
מפצל מותאם אישית
הכלי לפיצול בהתאמה אישית נועד לפצל מסמכים מורכבים (מסמכים שמורכבים מכמה סוגים) למספר מסמכים מסוג יחיד, על ידי זיהוי כל מסמך לוגי. לדוגמה, חבילת משכנתא מכילה כמה סוגים של מסמכים, כמו בקשה, אימות הכנסה ותעודה מזהה עם תמונה. אפשר להשתמש במעבדי פיצול מותאמים אישית כמו שהם, או לאמן אותם מאפס באמצעות מסמכים משלכם ומחלקות מותאמות אישית.
תיאור של ה-Splitter ושימוש בו
אתם יכולים ליצור מפצלי טקסט בהתאמה אישית שמתאימים במיוחד למסמכים שלכם, שאומנו והוערכו באמצעות הנתונים שלכם, או לפרוס מודלים שאומנו מראש באמצעות AI גנרטיבי. מעבדים כאלה מזהים סוגים של מסמכים מתוך קבוצה של סוגים שהוגדרה על ידי המשתמש. אחר כך תוכלו להשתמש במעבדים האלה במסמכים שלכם. בדרך כלל משתמשים במפצל מותאם אישית בקבצים שמורכבים מסוגים שונים של מסמכים לוגיים, ואז משתמשים בזיהוי המחלקה של כל אחד מהם כדי להעביר את המסמכים למעבד חילוץ מתאים לחילוץ הישויות.
מודלים של ML לא מושלמים ויש להם שיעור שגיאות מסוים, ושגיאות בפיצול הן בדרך כלל בעייתיות מאוד (פיצול שגוי גורם לשני מסמכים שגויים ומוביל לשגיאות בחילוץ). לכן, מומלץ תמיד לבצע בדיקה על ידי בודק אנושי אחרי חיזוי הפיצול ולפני הפיצול בפועל של הקובץ. בהתאם לדרישות העסקיות, יש חלופות לבדיקה אנושית:
- להשתמש בציוני ודאות בתחזית כדי להחליט אם לדלג על בדיקה אנושית (אם ציון הוודאות גבוה מספיק). צריך לקבוע את סף ניקוד הסמך על סמך נתונים היסטוריים לגבי שיעורי השגיאות בניקוד סמך נתון. זו צריכה להיות החלטה עסקית שמבוססת על הסבילות של התהליך העסקי לשגיאות ועל הדרישה לעקוף בדיקה אנושית.
- במקרים מסוימים, אפשר להפנות את המסמכים המפוצלים ישירות לחילוץ המתאים לפי הסיווג החזוי. לאחר מכן, אם החילוץ לא הושלם או אם ציוני רמת הסמך נמוכים, מבודדים את המסמכים המפוצלים ומפעילים את המסמך המורכב המקורי ואת ההחלטה על הפיצול כדי לבדוק אותם. יש כאן דרישות מורכבות למדי לתהליך העבודה.
גרסאות של מודלים מותאמים אישית לפיצול
המודלים הבאים זמינים לפיצול מותאם אישית. כדי לשנות את גרסאות המודלים, אפשר לעיין במאמר בנושא ניהול גרסאות המעבד.
גרסה 1.5 תומכת בציוני מהימנות.
| גרסת המודל | תיאור | ערוץ הפצה | תאריך הפצה |
|---|---|---|---|
pretrained-splitter-v1.5-2025-07-14 |
מודל GA שמבוסס על מודל שפה גדול (LLM) של Gemini 2.5 Flash. אפשר להשתמש במודל הזה שעבר אימון מראש בלי לבצע אימון מוקדם. היא תומכת בפילוח ובסיווג ללא דוגמאות. | יציב | 14 ביולי 2025 |
pretrained-splitter-v1.6-2026-03-09 |
גרסת קדם-הפצה שמבוססת על מודל שפה גדול (LLM) של Gemini 3.1 Flash. | גרסה מועמדת להפצה | 9 במרץ 2026 |
pretrained-splitter-v1.6-pro-2026-03-09 |
גרסה מועמדת להפצה שמבוססת על מודל שפה גדול (LLM) של Gemini 3.1 Pro. | גרסה מועמדת להפצה | 9 במרץ 2026 |
כדי לשלוח בקשה להגדלת המכסה (QIR) של מכסת ברירת המחדל של המעבד, פועלים לפי השלבים לבקשת שינוי מכסות.
בחירה של גרסה מותאמת אישית של מפצל
כשמשתמשים בכלי לפיצול בהתאמה אישית, אפשר לאמן את המודל על הנתונים שלכם או להשתמש בגרסה שאומנה מראש עם AI גנרטיבי, כמו pretrained-splitter-v1.5-2025-07-14.
תהליך האימון יכול להימשך כמה שעות, אבל הוא מאפשר לכם להתאים את המודל לפרטים הספציפיים של הנתונים שלכם. גרסאות שאומנו מראש מבוססות על מודלים של Gemini. אפשר להעביר אותם לסביבת הייצור תוך זמן קצר יותר, או להשתמש בהם כדי לבצע איטרציות ולבדוק במהירות סכימת תיוג. הם לא דורשים מערך נתונים לאימון.
המדריך הבא רלוונטי לשתי הגרסאות, ובמקרים שבהם יש הבדלים בין השלבים, נציין זאת.
יצירת מפצל בהתאמה אישית במסוף Google Cloud
במדריך הזה מוסבר איך להשתמש ב-Document AI כדי ליצור וללמד מפצל מותאם אישית שמפצל ומסווג מסמכי רכש. רוב ההכנה של המסמך כבר נעשתה, כך שתוכלו להתמקד ביצירת מפצל בהתאמה אישית.
תהליך העבודה האופייני ליצירה ולשימוש בגרסת בסיס של מפצל בהתאמה אישית שעברה אימון הוא כדלקמן:
- יצירת מפצל בהתאמה אישית ב-Document AI.
- יצירת מערך נתונים באמצעות קטגוריה ריקה של Cloud Storage.
- הגדרת סכימת המעבד (סוגים) ויצירה שלה.
- ייבוא מסמכים.
- הקצאת מסמכים למערכי האימון והבדיקה.
- להוסיף הערות למסמכים באופן ידני ב-Document AI או באמצעות משימות תיוג.
- מאמנים את המעבד.
- הערכת המעבד.
- פורסים את המעבד.
- בודקים את המעבד.
- שימוש במעבד במסמכים.
תהליך העבודה הרגיל ליצירה ולשימוש בגרסה של מפצל בהתאמה אישית שעברה אימון מראש הוא כזה:
- יצירת מפצל בהתאמה אישית ב-Document AI.
- יצירת מערך נתונים באמצעות קטגוריה ריקה של Cloud Storage.
- בחירת גרסה של מודל שעבר אימון מראש
- הגדרת סכימת המעבד (סוגים) ויצירה שלה.
- (אופציונלי) מייבאים מסמכים.
- (אופציונלי, אם רוצים להעריך את הביצועים) מקצים מסמכים לקבוצות הבדיקה
- (אופציונלי) מעריכים את המעבד.
- בודקים את המעבד.
- פורסים את המעבד.
- שימוש במעבד במסמכים.
לחצו על תראו לי איך כדי לקרוא הסבר מפורט על המשימה ישירות במסוף Google Cloud :
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
If you're using an existing project for this guide, verify that you have the permissions required to complete this guide. If you created a new project, then you already have the required permissions.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
התפקידים הנדרשים
כדי לקבל את ההרשאות שדרושות ליצירת מפצל בהתאמה אישית, צריך לבקש מהאדמין להקצות לכם את תפקידי ה-IAM הבאים בפרויקט:
- אדמין של Document AI (
roles/documentai.admin) - אדמין באחסון (
roles/storage.admin)
להסבר על מתן תפקידים, ראו איך מנהלים את הגישה ברמת הפרויקט, התיקייה והארגון.
יכול להיות שאפשר לקבל את ההרשאות הנדרשות גם באמצעות תפקידים בהתאמה אישית או תפקידים מוגדרים מראש.
יצירת מעבד
במסוף Google Cloud , בקטע Document AI, עוברים לדף Workbench.
בקטע Custom Document Splitter (מפצל מסמכים בהתאמה אישית), לוחצים על
Create processor (יצירת מעבד).
בתפריט Create processor, מזינים שם למעבד, למשל
my-custom-document-splitter.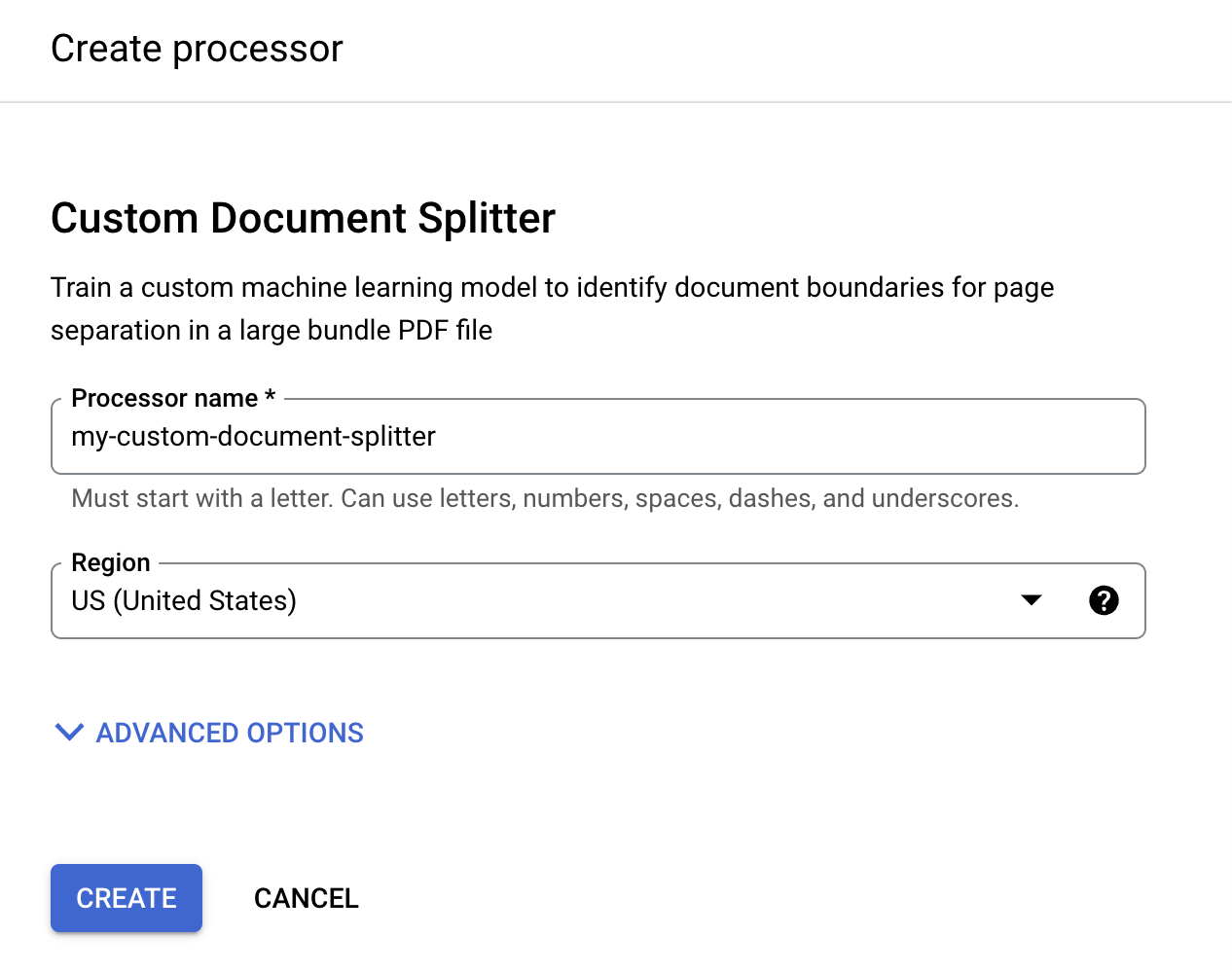
בוחרים את האזור שהכי קרוב אליכם.
לוחצים על יצירה. מופיעה הכרטיסייה פרטי המעבד.
הגדרת מערך נתונים
כדי לאמן את המעבד החדש הזה, צריך ליצור מערך נתונים עם נתוני אימון ובדיקה שיעזרו למעבד לזהות את המסמכים שרוצים לפצל ולסווג.
מערך הנתונים הזה צריך מיקום חדש. זה יכול להיות מאגר Cloud Storage או תיקייה ריקים, או שתוכלו לאפשר מיקום בניהול Google (פנימי).
- אם רוצים אחסון בניהול Google, בוחרים באפשרות הזו.
- אם אתם רוצים להשתמש באחסון משלכם כדי להשתמש במפתחות הצפנה בניהול הלקוח (CMEK), בוחרים באפשרות I'll specify my own storage location (אציין מיקום אחסון משלי) ופועלים לפי ההוראות בהמשך.

יצירת קטגוריה של Cloud Storage למערך הנתונים
עוברים לכרטיסייה
Train (אימון) של המעבד.בוחרים באפשרות הגדרת מיקום מערך הנתונים. תתבקשו לבחור או ליצור קטגוריה של Cloud Storage או תיקייה ריקה.
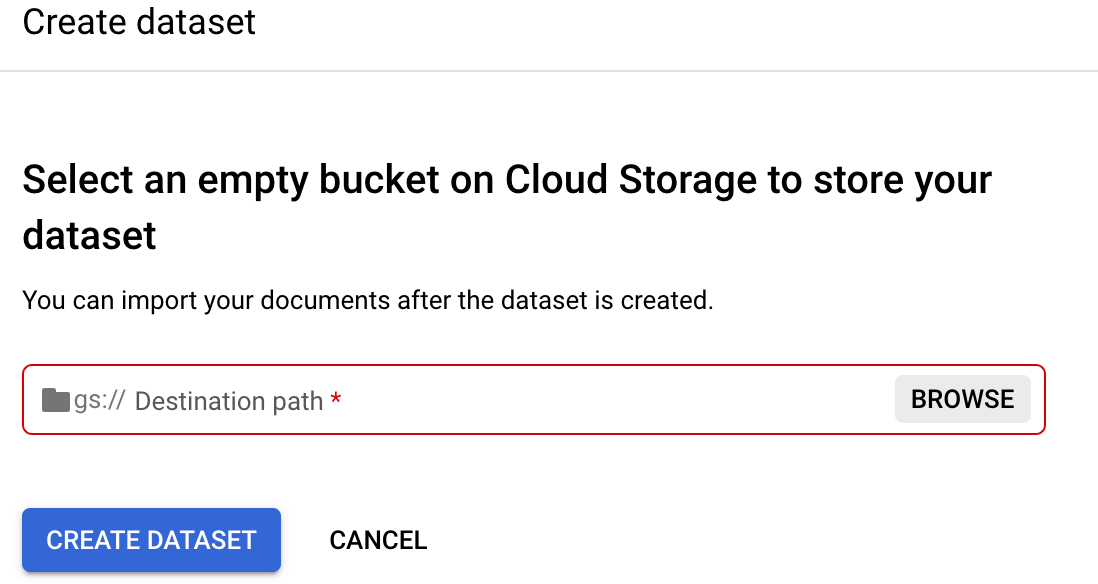
לוחצים על עיון כדי לפתוח את בחירת תיקייה.
לוחצים על הסמל Create a new bucket (יצירת קטגוריה חדשה) ופועלים לפי ההנחיות ליצירת קטגוריה חדשה. אחרי שיוצרים את הקטגוריה, מופיע הדף Select folder. מידע נוסף על יצירת קטגוריית Cloud Storage זמין במאמר קטגוריות של Cloud Storage.
בדף Select folder של ה-bucket, לוחצים על Select button בתחתית תיבת הדו-שיח.
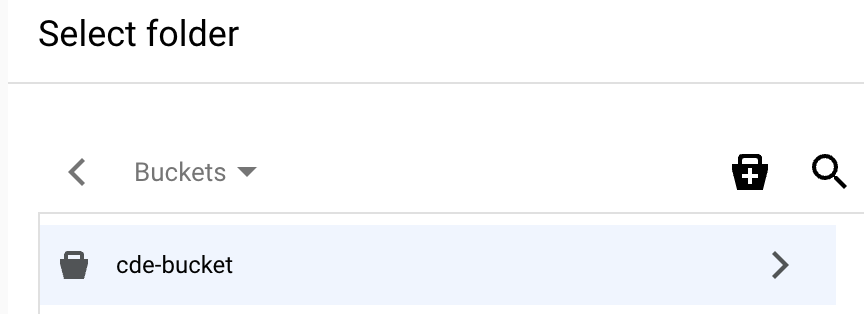
מוודאים שנתיב היעד מאוכלס בשם של קטגוריית ה-bucket שבחרתם. לוחצים על יצירת מערך נתונים. יכול להיות שיחלפו כמה דקות עד שערכת הנתונים תיווצר.
(אופציונלי) בוחרים גרסה של מודל שעבר אימון מראש
אם החלטתם להשתמש במודל שאומן מראש, אתם צריכים קודם לבחור אותו בקטע Deploy and use (פריסה ושימוש). אפשר להתעלם מהקטעים שאחרי הקטע הבא, 'הגדרת סכימת מעבד'.
עוברים אל Deploy and use (פריסה ושימוש).
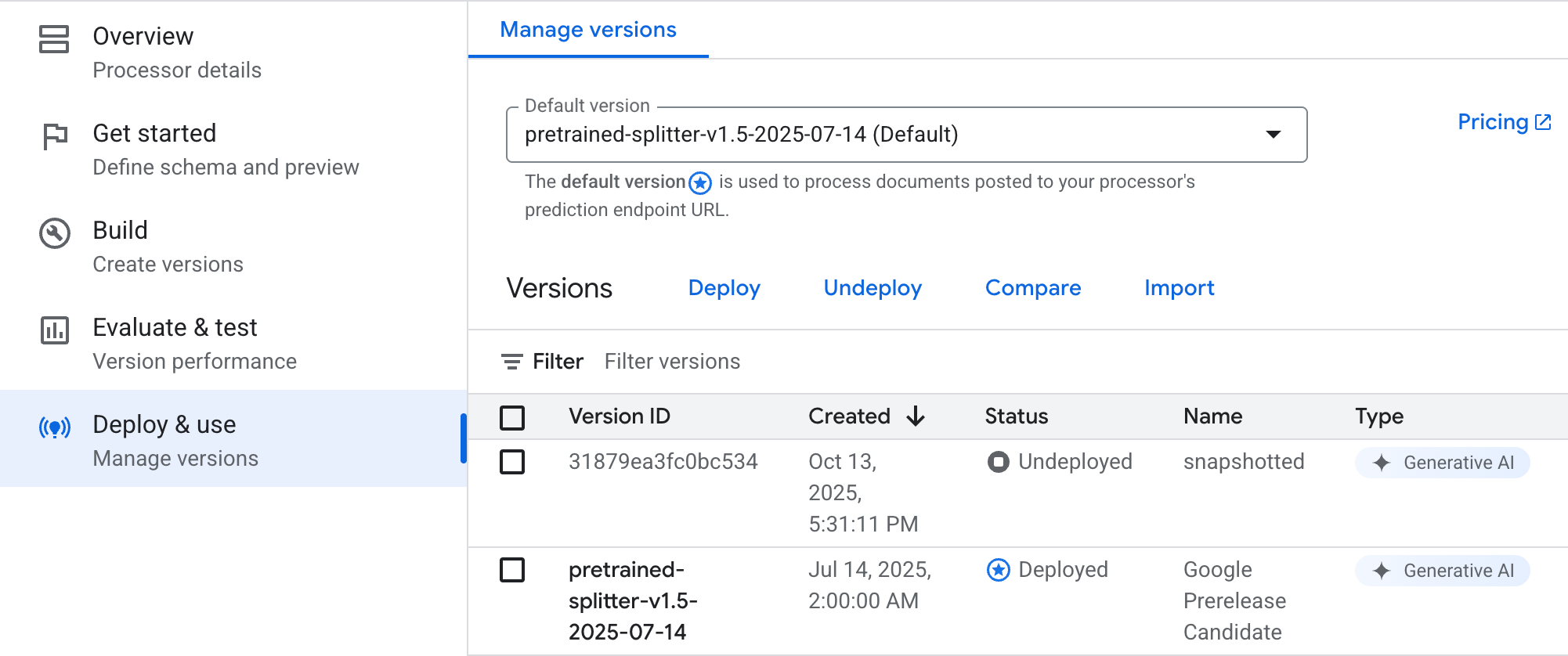
לוחצים על התפריט הנפתח ניהול גרסאות.
בוחרים את גרסת המעבד הרצויה.
הגדרת סכימת המעבד
אפשר ליצור את סכימת המעבד לפני או אחרי שמייבאים מסמכים למערך הנתונים. הסכימה מספקת תוויות שמשמשות להוספת הערות למסמכים.
בכרטיסייה Build (יצירה), לוחצים על Manage dataset (ניהול מערך נתונים). ייפתח הדף לניהול קבוצת הנתונים.
בוחרים באפשרות
עריכת סכימה .בוחרים באפשרות
יצירת תווית ומזינים את שם התווית. לוחצים על יצירה. הוראות מפורטות ליצירה ולעריכה של סכימה זמינות במאמר הגדרת סכימת מעבד.צריך ליצור כל אחת מהתוויות הבאות לסכימת המעבד.
bank_statementform_1040form_w2form_w9paystub
כשמסיימים להוסיף את התוויות, לוחצים על
שמירה .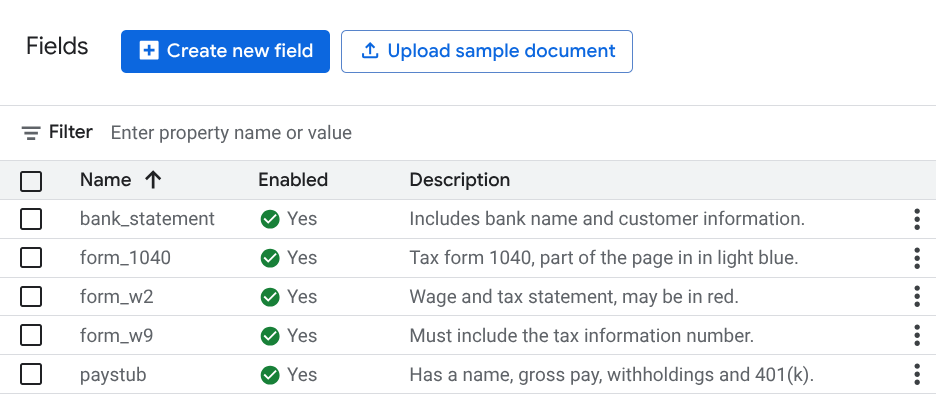
ייבוא מסמך לא מתויג למערך נתונים
השלב הבא הוא להתחיל לייבא מסמכים לא מסומנים למערך הנתונים ולסמן אותם. אפשרות חלופית מומלצת היא לייבא מסמכים שמסודרים בתיקיות לפי כיתה, אם יש אפשרות כזו.
אם אתם עובדים על פרויקט משלכם, אתם קובעים איך לתייג את הנתונים. אפשר לעיין באפשרויות התיוג.
מעבדים בהתאמה אישית ב-Document AI דורשים מינימום של 10 מסמכים בקבוצות האימון והבדיקה, ו-10 מקרים של כל תווית בכל קבוצה. כדי להשיג את הביצועים הכי טובים, מומלץ לכלול לפחות 50 מסמכים בכל קבוצה, עם 50 מקרים של כל תווית. באופן כללי, ככל שיש יותר נתוני אימון, כך רמת הדיוק גבוהה יותר.
בכרטיסייה Train (אימון), בוחרים באפשרות
Import documents (ייבוא מסמכים).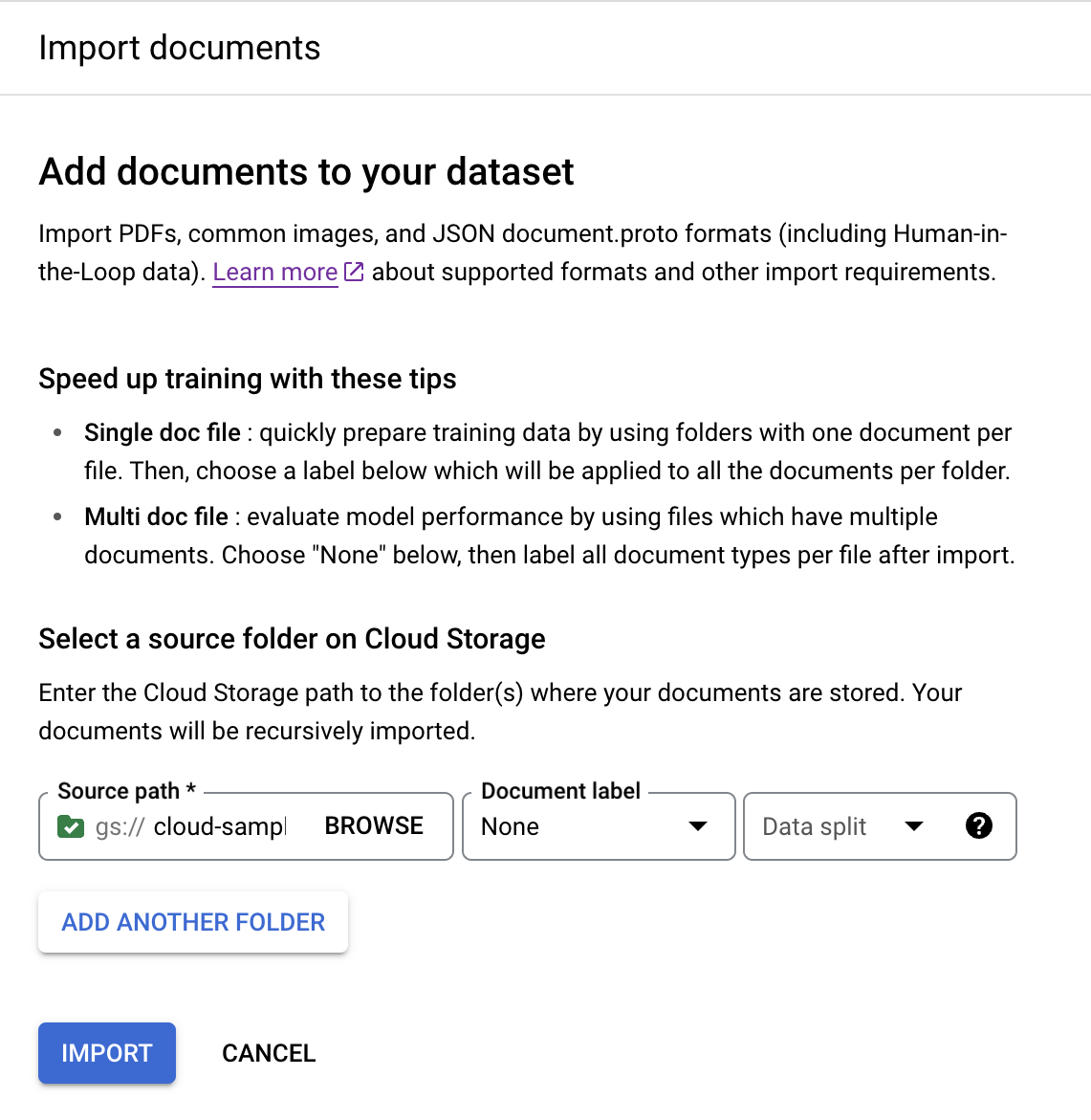
בדוגמה הזו, מזינים את הנתיב הזה ב
נתיב המקור . הוא מכיל קובץ PDF אחד של מסמך.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-Unlabeledמגדירים את
תווית המסמך לערך ללא.בתפריט הנפתח
פיצול מערך הנתונים בוחרים באפשרות לא הוקצה.כברירת מחדל, לא מוקצית תווית למסמך בתיקייה הזו, והוא לא משויך לקבוצת הבדיקה או לקבוצת האימון.
בוחרים באפשרות
ייבוא . Document AI קורא את המסמכים מהמאגר לתוך מערך הנתונים. היא לא משנה את דלי הייבוא או קוראת מהדלי אחרי שהייבוא מסתיים.
כשמייבאים מסמכים, אפשר להקצות אותם לקבוצת האימון או לקבוצת הבדיקה בזמן הייבוא, או להקצות אותם מאוחר יותר.
כדי למחוק מסמך או מסמכים שייבאתם, בוחרים אותם בכרטיסייה אימון ולוחצים על מחיקה.
מידע נוסף על הכנת הנתונים לייבוא זמין במדריך להכנת נתונים.
אופציונלי: תיוג קבוצתי של מסמכים במהלך הייבוא
כדי לחסוך זמן בתיוג, אפשר לתייג את כל המסמכים שנמצאים בספרייה מסוימת במהלך הייבוא. אם מסמכי האימון שלכם מאורגנים לפי כיתה בתיקיות, אתם יכולים להשתמש בשדה תווית המסמך כדי לציין את הכיתה של המסמכים האלה, וכך להימנע מהוספת תוויות לכל מסמך באופן ידני.
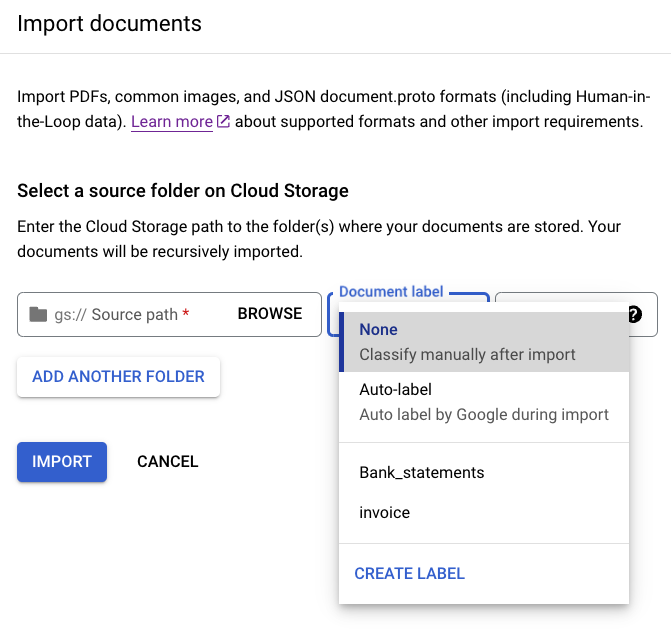
בתמונה, התוויות המוגדרות Bank_statements ו-Invoice (סוגי מסמכים) זמינות לבחירה. אפשר גם להשתמש ב-CREATE LABEL ולהגדיר מחלקה חדשה.
- לוחצים על ייבוא מסמכים.
מזינים את הנתיב הבא בנתיב המקור. המאגר הזה מכיל מסמכים לא מסומנים בפורמט PDF.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelברשימה פיצול נתונים, בוחרים באפשרות פיצול אוטומטי. המסמכים יפוצלו אוטומטית כך ש-80% מהם יהיו בקבוצת נתונים לאימון ו-20% בקבוצת נתונים לבדיקה.
בקטע החלת תוויות, בוחרים באפשרות בחירת תווית.
למסמכים לדוגמה האלה, בוחרים באפשרות 'אחר'.
לוחצים על ייבוא וממתינים לייבוא המסמכים. אפשר לצאת מהדף ולחזור אליו מאוחר יותר.
הוספת תוויות למסמך
התהליך של הוספת תוויות למסמך נקרא הערה.
חוזרים לכרטיסייה Train ובוחרים באפשרות
a document כדי לפתוח את מסוף Label management.המסמך הזה מכיל כמה קבוצות של דפים שצריך לזהות ולתייג. קודם כול צריך לזהות את נקודות הפיצול. מעבירים את העכבר בין הדפים 1 ו-2 בתצוגת התמונה ולוחצים על
הסמל + .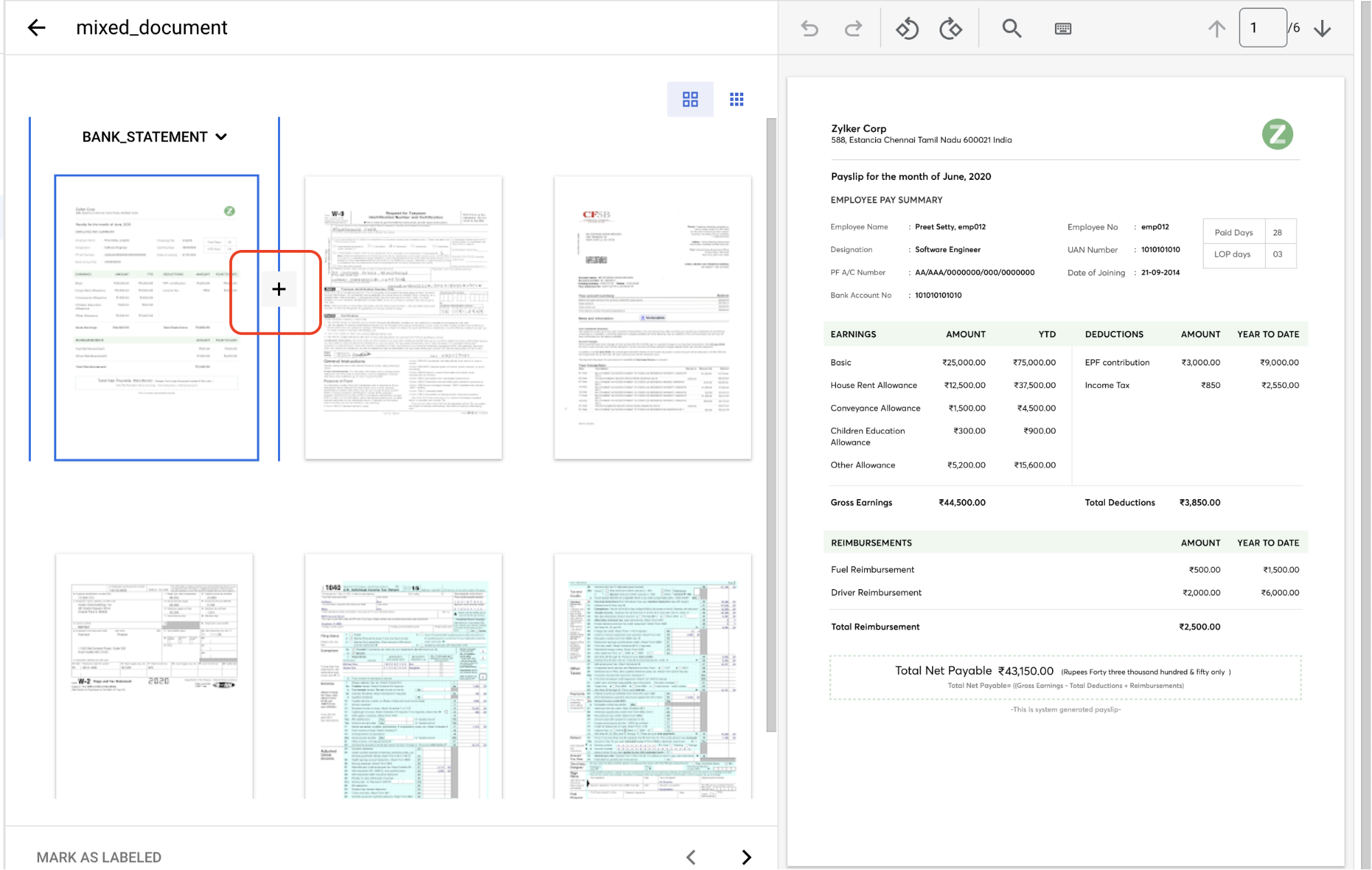
יוצרים נקודות פיצול לפני מספרי העמודים הבאים: 2, 3, 4, 5.
בסיום, המסוף אמור להיראות כך.
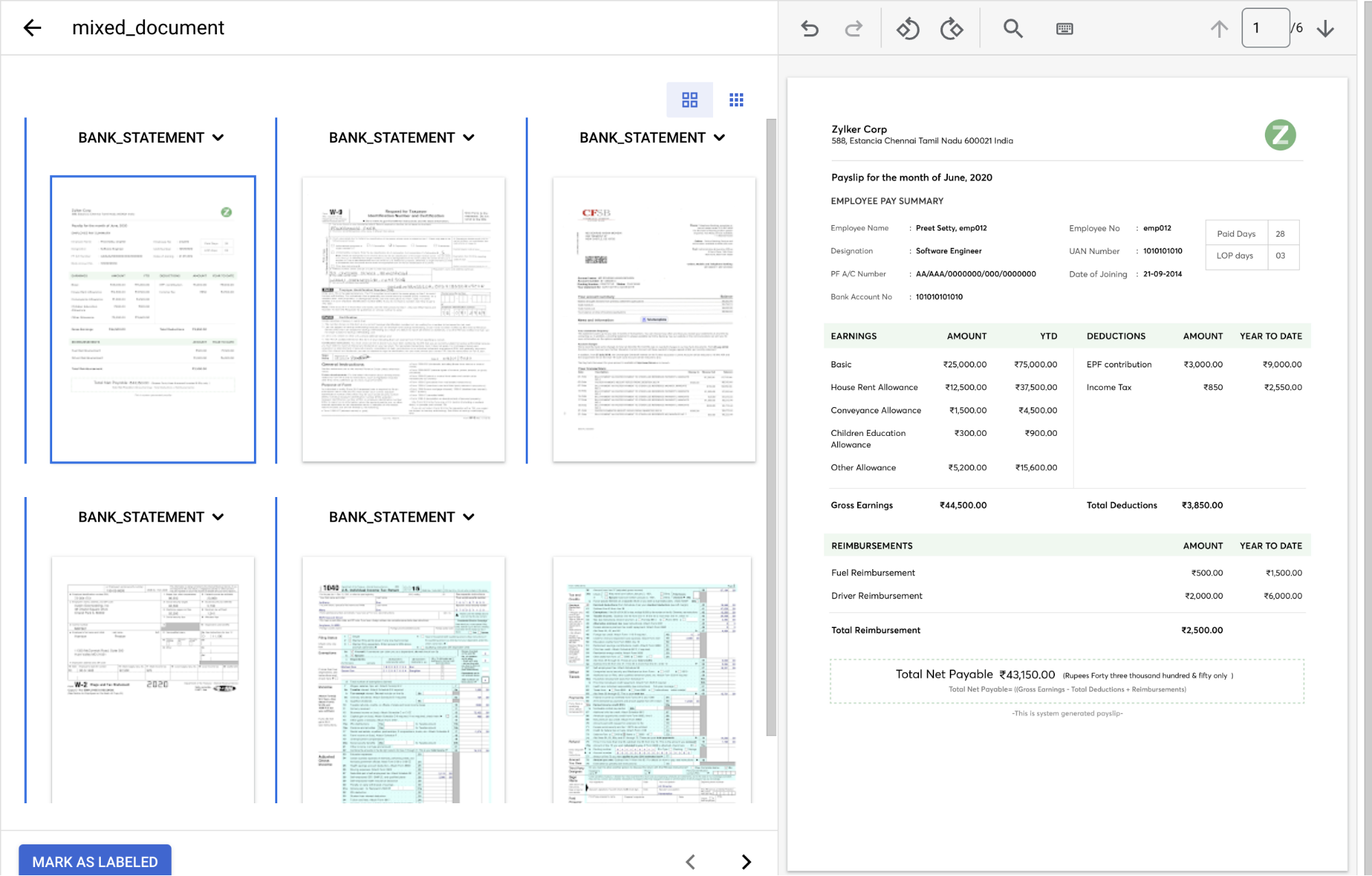
בתפריט הנפתח
סוג המסמך , בוחרים את התווית המתאימה לכל קבוצת דפים.עמודים סוג המסמך 1 paystub2 form_w9ר3 bank_statement4 form_w25 & 6 form_1040מסמך עם תוויות צריך להיראות כך:
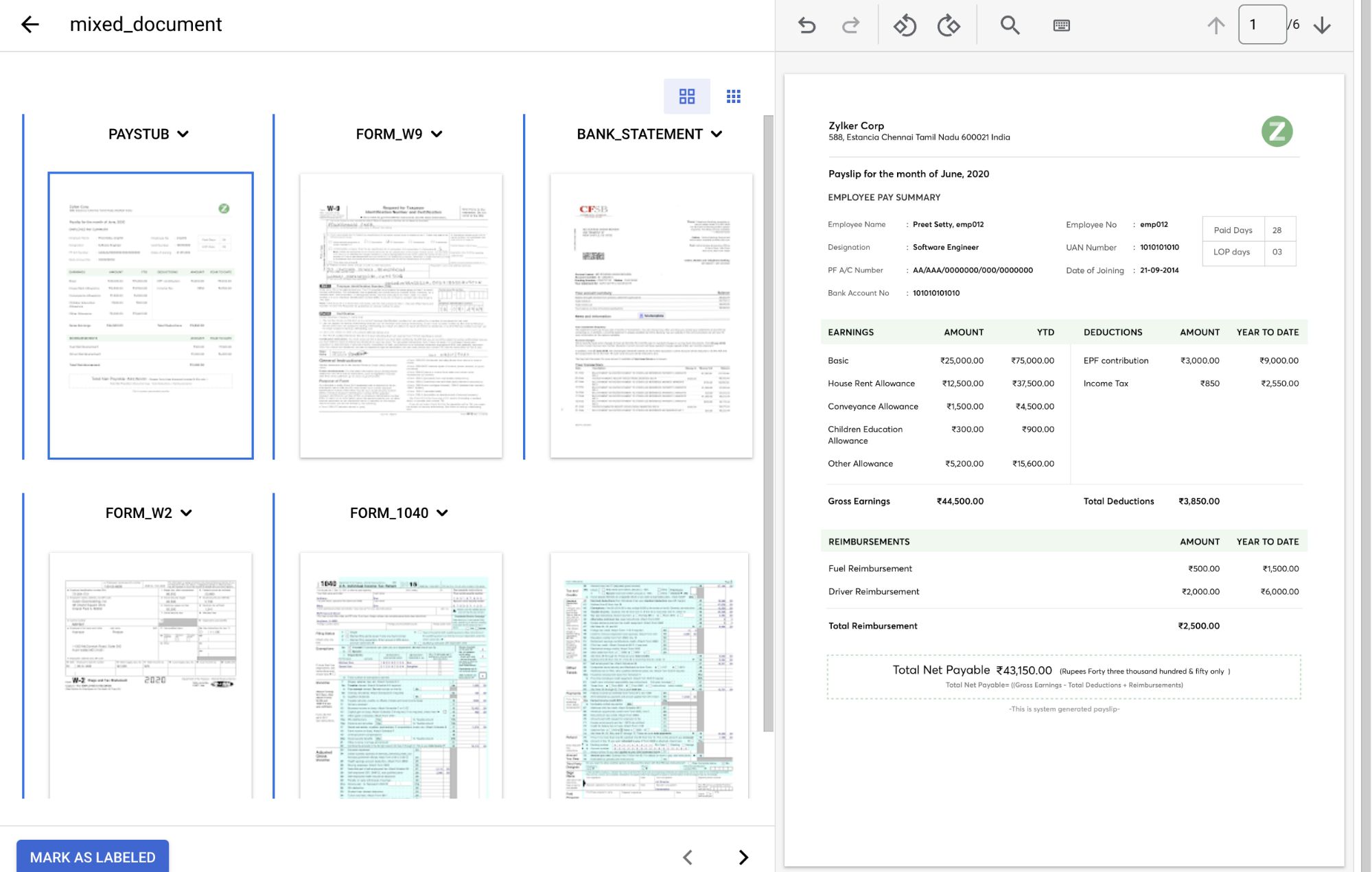
כשמסיימים להוסיף הערות למסמך, בוחרים באפשרות
סימון כ'תויג' .בכרטיסייה Train (אימון), בחלונית הימנית מוצג שמסמך אחד סומן.
הקצאת מסמך עם הערות לקבוצת נתונים לאימון
אחרי שמוסיפים תוויות למסמך לדוגמה, אפשר להקצות אותו לקבוצת נתונים לאימון.
בכרטיסייה Train (אימון), מסמנים את תיבת הסימון
Select All (בחירת הכול).ברשימה
הקצאה לקבוצה , בוחרים באפשרות הדרכה.
בחלונית הימנית, אפשר לראות שמסמך אחד הוקצה לקבוצת נתונים לאימון.
ייבוא נתונים עם תיוג באצווה
לאחר מכן מייבאים קובצי PDF ללא תוויות שממוינים לספריות שונות ב-Cloud Storage לפי הסוג שלהם. תיוג אצווה עוזר לחסוך זמן בתיוג, כי הוא מקצה תווית בזמן הייבוא על סמך הנתיב.
בכרטיסייה Train (אימון), בוחרים באפשרות
Import documents (ייבוא מסמכים).מזינים את הנתיב הבא ב
נתיב המקור . בתיקייה הזו יש קובצי PDF של דפי חשבון בנק.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/bank-statementמגדירים את
תווית המסמך לערךbank_statement.בתפריט
Dataset split , מגדירים את האפשרות Auto-split. המסמכים יפוצלו אוטומטית כך ש-80% מהם יהיו בקבוצת נתונים לאימון ו-20% בקבוצת נתונים לבדיקה.בוחרים באפשרות
הוספת תיקייה נוספת כדי להוסיף עוד תיקיות.חוזרים על השלבים הקודמים עם הנתיבים ותוויות המסמכים הבאים:
נתיב הקטגוריה תווית מסמך cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/1040form_1040cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w2form_w2cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w9form_w9cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/paystubpaystubבסיום, המסוף אמור להיראות כך:
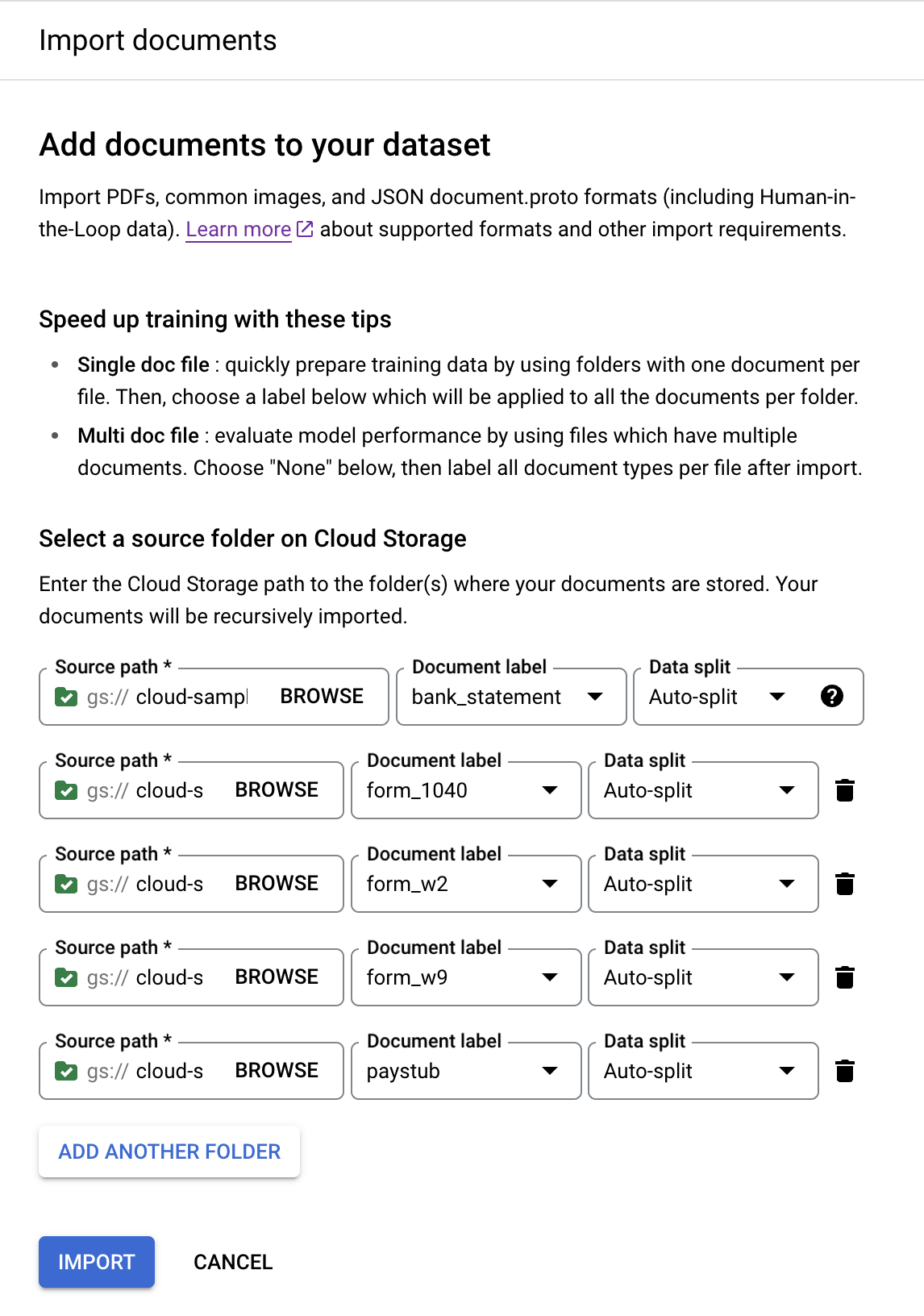
בוחרים באפשרות
ייבוא . הייבוא יימשך כמה דקות.
כשהייבוא מסתיים, המסמכים מופיעים בכרטיסייה אימון.
ייבוא נתונים שכבר סומנו
במדריך הזה, הנתונים המסומנים מראש מסופקים בפורמט Document כקובצי JSON.
זהו אותו פורמט שמופק על ידי Document AI כשמעבדים מסמך, כשמבצעים תיוג באמצעות Human-in-the-Loop או כשמייצאים מערך נתונים.
בכרטיסייה Train (אימון), בוחרים באפשרות
Import documents (ייבוא מסמכים).מזינים את הנתיב הבא ב
נתיב המקור .cloud-samples-data/documentai/Custom/Lending-Splitter/JSON-Labeledמגדירים את
תווית המסמך לערך ללא.בתפריט הנפתח
Dataset split (פיצול מערך הנתונים), בוחרים באפשרות Auto-split (פיצול אוטומטי).בוחרים באפשרות
ייבוא .
כשהייבוא מסתיים, המסמכים מופיעים בכרטיסייה אימון.
אימון המעבד
אחרי שמייבאים את נתוני האימון והבדיקה, אפשר לאמן את המעבד. תהליך האימון עשוי להימשך כמה שעות, לכן חשוב לוודא שהגדרתם את המעבד עם הנתונים והתוויות המתאימים לפני שמתחילים באימון.
בוחרים באפשרות
Train New Version (אימון גרסה חדשה).בשדה
Version name (שם הגרסה), מזינים שם לגרסה הזו של המעבד, למשלmy-cds-version-1.(אופציונלי) בוחרים באפשרות הצגת נתונים סטטיסטיים של התווית כדי לראות מידע על תוויות המסמכים. כך תוכלו לקבוע את הכיסוי שלכם. בוחרים באפשרות סגירה כדי לחזור להגדרת האימון.
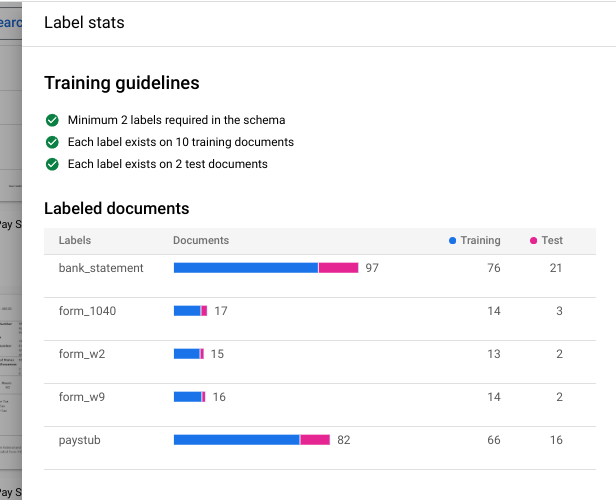
בוחרים באפשרות
התחלת האימון . אפשר לבדוק את הסטטוס בחלונית השמאלית.
פריסת גרסת המעבד
אחרי שהאימון יסתיים, עוברים לכרטיסייה
ניהול גרסאות . אפשר לראות פרטים על הגרסה שאומנה.לוחצים על
סמל האפשרויות הנוספות (3 נקודות אנכיות) משמאל לגרסה שרוצים לפרוס, ואז על פריסת גרסה.בחלון הקופץ, לוחצים על
פריסה .תהליך הפריסה נמשך כמה דקות.
הערכה ובדיקה של המעבד
אחרי שהפריסה מסתיימת, עוברים לכרטיסייה
הערכה ובדיקה .בדף הזה אפשר לראות מדדי הערכה, כולל ציון F1, דיוק וזיכרון לכל המסמך ולתוויות נפרדות. מידע נוסף על הערכה וסטטיסטיקות זמין במאמר Evaluate processor.
הורידו מסמך שלא היה מעורב בהדרכה או בבדיקה קודמות, כדי שתוכלו להשתמש בו להערכת גרסת המעבד. אם משתמשים בנתונים משלכם, צריך להשתמש במסמך שנועד למטרה הזו.
בוחרים באפשרות
העלאת מסמך בדיקה ובוחרים את המסמך שהורדתם.הדף Custom splitter analysis ייפתח. פלט המסך מדגים את רמת הדיוק של פיצול המסמך וסיווגו.
בסיום, המסוף אמור להיראות כך:
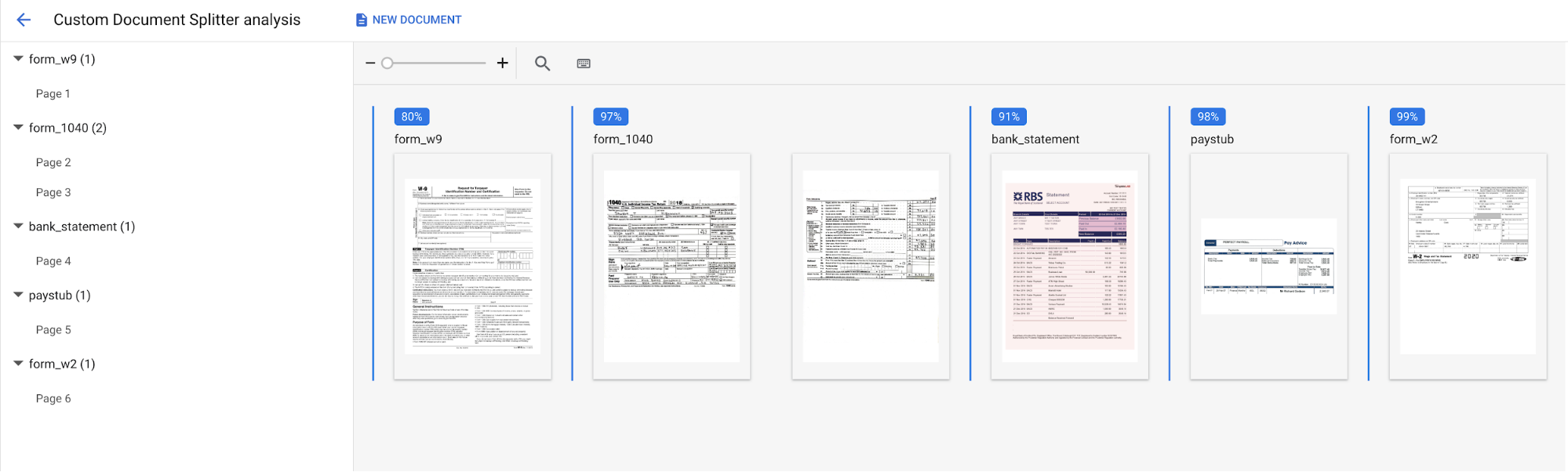
אפשר גם להריץ מחדש את ההערכה על קבוצת נתונים לבדיקה אחרת או על גרסה אחרת של מעבד.
(אופציונלי) ייבוא נתונים עם תיוג אוטומטי
אחרי פריסת גרסה של מעבד שאומן, אפשר להשתמש בתיוג אוטומטי כדי לחסוך זמן בתיוג כשמייבאים מסמכים חדשים.
בכרטיסייה Train (אימון), בוחרים באפשרות
Import documents (ייבוא מסמכים).מזינים את הנתיב הבא ב
נתיב המקור . התיקייה הזו מכילה קובצי PDF לא מסומנים של כמה סוגי מסמכים.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-AutoLabelמגדירים את
תווית המסמך כהוספת תווית אוטומטית.בתפריט הנפתח
Dataset split (פיצול מערך הנתונים), בוחרים באפשרות Auto-split (פיצול אוטומטי).בקטע תיוג אוטומטי, מגדירים את
הגרסה כגרסה שאומנה קודם.- לדוגמה:
2af620b2fd4d1fcf
- לדוגמה:
בוחרים באפשרות
ייבוא ומחכים עד שהמסמכים ייובאו.אי אפשר להשתמש במסמכים עם תוויות אוטומטיות לאימון או לבדיקה בלי לסמן אותם כמתויגים. כדי לראות את המסמכים עם התוויות האוטומטיות, עוברים לקטע
Auto-labeled .בוחרים את המסמך הראשון כדי להיכנס למסוף התיוג.
מוודאים שהתווית נכונה, ואם לא, משנים אותה.
כשמסיימים, בוחרים באפשרות
סימון כתווית .חוזרים על אימות התווית לכל מסמך שנוספה לו תווית באופן אוטומטי.
חוזרים לדף Train (אימון) ולוחצים על Train New Version (אימון גרסה חדשה) כדי להשתמש בנתונים לאימון.
שימוש במעבד
יצרתם והכשרתם בהצלחה מעבד מותאם אישית לפיצול.
אפשר לנהל את הגרסאות של מעבד שעבר אימון מותאם אישית בדיוק כמו כל גרסה אחרת של מעבד. מידע נוסף זמין במאמר בנושא ניהול גרסאות של מעבדים.
אחרי הפריסה, אפשר לשלוח בקשת עיבוד למעבד המותאם אישית, והתגובה תטופל כמו תגובות של מעבדי פיצול אחרים.
הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם בדף הזה, פועלים לפי השלבים הבאים:
כדי להימנע מחיובים מיותרים Google Cloud , אפשר להשתמש ב-Google Cloud console כדי למחוק את המעבד והפרויקט אם אין בהם צורך.
אם יצרתם פרויקט חדש כדי ללמוד על Document AI ואתם כבר לא צריכים אותו, אפשר למחוק אותו.
אם השתמשתם בפרויקט קיים Google Cloud , מחקו את המשאבים שיצרתם כדי להימנע מחיובים בחשבון:
בתפריט הניווט במסוף Google Cloud , בוחרים באפשרות Document AI ואז באפשרות My Processors.
בוחרים באפשרות
עוד פעולות באותה שורה של המעבד שרוצים למחוק.בוחרים באפשרות מחיקת מעבד, מקלידים את שם המעבד ובוחרים שוב באפשרות מחיקה כדי לאשר.