
Knowledge Catalog use cases
Run complex, natural language queries on enterprise data assets, using a discovery agent that makes Knowledge Catalog API calls (Python).
Generate AI-powered overviews for your data assets at scale, using an enrichment agent that makes Knowledge Catalog API calls (Python).
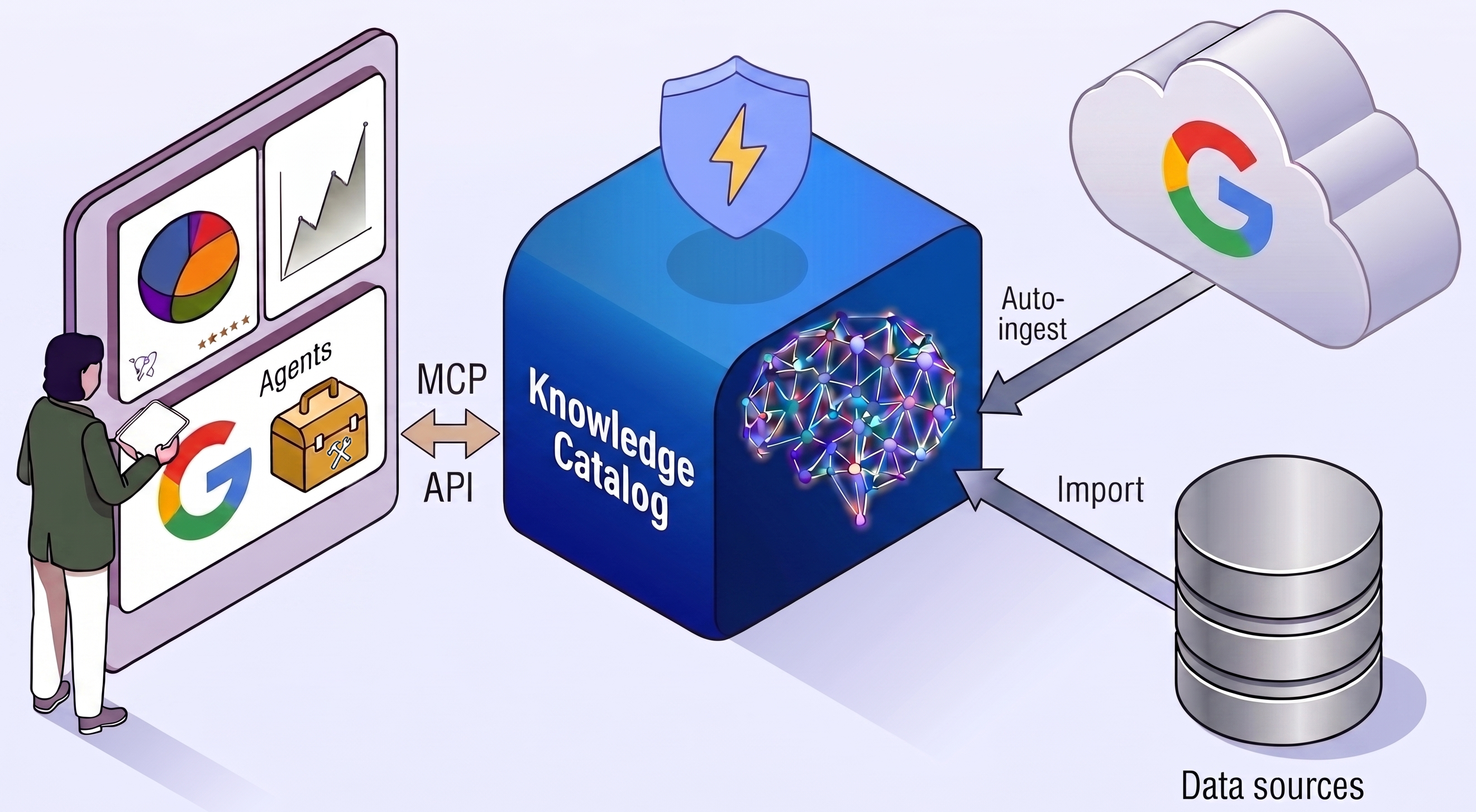
Architect cross-cloud analytics workflows across distributed data stores using AI agents and Knowledge Catalog as the context graph.
Attach structured, schema-driven metadata (aspects) and business definitions (glossaries) to your data assets (entries) using the Google Cloud console.
Create Apache Iceberg tables, enforce centralized data policies for column-level security, define security policies, and visualize automated data lineage.
Automatically ingest metadata from Google services like BigQuery.
Index metadata from custom data sources using open APIs.
With the Antigravity CLI, use natural language queries to profile data and generate quality rules, then deploy data quality rules as automated scans.
Verify that Knowledge Catalog can distinguish between source data and temporary derivatives, using natural language queries to the Antigravity CLI.
Identify how data transformations affect downstream resources, data integrity, and workflows.
Trace the flow of sensitive data back to the process that moves it from a trusted to an untrusted location.
Reduce storage costs by identifying assets that are not actively used as sources for other processes.
Retrieve pre-formatted, LLM-ready context for data assets using a single API request.