
Quando você armazena seus dados em diferentes sistemas de armazenamento, gerenciar a segurança fragmentada pode se tornar um grande desafio. Você quer garantir que informações sensíveis, como registros financeiros, permaneçam protegidas, mesmo que sejam armazenadas em formatos abertos como o Apache Iceberg no Google Cloud armazenamento.
É fundamental que suas medidas de segurança funcionem perfeitamente em vários mecanismos de consulta, como o SQL do BigQuery e o Apache Spark. Nessa arquitetura, o Knowledge Catalog resolve isso funcionando como um mecanismo de contexto universal. Ele contém os metadados necessários para garantir que seu contexto de segurança seja aplicado de maneira consistente, não importa qual mecanismo consulte os dados.
Neste tutorial, você vai criar um data lakehouse seguro para resolver esses desafios. Usando scripts, você define políticas de segurança e vê o Knowledge Catalog (antigo Dataplex Universal Catalog) e o Lakehouse para Apache Iceberg trabalhando juntos para aplicar as políticas em diferentes mecanismos de consulta.
Informações gerais da arquitetura
Para configurar o controle de acesso refinado em um formato de tabela aberta, como o Apache Iceberg, é preciso criar uma arquitetura de segurança estrita e unificada.
Com esse design, o Knowledge Catalog atua como o plano de controle central. O Knowledge Catalog aplica dinamicamente seu contexto de segurança em todos os mecanismos compatíveis.
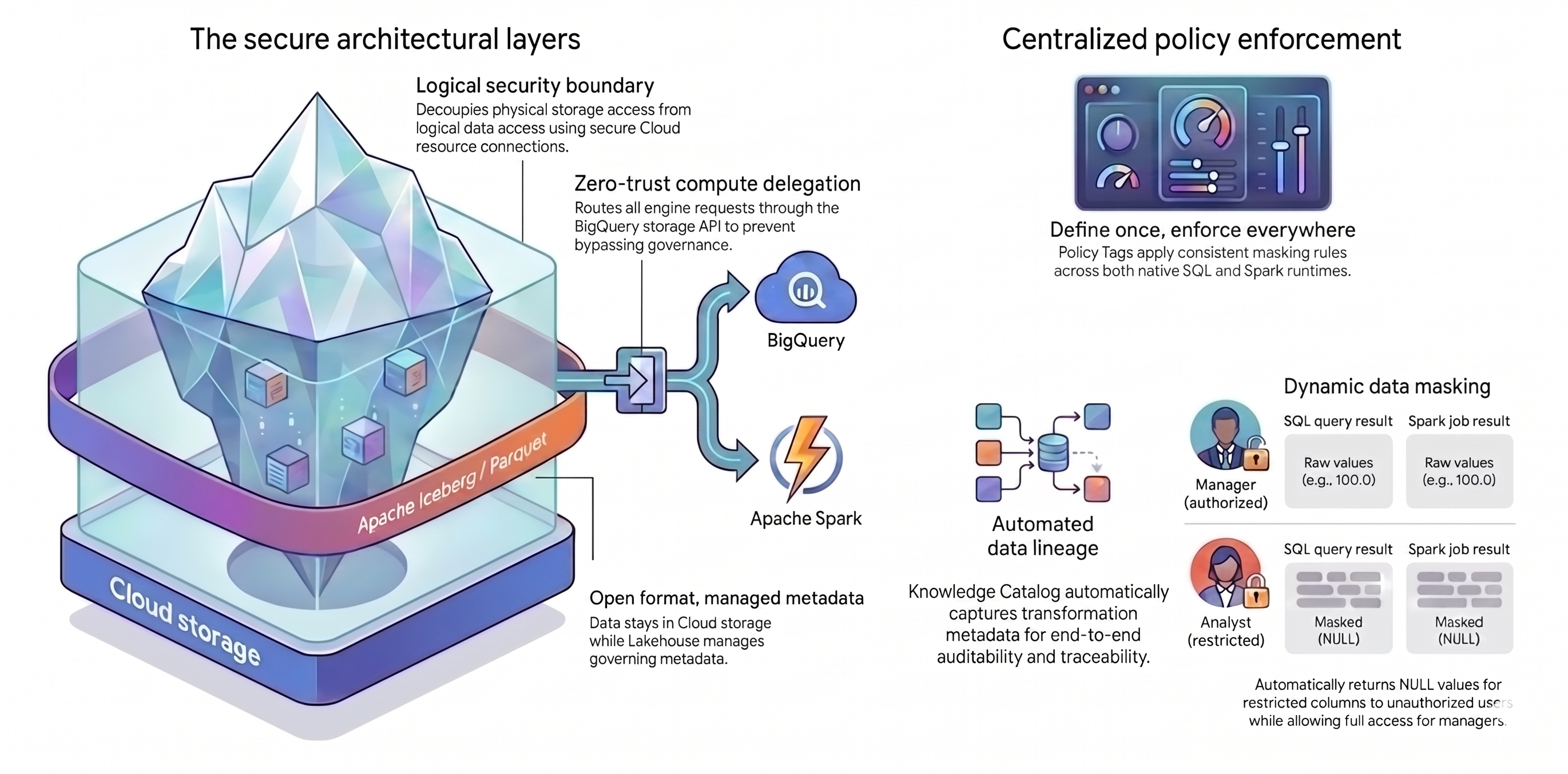
Este tutorial se baseia em dois conceitos principais para criar essa arquitetura unificada:
- Camadas arquitetônicas seguras:em vez de permitir que usuários ou mecanismos de consulta acessem diretamente seus buckets do Cloud Storage, crie uma base segura e em camadas com base nos seguintes atributos:
- Formato aberto com metadados gerenciados:seus dados permanecem no formato aberto do Apache Iceberg (Parquet) no Cloud Storage, enquanto o Lakehouse para Apache Iceberg gerencia os metadados da tabela.
- Limite de segurança lógica:você separa as permissões de armazenamento das consultas de dados usando uma conexão a recursos do Cloud segura. Você nunca concede aos usuários finais acesso direto aos arquivos.
- Delegação de computação:para evitar que os mecanismos de consulta ignorem suas regras, encaminhe todas as solicitações de dados pela API BigQuery Storage. O encaminhamento de solicitações pela API BigQuery Storage garante que o Knowledge Catalog possa interceptar e aplicar políticas, mesmo para mecanismos de processamento externos.
- Aplicação centralizada de políticas:com uma base segura, use o Knowledge Catalog para aplicar suas regras de forma universal:
- Defina uma vez, aplique em todos os lugares:você define tags de política no Knowledge Catalog apenas uma vez, e a plataforma aplica regras de mascaramento consistentes em todos os mecanismos de consulta compatíveis.
- Máscara de dados dinâmica:o sistema avalia a identidade do usuário durante as consultas. Os usuários autorizados veem valores brutos, enquanto os usuários restritos recebem saídas
NULLem todos os mecanismos de consulta. - Linhagem de dados automatizada:o Knowledge Catalog rastreia transformações de dados automaticamente, criando um rastreamento de auditoria sem código de geração de registros personalizado.
Objetivos
- Crie tabelas do Apache Iceberg gerenciadas pelo BigQuery. O Lakehouse gerencia os metadados do Iceberg.
- Configure regras de segurança centralizadas usando tags de política para mascarar e proteger colunas sensíveis.
- Separe as permissões de armazenamento físico das consultas de dados lógicos usando uma conexão a recursos do Cloud.
- Encaminhe consultas com segurança pelo Serviço Gerenciado para Apache Spark para que mecanismos externos não possam ignorar suas regras de segurança.
- Analise um mapa interativo dos seus dados usando a linhagem de dados.
Antes de começar
Antes de começar, faça o seguinte:
- Selecione um projeto do Google Cloud para este tutorial.
- Confirme se o faturamento está ativado para o projeto.
Preparar o ambiente
Este tutorial usa o Cloud Shell, um ambiente de linha de comando executado na nuvem.
No Google Cloud Console, clique no ícone do Cloud Shell na barra de ferramentas superior direita.
Defina as variáveis do projeto:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"Defina variáveis para duas personas de usuário, um analista e um gerente de varejo:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)Ative as APIs Google Cloud necessárias.
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
Baixar o código-fonte do tutorial
Faça o download dos scripts Python para este tutorial no repositório Google Cloud DevRel:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Criar um bucket de armazenamento
Crie um bucket para armazenar arquivos de tabela Iceberg:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Preparar identidades e segurança
Nesta etapa, você configura a delegação de computação criando uma conexão a recursos do Cloud. Essa conexão funciona como uma identidade segura e delegada que o BigQuery usa para gerenciar e ler seus arquivos do Iceberg. Isso ajuda a garantir que os usuários individuais nunca tenham acesso direto ao bucket do Cloud Storage.
Execute os comandos a seguir para criar a conexão, recuperar a conta de serviço gerada automaticamente e conceder a ela as permissões necessárias para gerenciar seus dados do Iceberg:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Crie contas de serviço para duas personas: Analista e Gerente. Os comandos a seguir configuram essas contas de serviço, permitem que seu usuário atual as represente para teste e concedem a elas papéis específicos para executar consultas e visualizar dados.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Criar tabelas do Apache Iceberg
Use o mecanismo SQL do BigQuery para criar tabelas do Apache Iceberg. Embora você execute os comandos de criação com o BigQuery, o Lakehouse atua como a camada de gerenciamento que armazena os metadados da tabela e protege os arquivos Parquet subjacentes no Cloud Storage.
Depois de criar as tabelas, execute uma transformação rápida para ver como o Knowledge Catalog lida com a segurança e rastreia automaticamente a jornada dos seus dados.
Criar um conjunto de dados do BigQuery
Primeiro, crie um conjunto de dados do BigQuery para agrupar suas tabelas:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Criar as tabelas do Iceberg
Execute os comandos a seguir para criar tabelas de inventário e transação:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Inserir dados de amostra
Insira dados de amostra nas tabelas:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Agora você tem duas tabelas do Iceberg com dados de amostra brutos. O lakehouse gerencia os metadados, mas os arquivos Parquet reais estão no seu bucket do Cloud Storage.
Transformar dados para linhagem automatizada
Agregue suas transações brutas em um resumo de vendas diárias. Essa transformação cria uma nova tabela e gera os metadados que o Knowledge Catalog usa para mapear automaticamente a jornada dos seus dados.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Definir políticas de governança de acesso
Em um ambiente de produção, escrever suas regras de segurança como código (infraestrutura como código) torna suas políticas repetíveis, controladas por versão e mais fáceis de manter. Nesta seção, você vai usar o SDK Google Cloud Python para definir e aplicar suas regras automaticamente.
Preparar o ambiente virtual do Python
Configure um ambiente virtual Python isolado para gerenciar suas dependências e garantir que os scripts sejam executados de maneira confiável:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Definir taxonomias e tags de segurança
Comece criando a base das suas regras de segurança. Nesta etapa, você vai criar uma taxonomia para funcionar como um contêiner e uma tag de política para servir como um rótulo de segurança específico para dados sensíveis.
Execute o script para criar os recursos:
python 1_create_taxonomy.py
Revise 1_create_taxonomy.py para conferir a lógica principal:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Ao definir explicitamente o tipo de política FINE_GRAINED_ACCESS_CONTROL, você transforma uma tag de metadados padrão em um limite de segurança de negação por padrão estrita. Por padrão, qualquer coluna com essa tag nega o acesso a todos os usuários.
Criar uma política de mascaramento dinâmico de dados
Agora, defina o que acontece quando alguém sem privilégios consulta uma coluna marcada. Crie uma política de mascaramento de dados que substitua automaticamente valores sensíveis por NULL para a persona Analista.
Execute o script para configurar a regra de mascaramento:
python 2_create_masking.py
Em 2_create_masking.py, o script procura o ID da tag de política que você criou e aplica a política de dados à conta de serviço Analyst:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Conceder acesso privilegiado aos seus dados
Devido à configuração de negação por padrão, ninguém pode ler a coluna marcada. É preciso conceder acesso explicitamente aos usuários autorizados. Conceda à persona Gerente e à sua conta o papel de Leitor refinado. Isso permite que esses usuários específicos ignorem as regras de mascaramento e leiam os dados não mascarados.
Execute o script para conceder acesso:
python 3_grant_access.py
Em 3_grant_access.py, o script modifica a política do IAM da tag de política:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Anexar tags de segurança ao esquema da tabela
Por fim, você pode conectar suas regras lógicas aos dados reais. Atualize o esquema da tabela do Iceberg para anexar a tag de política diretamente à coluna amount. Depois disso, o Lakehouse aplica instantaneamente as proteções aos arquivos de tabela do Iceberg no bucket.
Execute o script para anexar a tag de política:
python 4_attach_tag.py
Revise 4_attach_tag.py. O script busca o esquema da tabela do BigQuery, itera pelos campos e anexa a tag especificamente à coluna amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Verificar suas políticas de segurança
Execute algumas consultas de teste para garantir que as permissões funcionem conforme o esperado. Para provar que o Knowledge Catalog atua como um mecanismo de contexto universal ao aplicar as mesmas políticas de segurança quando você muda de mecanismos de consulta, execute estes testes usando o BigQuery e o Apache Spark.
Teste com o SQL do BigQuery
Comece verificando suas políticas diretamente no BigQuery. Essa é a maneira mais rápida de confirmar se suas regras e permissões de mascaramento estão ativas.
Verificar como administrador
A persona Gerente tem acesso privilegiado e refinado de leitura. Eles precisam ver todos os detalhes da tabela, incluindo os valores na coluna amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Como o gerente tem o papel de leitor refinado, a consulta mostra os valores brutos de quantidade:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Verificar como o analista
Mude para o perfil Analista e execute a mesma consulta.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Mesmo que você execute a mesma consulta, o Knowledge Catalog vai mascarar os valores sensíveis na coluna amount:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Voltar para sua conta
Limpe o estado de autenticação do Cloud Shell para voltar ao usuário administrador.
gcloud config unset auth/impersonate_service_account
Teste com o Apache Spark
A segurança geralmente é violada quando os usuários acessam diretamente os arquivos de dados no Cloud Storage. Se um cientista de dados usar o Apache Spark para ler diretamente os arquivos de tabela do Iceberg, ele normalmente vai ignorar suas regras porque o Cloud Storage só entende permissões no nível do bucket.
Para evitar isso, use a delegação de computação. Ao usar o conector Spark-BigQuery, você cria uma ponte segura que encaminha todas as solicitações do Spark pela API BigQuery Storage. Isso garante que o Knowledge Catalog verifique as permissões e aplique regras de mascaramento antes que os dados cheguem ao cluster do Spark.
Faça upload do script read_transactions.py para o bucket do Cloud Storage para que o Serviço Gerenciado para Apache Spark possa acessá-lo:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Revise a lógica principal no script que você enviou:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
O script não aponta o Spark para o caminho gs:// dos arquivos do Iceberg. Ao especificar .format("bigquery"), a API BigQuery Storage intercepta a solicitação de leitura, verifica a identidade do usuário que está executando o job do Spark, aplica as regras de mascaramento do Knowledge Catalog e retorna apenas os dados autorizados ao DataFrame do Spark.
Executar o Spark como gerente
Envie um job do Spark como a persona Gerente. Use o Serviço Gerenciado para Apache Spark, um serviço gerenciado que permite executar cargas de trabalho do Spark sem o trabalho de gerenciar seus próprios clusters:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Analise os registros de saída do job no terminal. Como o gerente tem o papel de leitor refinado, o Spark recupera os valores não mascarados:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Executar o Spark como analista
Por fim, execute o mesmo código do Spark que a persona Analista:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Analise os registros de novo. Mesmo que o analista tenha executado o mesmo código do Spark, a API BigQuery Storage interceptou a solicitação e aplicou a política do Knowledge Catalog. O DataFrame do Spark do analista mostra null para os valores.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Você acabou de provar que, como seu plano de controle central, o Knowledge Catalog aplica suas políticas de segurança de maneira consistente, independente do mecanismo de consulta usado.
Acompanhe a jornada dos seus dados com a linhagem automatizada
Um lakehouse em conformidade com a política exige mais do que apenas controles de acesso. Ele também precisa de um rastreamento de auditoria claro. A linhagem de dados ajuda você a entender de onde vêm seus dados e como eles são transformados. Responder a perguntas essenciais, como "Quais tabelas brutas foram usadas para gerar este relatório de vendas?", ajuda você a manter a conformidade, depurar pipelines de dados rapidamente e criar uma base de dados confiável.
Em vez de escrever manualmente um código de geração de registros complexo, o Knowledge Catalog rastreia automaticamente esse ciclo de vida em toda a arquitetura. Por exemplo, quando você criou uma tabela de resumo no início deste tutorial, o BigQuery capturou os detalhes da transformação instantaneamente e os enviou para o Knowledge Catalog. Isso atualiza dinamicamente o contexto e o histórico dos seus dados.
Analisar o gráfico de linhagem interativo
Confira o mapa interativo gerado pelo Knowledge Catalog. Ele mostra como os dados brutos fluem da tabela transactions para a tabela transactions_summary. Como o Knowledge Catalog coleta metadados como um mecanismo de contexto dinâmico, esse gráfico mostra a rastreabilidade confiável e em tempo real necessária para uma auditoria de dados.
- No console Google Cloud , acesse Knowledge Catalog > Pesquisar.
- Digite
lakehouse_retail_demo.transactions_summaryna barra de pesquisa e clique na tabela. - Clique na guia Linhagem.
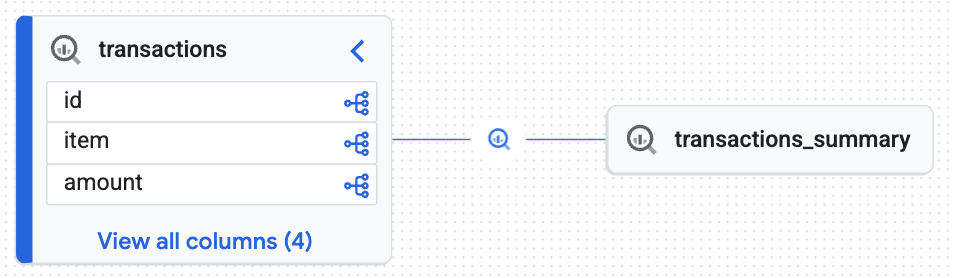
O gráfico interativo confirma que a tabela de destino (transactions_summary) deriva da tabela bruta gerenciada do Iceberg (transactions). Essa visualização demonstra a rastreabilidade de ponta a ponta dos seus dados.
Limpar
Para evitar cobranças contínuas, remova os recursos criados para este tutorial.
Remover recursos de política e metadados
Antes de excluir o conjunto de dados do BigQuery ou o bucket do Cloud Storage, é necessário excluir as políticas de governança de dados e os recursos de metadados.
Execute o script de limpeza do Python:
python cleanup_governance.py
Analise o script cleanup_governance.py do repositório para encontrar a seguinte lógica de encerramento. A ordem de exclusão é essencial. Primeiro, exclua a política de mascaramento de dados. Em seguida, exclua a taxonomia principal, o que remove automaticamente todas as tags de política subjacentes e evita erros de dependência de recursos.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Remover identidades, armazenamento e recursos de computação
Exclua as tabelas do BigQuery, os buckets do Cloud Storage, as contas de serviço e o ambiente virtual Python local.
Copie e execute o seguinte script de limpeza no Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
Limpe os arquivos do projeto:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
Conclusão
Você criou um data lakehouse seguro. Ao usar o Lakehouse para Apache Iceberg para gerenciar tabelas do Iceberg, você manteve os arquivos de tabela subjacentes seguros no Cloud Storage. Ao estabelecer o Knowledge Catalog como seu mecanismo de contexto universal, você definiu tags de política em um local central e as aplicou de forma consistente em diferentes mecanismos de consulta, como o SQL do BigQuery e o Apache Spark. Por fim, você rastreou automaticamente toda a jornada dos seus dados com a linhagem de dados em tempo real.
A seguir
- Recuperar contexto de dados para agentes de IA:recupere o contexto de dados com a API Context.
- Análise detalhada da linhagem de dados:consulte informações sobre a linhagem de dados.
- Conheça o controle de acesso avançado:para implementar cenários de segurança mais complexos, consulte a documentação oficial sobre como personalizar o Lakehouse com recursos extras.
- Serviço gerenciado para Apache Spark:descubra como escalonar pipelines de dados sem provisionar clusters na página de documentação do Spark sem servidor.
- Teste outros casos de uso: confira outros casos de uso do Knowledge Catalog.