
כדי לאמן גרסה של מעבד, לשפר את האימון שלה או להעריך אותה, צריך מערך נתונים של מסמכים עם תוויות.
בדף הזה מוסבר איך להחיל תוויות מסכימת המעבד על מסמכים מיובאים במערך הנתונים.
בדף הזה מניחים שכבר יצרתם מעבד שתומך באימון, באימון מתקדם או בהערכה. אם המעבד נתמך, הכרטיסייה Train מופיעה במסוף Google Cloud . בנוסף, מניחים שיצרתם מערך נתונים, ייבאתם מסמכים והגדרתם סכימה של מעבד.
שדות שם לחילוץ באמצעות AI גנרטיבי
השמות של השדות משפיעים על רמת הדיוק של חילוץ השדות באמצעות AI גנרטיבי. מומלץ לבחור שמות לשדות לפי השיטות המומלצות הבאות:
השם של השדה צריך להיות באותה שפה שבה הוא מתואר במסמך: לדוגמה, אם במסמך יש שדה שמתואר כ-
Employer Address, השם של השדה צריך להיותemployer_address. אל תשתמשו בקיצורים כמוemplr_addr.בשלב הזה אין תמיכה ברווחים בשמות של שדות: במקום להשתמש ברווחים, צריך להשתמש ב-
_. לדוגמה:First Nameייקראfirst_name.חזרה על שמות כדי לשפר את הדיוק: יש מגבלה ב-Document AI שלא מאפשרת לשנות שמות של שדות. כדי לבדוק שמות שונים, משתמשים בכלי לשינוי שם של ישות כדי לעדכן את השם של הישות הישנה בשם חדש יותר בקבוצת הנתונים, מייבאים את קבוצת הנתונים, מפעילים את הישויות החדשות במעבד ומשביתים או מוחקים את השדות הקיימים.
למידה ללא דוגמאות ולמידה עם כמה דוגמאות
למודלים עם Gemini יש יכולות למידה ללא דוגמאות ולמידה עם מעט דוגמאות, שיכולות ליצור מודלים עם ביצועים גבוהים עם מעט נתונים לאימון או ללא נתונים כאלה בכלל.
למידה ללא דוגמאות היא דוגמה ללמידת מכונה שבה מודל שאומן מראש ללא אימון נוסף לומד לזהות ולסווג מחלקות וישויות שהוא לא נתקל בהן לפני כן במהלך הבדיקה.
למידה עם מעט דוגמאות היא שיטה שבה מודל לומד לזהות ולסווג מחלקות וישויות חדשות עם כמה דוגמאות לאימון לכל מחלקה. הוא מסתמך על ידע ממודלים שעברו אימון מראש על קבוצות נתונים גדולות עם תוויות מדויקות, כדי לשפר את הביצועים במשימות עם מעט דוגמאות.
השיטה 'למידה עם מעט דוגמאות' יעילה יותר כשמערך הנתונים לאימון מסודר ומתויג בקפידה. בדרך כלל, המשמעות היא שצריכים להיות זמינים לפחות 10 דוגמאות לבדיקה ו-10 דוגמאות לאימון כדי שהמודל יוכל ללמוד מהן.
אפשרויות להוספת תוויות
אלה האפשרויות לתווית מסמכים:
ידני: הוספת תוויות למסמכים באופן ידני במסוף Google Cloud
תיוג אוטומטי: שימוש בגרסה קיימת של מעבד כדי ליצור תוויות
ייבוא מסמכים עם תוויות שכבר קיימות: חוסכים זמן אם כבר יש לכם מסמכים עם תוויות
הוספת תוויות ידנית במסוף Google Cloud
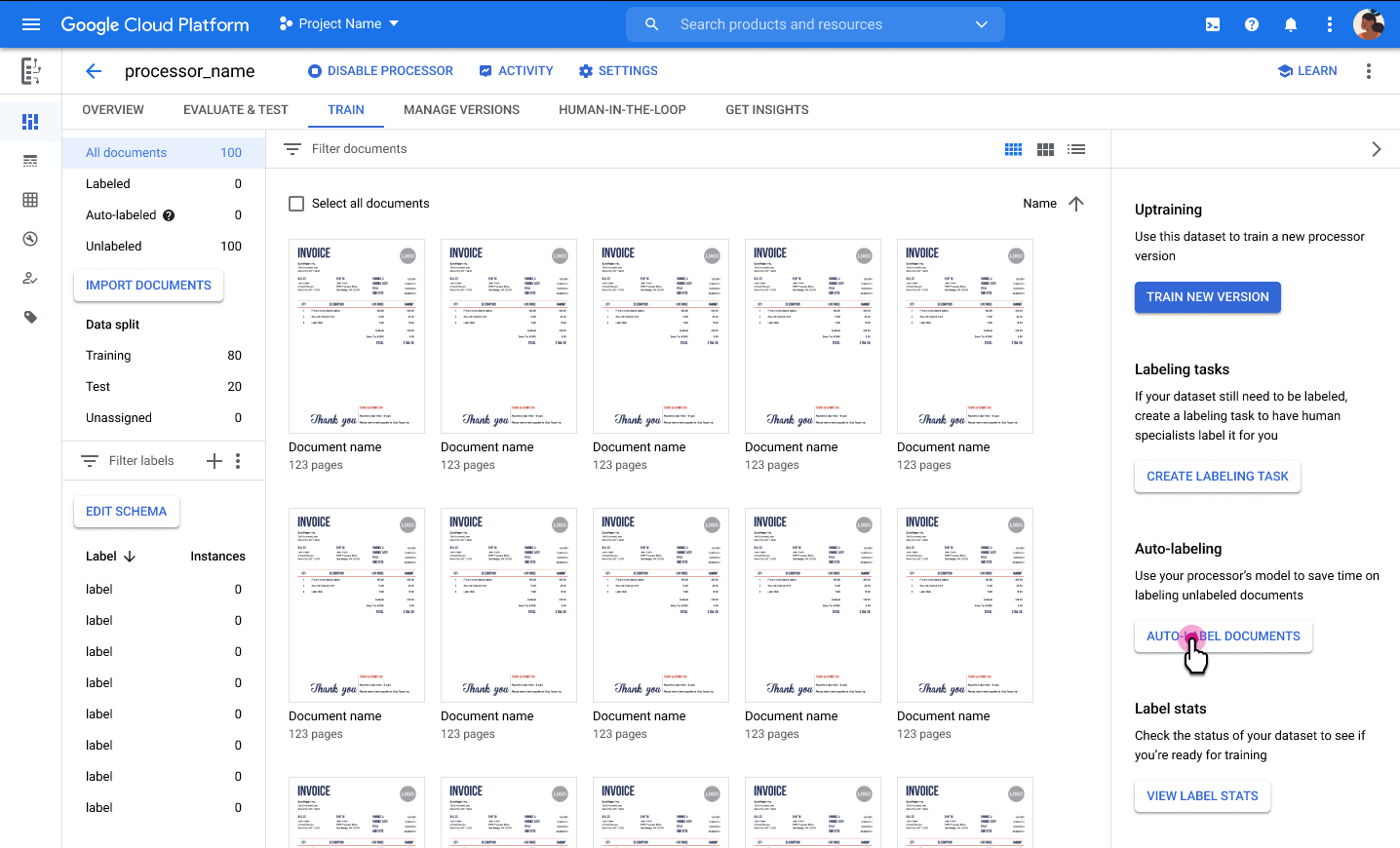
בכרטיסייה Train (אימון), בוחרים מסמך כדי לפתוח את כלי התיוג.
ברשימת תוויות הסכימה בצד ימין של כלי התיוג, לוחצים על סמל ההוספה כדי לבחור בכלי תיבת התוחמת, לסמן ישויות במסמך ולהקצות אותן לתווית.
בצילום המסך הבא, השדות EMPL_SSN, EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS, FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES ו-WAGES_TIPS_OTHER_COMP במסמך קיבלו תוויות.
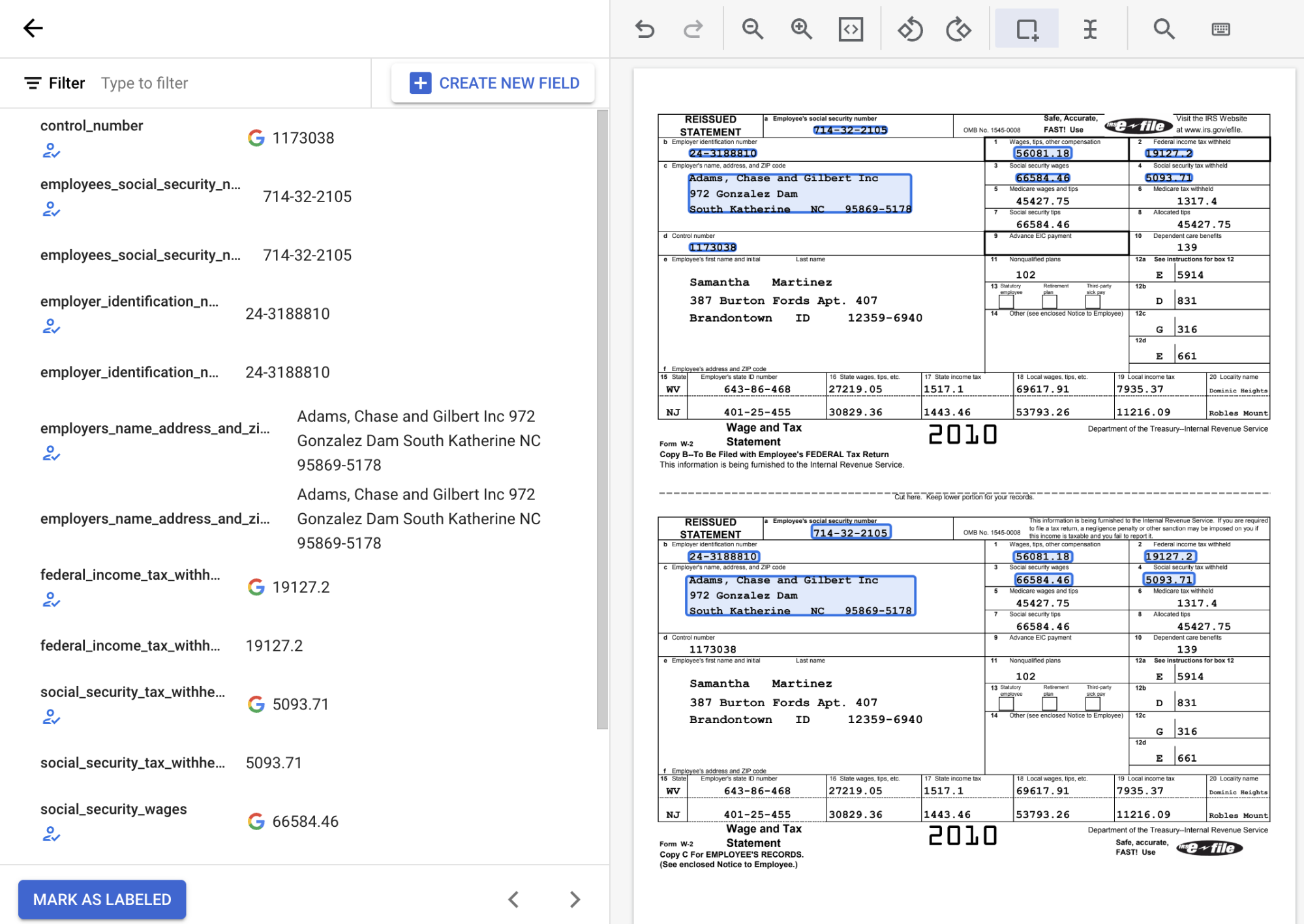
כשבוחרים תיבת סימון באמצעות הכלי תיבת תוחמת, צריך לבחור רק את תיבת הסימון עצמה, ולא טקסט שמשויך אליה. מוודאים שתיבת הסימון של הישות שמוצגת בצד ימין מסומנת או לא מסומנת בהתאם למה שמופיע במסמך.

כשמוסיפים תוויות לישויות הורה-צאצא, לא מוסיפים תוויות לישויות ההורה. ישות האב היא רק קונטיינר של ישויות הצאצא. צריך להוסיף תווית רק לישויות הצאצא. העדכון של ישויות האב מתבצע באופן אוטומטי.
כשמסמנים ישויות צאצא, מסמנים את ישות הצאצא הראשונה ואז משייכים את ישויות הצאצא שקשורות אליה לאותה שורה. אפשר להבחין בכך בפעם הראשונה שמתייגים ישויות כאלה, בישות הצאצא השנייה. לדוגמה, אם תתייגו את המילה description בחשבונית, היא תיראה כמו כל ישות אחרת. אבל אם תתנו את התווית כמות בשלב הבא, תתבקשו לבחור את תבנית האם.
חוזרים על השלב הזה לכל פריט, ובוחרים באפשרות New Parent Entity (ישות אב חדשה) לכל פריט חדש.
יש תמיכה בישויות הורה-צאצא בטבלאות עם עד שלוש שכבות של קינון. מודלים בסיסיים תומכים בשלוש רמות של שדות (סבא/סבתא, הורה, צאצא), כך שישויות צאצא יכולות לכלול רמה אחת של צאצאים. מידע נוסף על קינון מופיע במאמר בנושא קינון ברמה השלישית.
טבלאות מהירות
כשמתייגים טבלה, יכול להיות מייגע לתייג כל שורה שוב ושוב. יש כלי נוח מאוד שיכול לשכפל מבנה של ישות שורה. הערה: התכונה הזו פועלת רק בשורות שמוצגות בצורה אופקית.
- קודם כל, מתייגים את השורה הראשונה כרגיל.
לאחר מכן, מעבירים את הסמן מעל ישות האם שמייצגת את השורה. לוחצים על הוספת שורות. השורה הופכת לתבנית ליצירת שורות נוספות.
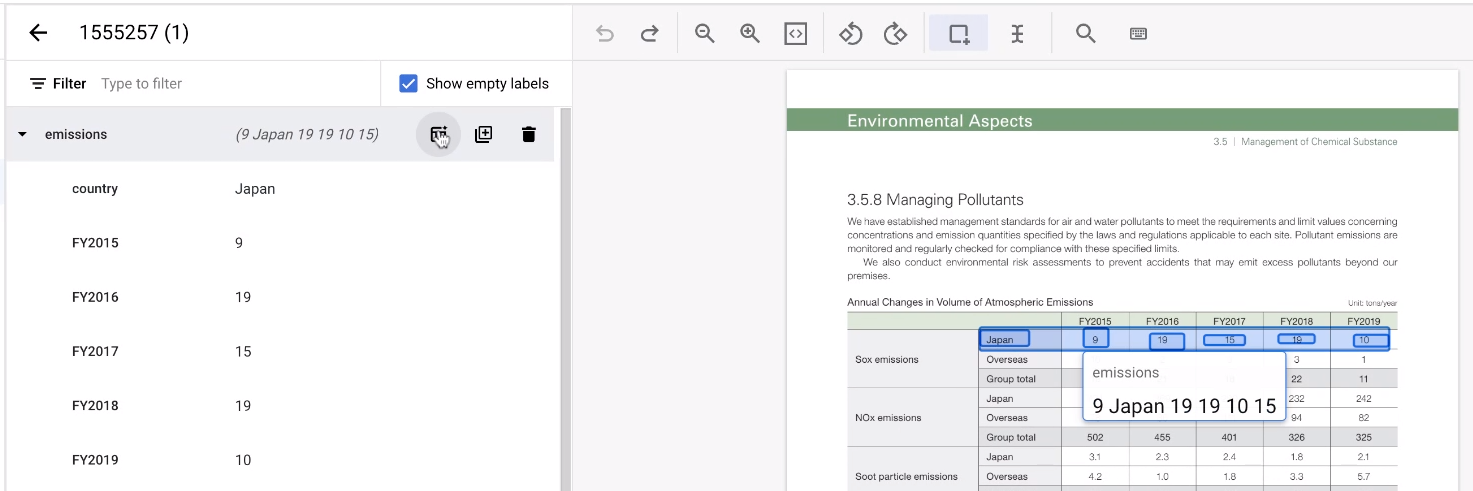
בוחרים את שאר האזור בטבלה.
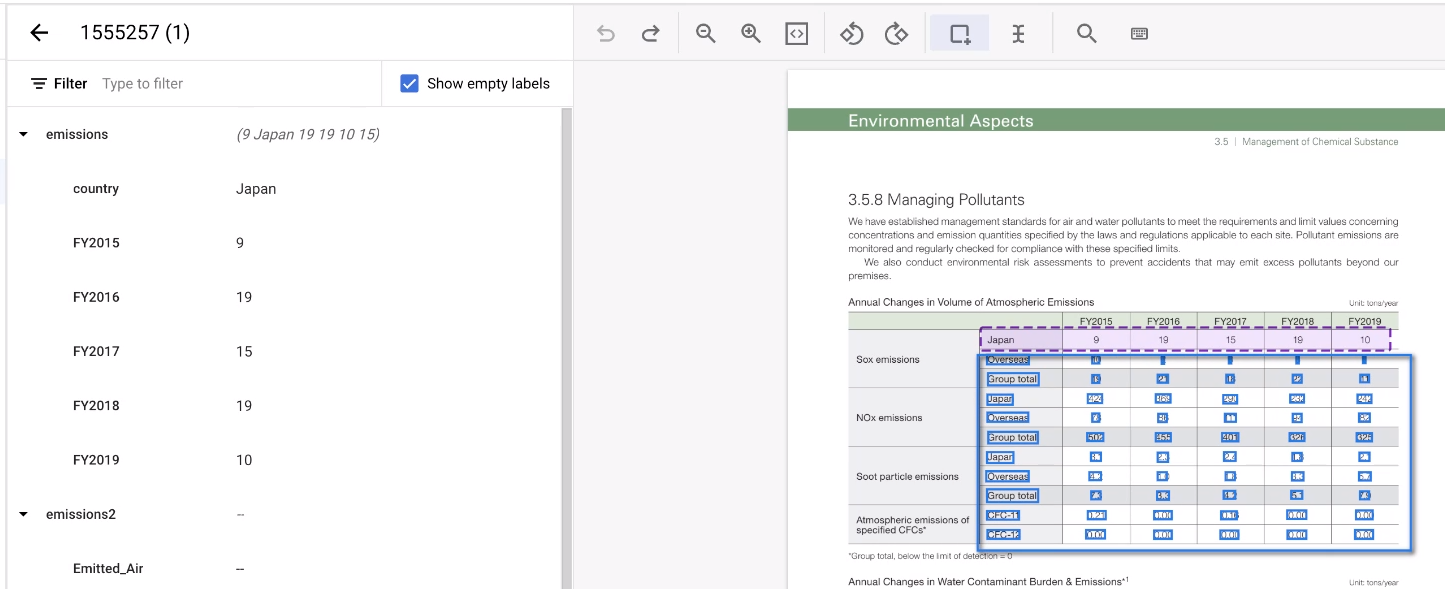
הכלי מנחש את ההערות, ובדרך כלל זה עובד. אם יש טבלאות שהכלי לא יכול לטפל בהן, צריך להוסיף להן הערות באופן ידני.
שימוש במקשי קיצור במסוף
כדי לראות את מקשי הקיצור שזמינים, בוחרים בתפריט בפינה השמאלית העליונה של מסוף התיוג. מוצגת רשימה של מקשי קיצור, כמו שרואים בטבלה הבאה.
| פעולה | קיצור דרך |
|---|---|
| Zoom in – התקרבות | Alt + = (Option + = ב-macOS) |
| Zoom out – התרחקות | Alt + - (Option + - ב-macOS) |
| הגדלה/הקטנה כדי להתאים את הגודל | Alt + 0 (Option + 0 ב-macOS) |
| גלילה לשינוי מרחק התצוגה | Alt + Scroll (Option + Scroll ב-macOS) |
| פאנינג | גלילה |
| הזזה הפוכה | Shift + גלילה |
| גרירה להזזה | מקש הרווח + גרירת העכבר |
| ביטול | Ctrl + Z (Control + Z ב-macOS) |
| Redo – ביצוע מחדש | Ctrl + Shift + Z (Control + +Shift + Z ב-macOS) |
תווית אוטומטית
אם יש לכם מעבד קיים, אתם יכולים להשתמש בו כדי להתחיל לתייג.
אפשר להפעיל את התיוג האוטומטי במהלך הייבוא. כל המסמכים מתויגים באמצעות גרסת המעבד שצוינה.
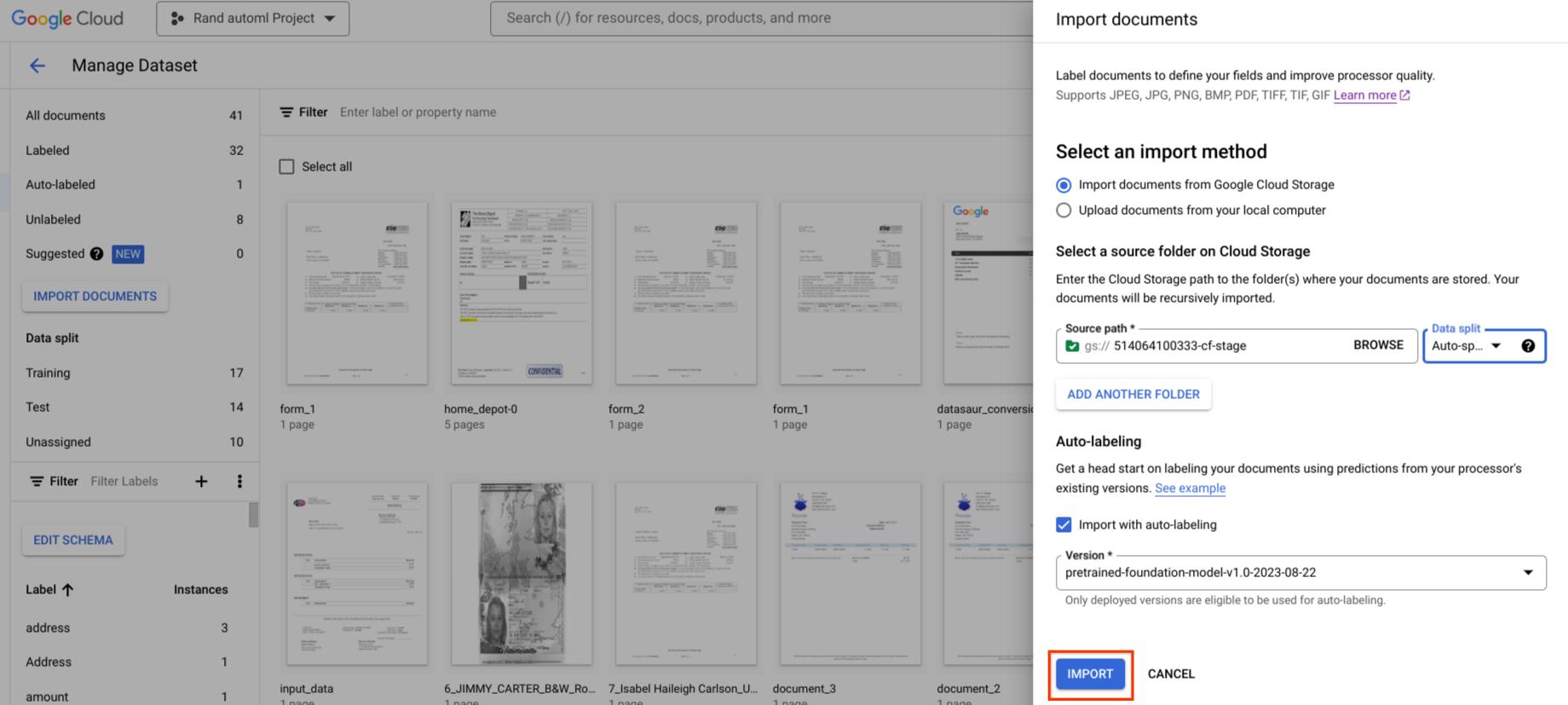
אפשר להפעיל את התיוג האוטומטי אחרי ייבוא של מסמכים בקטגוריה 'ללא תווית' או בקטגוריה 'תיוג אוטומטי'. כל המסמכים שנבחרו יתויגו באמצעות הגרסה שצוינה של המעבד.
אי אפשר לאמן או לשפר את האימון של מסמכים עם תוויות אוטומטיות, או להשתמש בהם בקבוצת נתונים לבדיקה, בלי לסמן אותם כמסמכים עם תוויות. בודקים ידנית את ההערות עם התוויות האוטומטיות ומתקנים אותן, ואז לוחצים על סימון כתווית כדי לשמור את התיקונים. אחר כך תוכלו להקצות את המסמכים לפי הצורך.
ייבוא מסמכים עם תוויות קיימות
אפשר לייבא קובצי JSON Document. אם entity במסמך תואם לתווית בסכימת המעבד, כלי הייבוא ממיר את entity למופע של תווית. יש כמה דרכים לקבל קבצים של מסמכי JSON:
ייצוא של מערך נתונים ממעבד אחר. ייצוא של מערכי נתונים
שליחת בקשת עיבוד למעבד נתונים קיים.
אפשר להשתמש בערכת הכלים לייבוא כדי להמיר תוויות קיימות ממערכת אחרת, למשל תוויות בפורמט CSV למסמכי JSON.
שיטות מומלצות לתיוג מסמכים
כדי לאמן מעבד באיכות גבוהה, צריך להקפיד על תיוג עקבי. מומלץ:
יוצרים הוראות לתיוג: ההוראות צריכות לכלול דוגמאות למקרים נפוצים ולמקרים חריגים. כמה טיפים:
- הסבר על השדות שצריך להוסיף להם הערות ואיך בדיוק אפשר להוסיף תוויות באופן עקבי. לדוגמה, כשמגדירים תווית ל'סכום', צריך לציין אם להגדיר תווית לסמל המטבע. אם התוויות לא עקביות, איכות המעבד תרד.
- צריך להוסיף תווית לכל המופעים של ישות, גם אם סוג התווית הוא
REQUIRED_ONCEאוOPTIONAL_ONCE. לדוגמה, אם הסמלinvoice_idמופיע פעמיים במסמך, צריך לתייג את כל המופעים שלו. - בדרך כלל עדיף להוסיף תווית קודם באמצעות כלי ברירת המחדל של התיבה התוחמת. אם זה לא עובד, משתמשים בכלי לבחירת טקסט.
- אם ה-OCR לא מזהה את הערך של התווית בצורה נכונה, אל תתקנו את הערך באופן ידני. במקרה כזה, אי אפשר יהיה להשתמש בו למטרות אימון.
הנה כמה הוראות לדוגמה לסימון:
- הדרכת המבארים: מוודאים שהמבארים מבינים את ההנחיות ויכולים לפעול לפיהן ללא שגיאות שיטתיות. אחת הדרכים לעשות זאת היא לבקש ממתאמנים שונים להוסיף הערות לאותה קבוצת מסמכים. לאחר מכן, המאמן יכול לבדוק את איכות העבודה של כל מתלמד. יכול להיות שתצטרכו לחזור על התהליך הזה עד שהמתאמנים יגיעו לרמת דיוק שתוגדר כרמת בסיס.
- בדיקות ראשוניות: כדאי לבדוק את המסמכים הראשונים (10 בערך) שסומנו לתרחיש שימוש מסוים על ידי מתייג חדש, לפני שמסמנים מספר גדול של מסמכים, כדי למנוע טעויות רבות שצריך לתקן.
- בדיקות איכות של הערות: ההערות דורשות עבודה רבה, ולכן גם מגיבים מנוסים עלולים לטעות. מומלץ שפרשנויות ייבדקו על ידי לפחות עוד פרשן מיומן.
הוספת הנחיית תיאור
כשמוסיפים תוויות לסכימה בכלי לחילוץ בהתאמה אישית ובמסווג תוכן מותאם אישית, אפשר להוסיף תיאור לתווית. כך אפשר לאמן את המעבד על ידי מתן הנחיה לזיהוי התווית. אפשר לנסות שינויים קלים כדי לבדוק את איכות התשובה. לדוגמה, total amount, total invoice amount או total amount of invoice.
סנכרון מחדש של מערך נתונים
הסנכרון מחדש שומר על עקביות בין תיקיית Cloud Storage של מערך הנתונים לבין האינדקס הפנימי של המטא-נתונים ב-Document AI. האפשרות הזו שימושית אם ביצעתם בטעות שינויים בתיקייה ב-Cloud Storage ואתם רוצים לסנכרן את הנתונים.
כדי לסנכרן מחדש:
בכרטיסייה פרטי המעבד, לצד השורה מיקום האחסון, לוחצים על ואז על סנכרון מחדש של מערך הנתונים.
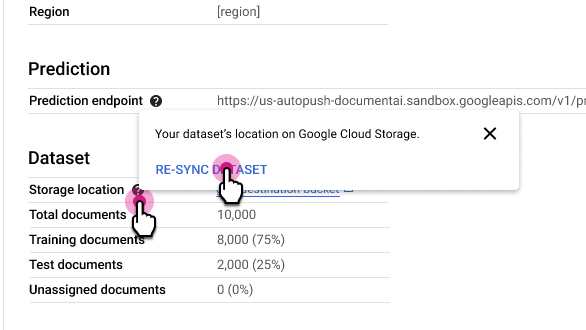
הערות שימוש:
- אם מוחקים מסמך מהתיקייה ב-Cloud Storage, סינכרון מחדש יגרום להסרתו ממערך הנתונים.
- אם מוסיפים מסמך לתיקייה ב-Cloud Storage, הסנכרון מחדש לא מוסיף אותו למערך הנתונים. כדי להוסיף מסמכים, מייבאים אותם.
- אם משנים את תוויות המסמכים בתיקייה ב-Cloud Storage, צריך לסנכרן מחדש כדי לעדכן את תוויות המסמכים במערך הנתונים.
העברת מערך נתונים
ייבוא וייצוא מאפשרים להעביר את כל המסמכים במערך נתונים ממעבד אחד למעבד אחר. האפשרות הזו יכולה להיות שימושית אם יש לכם מעבדים באזורים או ב Google Cloud פרויקטים שונים, אם יש לכם מעבדים שונים לסביבת הבמה ולסביבת הייצור, או לשימוש כללי אופליין.
שימו לב: רק המסמכים והתוויות שלהם מיוצאים. מטא-נתונים של מערך הנתונים, כמו סכימת מעבד, מטלות של מסמכים (אימון/בדיקה/לא הוקצו) וסטטוס התיוג של המסמכים (מתויג, לא מתויג, מתויג אוטומטית) לא מיוצאים.
העתקה וייבוא של מערך הנתונים ואז אימון המעבד של היעד לא זהים בדיוק לאימון המעבד של המקור. הסיבה לכך היא שהמערכת משתמשת בערכים אקראיים בתחילת תהליך הלמידה. כדי לייבא את אותו מודל בין פרויקטים, משתמשים בקריאה ל-API importProcessorVersion. זוהי שיטת העבודה המומלצת להעברת מעבדים לסביבות גבוהות יותר (למשל, מפיתוח ל-Staging לייצור), אם המדיניות מאפשרת זאת.
ייצוא של מערך נתונים
כדי לייצא את כל המסמכים כקבצי JSON Document לתיקייה ב-Cloud Storage, בוחרים באפשרות ייצוא מערך נתונים.
כמה דברים חשובים שכדאי לדעת:
במהלך הייצוא נוצרות שלוש תיקיות משנה: Test, Train ו-Unassigned. המסמכים ימוקמו בתיקיות המשנה האלה בהתאם.
סטטוס התיוג של מסמך לא מיוצא. אם תייבאו את המסמכים מאוחר יותר, הם לא יסומנו כמסמכים עם תוויות אוטומטיות.
אם Cloud Storage נמצא ב Google Cloud פרויקט אחר, צריך לתת הרשאת גישה כדי לאפשר ל-Document AI לכתוב קבצים במיקום הזה. באופן ספציפי, צריך להקצות את התפקיד Storage Object Creator לסוכן השירות הראשי של Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. מידע נוסף זמין במאמר בנושא סוכני שירות.
ייבוא של מערך נתונים
התהליך זהה לייבוא מסמכים.
מדריך למשתמש בנושא תיוג סלקטיבי
התוויות הסלקטיביות עוזרות לקבל המלצות לגבי המסמכים שכדאי לתייג. אתם יכולים ליצור מערכי נתונים מגוונים לאימון ולבדיקה כדי לאמן מודלים מייצגים. בכל פעם שמבצעים תיוג סלקטיבי, נבחרים המסמכים המגוונים ביותר (עד 30) מתוך מערך הנתונים.
קבלת הצעות למסמכים
ליצור מעבד CDE ולייבא מסמכים.
- נדרשות לפחות 100 דוגמאות לאימון (25 לבדיקה).
- אחרי שמייבאים מספיק מסמכים ואחרי תיוג סלקטיבי, סרגל המידע אמור להופיע.
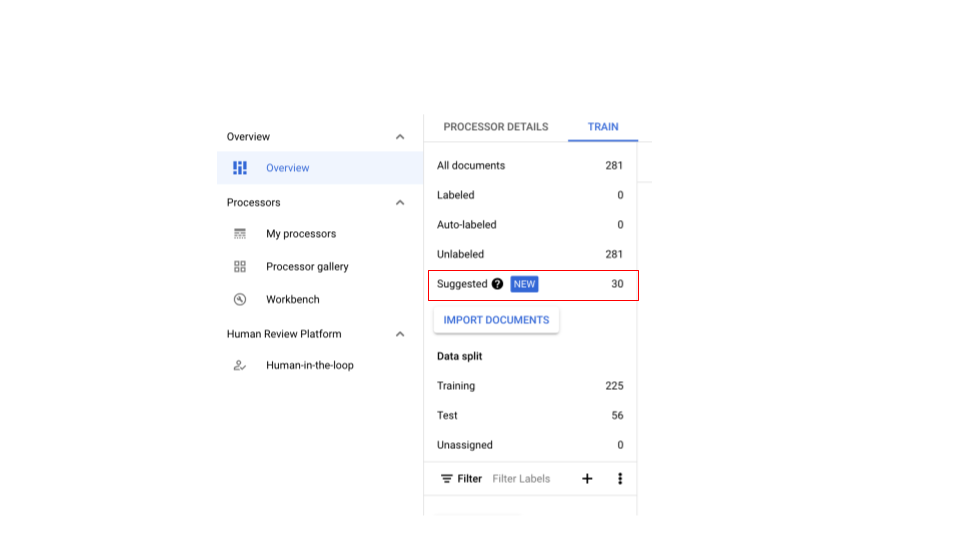
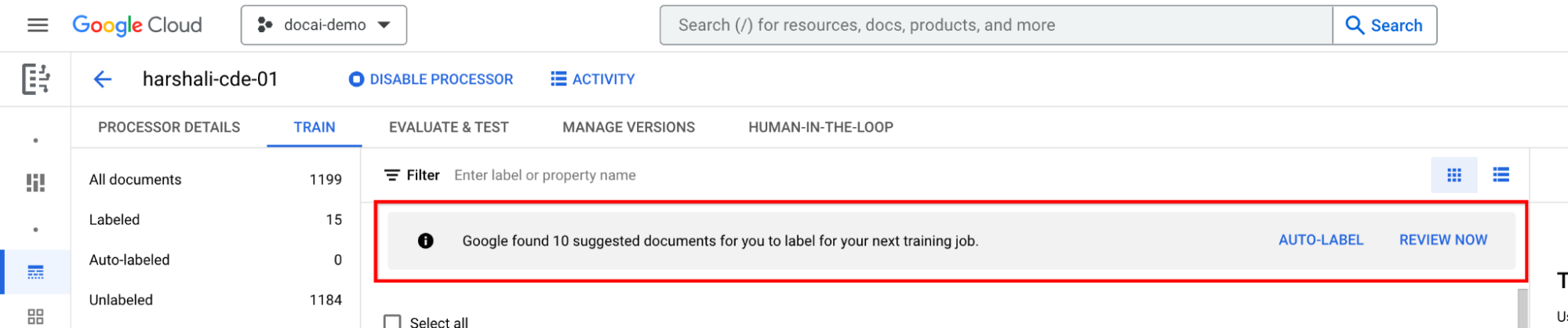
אם מעבד CDE לא מציע מסמכים, צריך לייבא עוד מסמכים כדי שיהיו מספיק מסמכים בכל אחד מהפיצולים לצורך דגימה.
- הפעולה הזו אמורה להפעיל את המסמכים המוצעים בקטגוריה 'הצעות'. אפשר לבקש מסמכים מוצעים באופן ידני.
- נוסף מסנן חדש בחלק העליון כדי לסנן את המסמכים המוצעים.
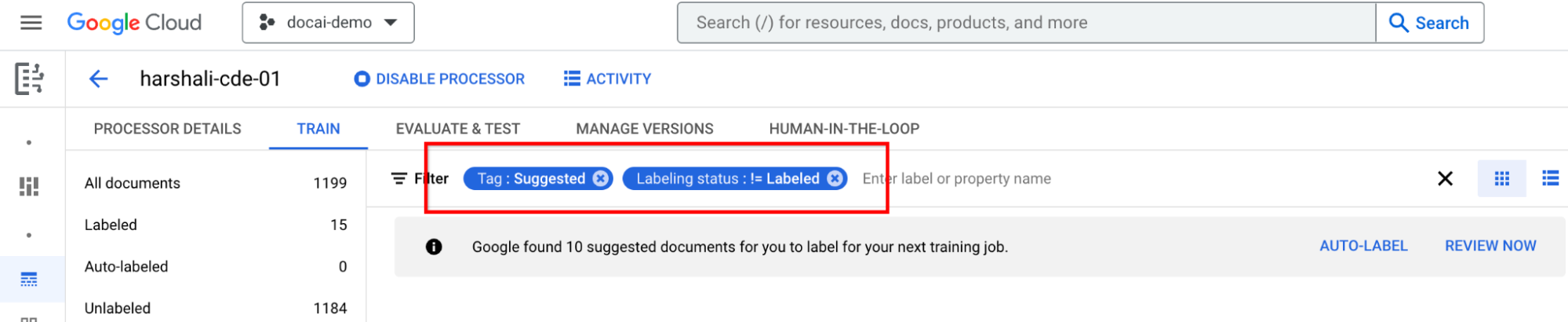
הוספת תוויות למסמכים מוצעים
בחלונית הימנית של רשימת התוויות, עוברים אל קטגוריה מוצעת. מתחילים לתייג את המסמכים האלה.
אם המעבד אומן, בוחרים באפשרות תווית אוטומטית בסרגל המידע. מוסיפים תוויות למסמכים המוצעים.
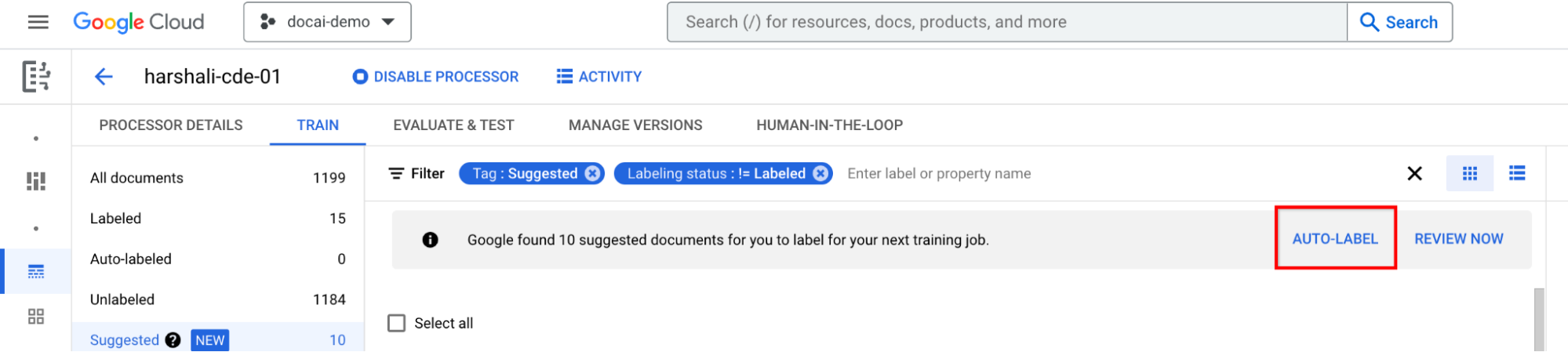
אחר כך, כשמוצעים מסמכים במעבד, אפשר ללחוץ על בדיקה עכשיו בסרגל כדי לעבור אליהם. חשוב לבדוק את הדיוק של כל המסמכים שסומנו באופן אוטומטי. מתחילים לבדוק.
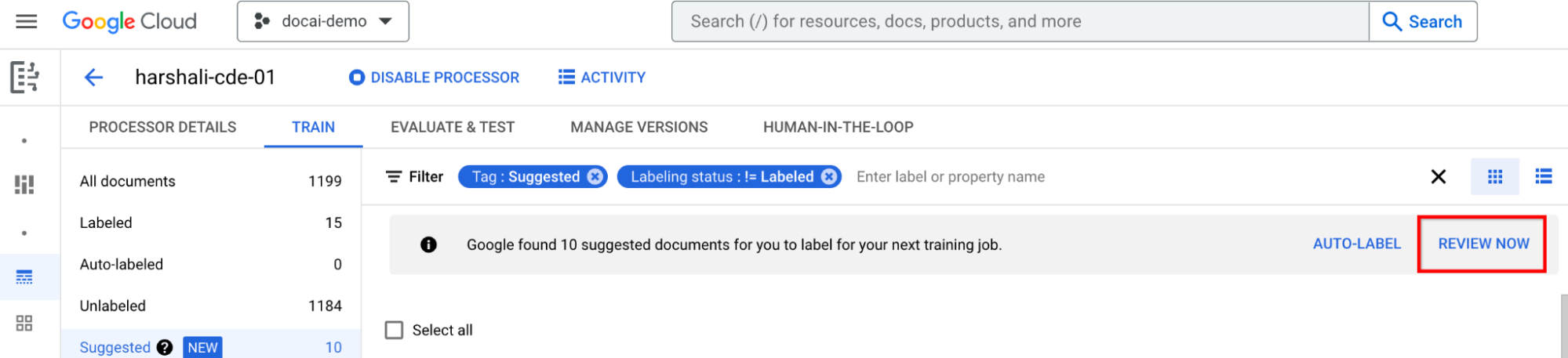
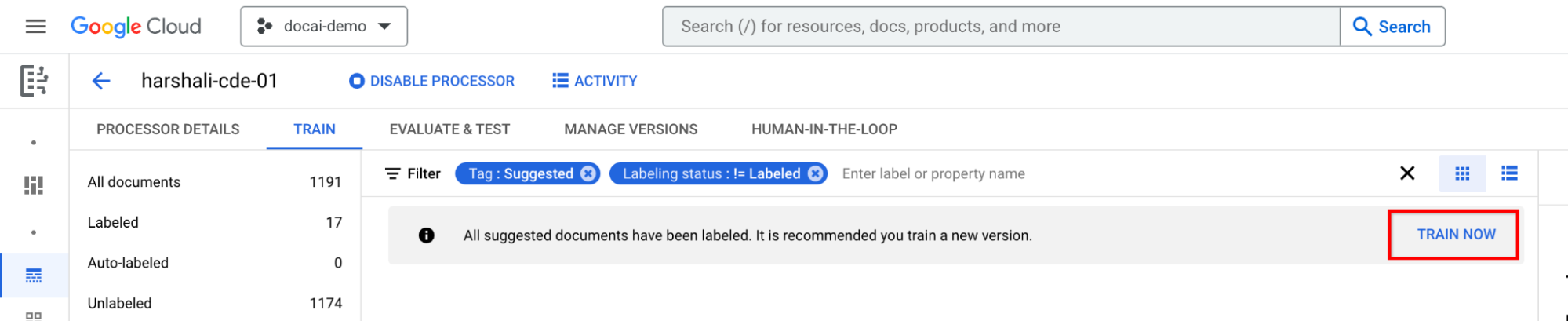
אימון אחרי הוספת תוויות לכל המסמכים המוצעים
עוברים אל Train now (אימון עכשיו) בסרגל המידע. כשמסמכים מוצעים מסומנים, אמור להופיע סרגל המידע הבא עם המלצה להדרכה.
תכונות נתמכות ומגבלות
| תכונה | תיאור | נתמך |
|---|---|---|
| תמיכה במעבדים ישנים | יכול להיות שהשיטה לא תפעל בצורה טובה עם מעבדים ישנים שבהם כבר יובא מערך נתונים |