
Knowledge Catalog 是由 Gemini 驅動的資料目錄,可為整個資料資產提供通用業務脈絡和治理機制。這項功能會自動從結構化和非結構化資料中擷取語意,建立動態脈絡圖,讓 AI 代理以企業事實為依據,減少幻覺。資料團隊和 AI 開發人員可使用 Knowledge Catalog 探索資料、強制執行政策,以及擷取豐富的背景資訊,用於分析和自主應用程式。如需 Knowledge Catalog 的詳細逐步操作說明,請觀看內嵌影片。
Dataplex Universal Catalog 現已更名為 Knowledge Catalog
為進一步實現整合資料治理與生成式 AI 功能的願景,Dataplex Universal Catalog 現已更名為 Knowledge Catalog。產品名稱的演變代表從傳統的被動中繼資料登錄,轉向主動式 AI 輔助背景資訊圖表。
Dataplex 為何更名為 Knowledge Catalog
隨著機構加速採用生成式 AI,AI 代理需要深入瞭解業務脈絡,才能提供準確且符合事實的回覆。Knowledge Catalog 可消弭企業資料治理與 AI 代理工作流程之間的落差。
Dataplex 和 Knowledge Catalog 有何不同
Knowledge Catalog 更新內容反映了以 AI 為中心的新功能。與傳統的被動式目錄不同,Knowledge Catalog 會自動將中繼資料、業務邏輯和資料關係整理成整合式脈絡圖。這個圖表提供 AI 代理執行複雜工作所需的可靠企業真相。這項工具運用自動內容策展、經過驗證的範例查詢,以及本機和遠端 Model Context Protocol (MCP) 整合等功能。
維持不變的部分
現有的 Dataplex 部署作業、API 和設定仍可正常運作。資料探索、歷程、資料品質和商業詞彙等核心功能維持不變,且仍受支援。現有的中繼資料、層面和設定會自動轉移至新的知識目錄體驗,不需手動遷移、移動資料或停機。
API 和用戶端程式庫
重新命名為 Knowledge Catalog 後,現有的 API 端點、gcloud dataplex 指令或用戶端程式庫不會變更。您仍可使用 Knowledge Catalog API 和用戶端程式庫與 Knowledge Catalog 互動:
REST API。請參閱 Knowledge Catalog REST API 說明文件。
RPC API。請參閱 Knowledge Catalog RPC API 說明文件。
用戶端程式庫。使用 Knowledge Catalog 用戶端程式庫,以您選擇的語言開始使用 Knowledge Catalog。
gcloud 指令。使用
gcloud dataplex指令群組管理 Knowledge Catalog 資源。請參閱 gcloud Dataplex 指令參考資料。
Knowledge Catalog 的運作方式
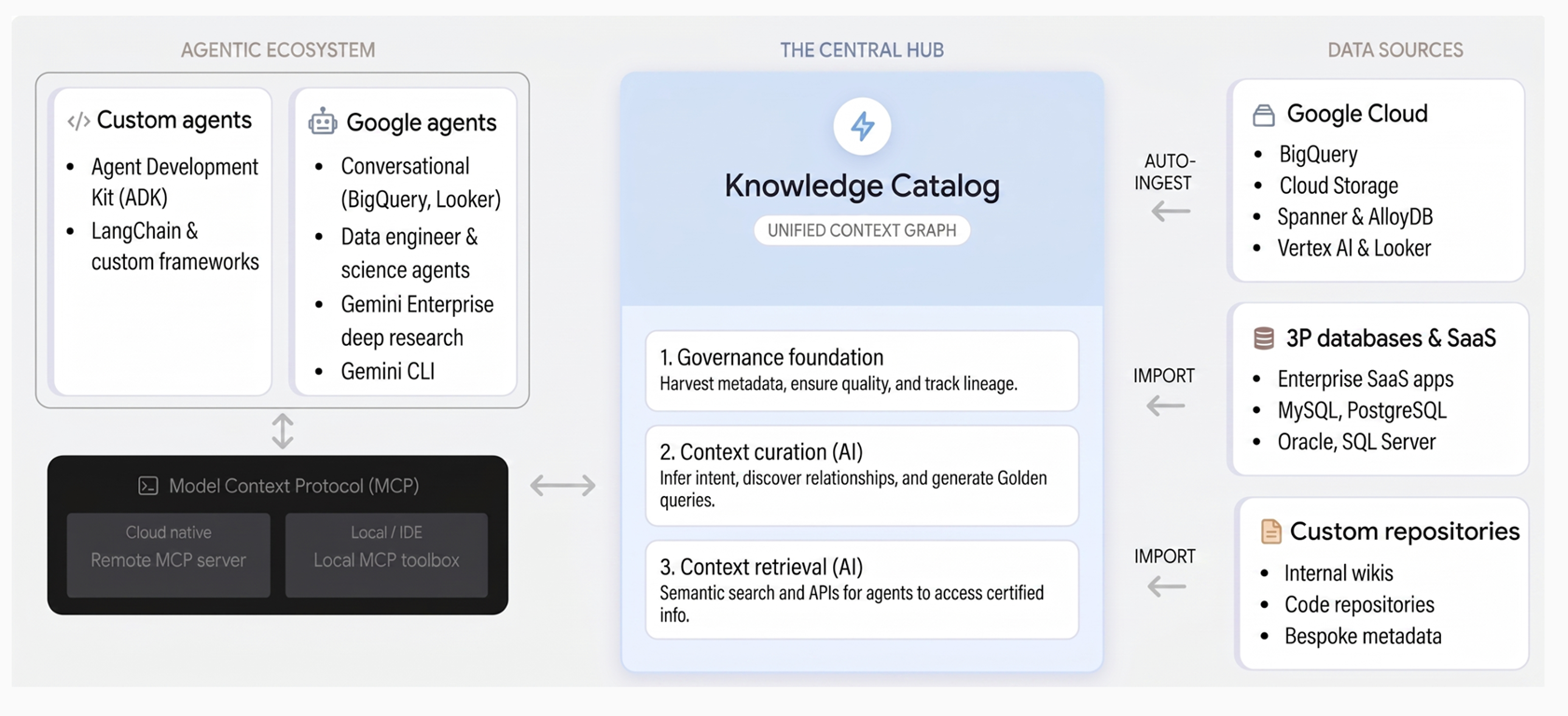
Knowledge Catalog 透過三大核心支柱,整合治理和脈絡資訊:
治理基礎。Knowledge Catalog 會自動從 BigQuery、AlloyDB for PostgreSQL 和 Spanner 等 Google Cloud 服務,以及第三方系統收集技術中繼資料。透過集中式組織詞彙、資料品質檢查、異常偵測和政策式治理,建立值得信賴的資料基礎。
脈絡收錄。這項服務會使用 Gemini 分析資料中的結構定義、查詢記錄和語意模型,推斷商家意圖。這項功能會生成自然語言說明、探索關係,並以範例查詢的形式,建議經過驗證的 SQL 模式,擷取複雜的商業邏輯。
檢索內容。AI 代理和應用程式可透過語意搜尋和支援 Model Context Protocol (MCP) 的工具,立即找出資產並擷取豐富的內容。這可讓代理存取機構的真實資訊,做出可靠的決策。
下圖說明知識目錄的架構,以及如何透過生成式 AI 工作流程整合資料控管:
常見用途
Knowledge Catalog 可協助資料工程師、資料科學家和 AI 開發人員解決資料管理和 AI 開發方面的難題:
充實 AI 資料。使用非結構化資料的資料洞察功能,從 Cloud Storage 中的 PDF 等非結構化檔案自動擷取中繼資料和實體。讓 AI 模型存取暗資料和機構知識。
減少 AI 幻覺。提供預先驗證的範例查詢和語意防護措施,讓 AI 代理執行複雜的資料擷取作業時,能獲得更確定的結果。
加快資料探索速度。使用語意搜尋和集中式脈絡圖,在不同來源中找出相關資料資產,用於分析和資料科學工作流程。
自動建立資料產品。推論資料資產之間的關係,將資產封裝成具備內建服務水準協議 (SLA) 和管理限制的獨立資料產品。
Knowledge Catalog 中的工作流程範例
如要瞭解如何建構內容圖表及管理資料資產,請參考下列線上零售公司使用 Knowledge Catalog 功能的範例:
探索及編目資料。這家零售商會自動擷取交易資料,並從 BigQuery、Pub/Sub 和 Cloud Storage 等 Google Cloud 服務收集中繼資料。這項服務也會從自訂商品目錄資料庫匯入中繼資料,建立整個零售資料資產的整合式資料檢視。詳情請參閱「探索資料」。
搜尋資料資產。資料科學家使用 Knowledge Catalog 搜尋引擎,透過多面向篩選、自然語言語意搜尋和邏輯運算子,找出所需的確切客戶資料資產。詳情請參閱「搜尋資料資產」。
擴充資料增添業務情境資訊。資料治理團隊使用組織詞彙定義零售業術語 (例如「生命週期價值:LTV」或「SKU」),並運用 AI 輔助的資料洞察功能,自動產生新產品資料表的說明。他們也會手動將結構化自訂中繼資料和標記 (切面) 統一套用至資產。詳情請參閱「管理層面及豐富中繼資料」和「管理組織詞彙」。
透過歷程瞭解資料關係。工程團隊會自動追蹤資料歷程,瞭解訂單資料在系統間的移動、轉換和使用情形。他們會使用歷程圖表排解報表管道問題、對結帳錯誤執行根本原因分析,並確保法規遵循。詳情請參閱「資料歷程總覽」。
剖析資料並評估品質。這家零售商使用自動資料剖析功能,找出 BigQuery 價格表中的模式和異常情況。他們會定義及執行資料品質檢查,確保客戶運送地址準確、完整且可靠,以供後續 AI 和出貨工作負載使用。詳情請參閱「資料剖析總覽」和「自動分析資料品質總覽」。
管理及共用資料產品。資料平台團隊會將區域銷售資產及其相關中繼資料、品質分數和歷程資訊,封裝成精選的「客戶 360」資料產品,供行銷和庫存團隊發掘及使用。詳情請參閱「資料產品總覽」。
Google Cloud 生態系統中的 Knowledge Catalog
建構資料基礎時,請務必瞭解 Knowledge Catalog 如何與相關Google Cloud 服務整合:
| 服務 | 主要角色 | 使用時機 |
|---|---|---|
| Knowledge Catalog | 代理程式背景資訊和資料治理 | 可用於編目中繼資料、管理資料品質,以及為 AI 代理提供語意基礎。 |
| BigQuery | 企業資料倉儲 | 用於儲存、查詢及分析龐大的資料集。Knowledge Catalog 會為 BigQuery 資料加上業務背景資訊。 |
| Vertex AI | AI 與機器學習平台 | 用於建構及部署機器學習模型和 AI 代理程式。代理會使用 Knowledge Catalog API 擷取準確的企業脈絡資訊。 |
| Cloud Storage | 非結構化資料儲存空間 | 用於儲存原始檔案。Knowledge Catalog 會掃描 Cloud Storage bucket,擷取可搜尋的中繼資料和實體。 |
核心概念
如要有效使用 Knowledge Catalog,請瞭解下列重要概念:
脈絡圖。動態整合式地圖,顯示資料與您業務的關聯。將技術架構與業務實體和非結構化知識連結。
查詢範例。預先產生並經過驗證的 SQL 模式,可擷取複雜的商業邏輯。無論是人類還是 AI 代理程式,都能透過這些查詢準確查詢資料,不必重新發明複雜的資料表聯結。
Model Context Protocol (MCP)。這項開放標準可讓 AI 代理程式探索並適應性地使用可用工具。Knowledge Catalog 會使用 MCP 工具,直接向代理提供經過認證的機構事實,並提供遠端和本機 MCP 伺服器,以符合無障礙和安全性需求。
-- Example: An example query retrieved by an AI agent to ensure accurate revenue calculation
SELECT customer_id, SUM(transaction_amount) AS total_revenue
FROM `sales.processed_transactions`
WHERE transaction_status = 'COMPLETED'
GROUP BY customer_id;
擷取
Knowledge Catalog 會自動從下列Google Cloud 來源擷取中繼資料。對於 AlloyDB for PostgreSQL 和 Cloud SQL 等部分服務,您必須先啟用 Knowledge Catalog 整合功能,才能擷取中繼資料:
數據分析和湖倉
- BigQuery 資料集、資料表、檢視區塊、模型、常式、連線和連結的資料集
- BigQuery sharing (舊稱 Analytics Hub) 交易所和項目
- Dataform 存放區和程式碼資產
- Dataproc Metastore 服務、資料庫和資料表
Iceberg REST 目錄資料表 (包括 Google Cloud Lakehouse 執行階段目錄 IRC、Databricks Unity IRC、AWS Glue Data Catalog IRC 和 Snowflake Horizon IRC)
AI 與機器學習
- Vertex AI 模型、資料集、特徵群組、特徵檢視畫面和網路商店執行個體
商業智慧
- Looker (Google Cloud Core) 執行個體、資訊主頁、資訊主頁元素、Look、LookML 專案、模型、探索和檢視畫面 (預先發布版)
資料庫
- Bigtable 執行個體、叢集和資料表 (包括資料欄系列詳細資料)
- Spanner 執行個體、資料庫、資料表和檢視區塊
串流和訊息
- Pub/Sub 主題
非結構化資料
作業資料庫
- AlloyDB for PostgreSQL 叢集、執行個體、資料庫、結構定義、表格和檢視區塊 (預先發布版)。Knowledge Catalog 只會從 AlloyDB for PostgreSQL 主要執行個體擷取中繼資料,不會從唯讀副本擷取。詳情請參閱「使用 Knowledge Catalog 管理 AlloyDB for PostgreSQL 資源」。
- Cloud SQL 執行個體、資料庫、結構定義、資料表、檢視區塊。 知識目錄只會從 Cloud SQL 主要執行個體擷取中繼資料,不會從唯讀備用資源擷取。詳情請參閱「使用 Knowledge Catalog 管理 Cloud SQL 資源」。
如要將第三方來源的中繼資料匯入 Knowledge Catalog,可以使用 Knowledge Catalog 連接器或受管理連線管道。詳情請參閱「關於 Knowledge Catalog 連接器」和「受管理連線總覽」。
限制
規劃部署作業時,請考量下列限制:
支援的整合功能。雖然 Knowledge Catalog 支援主要第三方系統,但某些自動語意擷取作業可能僅限於內建 Google Cloud 服務。
配額限制。標準 Google Cloud API 配額適用於內容擷取和中繼資料擷取作業。