Konektor kustom memungkinkan Anda mengintegrasikan sumber data eksternal yang tidak termasuk dalam library konektor standar Gemini Enterprise, sehingga data unik organisasi Anda dapat ditelusuri dan diakses menggunakan bahasa alami, yang didukung oleh Gemini dan teknologi penelusuran canggih Google. Konektor kustom berinteraksi langsung dengan Discovery Engine API, yang memungkinkan kemampuan penyimpanan data, pengindeksan, dan penelusuran cerdas yang andal. Konektor mengonversi informasi sumber ke dalam format Dokumen berbasis JSON standar (menyusun konten, metadata, dan Daftar Kontrol Akses (ACL)) serta memastikan data ini disusun ke dalam Penyimpanan data. Penyimpanan ini berfungsi sebagai repositori logis, yang idealnya merepresentasikan satu format dokumen, masing-masing dengan indeks penelusuran dan konfigurasi khusus.
Cara kerja konektor kustom
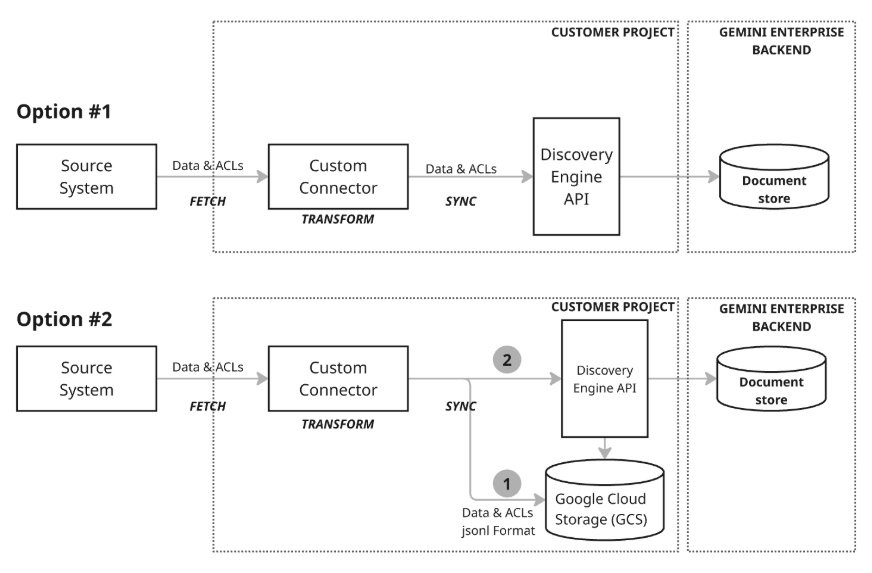
Konektor kustom berfungsi dengan menggunakan pipeline data otomatis untuk melakukan tiga tindakan utama: Ambil, Transformasi, dan Sinkronkan. Proses ini memastikan data eksternal disiapkan dan diupload dengan benar ke Gemini Enterprise.
Pengambilan: Konektor menarik data, termasuk dokumen, metadata, dan izin, dari sistem eksternal menggunakan API, database, atau format filenya.
Transformasi: Konektor mengonversi data mentah menjadi format dokumen Discovery Engine, menyusun konten dan metadata, serta menetapkan ID unik secara global ke setiap dokumen. Untuk kontrol akses, Anda dapat menggunakan identitas yang dikenali Google secara langsung atau pemetaan identitas untuk pengguna eksternal atau grup kustom.
Sinkronkan: Konektor mengupload dokumen ke penyimpanan data Gemini Enterprise dan terus memperbaruinya melalui tugas terjadwal. Sinkronisasi data dilakukan menggunakan penyimpanan data yang dibuat untuk entity. Untuk mengetahui informasi selengkapnya tentang cara membuat penyimpanan data, lihat Proses pembuatan penyimpanan data. Pilih mode sinkronisasi berdasarkan kebutuhan Anda: Inkremental menambahkan dan memperbarui data, sedangkan Penuh menggantikan seluruh set data.
ACL dan Pemetaan identitas
Untuk mengelola akses tingkat dokumen, pilih antara dua metode — ACL Murni atau Pemetaan Identitas, bergantung pada format identitas yang digunakan oleh data.
ACL murni (AclInfo): Metode ini digunakan saat sumber data menggunakan identitas berbasis email yang dikenali oleh (Google Cloud). Pendekatan ini ideal untuk menentukan secara langsung siapa yang memiliki akses.
Pemetaan identitas: Metode ini digunakan saat sumber data menggunakan nama pengguna, ID lama, atau sistem identitas eksternal lainnya:
Tindakan ini menetapkan hubungan satu-ke-satu yang jelas antara grup identitas eksternal (misalnya, EXT1) dan pengguna atau grup Penyedia Identitas (IDP) internal (misalnya,
IDPUser1@example.com).Hal ini memungkinkan sistem memahami dan menerapkan kontrol akses berbasis grup dari sistem sumber, yang berguna saat API menampilkan label grup tanpa keanggotaan pengguna penuh atau untuk menskalakan ACL secara efisien tanpa mencantumkan ribuan pengguna per dokumen.
Proses pemetaan identitas memerlukan penyelesaian semua struktur identitas bertingkat atau hierarkis menjadi daftar datar pemetaan langsung, biasanya dalam format JSON yang ditentukan.
Gunakan ID grup identitas eksternal yang unik (misalnya, EXT1) untuk identitas eksternal guna menjaga integritas sistem. Untuk mengetahui informasi dan contoh selengkapnya, lihat Memetakan identitas eksternal.
Proses pembuatan penyimpanan data
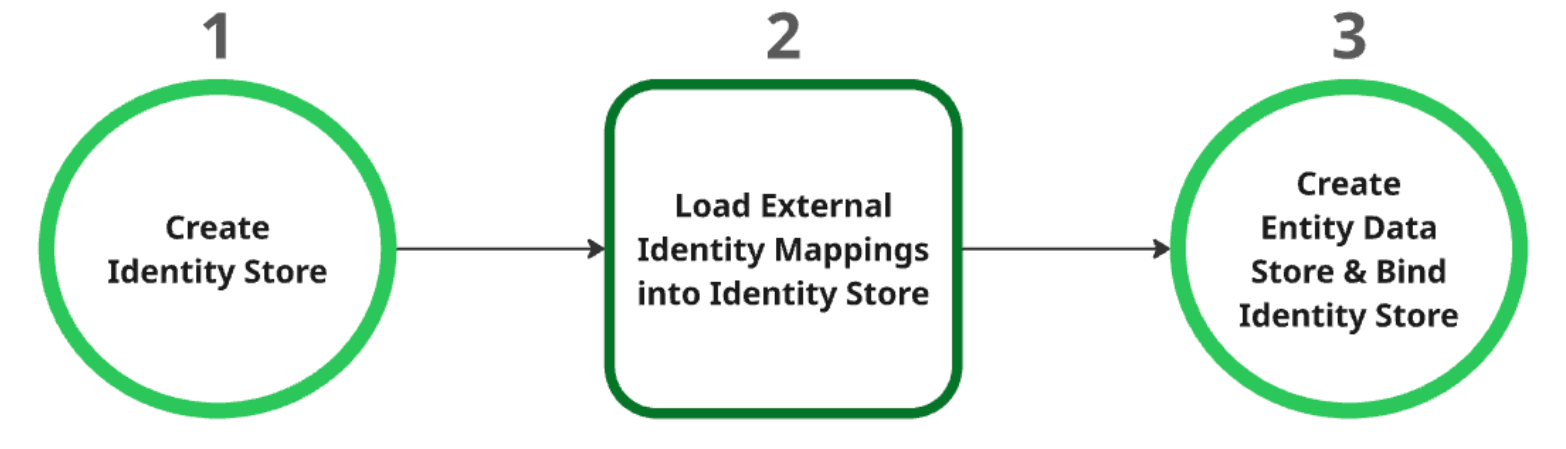
Buat penyimpanan identitas: Penyimpanan ini bertindak sebagai resource induk untuk semua pemetaan identitas. Setelah dibuat, setelan Penyedia Identitas (IDP) tingkat project akan otomatis diambil. Untuk mengetahui informasi selengkapnya, lihat Mengambil atau membuat penyimpanan identitas.
Memuat pemetaan identitas eksternal ke penyimpanan identitas: Setelah membuat penyimpanan identitas, muat data identitas eksternal ke dalamnya. Untuk mengetahui informasi selengkapnya, lihat Menyerap pemetaan identitas ke dalam penyimpanan identitas.
Buat dan ikat penyimpanan data entitas: Penyimpanan data entitas hanya dapat dibuat setelah penyimpanan identitas berhasil dibuat dan pemetaan identitas dimuat. Anda harus mengikat penyimpanan identitas ke penyimpanan data entity selama pembuatannya. Untuk mengetahui informasi selengkapnya tentang cara membuat penyimpanan data entitas, lihat Membuat penyimpanan data.
Sinkronisasi data
Ada dua model arsitektur yang berbeda untuk menyinkronkan data:
Model Arsitektur 1: Upsert inkremental: Pendekatan upsert inkremental paling cocok untuk skenario saat data di-streaming dan memerlukan update real-time. Konektor ini memanfaatkan Discovery Engine API untuk melakukan upsert inkremental yang efisien (memasukkan atau memperbarui data) dengan memanggil fungsi yang sesuai dengan perubahan kecil saat terjadi. Fokus pada ukuran perubahan minimal dan penundaan minimal ini membuat penyimpanan dokumen tetap sangat terbaru, bahkan dengan data yang berubah cepat.
Model Arsitektur 2: Sinkronisasi komprehensif dengan Google Cloud Storage: Pendekatan yang direkomendasikan ini menawarkan serangkaian fitur pengelolaan data yang komprehensif dan fleksibilitas tinggi. API ini mendukung sinkronisasi penuh, yang memungkinkan penyisipan, pembaruan, dan penghapusan data di seluruh set data, dan sinkronisasi inkremental, yang hanya menangani penyisipan dan pembaruan dengan mengirimkan perubahan. Hal ini membuat pendekatan ini kuat untuk berbagai kebutuhan data, terutama untuk mengelola operasi data yang lebih besar atau lebih kompleks. Model ini menggunakan proses penyiapan (langkah 1 dalam diagram) di mana konektor pertama-tama menulis data ke Google Cloud Storage (GCS), lalu memanfaatkan Discovery Engine API untuk memperbarui penyimpanan dokumen dengan memanggil fungsi impor yang diperlukan dari lokasi GCS yang disiapkan.
Konektor kustom cukup fleksibel untuk mendukung arsitektur hybrid, sehingga Anda dapat menerapkan upsert inkremental untuk data yang berubah dengan cepat dan sinkronisasi komprehensif untuk pembaruan atau penghapusan data lengkap terjadwal.