
יצירה, שימוש וניהול של מסווג מסמכים בהתאמה אישית
שימוש במסווג תוכן מותאם אישית כדי לסווג מסמכים. אתם יכולים לבנות אותו מאפס באמצעות מסמכים משלכם וסיווגים בהתאמה אישית. היבט ה-AI הגנרטיבי שלו מאפשר למידה מכמה דוגמאות ושיפור ביצועים. השיפורים האלה מאפשרים להגיע לרמת דיוק גבוהה יותר עם פחות דוגמאות ותיקונים באמצעות תיוג אוטומטי איטרטיבי.
מסווג תוכן מותאם אישית מכסה את שלושת תרחישי השימוש הכלליים האלה.
- מודל שאומן מראש: אפשר להשתמש במודל הבסיס של AI גנרטיבי שאומן מראש כדי לסווג במהירות מסמכים עם התוויות שסיפקתם.
- כוונון עדין: כדי לשפר את הדיוק, מאמנים את מודל הבסיס של ה-AI הגנרטיבי על הנתונים והתוויות שלכם.
- אימון מודל בהתאמה אישית: אימון של כלי חילוץ בהתאמה אישית שאינו מבוסס על AI גנרטיבי באמצעות נתונים ותוויות משלכם.
גרסאות של מודלים של מסווג תוכן מותאם אישית
יש תמיכה בציוני מהימנות במודלים מותאמים אישית של מסווגים בתצוגה מקדימה. כדי לקבל את הביצועים הכי טובים, מומלץ להשתמש בהם עם מודלים שעברו כוונון עדין.
| גרסת המודל | תיאור | ערוץ הפצה | עיבוד באמצעות ML בארה"ב או באיחוד האירופי | כוונון עדין בארה"ב ובאיחוד האירופי | תאריך הפצה |
|---|---|---|---|---|---|
pretrained-classifier-v1.5-2025-08-05 |
מודל מוכן לייצור שמבוסס על מודל שפה גדול (LLM) Gemini 2.5 Flash. כולל גם תכונות OCR מתקדמות. אפשר להשתמש במודל הזה שעבר אימון מראש בלי לבצע אימון מוקדם. הוא תומך בסיווג ללא דוגמאות ומספק תמיכה טובה יותר לסיווג כללי. | יציב | כן | ארה"ב, האיחוד האירופי (תצוגה מקדימה) | 5 באוגוסט 2025 |
pretrained-classifier-v1.6-2026-03-09 |
גרסת קדם-הפצה שמבוססת על מודל שפה גדול (LLM) של Gemini 3.1 Flash. | גרסה מועמדת להפצה | כן | ארה"ב, האיחוד האירופי (תצוגה מקדימה) | 9 במרץ 2026 |
pretrained-classifier-v1.6-pro-2026-03-09 |
גרסה מועמדת להפצה שמבוססת על מודל שפה גדול (LLM) של Gemini 3.1 Pro. | גרסה מועמדת להפצה | כן | ארה"ב, האיחוד האירופי (תצוגה מקדימה) | 9 במרץ 2026 |
יצירת מסווג תוכן מותאם אישית במסוף Google Cloud
אתם יכולים ליצור מסווגים בהתאמה אישית שמתאימים במיוחד למסמכים שלכם, ולבצע אימון והערכה שלהם באמצעות הנתונים שלכם. המעבד הזה מזהה סוגים של מסמכים מתוך קבוצה של סוגים שהוגדרה על ידי המשתמש. לאחר מכן תוכלו להשתמש במעבד המאומן הזה במסמכים נוספים. בדרך כלל משתמשים במסווג תוכן מותאם אישית במסמכים מסוגים שונים, ואז משתמשים בזיהוי כדי להעביר את המסמכים למעבד חילוץ כדי לחלץ את הישויות.
בקטע איך עושים את זה מוסבר התהליך הכללי ליצירה ולשימוש במעבד.
אתם יכולים לבחור את ההגדרות שמתאימות לתהליך העבודה שלכם.
לחצו על תראו לי איך כדי לקרוא הסבר מפורט על המשימה ישירות במסוף Google Cloud :
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות ליצירת סיווג בהתאמה אישית, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים בפרויקט:
- אדמין של Document AI (
roles/documentai.admin) - אדמין באחסון (
roles/storage.admin)
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שאפשר לקבל את ההרשאות הנדרשות גם באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש.
יצירת מעבד
מבצעים את השלבים הבאים.
עוברים אל Workbench.
כדי ליצור סיווג מסמכים בהתאמה אישית, בוחרים באפשרות
יצירת מעבד .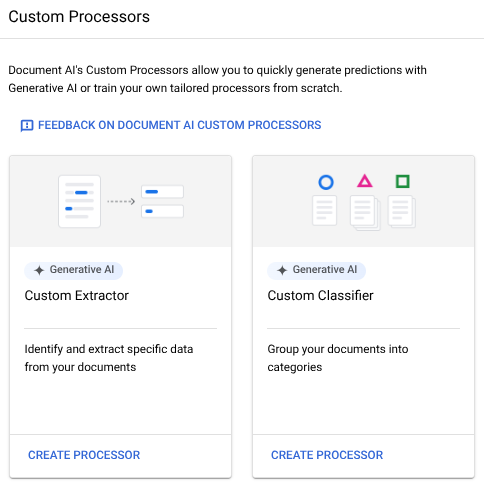
בתפריט Create processor, מזינים שם למעבד, למשל
my-custom-document-classifier.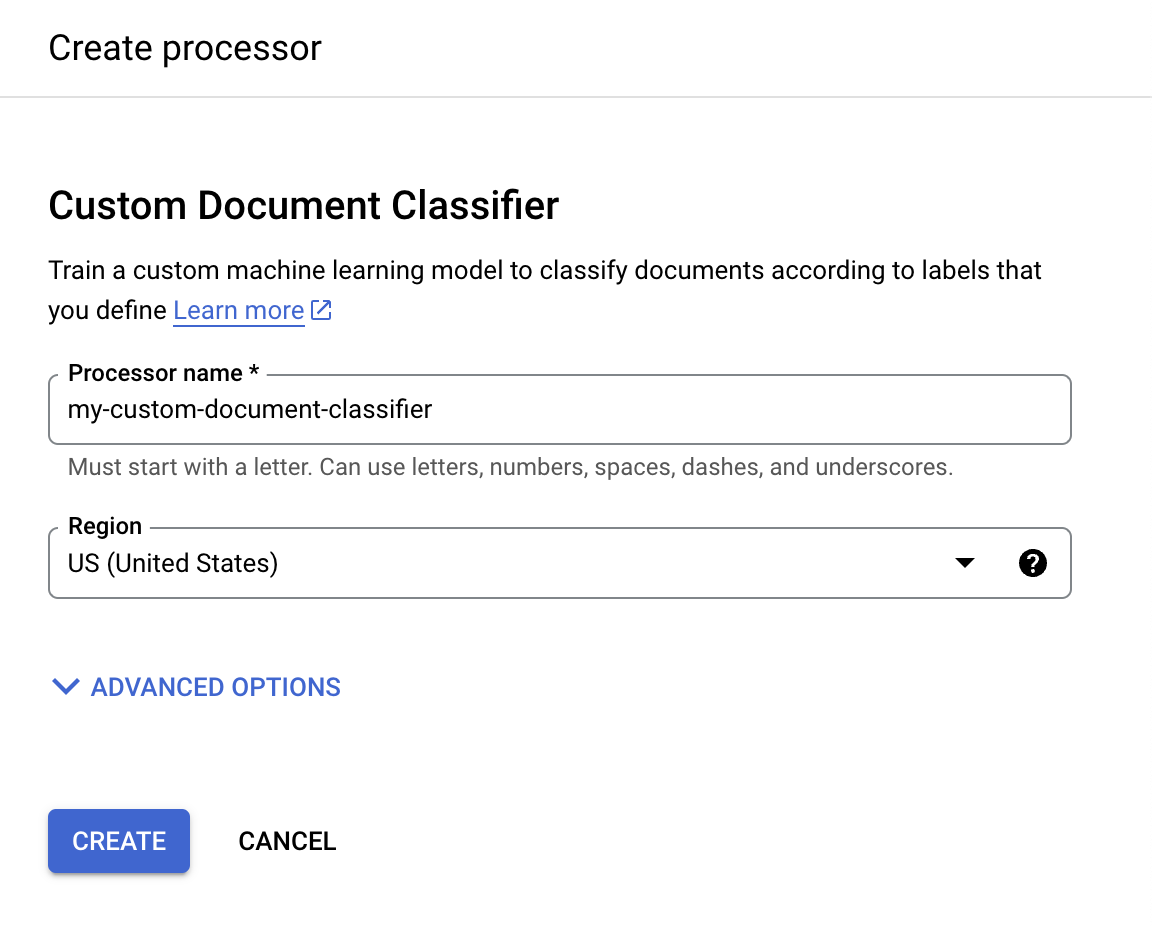
בוחרים את האזור שהכי קרוב אליכם.
לוחצים על יצירה. מופיעה הכרטיסייה פרטי המעבד.
הגדרת מערך נתונים
כדי לאמן את מעבד הנתונים החדש הזה, צריך ליצור מערך נתונים עם נתוני אימון ובדיקה שיעזרו למעבד לזהות את המסמכים שרוצים לפצל ולסווג. נדרש מיקום חדש למערך הנתונים הזה. יכול להיות שזו קטגוריה של Cloud Storage או תיקייה ריקה, או שאתם יכולים לאפשר מיקום שמנוהל באופן פנימי.
אחרי שהכרטיסייה פרטי המעבד מופיעה, אפשר:
- אם רוצים להשתמש ב-Cloud Storage, בוחרים באפשרות אחסון בניהול Google.
- אם רוצים להשתמש באחסון משלכם כדי להשתמש במפתחות הצפנה בניהול הלקוח (CMEK), בוחרים באפשרות אציין מיקום אחסון משלי ופועלים לפי השלבים במאמר יצירת מערך נתונים.

ייבוא מסמכים למערך נתונים
לאחר מכן מייבאים את המסמכים למערך הנתונים.
בכרטיסייה Build (בנייה), בוחרים באפשרות
Import documents (ייבוא מסמכים).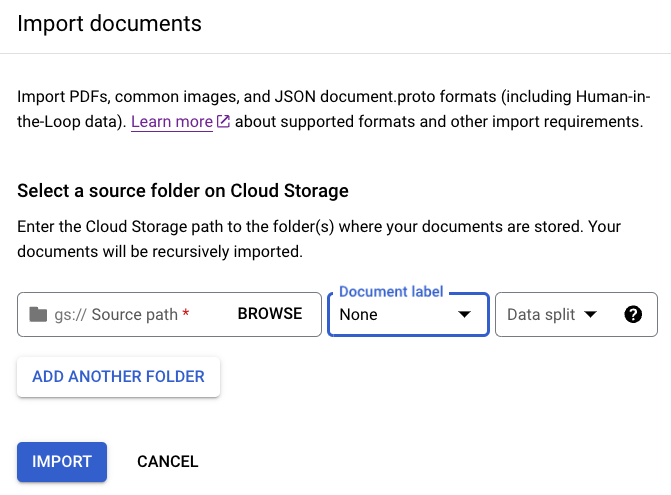
כשבוחרים להשתמש בקטגוריית אחסון, צריך להזין את נתיב המקור של הקטגוריה. בדוגמה הזו, מזינים את שם הקטגוריה בשדה
Source path (נתיב המקור). הקישור הזה מוביל ישירות למסמך אחד.cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdfבקטע Data split (פיצול נתונים), בוחרים באפשרות Unassigned (לא הוקצה). המסמך בתיקייה הזו לא משויך לקבוצת הבדיקה או לקבוצת האימון. משאירים את התיבה ייבוא עם תיוג אוטומטי לא מסומנת.
לוחצים על ייבוא. Document AI קורא את המסמכים מהמאגר אל מערך הנתונים. הוא לא משנה את דלי הייבוא או קורא מהדלי אחרי שהייבוא מסתיים.
אופציונלי: כדי למחוק מסמכים מיובאים, בכרטיסייה Build (יצירה), עוברים אל Manage dataset (ניהול מערך הנתונים) > בוחרים את המסמכים > לוחצים על Delete (מחיקה).
כשמייבאים מסמכים, אפשר להקצות אותם לקבוצת האימון או לקבוצת הבדיקה בזמן הייבוא, או להקצות אותם מאוחר יותר.
מידע נוסף על הכנת הנתונים לייבוא זמין במדריך להכנת נתונים.
הגדרת סכימת המעבד
אפשר ליצור את סכימת המעבד לפני או אחרי שמייבאים מסמכים למערך הנתונים. הסכימה מספקת תוויות שמשמשות להוספת הערות למסמכים.
בכרטיסייה Build (יצירה), בוחרים באפשרות Manage Dataset (ניהול מערך נתונים) > Edit Schema (עריכת סכימה). ייפתח הדף עריכת סכימה.
בוחרים באפשרות
יצירת תווית .מזינים את השם של התווית.
לוחצים על יצירה. הוראות מפורטות ליצירה ולעריכה של סכימה זמינות במאמר בנושא הגדרת סכימת מעבד.
צריך ליצור כל אחת מהתוויות הבאות לסכימת המעבד.
computer_visioncryptomed_techother
כשמסיימים להוסיף את התוויות, לוחצים על
שמירה .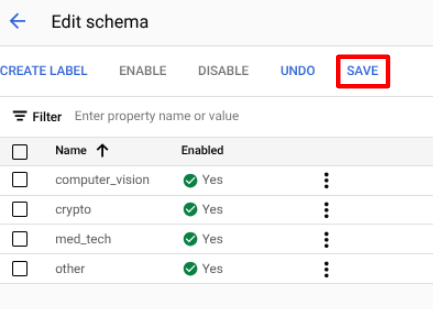
הוספת תוויות למסמך
התהליך של בחירת טקסט במסמך והוספת תוויות נקרא הערה.
חוזרים לכרטיסייה Build ובוחרים
מסמך כדי לפתוח את מסוף Manage Dataset.בין
האפשרויות , בוחרים את התווית המתאימה למסמך. אם אתם משתמשים במסמך לדוגמה שסיפקנו, בוחרים באפשרותcomputer_vision.כשמסמנים את המסמך, הוא אמור להיראות כך:

כשמסיימים להוסיף הערות למסמך, בוחרים באפשרות
סימון כ'תויג' .בכרטיסייה ניהול קבוצת נתונים, בחלונית מסמך מוצג מסמך אחד עם תווית.
הקצאת מסמך עם הערות לקבוצת נתונים לאימון
אחרי שמתייגים את המסמך לדוגמה, אפשר להקצות אותו לקבוצת נתונים לאימון.
בכרטיסייה ניהול מערך נתונים, מסמנים את תיבת הסימון
בחירת הכול .ברשימה
הקצאה לקבוצה , בוחרים באפשרות הדרכה.
בחלונית Documents, אפשר לראות שמסמך אחד הוקצה לקבוצת נתונים לאימון.
(אופציונלי) ייבוא נתונים עם תוויות מוגדרות מראש למערכי האימון והבדיקה
אם אתם משתמשים בגרסה 1.4, אתם צריכים להעלות קבוצות אימון ובדיקה כדי לאמן את מעבד הנתונים המותאם אישית. אם משתמשים בגרסה 1.5, אפשר לדלג על השלב הזה.
במדריך הזה, הנתונים מסומנים מראש. אם אתם עובדים על פרויקט משלכם, אתם צריכים להחליט איך לתייג את הנתונים. אפשר לעיין באפשרויות התיוג.
כדי לתייג כל סוג מסמך, צריך לפחות מסמך אחד בקבוצות האימון והבדיקה של מעבדים מותאמים אישית של Document AI. כדי להשיג את הביצועים הכי טובים, מומלץ להוסיף לפחות 10 מסמכים לכל תווית. אם יש 5 תוויות, תצטרכו 50 מסמכים לאימון ו-50 לבדיקה. בדרך כלל, ככל שיש יותר נתוני אימון, כך רמת הדיוק גבוהה יותר.
לוחצים על
ייבוא מסמכים .מזינים את הנתיב הבא ב
נתיב המקור . המאגר הזה מכיל מסמכים עם תוויות מוגדרות מראש בפורמט Document JSON.cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionTypeברשימה פיצול נתונים, בוחרים באפשרות פיצול אוטומטי. המסמכים יפוצלו אוטומטית כך ש-80% מהם יהיו בקבוצת נתונים לאימון ו-20% בקבוצת נתונים לבדיקה. מתעלמים מהקטע הוספת תוויות.
לוחצים על ייבוא. יכול להיות שייקח כמה דקות עד שהייבוא יסתיים.
כשהייבוא יסתיים, המסמכים יופיעו בכרטיסייה ניהול מערך נתונים.
הוספת תוויות למסמכים בייבוא
אופציונלית, אחרי שמגדירים את הסכימה, אפשר להוסיף תוויות לכל המסמכים שנמצאים בספרייה מסוימת בזמן הייבוא, כדי לחסוך זמן בהוספת תוויות.
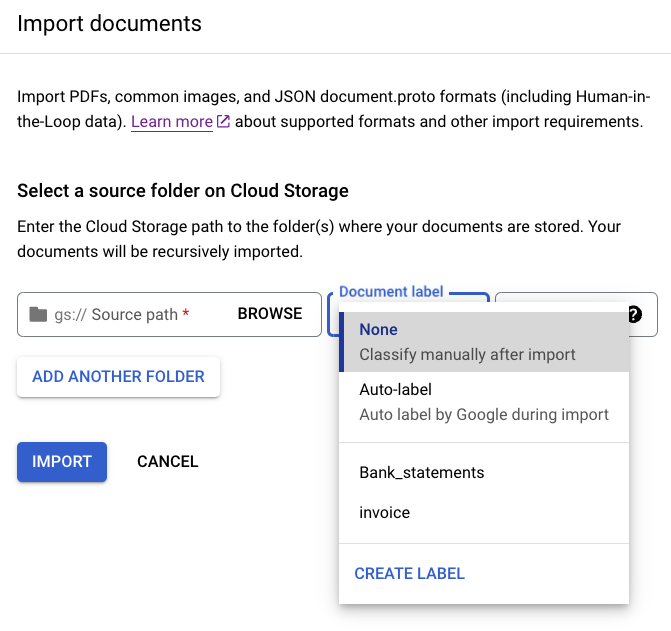
לוחצים על
ייבוא מסמכים .מזינים את הנתיב הבא ב
נתיב המקור . המאגר הזה מכיל מסמכים לא מסומנים בפורמט PDF.cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelברשימה פיצול נתונים, בוחרים באפשרות פיצול אוטומטי. המסמכים יפוצלו אוטומטית כך ש-80% מהם יהיו בקבוצת נתונים לאימון ו-20% בקבוצת נתונים לבדיקה.
בקטע החלת תוויות, בוחרים באפשרות בחירת תווית.
בדוגמאות האלה, בוחרים באפשרות
other.בוחרים באפשרות ייבוא ומחכים שהתהליך יסתיים. אפשר לצאת מהדף ולחזור אליו מאוחר יותר. כשהתהליך מסתיים, המסמכים מופיעים בכרטיסייה ניהול מערך נתונים עם התווית שהוקצתה להם.
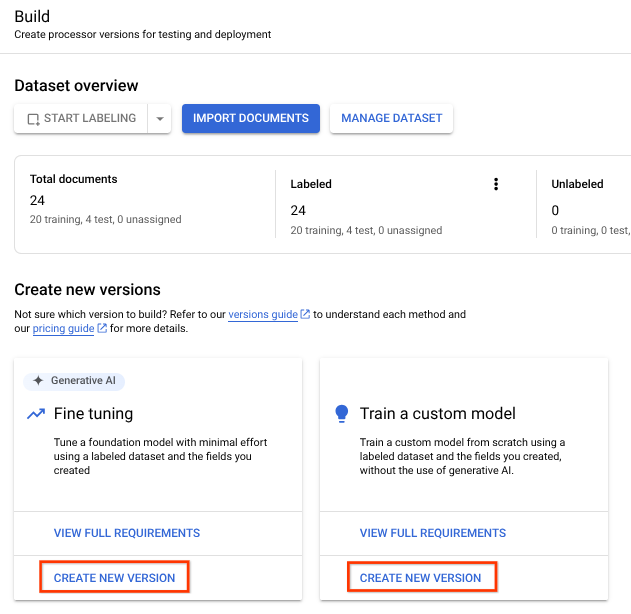
(אופציונלי) אימון המעבד
אם אתם משתמשים בגרסה 1.4, אתם צריכים לאמן את מעבד הנתונים המותאם אישית על נתוני אימון ונתוני בדיקה. אם משתמשים בגרסה 1.5, אפשר לדלג על השלב הזה.
אחרי שמייבאים את נתוני האימון והבדיקה, אפשר לאמן את המעבד. תהליך האימון עשוי להימשך כמה שעות, לכן חשוב לוודא שהגדרתם את המעבד עם הנתונים והתוויות המתאימים לפני שתתחילו באימון.
אתם יכולים לאמן מודלים מותאמים אישית ומודלים עם כוונון עדין באמצעות הנתונים המתויגים שלכם. מודלים שעברו כוונון עדין מבוססים על AI גנרטיבי. המודלים המותאמים אישית מאמנים מודל שפה גדול ייחודי באמצעות הנתונים המתויגים שלכם. צריך לפחות שתי תוויות בסכימה, עם 10 מסמכי אימון מומלצים ו-10 מסמכי בדיקה (מינימום של 1).
- בוחרים באפשרות
Train New Version (אימון גרסה חדשה).
בשדה
Version name (שם הגרסה), מזינים שם לגרסה הזו של המעבד, למשלmy-cdc-version-1.אופציונלי: בוחרים באפשרות הצגת נתונים סטטיסטיים של תוויות כדי לראות מידע על תוויות המסמך שיכול לעזור לכם לקבוע את היקף הכיסוי. לוחצים על סגירה כדי לחזור להגדרת ההדרכה.
בוחרים באפשרות
התחלת האימון . אפשר לבדוק את הסטטוס בחלונית הצדדית.
פריסת גרסת המעבד
אחרי שהאימון יסתיים, עוברים לכרטיסייה
ניהול גרסאות . אפשר לראות פרטים על הגרסה שאומנה.לוחצים על הסמל
לצד הגרסה שרוצים לפרוס ובוחרים באפשרות פריסת גרסה. בתיבת הדו-שיח, בוחרים באפשרות
פריסה .תהליך הפריסה נמשך כמה דקות.
הערכה ובדיקה של המעבד
אחרי שהפריסה מסתיימת, עוברים לכרטיסייה
הערכה ובדיקה .בדף הזה אפשר לראות מדדי הערכה, כולל ציון F1, דיוק וזיכרון לכל המסמך ולתוויות נפרדות. מידע נוסף על הערכה ועל נתונים סטטיסטיים זמין במאמר הערכת מעבד.
הורידו מסמך שלא היה מעורב בהדרכה או בבדיקה קודמות, כדי שתוכלו להשתמש בו להערכת גרסת המעבד. אם משתמשים בנתונים משלכם, צריך להשתמש במסמך שנועד למטרה הזו.
בוחרים באפשרות
העלאת מסמך בדיקה ובוחרים את המסמך שהורדתם.ייפתח הדף Custom Document Classifier analysis. הפלט מראה עד כמה המסמך סווג בצורה טובה.
אפשר גם להריץ מחדש את ההערכה על קבוצת נתונים לבדיקה אחרת או על גרסה אחרת של מעבד.
סימון אוטומטי של מסמכים חדשים שיובאו
אחרי פריסת גרסה של מעבד שאומן, אפשר להשתמש בתיוג אוטומטי כדי לחסוך זמן בתיוג כשמייבאים מסמכים חדשים.
בדף Manage Dataset (ניהול קבוצת הנתונים), לוחצים על
Import documents (ייבוא מסמכים).מעתיקים ומדביקים את הנתיב הבא ב-Cloud Storage. הספרייה הזו מכילה חמישה קובצי PDF של פטנטים ללא תווית. ברשימה הנפתחת פיצול נתונים, בוחרים באפשרות אימון.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabelבקטע החלת תוויות, בוחרים באפשרות הוספת תוויות אוטומטית.
בוחרים גרסה קיימת של מעבד כדי לתייג את המסמכים.
- לדוגמה:
2af620b2fd4d1fcf
- לדוגמה:
בוחרים באפשרות ייבוא ומחכים שהתהליך יסתיים. אפשר לצאת מהדף ולחזור אליו מאוחר יותר. בסיום, המסמכים יופיעו בקטע תיוג אוטומטי בדף ניהול מערך הנתונים.
אי אפשר להשתמש במסמכים עם תוויות אוטומטיות לאימון או לבדיקה בלי לסמן אותם כמסמכים עם תוויות. כדי לראות את המסמכים עם התוויות האוטומטיות, עוברים לקטע
Auto-labeled .בוחרים את המסמך הראשון כדי להיכנס למסוף התיוג.
בודקים את התווית כדי לוודא שהיא נכונה. אם הוא שגוי, משנים אותו.
כשמסיימים, בוחרים באפשרות
סימון כתווית .חוזרים על אימות התווית לכל מסמך שסומן אוטומטית, ואז חוזרים לדף ניהול מערך הנתונים כדי להקצות את הנתונים לאימון.
שימוש במעבד
אפשר לנהל את הגרסאות של מעבד שעבר אימון מותאם אישית בדיוק כמו כל גרסה אחרת של מעבד. מידע נוסף זמין במאמר בנושא ניהול גרסאות של מעבדים.
אפשר גם לשלוח בקשת עיבוד למעבד המותאם אישית, והתשובה יכולה להיות מטופלת כמו מעבדים אחרים של מסווגים.
הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם בדף הזה, פועלים לפי השלבים הבאים:
בתפריט הניווט במסוף Google Cloud , בוחרים באפשרות Document AI ואז באפשרות My Processors.
בוחרים באפשרות
עוד פעולות באותה שורה של המעבד שרוצים למחוק.לוחצים על מחיקת מעבד, מזינים את שם המעבד ולוחצים שוב על מחיקה כדי לאשר.
המאמרים הבאים
- פרטים נוספים זמינים במדריכים.
- רשימת המעבדים
- אפשר להפריד מסמכים לחלקים קריאים באמצעות Layout Parser.
- אפשר להשתמש ב-Enterprise Document OCR כדי לזהות ולחלץ טקסט.