Les connecteurs personnalisés vous permettent d'intégrer des sources de données externes qui ne font pas partie de la bibliothèque de connecteurs standards de Gemini Enterprise. Vous pouvez ainsi rendre les données uniques de votre organisation consultables et accessibles en langage naturel, grâce à Gemini et à l'intelligence de recherche avancée de Google. Le connecteur personnalisé interagit directement avec l'API Discovery Engine, qui offre des fonctionnalités robustes de stockage, d'indexation et de recherche intelligente de données. Le connecteur convertit les informations sources au format Document standardisé basé sur JSON (en structurant le contenu, les métadonnées et les listes de contrôle d'accès (ACL)), et s'assure que ces données sont organisées dans des magasins de données. Ces magasins servent de dépôts logiques, idéalement pour un seul format de document, chacun avec son propre index de recherche et ses propres configurations.
Fonctionnement des connecteurs personnalisés
Les connecteurs personnalisés fonctionnent à l'aide d'un pipeline de données automatisé pour effectuer trois actions clés : extraction, transformation et synchronisation. Ce processus permet de s'assurer que les données externes sont correctement préparées et importées dans Gemini Enterprise.
Récupération : le connecteur extrait les données, y compris les documents, les métadonnées et les autorisations, du système externe à l'aide de ses API, bases de données ou formats de fichier.
Transformer : le connecteur convertit les données brutes au format de document du moteur de découverte, structure le contenu et les métadonnées, et attribue un ID unique global à chaque document. Pour les contrôles d'accès, vous pouvez utiliser directement des identités reconnues par Google ou le mappage d'identité pour les utilisateurs externes ou les groupes personnalisés.
Synchronisation : le connecteur importe les documents dans les data stores Gemini Enterprise et les tient à jour grâce à des jobs planifiés. La synchronisation des données est effectuée à l'aide d'un datastore créé pour une entité. Pour en savoir plus sur la création d'un datastore, consultez Processus de création d'un datastore. Choisissez un mode de synchronisation en fonction de vos besoins : Incrémentiel ajoute et met à jour les données, tandis que Complet remplace l'intégralité de l'ensemble de données.
LCA et mappage d'identité
Pour gérer l'accès au niveau des documents, vous avez le choix entre deux méthodes : les LCA pures ou le mappage des identités, en fonction du format d'identité utilisé par les données.
LCA pures (AclInfo) : cette méthode est utilisée lorsque la source de données utilise des identités basées sur des adresses e-mail reconnues par (Google Cloud). Cette approche est idéale pour définir directement qui a accès aux données.
Mappage des identités : cette méthode est utilisée lorsque la source de données utilise des noms d'utilisateur, des anciens ID ou d'autres systèmes d'identité externes :
Elle établit une association claire et individuelle entre les groupes d'identité externes (par exemple, EXT1) et les utilisateurs ou groupes du fournisseur d'identité (IdP) interne (par exemple,
IDPUser1@example.com).Il permet au système de comprendre et d'appliquer les contrôles d'accès basés sur les groupes du système source, ce qui est utile lorsqu'une API renvoie des libellés de groupe sans appartenance complète des utilisateurs ou pour mettre à l'échelle efficacement les LCA sans lister des milliers d'utilisateurs par document.
Le processus de mappage des identités nécessite de résoudre toutes les structures d'identité imbriquées ou hiérarchiques en une liste plate de mappages directs, généralement dans un format JSON spécifié.
Utilisez des ID de groupe d'identité externe uniques (par exemple, EXT1) pour les identités externes afin de préserver l'intégrité du système. Pour en savoir plus et obtenir des exemples, consultez Mapper des identités externes.
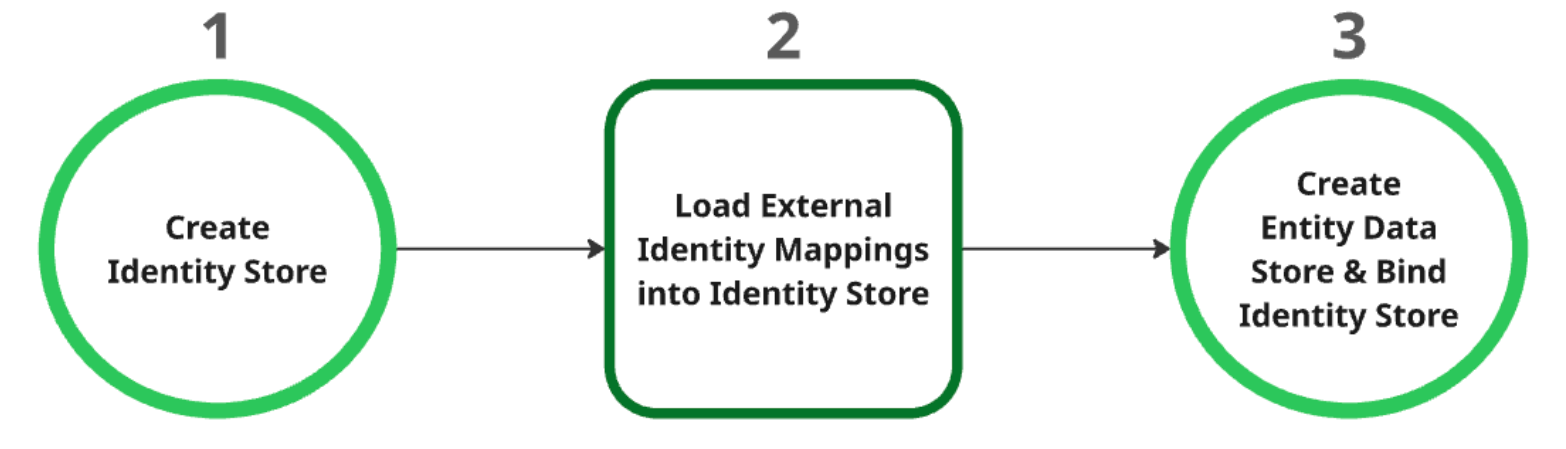
Processus de création d'un datastore
Créez le magasin d'identités : ce magasin sert de ressource parente pour tous les mappages d'identité. Lors de la création, les paramètres du fournisseur d'identité (IdP) au niveau du projet sont automatiquement récupérés. Pour en savoir plus, consultez Récupérer ou créer un magasin d'identités.
Chargez les mappages d'identité externe dans le magasin d'identités : après avoir créé le magasin d'identités, chargez-y les données d'identité externe. Pour en savoir plus, consultez Ingérer le mappage d'identité dans le magasin d'identités.
Créez et associez le datastore d'entités : le datastore d'entités ne peut être créé qu'après la création de l'identity store et le chargement des mappages d'identité. Vous devez associer le magasin d'identités au magasin de données d'entités lors de sa création. Pour en savoir plus sur la création d'un data store d'entités, consultez Créer un data store.
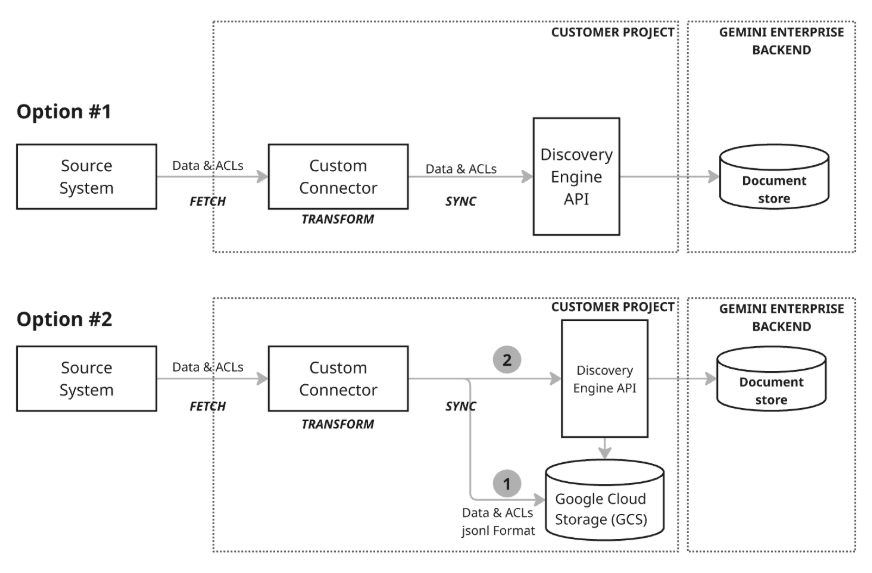
Synchroniser les données
Il existe deux modèles d'architecture différents pour synchroniser les données :
Modèle d'architecture 1 : Upsert incrémentiel : l'approche d'upsert incrémentiel est idéale pour les scénarios où les données sont diffusées en flux continu et nécessitent des mises à jour en temps réel. Le connecteur utilise l'API Discovery Engine pour effectuer des upserts incrémentaux efficaces (insertion ou mise à jour de données) en appelant les fonctions appropriées avec de petites modifications au fur et à mesure qu'elles se produisent. Cette approche, qui privilégie les modifications de taille et de délai minimaux, permet de maintenir le magasin de documents à jour, même avec des données qui évoluent rapidement.
Modèle d'architecture 2 : synchronisation complète avec Google Cloud Storage : cette approche recommandée offre un ensemble complet de fonctionnalités de gestion des données et une grande flexibilité. Il est compatible avec les synchronisations complètes, qui permettent d'insérer, de mettre à jour et de supprimer des données dans l'ensemble de données, et avec les synchronisations incrémentielles, qui ne gèrent que les insertions et les mises à jour en envoyant les modifications. Cette approche est donc robuste pour un large éventail de besoins en données, en particulier pour la gestion d'opérations de données plus volumineuses ou plus complexes. Ce modèle utilise un processus de préproduction (étape 1 du schéma) dans lequel le connecteur écrit d'abord les données dans Google Cloud Storage (GCS), puis utilise l'API Discovery Engine pour mettre à jour le data store en appelant les fonctions d'importation nécessaires à partir de l'emplacement GCS intermédiaire.
Les connecteurs personnalisés sont suffisamment flexibles pour prendre en charge une architecture hybride. Ils vous permettent d'implémenter l'upsert incrémentiel pour les données qui évoluent rapidement et la synchronisation complète pour les mises à jour ou les suppressions de données complètes planifiées.