
כדי לאמן גרסה של מעבד, לשפר את האימון שלה או להעריך אותה, צריך מערך נתונים של מסמכים עם תוויות.
בדף הזה מוסבר איך ליצור מערך נתונים, לייבא מסמכים ולהגדיר סכימה. כדי להוסיף תוויות למסמכים שיובאו, אפשר לעיין במאמר בנושא הוספת תוויות למסמכים.
בדף הזה מניחים שכבר יצרתם מעבד שתומך באימון, באימון מתקדם או בהערכה. אם המעבד שלכם נתמך, הכרטיסייה Train תופיע במסוף Google Cloud .
אפשרויות אחסון של מערכי נתונים
יש שתי אפשרויות לשמירת מערך הנתונים:
- בניהול Google
- מיקום מותאם אישית ב-Cloud Storage
אלא אם יש לכם דרישות מיוחדות (למשל, לשמור מסמכים בתיקיות עם הצפנה באמצעות מפתח בניהול הלקוח), אנחנו ממליצים על אפשרות האחסון הפשוטה יותר בניהול Google. אחרי שיוצרים את מערך הנתונים, אי אפשר לשנות את אפשרות האחסון שלו במעבד.
התיקייה או תיקיית המשנה של מיקום מותאם אישית ב-Cloud Storage צריכות להיות ריקות בהתחלה, וצריך להתייחס אליהן כאל תיקיות לקריאה בלבד. שינויים ידניים בתוכן של מערך הנתונים עלולים להפוך אותו ללא שמיש ולגרום לאובדן שלו. הסיכון הזה לא קיים באפשרות האחסון שמנוהלת על ידי Google.
כדי להקצות את מיקום האחסון, פועלים לפי השלבים הבאים.
אחסון בניהול Google (מומלץ)
הצגת אפשרויות מתקדמות במהלך יצירת מעבד חדש.
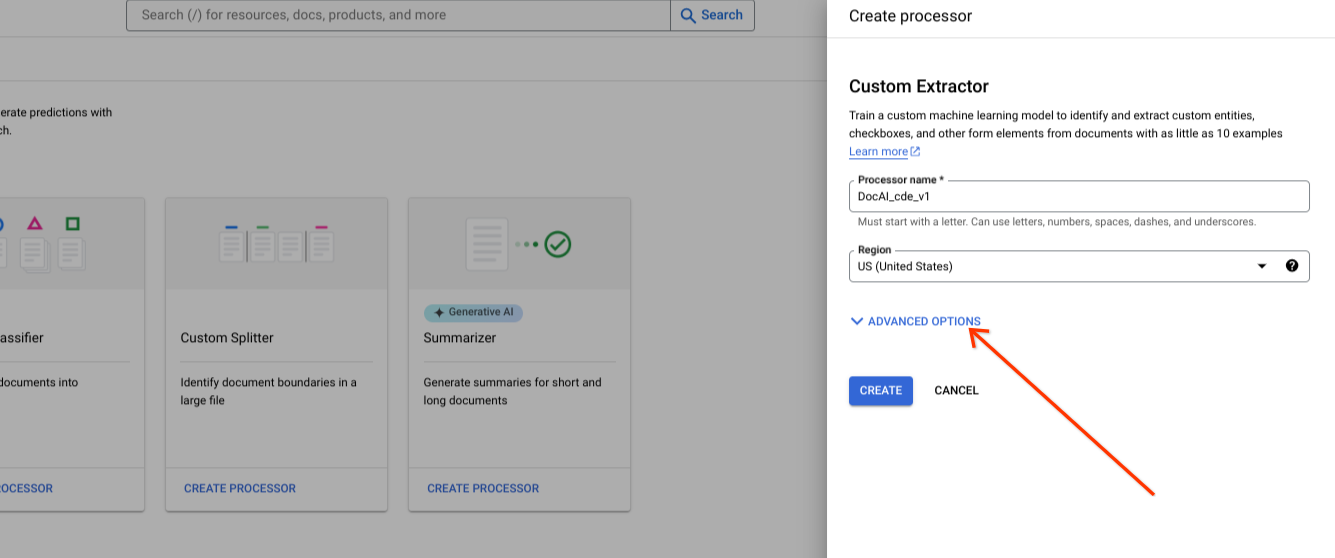
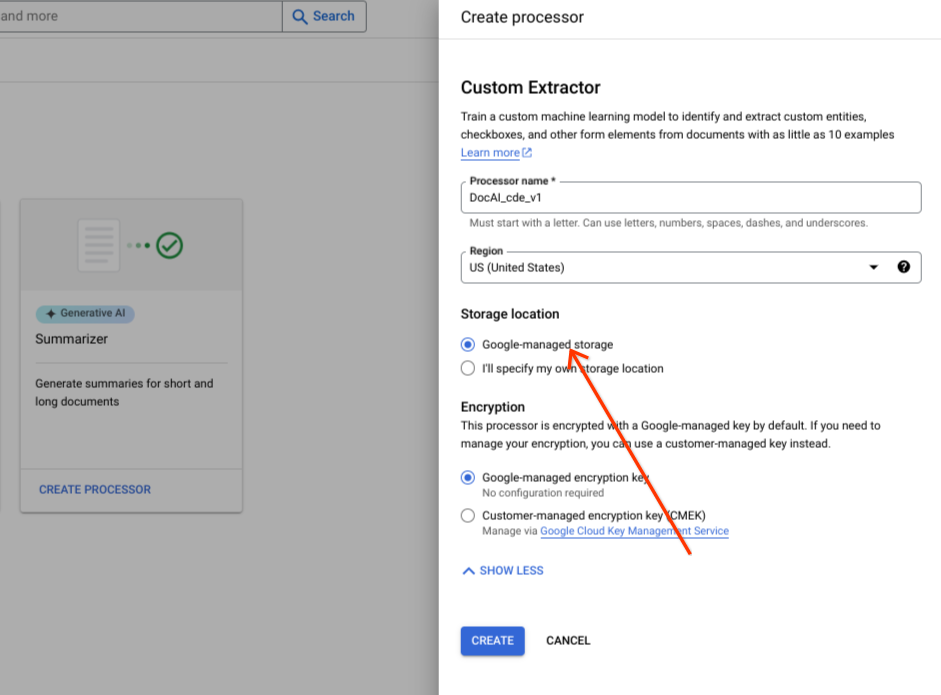
משאירים את ברירת המחדל של קבוצת הלחצנים Google-managed לאחסון.
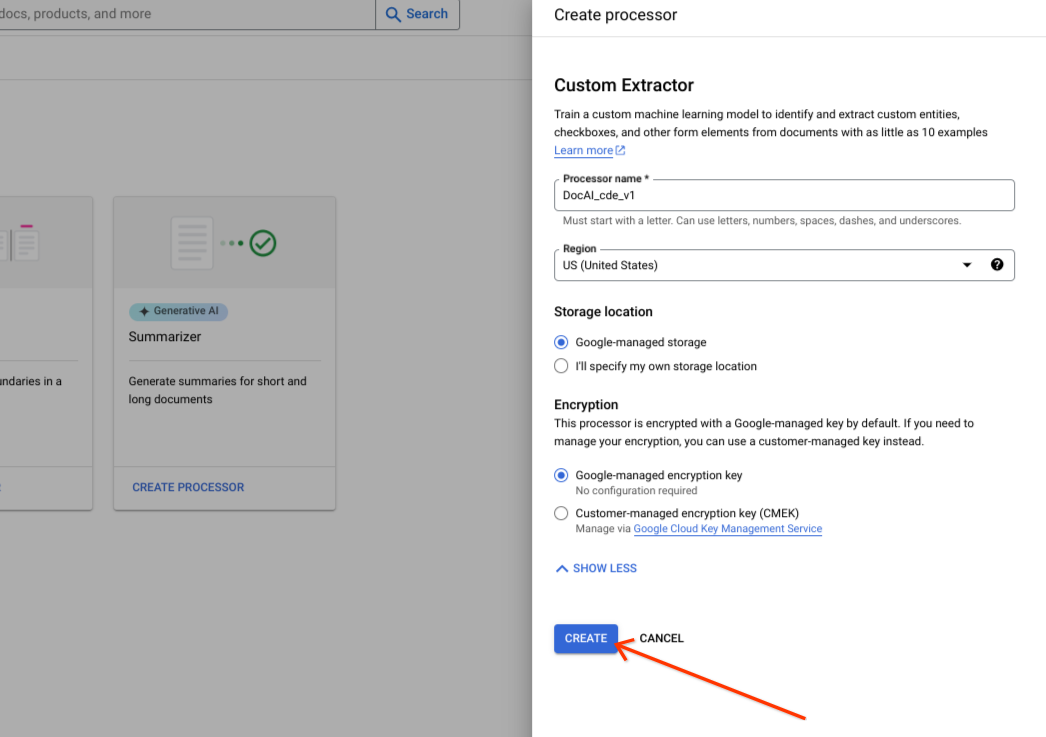
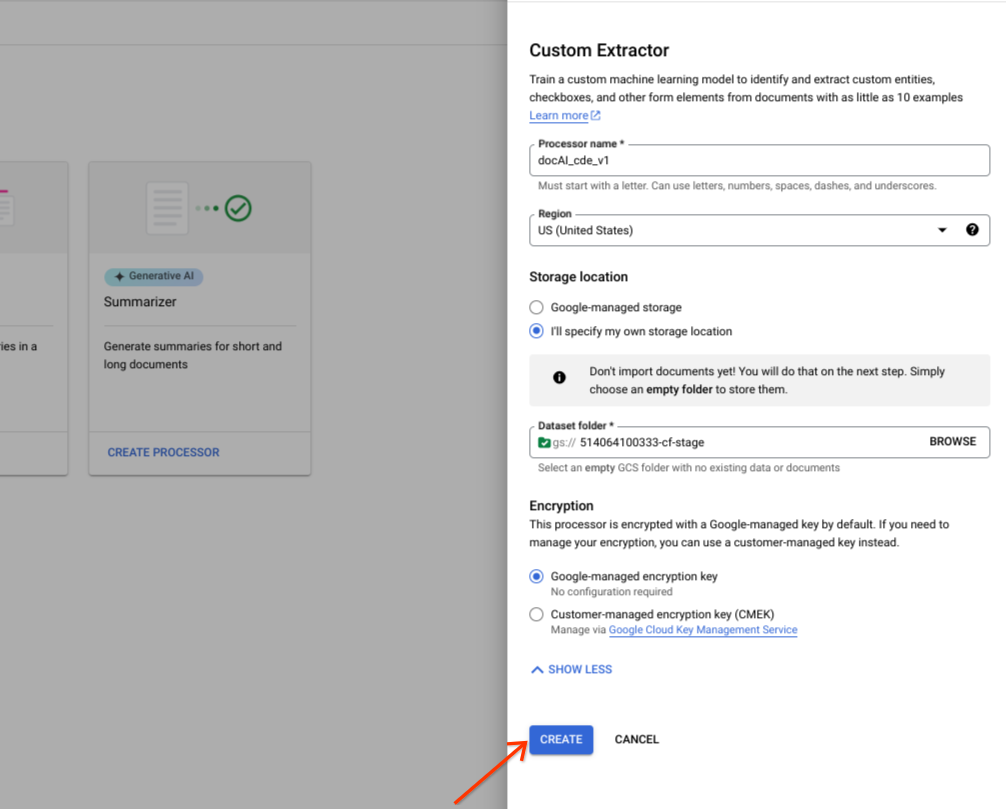
לוחצים על יצירה.
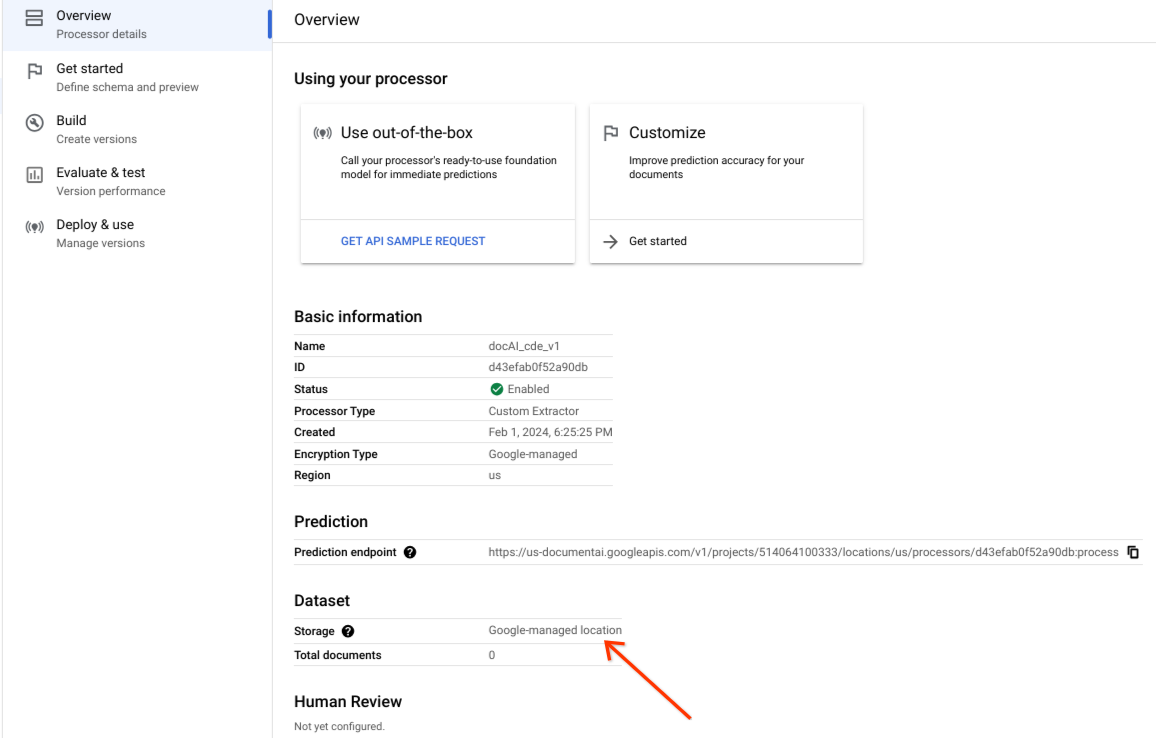
מוודאים שערכת הנתונים נוצרה בהצלחה ושהמיקום שלה הוא מיקום בניהול Google.
אפשרות אחסון מותאמת אישית
מפעילים או משביתים את האפשרויות המתקדמות.
בוחרים באפשרות אציין מיקום אחסון משלי.
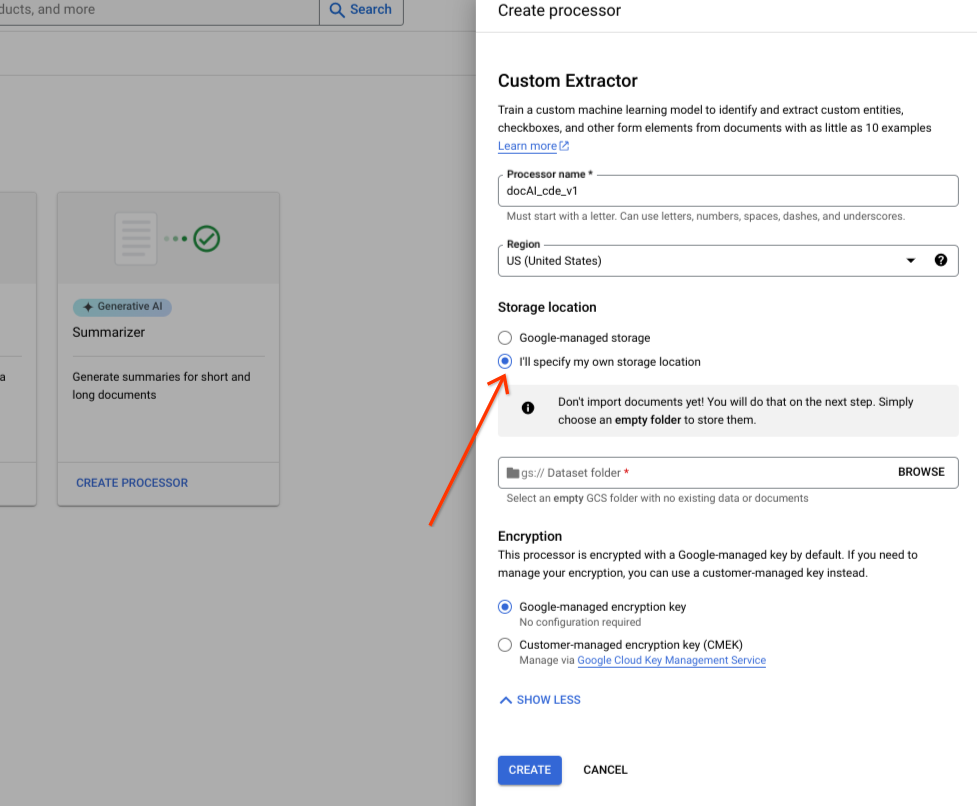
בוחרים תיקייה ב-Cloud Storage מרכיב הקלט.
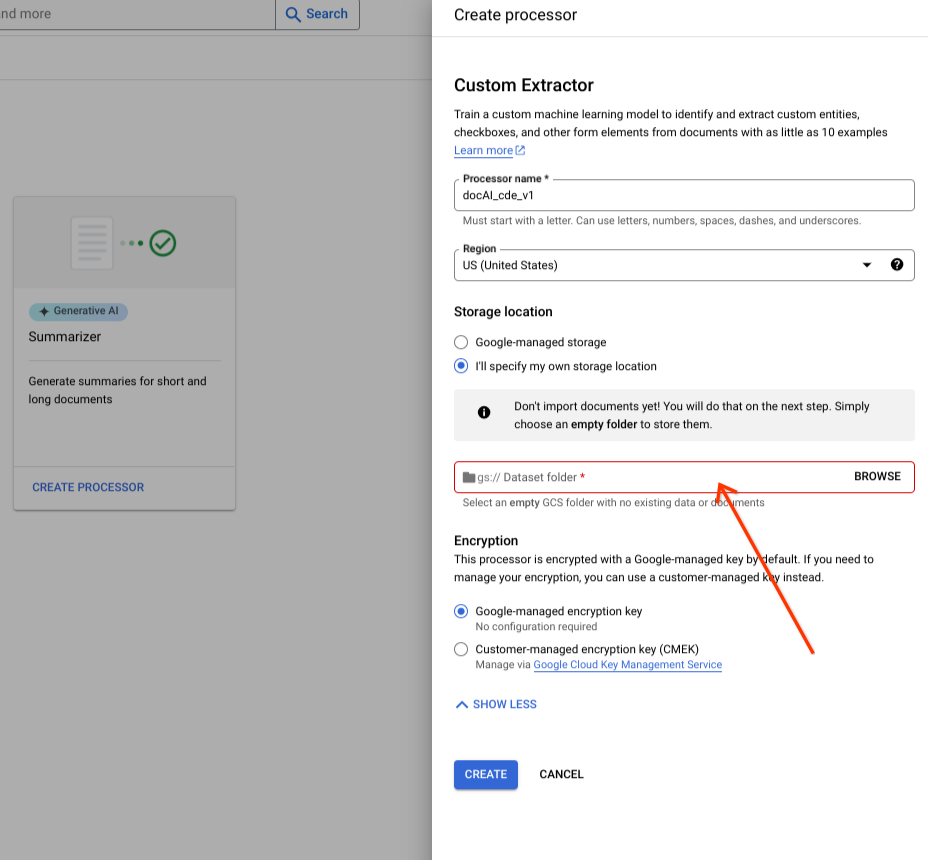
לוחצים על יצירה.
פעולות של Dataset API
בדוגמה הזו מוסבר איך להשתמש בשיטה processors.updateDataset כדי ליצור מערך נתונים. משאב של מערך נתונים הוא משאב יחיד במעבד,
כלומר אין RPC ליצירת משאב. במקום זאת, אפשר להשתמש ב-updateDataset RPC כדי להגדיר את ההעדפות. ב-Document AI יש אפשרות לאחסן את מסמכי מערך הנתונים בקטגוריה של Cloud Storage שאתם מספקים, או לאפשר ל-Google לנהל אותם באופן אוטומטי.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
הקטגוריה שצוינה
פועלים לפי השלבים הבאים כדי ליצור בקשה לקבוצת נתונים עם קטגוריה של Cloud Storage שסיפקתם.
שיטת HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetבקשת JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}בניהול Google
אם רוצים ליצור מערך נתונים שמנוהל על ידי Google, צריך לעדכן את הפרטים הבאים:
שיטת HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetבקשת JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}כדי לשלוח את הבקשה, אפשר להשתמש ב-Curl:
שומרים את גוף הבקשה בקובץ בשם request.json. מריצים את הפקודה הבאה:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}ייבוא מסמכים
מערך נתונים חדש שנוצר הוא ריק. כדי להוסיף מסמכים, בוחרים באפשרות ייבוא מסמכים ובוחרים תיקייה אחת או יותר ב-Cloud Storage שמכילות את המסמכים שרוצים להוסיף למערך הנתונים.
אם Cloud Storage נמצא ב Google Cloud פרויקט אחר, צריך להעניק גישה כדי לאפשר ל-Document AI לקרוא קבצים מהמיקום הזה. באופן ספציפי, עליך להעניק לסוכן השירות הראשי של Document AI service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com את התפקיד Storage Object Viewer. למידע נוסף, קראו את המאמר סוכני שירות.
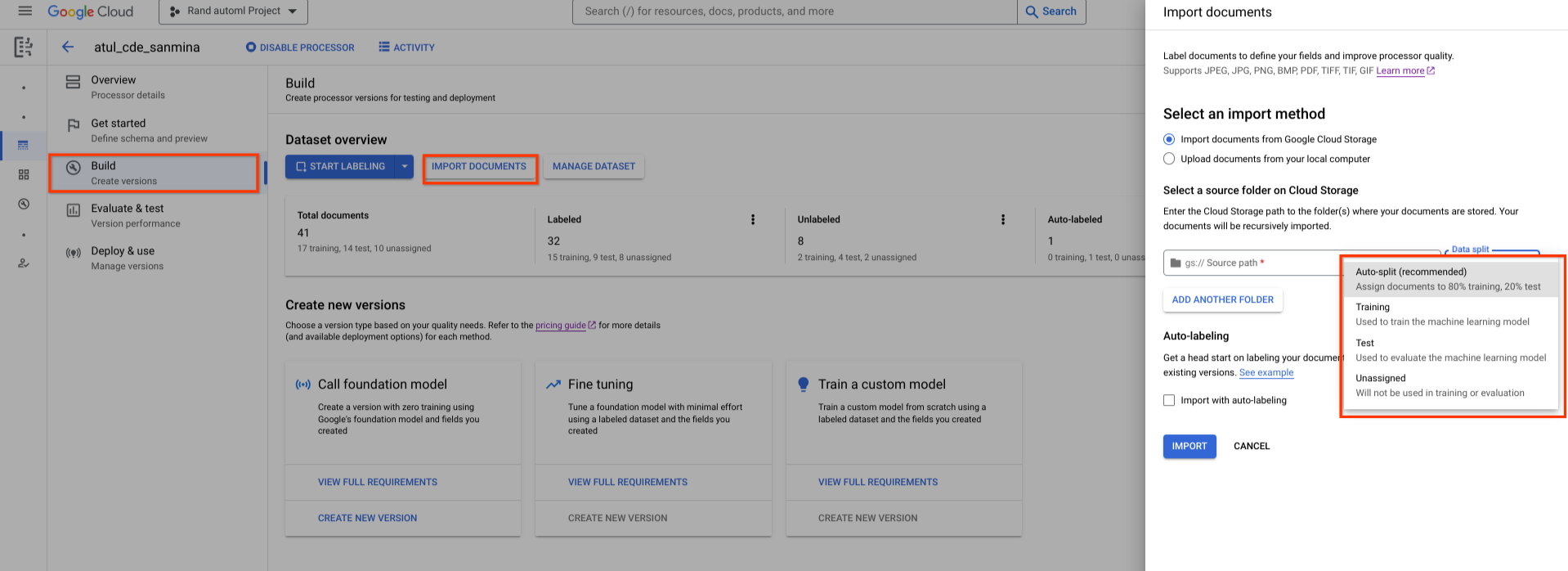
לאחר מכן, בוחרים באחת מהאפשרויות הבאות להקצאת הרשאות:
- אימון: הקצאה לקבוצת נתונים לאימון.
- בדיקה: הקצאה לקבוצת נתונים לבדיקה.
- פיצול אוטומטי: ערבוב אקראי של מסמכים במערך האימונים ובקבוצת הנתונים לבדיקה.
- לא הוקצה: לא נעשה בו שימוש באימון או בהערכה. אפשר להקצות אותם ידנית מאוחר יותר.
תמיד אפשר לשנות את ההקצאות בהמשך.
כשבוחרים באפשרות ייבוא, מערכת Document AI מייבאת את כל סוגי הקבצים הנתמכים וגם קובצי JSON Document למערך הנתונים. בקובצי JSON Document, Document AI מייבא את המסמך וממיר את entities למופעים של תוויות.
Document AI לא משנה את תיקיית הייבוא ולא קורא ממנה אחרי שהייבוא מסתיים.
לוחצים על פעילות בחלק העליון של הדף כדי לפתוח את החלונית פעילות, שבה מפורטים הקבצים שיובאו בהצלחה וגם הקבצים שלא יובאו.
אם כבר יש לכם גרסה קיימת של המעבד, אתם יכולים לסמן את תיבת הסימון ייבוא עם תיוג אוטומטי בתיבת הדו-שיח ייבוא מסמכים. המסמכים מקבלים תווית אוטומטית באמצעות המעבד הקודם כשהם מיובאים. אי אפשר לאמן או לשפר את האימון של מסמכים עם תוויות אוטומטיות, או להשתמש בהם במערך הבדיקה, בלי לסמן אותם כמסמכים עם תוויות. אחרי שמייבאים מסמכים עם תיוג אוטומטי, צריך לבדוק ולתקן אותם באופן ידני. לאחר מכן, לוחצים על שמירה כדי לשמור את התיקונים ולסמן את המסמך כמתויג. לאחר מכן תוכלו להקצות את המסמכים לפי הצורך. מידע נוסף על תיוג אוטומטי
ייבוא מסמכים RPC
בדוגמה הזו מוצג איך משתמשים בשיטה dataset.importDocuments כדי לייבא מסמכים למערך הנתונים.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
מערך נתונים לאימון או לבדיקה
אם רוצים להוסיף מסמכים לקבוצת הנתונים של האימון או של הבדיקה:
שיטת HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsבקשת JSON:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}מערך נתונים לאימון ולבדיקה
אם רוצים לפצל אוטומטית את המסמכים בין קבוצת הנתונים של האימון לבין קבוצת הנתונים של הבדיקה:
שיטת HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsבקשת JSON:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}מחיקת מסמכים RPC
בדוגמה הזו מוסבר איך להשתמש בשיטה dataset.batchDeleteDocuments כדי למחוק מסמכים ממערך הנתונים.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
מחיקת מסמכים
שיטת HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsבקשת JSON:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}הקצאת מסמכים לקבוצת אימון או לקבוצת נתונים לבדיקה
בקטע חלוקת נתונים, בוחרים מסמכים ומקצים אותם לקבוצת נתונים לאימון, לקבוצת נתונים לבדיקה או לקבוצה שלא הוקצתה.
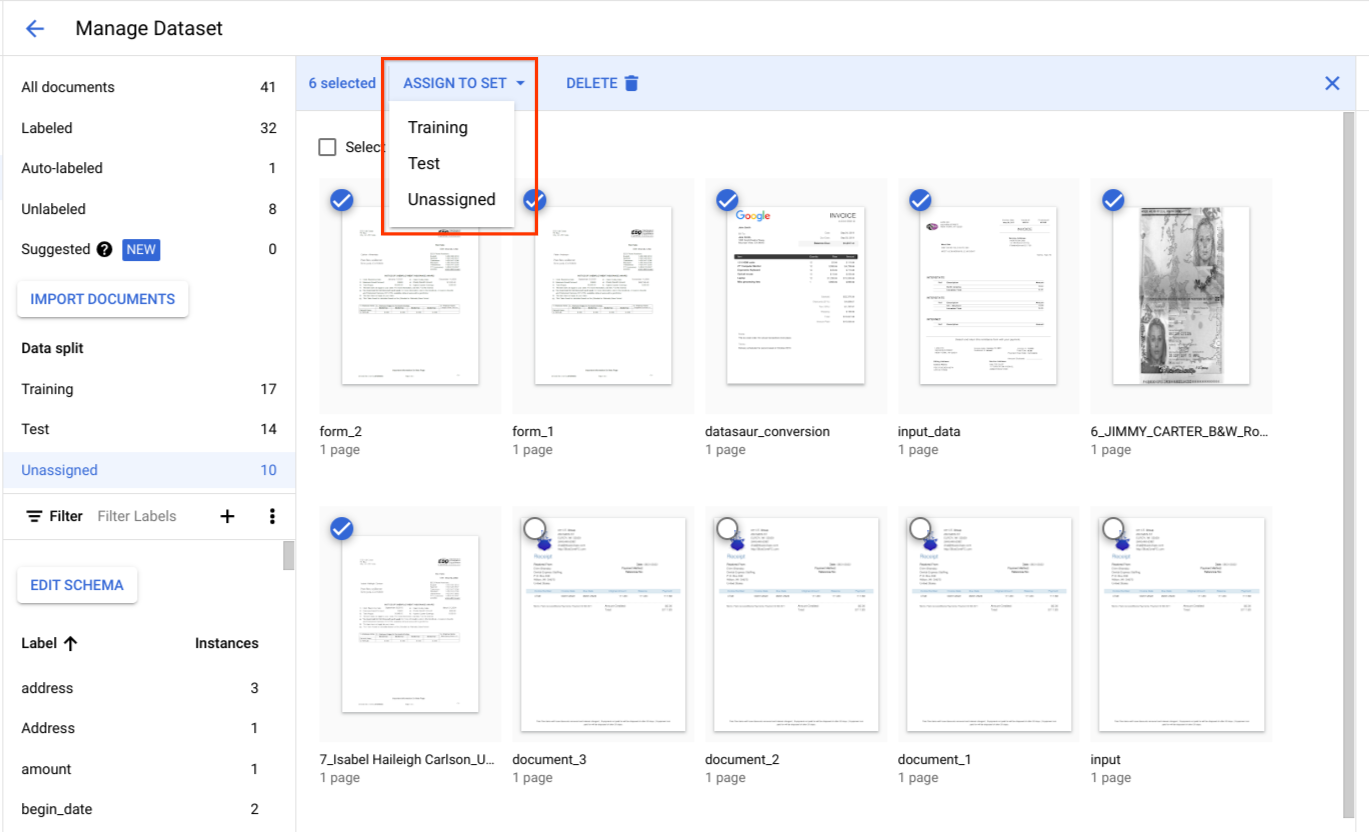
שיטות מומלצות לגבי קבוצת נתונים לבדיקה
איכות קבוצת הנתונים לבדיקה קובעת את איכות ההערכה.
צריך ליצור את קבוצת הנתונים לבדיקה בתחילת מחזור הפיתוח של המעבד ולנעול אותו כדי שתוכלו לעקוב אחרי איכות המעבד לאורך זמן.
מומלץ להשתמש ב-100 מסמכים לפחות לכל סוג מסמך בקבוצת נתונים לבדיקה. חשוב מאוד לוודא שקבוצת הנתונים לבדיקה מייצגת את סוגי המסמכים שהלקוחות משתמשים בהם עבור המודל שמפותח.
קבוצת נתונים לבדיקה צריכה לייצג את תנועת הייצור מבחינת התדירות. לדוגמה, אם אתם מעבדים טופסי W2 ומצפים ש-70% מהם יהיו משנת 2020 ו-30% משנת 2019, אז כ-70% מקבוצת הנתונים לבדיקה צריכים לכלול מסמכי W2 משנת 2020. הרכב כזה של קבוצת נתונים לבדיקה מבטיח שתינתן חשיבות מתאימה לכל סוג משנה של מסמך בעת הערכת הביצועים של המעבד. בנוסף, אם אתם מחלצים שמות של אנשים מטפסים בינלאומיים, חשוב לוודא שקבוצת נתונים לבדיקה כוללת טפסים מכל המדינות המטורגטות.
שיטות מומלצות לגבי קבוצת נתונים לאימון
מסמכים שכבר נכללו בקבוצת נתונים לבדיקה לא צריכים להיכלל בקבוצת נתונים לאימון.
בניגוד לקבוצת נתונים לבדיקה, קבוצת נתונים לאימון הסופי לא צריכה להיות מייצגת באופן מדויק של השימוש של הלקוח מבחינת מגוון המסמכים או התדירות שלהם. יש תוויות שקשה יותר לאמן מאחרות. לכן, יכול להיות שתקבלו ביצועים טובים יותר אם תטו את קבוצת הנתונים לאימון לכיוון התוויות האלה.
בהתחלה, אין דרך טובה לדעת אילו תוויות קשות. כדאי להתחיל עם קבוצת נתונים לאימון ראשונית קטנה שנבחרה באופן אקראי, באותה שיטה שמתוארת לגבי קבוצת נתונים לבדיקה. קבוצת נתונים לאימון ראשונית זו צריכה להכיל בערך 10% מהמספר הכולל של המסמכים שאתם מתכננים להוסיף להם הערות. לאחר מכן, תוכלו להעריך באופן איטרטיבי את איכות המעבד (לחפש דפוסי שגיאות ספציפיים) ולהוסיף עוד נתוני אימון.
הגדרת סכימת המעבד
אחרי שיוצרים קבוצת נתונים, אפשר להגדיר סכימה של מעבד לפני או אחרי שמייבאים מסמכים.
מעבד הנתונים schema מגדיר את התוויות, כמו שם וכתובת, לחילוץ מהמסמכים.
בוחרים באפשרות עריכת סכימה ואז יוצרים, עורכים, מפעילים ומשביתים תוויות לפי הצורך.
בסיום, לוחצים על שמירה.
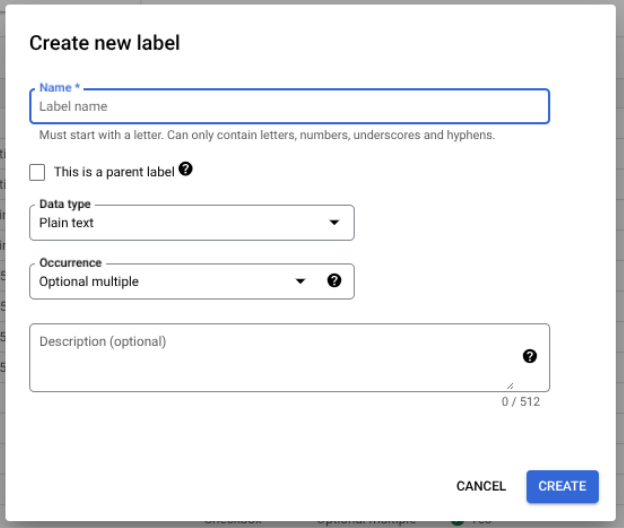
הערות לגבי ניהול תוויות של סכימות:
אחרי שיוצרים תווית סכימה, אי אפשר לערוך את השם שלה.
אפשר לערוך או למחוק תווית סכימה רק אם אין מעבדים מאומנים בגרסה. אפשר לערוך רק את סוג הנתונים ואת סוג המופע.
השבתה של תווית גם לא משפיעה על החיזוי. כששולחים בקשת עיבוד, הגרסה של המעבד מחלצת את כל התוויות שהיו פעילות בזמן האימון.
קבלת סכימת נתונים
בדוגמה הזו מוצג אופן השימוש במערך הנתונים.
getDatasetSchema
כדי לקבל את הסכימה הנוכחית. DatasetSchema הוא משאב יחידני, שנוצר באופן אוטומטי כשיוצרים משאב של מערך נתונים.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
קבלת סכימת נתונים
שיטת HTTP
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"אתם אמורים לקבל תגובת JSON שדומה לזו:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}עדכון סכימת המסמך
בדוגמה הזו מוצג איך להשתמש ב-dataset.updateDatasetSchema כדי לעדכן את הסכימה הנוכחית. בדוגמה הזו מוצגת פקודה לעדכון סכימת מערך הנתונים כך שתהיה לה תווית אחת. אם רוצים להוסיף תווית חדשה ולא למחוק או לעדכן תוויות קיימות, אפשר קודם להתקשר אל getDatasetSchema ולבצע את השינויים המתאימים בתגובה שלו.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
עדכון הסכימה
שיטת HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaבקשת JSON:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}שומרים את גוף הבקשה בקובץ בשם request.json ומריצים את הפקודה הבאה:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"בחירת מאפייני התוויות
סוג הנתונים
-
Plain text: ערך מחרוזת. -
Number: מספר – שלם או בשיטת נקודה צפה. -
Money: סכום כספי. כשמוסיפים תווית, לא כוללים את סמל המטבע.- כשהישות מחולצת, היא עוברת נורמליזציה ל-
google.type.Money.
- כשהישות מחולצת, היא עוברת נורמליזציה ל-
-
Currency: סמל מטבע. -
Datetime: ערך של תאריך או שעה.- כשהישות מחולצת, היא עוברת נורמליזציה לפורמט הטקסט
ISO 8601.
- כשהישות מחולצת, היא עוברת נורמליזציה לפורמט הטקסט
-
Address– כתובת של מיקום.- כשהישות מחולצת, היא עוברת נורמליזציה ומועשרת ב-EKG.
-
Checkbox– ערך בוליאניtrueאוfalse. -
Signature– ערך בוליאניtrueאוfalseב-normalized_value.signature_valueשמציין אם יש חתימה. הוא תומך בשיטותderive. -
mention_text– ערך בוליאניDetectedאו""ריק ב-has_signedשמציין אם יש חתימה. הוא תומך בשיטותderive. -
normalized_value.text– ערך בוליאניDetectedאו""ריק ב-has_signedשמציין אם יש חתימה. הוא תומך בשיטותderive. - השדה
normalized_value.boolean_valueלא מאוכלס.
שיטת המשלוח
- כשהישות היא
extracted, השדותtextAnchor,type,mentionTextו-pageAnchorמאוכלסים. - כשהישות היא
derived, יכול להיות שהערכים הנגזרים לא יופיעו בטקסט של המסמך. השדותtextAnchorו-pageAnchor.pageRefs[].bounding_polyלא מאוכלסים.
מופע
בוחרים באפשרות REQUIRED אם יש ציפייה שישות תמיד תופיע במסמכים מסוג מסוים. בוחרים באפשרות OPTIONAL אם לא ציפיתם לכך.
בוחרים באפשרות ONCE אם לישות צפוי להיות ערך אחד, גם אם אותו ערך מופיע כמה פעמים באותו מסמך. בוחרים באפשרות MULTIPLE אם צפוי שליישות יהיו כמה ערכים.
תוויות ראשיות ותוויות משניות
תוויות הורה-צאצא (שנקראות גם ישויות טבלאיות) משמשות לתווית נתונים בטבלה. הטבלה הבאה מכילה 3 שורות ו-4 עמודות.

אפשר להגדיר טבלאות כאלה באמצעות תוויות הורה-צאצא. בדוגמה הזו, תווית האב line-item מגדירה שורה בטבלה.
יצירת תווית אב
בדף עריכת סכימה, לוחצים על יצירת תווית.
מסמנים את התיבה זוהי תווית הורה ומזינים את שאר הפרטים. בתווית האב צריך להופיע
optional_multipleאוrequire_multipleכדי שאפשר יהיה לחזור עליה ולתפוס את כל השורות בטבלה.לוחצים על שמירה.
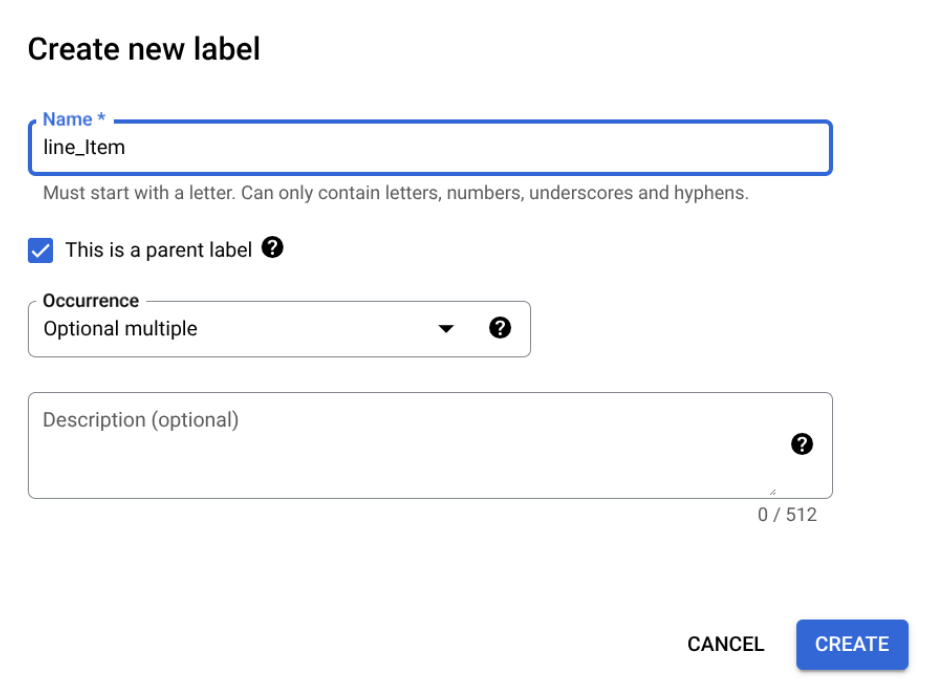
תווית האב מופיעה בדף עריכת סכימה, עם האפשרות הוספת תווית צאצא לצדה.
כדי ליצור תווית צאצא
לצד תווית ההורה בדף עריכת סכימה, לוחצים על הוספת תווית צאצא.
מזינים את הפרטים של תווית הילד.
לוחצים על שמירה.
חוזרים על הפעולה לכל תווית צאצא שרוצים להוסיף.
תוויות הצאצא מופיעות עם כניסה מתחת לתווית ההורה בדף עריכת סכימה.

תוויות הורה-צאצא הן תכונה בגרסת טרום-השקה והן נתמכות רק בטבלאות. עומק הקינון מוגבל ל-1, כלומר ישויות צאצא לא יכולות להכיל ישויות צאצא אחרות.
יצירת תוויות סכימה ממסמכים עם תוויות
יצירה אוטומטית של תוויות סכימה על ידי ייבוא קובצי JSON של Document עם תוויות מוכנות מראש.
במהלך הייבוא של Document, תוויות סכימה חדשות שנוספו מתווספות לכלי לעריכת סכימות. בוחרים באפשרות 'עריכת סכימה' כדי לבדוק או לשנות את סוג הנתונים ואת סוג המופע של התוויות החדשות בסכימה. אחרי האישור, בוחרים תוויות סכמה ולוחצים על הפעלה.
מערכי נתונים לדוגמה
כדי לעזור לכם להתחיל להשתמש ב-Document AI Workbench, אנחנו מספקים מערכי נתונים בקטגוריה ציבורית ב-Cloud Storage, שכוללת קובצי JSON לדוגמה של Document מסוגים שונים של מסמכים, עם תוויות וללא תוויות.
אפשר להשתמש בהם לאימון נוסף או לכלי חילוץ מותאמים אישית, בהתאם לסוג המסמך.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/