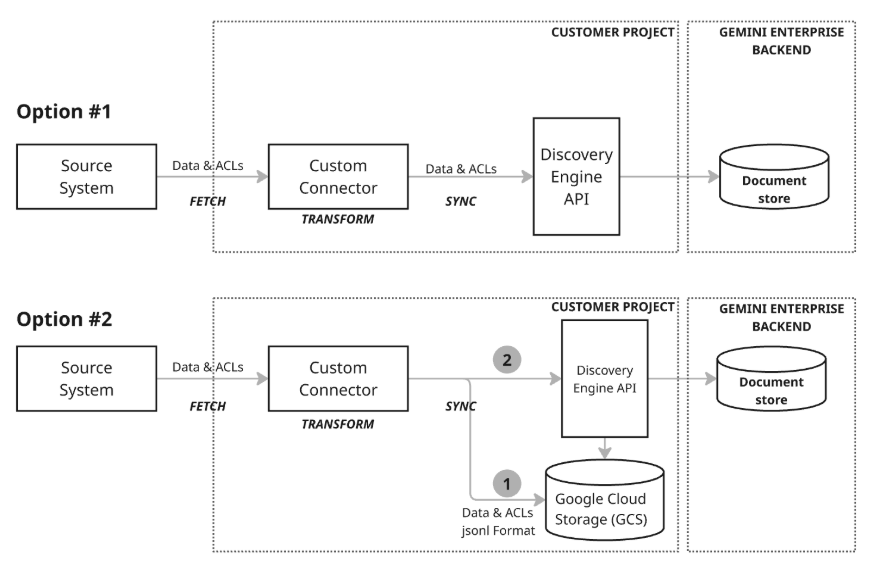
Esistono due diversi modelli di architettura per la sincronizzazione dei dati:
Modello di architettura 1: upsert incrementale:l'approccio upsert incrementale è più adatto a scenari in cui i dati vengono trasmessi in streaming e richiedono aggiornamenti in tempo reale. Il connettore utilizza l'API Discovery Engine per eseguire upsert incrementali efficienti (inserimento o aggiornamento dei dati) chiamando le funzioni appropriate con piccole modifiche man mano che si verificano. Questo approccio basato su dimensioni minime delle modifiche e ritardi minimi mantiene l'archivio documenti sempre aggiornato, anche con dati in rapido cambiamento.
Modello di architettura 2: sincronizzazione completa con Google Cloud Storage:questo approccio consigliato offre un insieme completo di funzionalità di gestione dei dati e un'elevata flessibilità. Supporta le sincronizzazioni complete, che consentono l'inserimento, l'aggiornamento e l'eliminazione dei dati nell'intero set di dati, e le sincronizzazioni incrementali, che gestiscono solo gli inserimenti e gli aggiornamenti inviando le modifiche. Ciò rende l'approccio solido per un'ampia gamma di esigenze di dati, in particolare per la gestione di operazioni sui dati più grandi o più complesse. Questo modello utilizza un processo di gestione temporanea (passaggio 1 nel diagramma) in cui il connettore scrive prima i dati in Google Cloud Storage (GCS), quindi utilizza l'API Discovery Engine per aggiornare l'archivio documenti chiamando le funzioni di importazione necessarie dalla posizione GCS temporanea.
I connettori personalizzati sono sufficientemente flessibili da supportare un'architettura ibrida, consentendoti di implementare l'upsert incrementale per i dati in rapida evoluzione e la sincronizzazione completa per aggiornamenti o eliminazioni programmati dei dati completi.