
如果資料分散儲存在不同儲存系統中,管理分散的安全性可能會成為一大挑戰。您想確保財務記錄等私密資訊受到保護,即使您將這些資訊儲存在 Google Cloud 儲存空間的 Apache Iceberg 等開放格式中,也不例外。
最重要的是,您的安全措施必須在各種查詢引擎 (例如 BigQuery SQL 和 Apache Spark) 中順暢運作。在這個架構中,Knowledge Catalog 可做為通用脈絡引擎,解決這個問題。這個資料夾會保存中繼資料,確保無論哪個引擎查詢資料,都會套用一致的安全環境。
在本教學課程中,您將建構安全的資料湖倉,解決這些挑戰。您可以使用指令碼定義安全性政策,並查看 Knowledge Catalog (舊稱 Dataplex Universal Catalog) 和 Lakehouse for Apache Iceberg 如何共同運作,在不同查詢引擎中強制執行政策。
架構總覽
如要在 Apache Iceberg 等開放資料表格式上設定精細的存取控管機制,您必須建立嚴格的統一安全架構。
採用這種設計後,Knowledge Catalog 就會成為中央控制層。Knowledge Catalog 會在所有支援的引擎中動態強制執行安全脈絡。
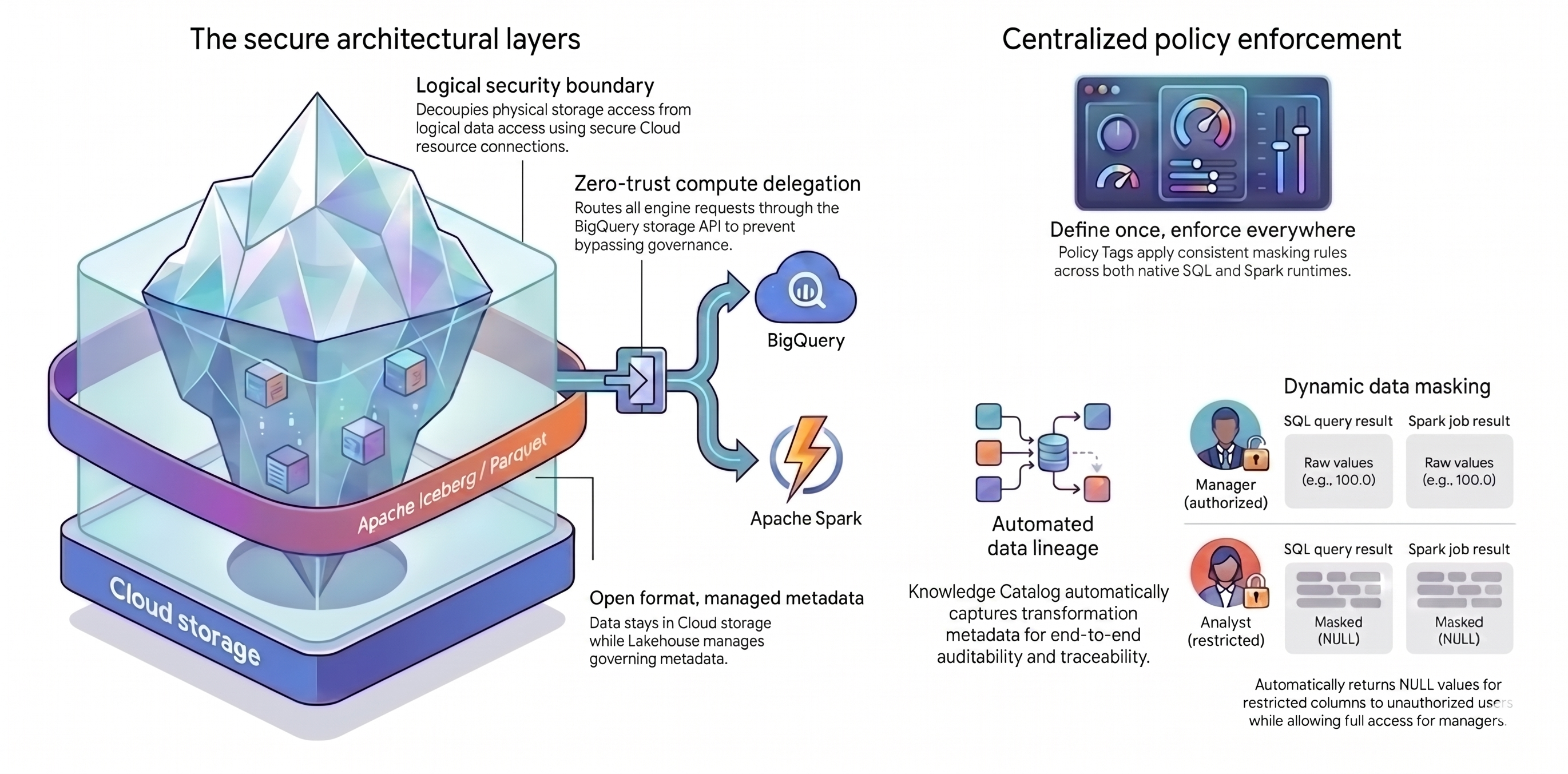
本教學課程會運用兩個主要概念,建立這個統一架構:
- 安全架構層:您可根據下列屬性建構安全的分層基礎,避免使用者或查詢引擎直接存取 Cloud Storage 值區:
- 開放格式搭配受管理的中繼資料:資料會以開放的 Apache Iceberg (Parquet) 格式儲存在 Cloud Storage 中,而 Lakehouse for Apache Iceberg 會管理資料表的中繼資料。
- 邏輯安全邊界:您可以使用安全的 Cloud 資源連結,將儲存空間權限與資料查詢分離。您絕不會直接授予使用者檔案存取權。
- 運算委派:為防止查詢引擎略過規則,請透過 BigQuery Storage API 傳送所有資料要求。透過 BigQuery Storage API 傳送要求,可確保 Knowledge Catalog 即使是外部處理引擎,也能攔截及強制執行政策。
- 集中式政策強制執行:建立安全基礎後,您可以使用 Knowledge Catalog 普遍套用規則:
- 定義一次,隨處強制執行:您只需要在 Knowledge Catalog 中定義一次政策標記,平台就會在所有支援的查詢引擎中套用一致的遮蓋規則。
- 動態資料遮蓋:系統會在查詢期間評估使用者身分。獲得授權的使用者會看到原始值,而受限使用者則會在所有查詢引擎中收到
NULL輸出內容。 - 自動化資料歷程:Knowledge Catalog 會自動追蹤資料轉換作業,建立稽核追蹤記錄,不必編寫自訂記錄程式碼。
目標
- 建立 BigQuery 管理的 Apache Iceberg 資料表。Lakehouse 會管理 Iceberg 中繼資料。
- 使用政策標記設定中央安全規則,遮蓋及保護機密資料欄。
- 使用 Cloud 資源連結,將實體儲存空間權限與邏輯資料查詢分開。
- 透過 Managed Service for Apache Spark 安全地傳送查詢,避免外部引擎規避安全規則。
- 使用資料歷程探索資料的互動式地圖。
事前準備
開始之前,請先執行下列操作:
- 選取本教學課程的 Google Cloud 專案。
- 確認專案已啟用計費功能。
準備環境
本教學課程會使用 Cloud Shell,這是可在雲端執行的指令列環境。
在Google Cloud 控制台中,點選右上角工具列的「Cloud Shell」圖示。
設定專案變數:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"為兩個使用者角色 (零售分析師和零售經理) 定義變數:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)啟用必要的 Google Cloud API。
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
下載教學課程原始碼
從 Google Cloud DevRel 存放區下載本教學課程的 Python 指令碼:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
建立儲存空間 bucket
建立新的 bucket 來存放 Iceberg 資料表檔案:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
準備身分識別和安全防護機制
在本步驟中,您會建立 Cloud 資源連結,藉此設定運算委派。這個連線就像是安全的委派身分,BigQuery 會使用這個身分管理及讀取 Iceberg 檔案。這有助於確保個別使用者永遠無法直接存取 Cloud Storage 值區。
執行下列指令來建立連線、擷取系統自動產生的服務帳戶,並授予該帳戶管理 Iceberg 資料所需的權限:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
為兩種角色建立服務帳戶:分析師和管理員。下列指令會設定這些服務帳戶、允許目前使用者模擬這些帳戶進行測試,並授予特定角色來執行查詢及查看資料。
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
建立 Apache Iceberg 資料表
使用 BigQuery SQL 引擎建立 Apache Iceberg 資料表。雖然您使用 BigQuery 執行建立指令,但 Lakehouse 會做為管理層,儲存資料表中繼資料,並保護 Cloud Storage 中的基礎 Parquet 檔案。
建立資料表後,您可以快速轉換資料,瞭解 Knowledge Catalog 如何處理安全性,以及自動追蹤資料歷程。
建立 BigQuery 資料集
首先,請建立 BigQuery 資料集,將資料表分組:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
建立 Iceberg 資料表
執行下列指令,建立商品目錄和交易資料表:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
插入範例資料
將範例資料插入資料表:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
您現在有兩個 Iceberg 資料表,內含原始範例資料。資料湖倉會管理中繼資料,但實際的 Parquet 檔案位於 Cloud Storage 值區中。
轉換資料以自動產生歷程
將原始交易彙整為每日銷售摘要。這項轉換會建立新資料表,並產生 Knowledge Catalog 用來自動對應資料歷程的中繼資料。
Google Cloudecho "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
定義存取權管理政策
在正式環境中,以程式碼 (基礎架構即程式碼) 形式編寫安全性規則,可讓政策重複使用、進行版本管控,且更易於維護。在本節中,您將使用 Google Cloud Python SDK 自動定義及強制執行規則。
準備 Python 虛擬環境
設定獨立的 Python 虛擬環境,管理依附元件並確保指令碼穩定執行:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
定義安全分類和標記
首先,請為安全性規則奠定基礎。在這個步驟中,您會建立做為容器的分類,以及做為機密資料特定安全標籤的政策標記。
執行指令碼來建立資源:
python 1_create_taxonomy.py
查看 1_create_taxonomy.py,瞭解核心邏輯:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
明確設定 FINE_GRAINED_ACCESS_CONTROL 政策類型後,標準中繼資料標記就會轉換為嚴格的預設拒絕安全界線。根據預設,所有使用者都無法存取含有這個標記的任何資料欄。
建立動態資料遮蓋政策
現在,請定義沒有權限的使用者查詢已加上標籤的資料欄時會發生什麼情況。建立資料遮蓋政策,針對「分析師」角色,自動將私密值替換為 NULL。
執行指令碼來設定遮蓋規則:
python 2_create_masking.py
在 2_create_masking.py 中,指令碼會查閱您建立的政策標記 ID,並將資料政策套用至 Analyst 服務帳戶:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
授予資料的特殊存取權
由於您採用預設拒絕設定,因此沒有人可以讀取標記的資料欄。您必須明確授予授權使用者存取權。將「Fine-Grained Reader」角色授予「Manager」角色和您自己的帳戶。這樣一來,這些特定使用者就能略過遮蓋規則,讀取未遮蓋的資料。
執行指令碼來授予存取權:
python 3_grant_access.py
在 3_grant_access.py 中,指令碼會修改政策標記的身分與存取權管理政策:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
將安全標記附加至資料表結構定義
最後,您可以將邏輯規則連結至實際資料。更新 Iceberg 資料表結構定義,直接將政策標記附加至 amount 資料欄。完成後,Lakehouse 會立即對 bucket 中的 Iceberg 資料表檔案強制執行保護措施。
執行指令碼來附加政策標記:
python 4_attach_tag.py
查看4_attach_tag.py。這項指令碼會擷取 BigQuery 資料表結構定義、逐一檢查欄位,然後將標記附加至 amount 欄:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
驗證安全性政策
執行幾項測試查詢,確保權限運作正常。為證明 Knowledge Catalog 可在您切換查詢引擎時強制執行相同的安全性政策,進而做為通用內容引擎,您可以使用 BigQuery 和 Apache Spark 執行這些測試。
使用 BigQuery SQL 進行測試
首先,請直接在 BigQuery 中檢查政策。這是確認遮蓋規則和權限是否有效的最快方法。
以管理員身分查看
管理員角色具備精細的讀取權限。他們應該會看到表格中的所有詳細資料,包括 amount 欄中的值。
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
由於管理員具有「細部讀取者」角色,查詢會顯示原始金額值:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
以分析師身分查看
切換至「分析師」角色,然後執行相同查詢。
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
即使您執行相同的查詢,Knowledge Catalog 仍會遮蓋 amount 欄中的機密值:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
返回帳戶
清理 Cloud Shell 驗證狀態,返回管理員使用者。
gcloud config unset auth/impersonate_service_account
使用 Apache Spark 進行測試
如果使用者直接存取 Cloud Storage 中的資料檔案,通常會導致安全性問題。如果資料科學家使用 Apache Spark 直接讀取 Iceberg 資料表檔案,通常會略過您的規則,因為 Cloud Storage 只會瞭解值區層級的權限。
如要避免這種情況,請使用運算委派。使用 Spark-BigQuery 連接器,即可建立安全橋接器,透過 BigQuery Storage API 傳送所有 Spark 要求。這樣可確保 Knowledge Catalog 會先檢查權限並套用遮蓋規則,再將資料傳送至 Spark 叢集。
將 read_transactions.py 指令碼上傳至 Cloud Storage bucket,讓 Managed Service for Apache Spark 存取:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
檢查您上傳的指令碼中的核心邏輯:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
指令碼不會將 Spark 指向 Iceberg 檔案的 gs:// 路徑。指定 .format("bigquery") 後,BigQuery Storage API 會攔截讀取要求、檢查執行 Spark 工作的使用者身分、套用 Knowledge Catalog 遮蓋規則,並只將授權資料傳回 Spark DataFrame。
以管理員身分執行 Spark
以「經理」身分提交 Spark 工作。使用 Managed Service for Apache Spark 這項代管服務,執行 Spark 工作負載,不必費心管理自己的叢集:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
在終端機中查看工作輸出記錄。由於管理員具有「細部讀取者」角色,Spark 成功擷取了未遮蓋的金額:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
以分析師身分執行 Spark
最後,以「分析師」角色執行相同的 Spark 程式碼:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
再次查看記錄。即使分析師執行相同的 Spark 程式碼,BigQuery Storage API 仍會攔截要求並強制執行 Knowledge Catalog 政策。分析師的 Spark DataFrame 會顯示金額的 null。
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
您剛才證明,無論使用哪種查詢引擎,Knowledge Catalog 都會做為中央控制層,持續強制執行安全性政策。
透過自動化歷程記錄查看資料歷程
符合政策的 Lakehouse 不僅需要存取控制,還需要清楚的稽核追蹤記錄。資料歷程可協助您瞭解資料來源和轉換方式。回答「產生這份銷售報表時使用了哪些原始資料表?」等基本問題,有助於維持法規遵循狀態、快速偵錯資料管道,以及建構可靠的資料基礎。
您不必手動編寫複雜的記錄程式碼,Knowledge Catalog 會自動追蹤架構中的這個生命週期。舉例來說,您稍早在本教學課程中建立摘要資料表時,BigQuery 會立即擷取轉換詳細資料,並傳送至 Knowledge Catalog。這會動態更新資料的內容和記錄。
探索互動式歷程圖
查看 Knowledge Catalog 生成的互動式地圖。這張圖表顯示原始資料如何從 transactions 資料表流入 transactions_summary 資料表。由於 Knowledge Catalog 會以動態脈絡引擎的形式收集中繼資料,因此這張圖表會顯示資料稽核所需的可靠即時追溯性。
- 在 Google Cloud 控制台中,依序前往「Knowledge Catalog」>「Search」。
- 在搜尋列中輸入
lakehouse_retail_demo.transactions_summary,然後按一下資料表。 - 按一下「歷程」分頁標籤。
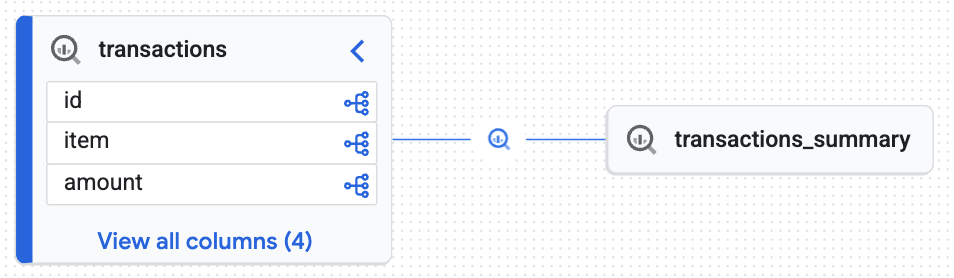
互動式圖表會確認目標資料表 (transactions_summary) 是衍生自原始受控管的 Iceberg 資料表 (transactions)。這個視覺化內容會顯示資料的端對端追蹤記錄。
清除所用資源
為避免產生持續性費用,請移除您為本教學課程建立的資源。
移除政策和中繼資料資產
如要刪除 BigQuery 資料集或 Cloud Storage 值區,必須先刪除資料控管政策和中繼資料資產。
執行 Python 清理指令碼:
python cleanup_governance.py
請查看存放區中的 cleanup_governance.py 指令碼,找出下列拆除邏輯。刪除順序至關重要。首先,請刪除資料遮蓋政策。接著刪除父項分類,系統就會自動移除所有基礎政策標記,避免發生資源依附元件錯誤。
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
移除身分、儲存空間和運算資產
刪除 BigQuery 資料表、Cloud Storage 儲存空間、服務帳戶和本機 Python 虛擬環境。
在 Cloud Shell 中複製並執行下列清理指令碼:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
清理專案檔案:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
結論
您已成功建構安全的資料湖倉!您使用 Lakehouse for Apache Iceberg 管理 Iceberg 資料表,確保 Cloud Storage 中的基礎資料表檔案安全無虞。將 Knowledge Catalog 設為通用內容引擎後,您可以在中央位置定義政策標記,並在 BigQuery SQL 和 Apache Spark 等不同查詢引擎中,一致地套用這些標記。最後,您使用即時資料歷程,自動追蹤資料的完整歷程。
後續步驟
- 為 AI 代理擷取資料內容: 使用 Context API 擷取資料內容。
- 深入探索資料歷程: 查看資料歷程資訊。
- 探索進階存取控管:如要實作更複雜的安全防護情境,請參閱這份官方文件,瞭解如何透過其他功能自訂 Lakehouse。
- Managed Service for Apache Spark:請參閱無伺服器 Spark 說明文件頁面,瞭解如何擴充資料管道,不必佈建叢集。
- 嘗試其他用途:試試其他 Knowledge Catalog 用途。