
Consulte a linhagem de dados para entender as relações entre os recursos do projeto e os processos que os criaram. Essas relações mostram como os recursos de dados, como tabelas e conjuntos de dados, são transformados por processos como consultas e pipelines. Este guia descreve como ver detalhes da linhagem de dados no console Google Cloud ou recuperá-los usando a API Data Lineage.
Papéis e permissões
A linhagem de dados rastreia informações de linhagem automaticamente quando você ativa a API Data Lineage. Não é necessário ter funções de administrador ou editor para capturar a linhagem dos seus recursos de dados.
Para ver a linhagem de dados, você precisa de permissões específicas do Identity and Access Management (IAM). As informações de linhagem são capturadas em vários projetos, então você precisa de permissões em vários deles.
Ao visualizar a linhagem no Knowledge Catalog, no BigQuery ou na Vertex AI, você precisa de permissões para acessar as informações de linhagem no projeto em que está visualizando.
Ao visualizar a linhagem registrada em outros projetos, você precisa de permissões para acessar as informações de linhagem nos projetos em que ela foi registrada.
Para receber as permissões necessárias para visualizar a linhagem de dados, peça ao administrador para conceder a você os seguintes papéis do IAM:
- Leitor da linhagem de dados (
roles/datalineage.viewer) no projeto em que a linhagem é registrada e no projeto em que ela é visualizada -
Acessar detalhes da tabela do BigQuery:
Leitor de dados do BigQuery (
roles/bigquery.dataViewer) no projeto de armazenamento da tabela -
Ver detalhes do job do BigQuery:
Leitor de recursos do BigQuery (
roles/bigquery.resourceViewer) no projeto de computação do job -
Confira detalhes de outros recursos catalogados:
Leitor do Dataplex Catalog (
roles/dataplex.catalogViewer) no projeto em que as entradas do catálogo estão armazenadas.
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Esses papéis predefinidos contêm as permissões necessárias para ver a linhagem de dados. Para acessar as permissões exatas necessárias, expanda a seção Permissões necessárias:
Permissões necessárias
As seguintes permissões são necessárias para ver a linhagem de dados:
-
Confira os detalhes da tabela do BigQuery:
bigquery.tables.get: o projeto de armazenamento da tabela -
Ver detalhes do job do BigQuery:
bigquery.jobs.get: o projeto de computação do job
Essas permissões também podem ser concedidas com funções personalizadas ou outros papéis predefinidos.
Tipos de visualizações de linhagem de dados
É possível ver as informações de linhagem como um gráfico interativo ou uma lista estruturada no console Google Cloud .
Para uma descrição detalhada dos elementos do gráfico (como nós, arestas, ícones de processo e rótulos) e das colunas disponíveis nas visualizações de lista, consulte Sobre a visualização da linhagem de dados no Knowledge Catalog.
Ativar a linhagem de dados
Ative a linhagem de dados para começar a rastrear automaticamente as informações de linhagem dos sistemas compatíveis. Por padrão, ativar a API ativa o rastreamento de linhagem para a maioria dos serviços compatíveis. Para controlar a ingestão de linhagem do Serviço Gerenciado para Apache Spark, consulte Controlar a ingestão de linhagem de um serviço.
É necessário ativar a API Data Lineage no projeto em que você visualiza a linhagem e nos projetos em que ela é registrada. Para mais informações, consulte Tipos de projetos.
- Para capturar informações de linhagem, siga estas etapas:
-
No console do Google Cloud , na página Seletor de projetos, selecione o projeto em que você quer registrar a linhagem.
Ative a API Data Lineage.
- Repita as etapas anteriores para cada projeto em que você quer registrar a linhagem.
-
No projeto em que você vê a linhagem, ative a API Data Lineage e a API Dataplex.
Controlar a ingestão de linhagem de dados para um serviço
É possível ativar ou desativar seletivamente o rastreamento automático de linhagem para serviços específicos no nível do projeto, da pasta ou da organização.
Para detalhes sobre como essas configurações são aplicadas de maneira hierárquica na árvore de recursos, consulte Controlar a ingestão de linhagem.
Pré-requisitos
Para controlar a ingestão de linhagem, use a API Data Lineage. Verifique se você tem um projeto cliente configurado para faturamento e cota, porque a API Data Lineage é uma API baseada em cliente.
Ative a API
datalineage.googleapis.comno projeto do cliente. Para mais informações, consulte Ativar a linhagem de dados.Defina o projeto do cliente. Para os exemplos a seguir, use o cabeçalho
X-Goog-User-Project. Para mais informações, consulte Parâmetros do sistema.
Receber configuração atual
Para verificar se a ingestão de linhagem está ativada para um recurso ou para receber o valor etag antes de modificar a configuração, recupere a configuração atual.
C#
C#
Antes de testar esta amostra, siga as instruções de configuração do C# no Guia de início rápido do Data Lineage: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Data Lineage C#.
Para autenticar no Data Lineage, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Go
Go
Antes de testar esta amostra, siga as instruções de configuração do Go no Guia de início rápido do Data Lineage: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Data Lineage Go.
Para autenticar no Data Lineage, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Java
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do Data Lineage: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Data Lineage Java.
Para autenticar no Data Lineage, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do Data Lineage: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API Data Lineage Python.
Para autenticar no Data Lineage, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
gcloud
Para conferir a configuração de linhagem atual, use o comando
gcloud datalineage config describe. É possível recuperar a configuração de um projeto, uma pasta ou uma organização.
O exemplo a seguir mostra como receber a configuração do projeto atual:
gcloud datalineage config describe
Por exemplo, para receber a configuração de um projeto específico, use a flag --project:
gcloud datalineage config describe --project=PROJECT_ID
Substitua:
PROJECT_ID: o ID do projeto cuja configuração você quer ver.
Para conferir a configuração atual de ingestão de linhagem de um serviço em uma pasta ou organização, substitua --project= por:PROJECT_ID
--folder=se você quiser ver as configurações de ingestão de dados de uma pasta.FOLDER_ID--organization=se você quiser ver as configurações de ingestão de dados de uma organização.ORGANIZATION_ID
REST
Para conferir a configuração de linhagem de dados atual, use o método
projects.locations.config.get. É possível recuperar a configuração de um projeto, uma pasta ou uma organização.
O exemplo a seguir mostra como receber a configuração de um projeto:
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
CLIENT_PROJECT_ID: o ID do projeto do cliente usado para faturamento ou cotas.PROJECT_ID: o ID do projeto cuja configuração você quer ver.
Método HTTP e URL:
GET https://datalineage.googleapis.com/v1/projects/PROJECT_ID/locations/global/config
Para enviar a solicitação, expanda uma destas opções:
O comando retorna uma das seguintes saídas:
- Se você não fornecer nenhuma configuração de ingestão de linhagem, vai receber uma saída com um objeto
ingestionvazio:{ "name": "projects/123456789012/locations/global/config", "ingestion": {} }
Isso significa que o serviço usa a configuração padrão de ingestão de linhagem. Neste exemplo, a configuração de ingestão de linhagem do Serviço Gerenciado para Apache Spark é
enabled. - Se você ativar a ingestão de linhagem explicitamente, vai receber a seguinte saída:
{ "name": "projects/123456789012/locations/global/config", "ingestion": { "rules": [ { "integrationSelector": { "integration": "DATAPROC" }, "lineageEnablement": { "enabled": true } } ] }, "etag": "1a2b3c4d5e" }
- Se a ingestão de linhagem estiver desativada, você vai receber a seguinte saída:
{ "name": "projects/123456789012/locations/global/config", "ingestion": { "rules": [ { "integrationSelector": { "integration": "DATAPROC" }, "lineageEnablement": { "enabled": false } } ] }, "etag": "1a2b3c4d5e" }
Para receber a configuração de uma pasta ou organização, substitua
projects/ por PROJECT_IDfolders/ ou FOLDER_IDorganizations/.ORGANIZATION_ID
O campo etag na resposta é um checksum gerado pelo servidor com base no valor atual da configuração. Ao atualizar uma configuração usando
o método patch, inclua o valor etag retornado de uma
solicitação get recente no corpo da solicitação. Se você fornecer o etag,
o Knowledge Catalog vai usá-lo para verificar se a configuração não mudou
desde sua última solicitação de leitura. Se houver uma incompatibilidade, a solicitação de atualização
vai falhar. Isso evita que você substitua sem querer as configurações feitas por outros usuários em cenários de leitura-modificação-gravação. Se você não fornecer um etag na solicitação patch, o Knowledge Catalog vai substituir a configuração incondicionalmente.
Desativar a ingestão de linhagem para um serviço
Para gerenciar custos, aplicar políticas de governança de dados ou excluir projetos de desenvolvimento e outras cargas de trabalho que não se beneficiam do rastreamento de linhagem, desative a ingestão de linhagem para um serviço.
Java
package com.google.cloud.datacatalog.lineage.configmanagement.v1.samples;
import com.google.api.gax.rpc.NotFoundException;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule.IntegrationSelector;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule.IntegrationSelector.Integration;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule.LineageEnablement;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.ConfigManagementServiceClient;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.ConfigName;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.GetConfigRequest;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.UpdateConfigRequest;
public class DisableLineageIngestion {
public static void main(String[] args) throws Exception {
// TODO(developer): Replace these variables before running the sample.
String projectId = "your-project-id";
String location = "global";
disableLineageIngestion(projectId, location);
}
// Disables lineage ingestion for a specific service
// (Managed Service for Apache Spark).
public static void disableLineageIngestion(String projectId, String location) throws Exception {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests.
try (ConfigManagementServiceClient client = ConfigManagementServiceClient.create()) {
// Format the resource name.
String name = ConfigName.ofProjectLocationName(projectId, location).toString();
Config.Builder configBuilder = Config.newBuilder().setName(name);
// It is a best practice to read the existing config to preserve other rules
// and use the etag for optimistic concurrency control.
try {
GetConfigRequest getRequest = GetConfigRequest.newBuilder().setName(name).build();
Config existingConfig = client.getConfig(getRequest);
configBuilder.mergeFrom(existingConfig);
} catch (NotFoundException e) {
// If config doesn't exist, we will proceed by creating a new one.
}
// Create an integration selector for the service you want to disable.
IntegrationSelector selector =
IntegrationSelector.newBuilder().setIntegration(Integration.DATAPROC).build();
// Set lineage enablement to false to disable tracking.
LineageEnablement enablement = LineageEnablement.newBuilder().setEnabled(false).build();
// Build the ingestion rule.
IngestionRule disableRule =
IngestionRule.newBuilder()
.setIntegrationSelector(selector)
.setLineageEnablement(enablement)
.build();
// Preserve existing rules except for the one we are modifying, then add the new rule.
// We clear the ingestion block out of the configBuilder entirely to reconstruct it.
Ingestion.Builder ingestionBuilder = Ingestion.newBuilder();
if (configBuilder.hasIngestion()) {
for (IngestionRule rule : configBuilder.getIngestion().getRulesList()) {
// Keep all existing rules EXCEPT the one targeting DATAPROC
if (rule.getIntegrationSelector().getIntegration() != Integration.DATAPROC) {
ingestionBuilder.addRules(rule);
}
}
}
ingestionBuilder.addRules(disableRule);
// Update the config builder with the reconstructed ingestion settings.
configBuilder.setIngestion(ingestionBuilder.build());
// Build the update request.
UpdateConfigRequest request = UpdateConfigRequest.newBuilder()
.setConfig(configBuilder.build())
.build();
// Update the config.
Config response = client.updateConfig(request);
System.out.printf("Successfully updated config: %s\n", response.getName());
}
}
}
Python
from google.api_core.exceptions import NotFound
from google.cloud.datacatalog.lineage import configmanagement_v1
def disable_lineage_ingestion(project_id: str, location: str = "global") -> configmanagement_v1.Config:
"""Disables lineage ingestion for a specific service.
Args:
project_id: The ID of your Google Cloud project.
location: The region location, usually 'global'.
Returns:
The updated Configuration object.
"""
# Initialize client that will be used to send requests.
client = configmanagement_v1.ConfigManagementServiceClient()
# The config name format
name = f"projects/{project_id}/locations/{location}/config"
try:
# Retrieve the existing config to preserve other configurations and
# obtain the latest etag for optimistic concurrency control.
config = client.get_config(name=name)
# Filter out existing rules for the integration we are updating
new_rules = [
rule for rule in config.ingestion.rules
if rule.integration_selector.integration != configmanagement_v1.Config.Ingestion.IngestionRule.IntegrationSelector.Integration.DATAPROC
]
except NotFound:
# If the config does not exist, start fresh
config = configmanagement_v1.Config(name=name)
new_rules = []
# Define the integration to disable tracking for (e.g., DATAPROC).
integration_selector = configmanagement_v1.Config.Ingestion.IngestionRule.IntegrationSelector(
integration=configmanagement_v1.Config.Ingestion.IngestionRule.IntegrationSelector.Integration.DATAPROC
)
# Set lineage enablement to False to disable tracking.
lineage_enablement = configmanagement_v1.Config.Ingestion.IngestionRule.LineageEnablement(
enabled=False
)
# Create the ingestion rule.
disable_rule = configmanagement_v1.Config.Ingestion.IngestionRule(
integration_selector=integration_selector,
lineage_enablement=lineage_enablement,
)
# Append the new disabling rule and assign it back to the config ingestion rules
new_rules.append(disable_rule)
config.ingestion = configmanagement_v1.Config.Ingestion(rules=new_rules)
# Create the update request using the config (which includes the etag if it existed).
request = configmanagement_v1.UpdateConfigRequest(
config=config,
)
# Make the request to update the config
response = client.update_config(request=request)
print(f"Successfully updated config: {response.name}")
return response
gcloud
Para desativar a ingestão de linhagem de dados em um serviço específico,
use o comando gcloud datalineage config update com uma string JSON inline ou um caminho para um arquivo JSON que define lineageEnablement.enabled como false para o integration específico.
O exemplo a seguir mostra como desativar a ingestão de linhagem de um serviço para um projeto usando uma string JSON inline:
gcloud datalineage config update --project=PROJECT_ID \
--config='{
"ingestion": {
"rules": [
{
"integrationSelector": {
"integration": "INTEGRATION"
},
"lineageEnablement": {
"enabled": false
}
}
]
},
"etag": "ETAG"
}'
Substitua:
PROJECT_ID: o ID do projeto cuja configuração você quer atualizar.INTEGRATION: a integração para a qual você definiu a configuração. Por exemplo,DATAPROCouBIGQUERY.ETAG: o valoretagretornado de uma solicitaçãogetrecente no corpo da solicitação, usado para verificar se a configuração não mudou desde sua última solicitação de leitura.
Para atualizar a configuração usando um arquivo JSON, execute:
gcloud datalineage config update --project=PROJECT_ID --config=CONFIG_FILE
Substitua:
CONFIG_FILE: o caminho para o arquivo JSON que contém a configuração.
Para desativar a ingestão de linhagem de um serviço em uma pasta ou organização, substitua --project= por:PROJECT_ID
--folder=se quiser atualizar as configurações de ingestão de dados de uma pasta.FOLDER_ID--organization=se você quiser atualizar as configurações de ingestão de dados de uma organização.ORGANIZATION_ID
REST
Para desativar a ingestão de linhagem de dados em um serviço específico, use o método projects.locations.config.patch com uma regra de ingestão que defina lineageEnablement.enabled como false para o integration específico.
Para evitar a substituição acidental de configurações feitas por outros usuários em
cenários de leitura-modificação-gravação, inclua o campo etag no corpo
da solicitação. Para mais informações, consulte
Receber a configuração atual.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
CLIENT_PROJECT_ID: o ID do projeto do cliente usado para faturamento ou cotas.PROJECT_ID: o ID do projeto cuja configuração você quer atualizar.ETAG: o valoretagretornado de uma solicitaçãogetrecente.INTEGRATION: ointegrationpara o qual você definiu a configuração. Por exemplo,DATAPROC.
Método HTTP e URL:
PATCH https://datalineage.googleapis.com/v1/projects/PROJECT_ID/locations/global/config
Corpo JSON da solicitação:
{
"ingestion": {
"rules": [
{
"integrationSelector": {
"integration": "INTEGRATION"
},
"lineageEnablement": {
"enabled": false
}
}
]
},
"etag": "ETAG"
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"name": "projects/PROJECT_ID/locations/global/config",
"ingestion": {
"rules": [
{
"integrationSelector": {
"integration": "INTEGRATION"
},
"lineageEnablement": {
"enabled": false
}
}
]
},
"etag": "1a2b3c4d5e"
}
Para desativar a ingestão de linhagem em uma pasta ou organização, substitua
projects/ por PROJECT_IDfolders/ ou FOLDER_IDorganizations/.ORGANIZATION_ID
Ativar a ingestão de linhagem para um serviço
Para retomar o rastreamento depois de desativá-lo ou ativar uma integração desativada por padrão, ative a ingestão de linhagem para um serviço.
Java
package com.google.cloud.datacatalog.lineage.configmanagement.v1.samples;
import com.google.api.gax.rpc.NotFoundException;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule.IntegrationSelector;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule.IntegrationSelector.Integration;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.Config.Ingestion.IngestionRule.LineageEnablement;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.ConfigManagementServiceClient;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.ConfigName;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.GetConfigRequest;
import com.google.cloud.datacatalog.lineage.configmanagement.v1.UpdateConfigRequest;
public class EnableLineageIngestion {
public static void main(String[] args) throws Exception {
// TODO(developer): Replace these variables before running the sample.
String projectId = "your-project-id";
String location = "global";
enableLineageIngestion(projectId, location);
}
// Enables lineage ingestion for a specific service
// (Managed Service for Apache Spark).
public static void enableLineageIngestion(String projectId, String location) throws Exception {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests.
try (ConfigManagementServiceClient client = ConfigManagementServiceClient.create()) {
// Format the resource name.
String name = ConfigName.ofProjectLocationName(projectId, location).toString();
Config.Builder configBuilder = Config.newBuilder().setName(name);
// It is a best practice to read the existing config to preserve other rules
// and use the etag for optimistic concurrency control.
try {
GetConfigRequest getRequest = GetConfigRequest.newBuilder().setName(name).build();
Config existingConfig = client.getConfig(getRequest);
configBuilder.mergeFrom(existingConfig);
} catch (NotFoundException e) {
// If config doesn't exist, we will proceed by creating a new one.
}
// Create an integration selector for the service you want to enable (e.g., DATAPROC).
IntegrationSelector selector =
IntegrationSelector.newBuilder().setIntegration(Integration.DATAPROC).build();
// Set lineage enablement to true to enable tracking.
LineageEnablement enablement = LineageEnablement.newBuilder().setEnabled(true).build();
// Build the ingestion rule.
IngestionRule enableRule =
IngestionRule.newBuilder()
.setIntegrationSelector(selector)
.setLineageEnablement(enablement)
.build();
// Preserve existing rules except for the one we are modifying, then add the new rule.
// We clear the ingestion block out of the configBuilder entirely to reconstruct it.
Ingestion.Builder ingestionBuilder = Ingestion.newBuilder();
if (configBuilder.hasIngestion()) {
for (IngestionRule rule : configBuilder.getIngestion().getRulesList()) {
// Keep all existing rules EXCEPT the one targeting DATAPROC
if (rule.getIntegrationSelector().getIntegration() != Integration.DATAPROC) {
ingestionBuilder.addRules(rule);
}
}
}
ingestionBuilder.addRules(enableRule);
// Update the config builder with the reconstructed ingestion settings.
configBuilder.setIngestion(ingestionBuilder.build());
// Build the update request.
UpdateConfigRequest request = UpdateConfigRequest.newBuilder()
.setConfig(configBuilder.build())
.build();
// Update the config.
Config response = client.updateConfig(request);
System.out.printf("Successfully updated config: %s\n", response.getName());
}
}
}
Python
from google.api_core.exceptions import NotFound
from google.cloud.datacatalog.lineage import configmanagement_v1
def enable_lineage_ingestion(project_id: str, location: str = "global") -> configmanagement_v1.Config:
"""Enables lineage ingestion for a specific service like Dataproc
(Managed Service for Apache Spark).
Args:
project_id: The ID of your Google Cloud project.
location: The region location, usually 'global'.
Returns:
The updated Configuration object.
"""
# Initialize client that will be used to send requests.
client = configmanagement_v1.ConfigManagementServiceClient()
# The config name format
name = f"projects/{project_id}/locations/{location}/config"
try:
# Retrieve the existing config to preserve other configurations and
# obtain the latest etag for optimistic concurrency control.
config = client.get_config(name=name)
# Filter out existing rules for the integration we are updating
new_rules = [
rule for rule in config.ingestion.rules
if rule.integration_selector.integration != configmanagement_v1.Config.Ingestion.IngestionRule.IntegrationSelector.Integration.DATAPROC
]
except NotFound:
# If the config does not exist, start fresh
config = configmanagement_v1.Config(name=name)
new_rules = []
# Define the integration to enable tracking for (e.g., DATAPROC).
integration_selector = configmanagement_v1.Config.Ingestion.IngestionRule.IntegrationSelector(
integration=configmanagement_v1.Config.Ingestion.IngestionRule.IntegrationSelector.Integration.DATAPROC
)
# Set lineage enablement to True to enable tracking.
lineage_enablement = configmanagement_v1.Config.Ingestion.IngestionRule.LineageEnablement(
enabled=True
)
# Create the ingestion rule.
enable_rule = configmanagement_v1.Config.Ingestion.IngestionRule(
integration_selector=integration_selector,
lineage_enablement=lineage_enablement,
)
# Append the new enabling rule and assign it back to the config ingestion rules
new_rules.append(enable_rule)
config.ingestion = configmanagement_v1.Config.Ingestion(rules=new_rules)
# Create the update request using the config (which includes the etag if it existed).
request = configmanagement_v1.UpdateConfigRequest(
config=config,
)
# Make the request to update the config
response = client.update_config(request=request)
print(f"Successfully updated config: {response.name}")
return response
gcloud
Para ativar a ingestão de linhagem em um serviço específico,
use o comando gcloud datalineage config update com uma string JSON inline ou um caminho para um arquivo JSON que define lineageEnablement.enabled como true para o integration específico. As integrações atuais incluem o Serviço Gerenciado para Apache Spark, o BigQuery e o Managed Airflow.
O exemplo a seguir mostra como ativar a ingestão de linhagem de um serviço para um projeto usando uma string JSON inline:
gcloud datalineage config update --project=PROJECT_ID \
--config='{
"ingestion": {
"rules": [
{
"integrationSelector": {
"integration": "INTEGRATION"
},
"lineageEnablement": {
"enabled": true
}
}
]
},
"etag": "ETAG"
}'
Substitua:
PROJECT_ID: o ID do projeto cuja configuração você quer atualizar.INTEGRATION: a integração para a qual você definiu a configuração (por exemplo,DATAPROCouBIGQUERY).ETAG: o valoretagretornado de uma solicitaçãogetrecente no corpo da solicitação, usado para verificar se a configuração não mudou desde sua última solicitação de leitura.
Para atualizar a configuração usando um arquivo JSON, execute:
gcloud datalineage config update --project=PROJECT_ID --config=CONFIG_FILE
Substitua:
CONFIG_FILE: o caminho para o arquivo JSON que contém a configuração.
Para ativar a ingestão de linhagem de um serviço em uma pasta ou organização, substitua --project= por:PROJECT_ID
--folder=se quiser atualizar as configurações de ingestão de dados de uma pasta.FOLDER_ID--organization=se você quiser atualizar as configurações de ingestão de dados de uma organização.ORGANIZATION_ID
REST
Para ativar a ingestão de linhagem em um serviço específico, use o método projects.locations.config.patch com uma regra de ingestão que define lineageEnablement.enabled como true para o integration específico. As integrações atuais incluem o Serviço Gerenciado para Apache Spark, o BigQuery e o Managed Airflow.
Para evitar a substituição acidental de configurações feitas por outros usuários em
cenários de leitura-modificação-gravação, inclua o campo etag no corpo
da solicitação. Para mais informações, consulte
Receber a configuração atual.
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
CLIENT_PROJECT_ID: o ID do projeto do cliente usado para faturamento ou cotas.PROJECT_ID: o ID do projeto cuja configuração você quer atualizar.ETAG: o valoretagretornado de uma solicitaçãogetrecente.INTEGRATION: ointegrationpara o qual você definiu a configuração. Por exemplo,DATAPROC.
Método HTTP e URL:
PATCH https://datalineage.googleapis.com/v1/projects/PROJECT_ID/locations/global/config
Corpo JSON da solicitação:
{
"ingestion": {
"rules": [
{
"integrationSelector": {
"integration": "INTEGRATION"
},
"lineageEnablement": {
"enabled": true
}
}
]
},
"etag": "ETAG"
}
Para enviar a solicitação, expanda uma destas opções:
Você receberá uma resposta JSON semelhante a esta:
{
"name": "projects/PROJECT_ID/locations/global/config",
"ingestion": {
"rules": [
{
"integrationSelector": {
"integration": "INTEGRATION"
},
"lineageEnablement": {
"enabled": true
}
}
]
},
"etag": "1a2b3c4d5e"
}
Para ativar a ingestão de linhagem de um serviço em uma pasta ou organização, substitua
projects/ por PROJECT_IDfolders/ ou
FOLDER_IDorganizations/.ORGANIZATION_ID
Ver linhagem
Para acompanhar como os dados são transformados e movidos entre sistemas, é possível conferir a linhagem de dados usando o console ou a API Google Cloud .
Console
É possível acessar informações de linhagem de dados no console do Google Cloud de vários pontos de partida:
- Knowledge Catalog:acesse a página Pesquisa do Knowledge Catalog, selecione Knowledge Catalog como o modo de pesquisa, procure a entrada que você quer ver e clique nela. Para mais informações, consulte Pesquisar recursos no Knowledge Catalog.
- BigQuery:acesse a página BigQuery e abra a tabela para ver a linhagem de dados.
- Vertex AI:acesse a página Conjuntos de dados ou Model Registry e clique no conjunto de dados ou modelo para conferir a linhagem de dados.
Para ver o gráfico de linhagem, siga estas etapas:
Clique na guia Linhagem.
A visualização Gráfico padrão é aberta, mostrando a linhagem no nível da tabela em sistemas e regiões. Para mais informações, consulte Visualização do gráfico de linhagem.
Para explorar manualmente o gráfico de linhagem, clique em Expandir ao lado de um nó para carregar mais cinco nós por vez.
Para mais informações, consulte Como analisar manualmente o gráfico de linhagem.
Clique em um nó na visualização Gráfico.
O painel Detalhes é aberto com informações sobre o recurso, como nome e tipo totalmente qualificados. Para mais informações, consulte Detalhes do nó.
Clique em uma aresta com um ícone de processo na visualização Gráfico.
O painel Consulta é aberto. Para mais informações, consulte Inspecionar a lógica de transformação e Auditoria e histórico de execuções.
- Para inspecionar a lógica de transformação, clique na guia Detalhes.
- Para ver a auditoria e o histórico de execuções, clique na guia Execuções.
No painel Explorador de linhagem, selecione critérios de filtro, por exemplo, Direção, Tipo de dependência ou Período, e clique em Aplicar.
Isso abre uma visualização focada em uma região específica (prévia). Essa visualização expande automaticamente o gráfico em até três níveis de nós. Para mais informações, consulte Aplicar filtros para uma visualização de linhagem focada.
Na visualização Gráfico focada, selecione um nó e, no painel de detalhes dele, clique em Visualizar caminho para ver o caminho de linhagem do nó selecionado até a entrada raiz (somente na visualização focada).
Para mais informações, consulte Visualização do caminho de linhagem.
Para ver a linhagem no nível da coluna (somente para jobs do BigQuery e do Serviço Gerenciado para Apache Spark), faça o seguinte:
- Em uma visualização Gráfico focada, clique no ícone de coluna em uma tabela.
Ícone de coluna - No painel Análise de linhagem, filtre por nome da coluna e clique em Aplicar.
Para mais informações, consulte Linhagem no nível da coluna.
- Em uma visualização Gráfico focada, clique no ícone de coluna em uma tabela.
Clique em Redefinir.
Essa ação remove todos os filtros aplicados e leva você ao início da visualização de gráfico.
Clique em Lista para mudar para a visualização em lista.
A visualização Lista oferece representações tabulares simplificadas e detalhadas da linhagem no nível da tabela e da coluna, sincronizadas com a visualização Gráfico. Por padrão, a visualização simplificada em lista é mostrada, e você pode alternar para a visualização detalhada em lista para analisar as relações individuais de origem-destino. É possível configurar quais colunas serão mostradas e exportar dados de linhagem. Para mais informações, consulte Visualização em lista da linhagem.
Java
import com.google.api.gax.rpc.ApiException;
import com.google.cloud.datacatalog.lineage.v1.BatchSearchLinkProcessesRequest;
import com.google.cloud.datacatalog.lineage.v1.EntityReference;
import com.google.cloud.datacatalog.lineage.v1.EventLink;
import com.google.cloud.datacatalog.lineage.v1.LineageClient;
import com.google.cloud.datacatalog.lineage.v1.LineageEvent;
import com.google.cloud.datacatalog.lineage.v1.Link;
import com.google.cloud.datacatalog.lineage.v1.ListLineageEventsRequest;
import com.google.cloud.datacatalog.lineage.v1.ListRunsRequest;
import com.google.cloud.datacatalog.lineage.v1.LocationName;
import com.google.cloud.datacatalog.lineage.v1.ProcessLinks;
import com.google.cloud.datacatalog.lineage.v1.Run;
import com.google.cloud.datacatalog.lineage.v1.SearchLinksRequest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.Set;
public class ViewLineageExample {
public static void main(String[] args) throws IOException {
// TODO(developer): Replace these variables before running the sample.
String projectId = "my-project-id";
String location = "us";
String targetFullyQualifiedName = "bigquery:my-project-id.my_dataset.my_table";
int maxDepth = 3;
viewLineage(projectId, location, targetFullyQualifiedName, maxDepth);
}
static class Node {
String fqn;
int depth;
Node(String fqn, int depth) {
this.fqn = fqn;
this.depth = depth;
}
}
public static void viewLineage(
String projectId, String location, String targetFullyQualifiedName, int maxDepth)
throws IOException {
// Initialize client that will be used to send requests. This client only needs
// to be created once, and can be reused for multiple requests.
try (LineageClient client = LineageClient.create()) {
String parent = LocationName.of(projectId, location).toString();
Set<String> visitedNodes = new HashSet<>();
Queue<Node> queue = new LinkedList<>();
visitedNodes.add(targetFullyQualifiedName);
queue.offer(new Node(targetFullyQualifiedName, 0));
while (!queue.isEmpty()) {
Node current = queue.poll();
System.out.printf("\nExploring node (Depth %d): %s\n", current.depth, current.fqn);
if (current.depth >= maxDepth) {
continue;
}
EntityReference targetEntity =
EntityReference.newBuilder().setFullyQualifiedName(current.fqn).build();
SearchLinksRequest searchLinksRequest =
SearchLinksRequest.newBuilder().setParent(parent).setTarget(targetEntity).build();
List<String> linkNames = new ArrayList<>();
try {
// 1. Search for links related to the target entity
for (Link link : client.searchLinks(searchLinksRequest).iterateAll()) {
linkNames.add(link.getName());
}
} catch (ApiException e) {
System.out.printf(" Failed to retrieve links for %s: %s\n", current.fqn, e.getMessage());
continue;
}
if (linkNames.isEmpty()) {
continue;
}
// 2. Batch search for processes in chunks of 100
for (int i = 0; i < linkNames.size(); i += 100) {
List<String> batch = linkNames.subList(i, Math.min(linkNames.size(), i + 100));
BatchSearchLinkProcessesRequest batchSearchRequest =
BatchSearchLinkProcessesRequest.newBuilder()
.setParent(parent)
.addAllLinks(batch)
.build();
try {
for (ProcessLinks processLinks :
client.batchSearchLinkProcesses(batchSearchRequest).iterateAll()) {
String processName = processLinks.getProcess();
System.out.printf(" Process: %s\n", processName);
// 3. List runs for the process
ListRunsRequest runsRequest =
ListRunsRequest.newBuilder().setParent(processName).build();
for (Run run : client.listRuns(runsRequest).iterateAll()) {
System.out.printf(" Run: %s\n", run.getName());
// 4. List events for the run
ListLineageEventsRequest eventsRequest =
ListLineageEventsRequest.newBuilder().setParent(run.getName()).build();
for (LineageEvent event : client.listLineageEvents(eventsRequest).iterateAll()) {
for (EventLink eventLink : event.getLinksList()) {
String sourceFqn = eventLink.getSource().getFullyQualifiedName();
// If exploring upstream, queue the source
if (!sourceFqn.isEmpty() && !visitedNodes.contains(sourceFqn)) {
visitedNodes.add(sourceFqn);
queue.offer(new Node(sourceFqn, current.depth + 1));
}
}
}
}
}
} catch (ApiException e) {
System.out.printf(" Failed to retrieve processes/runs: %s\n", e.getMessage());
}
}
}
}
}
}
Python
from google.cloud import datacatalog_lineage_v1
from google.api_core.exceptions import GoogleAPICallError
def view_lineage(project_id: str, location: str, target_fully_qualified_name: str, max_depth: int = 3):
"""Retrieves lineage for a given entity using a depth-limited search."""
client = datacatalog_lineage_v1.LineageClient()
parent = f"projects/{project_id}/locations/{location}"
# Store visited nodes to avoid infinite loops in cyclic graphs
visited_nodes = set([target_fully_qualified_name])
queue = [(target_fully_qualified_name, 0)]
while queue:
current_node, current_depth = queue.pop(0)
print(f"\nExploring node (Depth {current_depth}): {current_node}")
if current_depth >= max_depth:
continue
target_entity = datacatalog_lineage_v1.EntityReference(
fully_qualified_name=current_node
)
search_links_request = datacatalog_lineage_v1.SearchLinksRequest(
parent=parent,
target=target_entity,
)
try:
links = list(client.search_links(request=search_links_request))
except GoogleAPICallError as e:
print(f" Failed to retrieve links for {current_node}: {e.message}")
continue
if not links:
continue
# Extract link names to query processes in batches
link_names = [link.name for link in links]
# Batch max size is 100
for i in range(0, len(link_names), 100):
batch = link_names[i:i + 100]
batch_request = datacatalog_lineage_v1.BatchSearchLinkProcessesRequest(
parent=parent,
links=batch
)
try:
for process_links in client.batch_search_link_processes(request=batch_request):
process_name = process_links.process
print(f" Process: {process_name}")
runs_request = datacatalog_lineage_v1.ListRunsRequest(parent=process_name)
for run in client.list_runs(request=runs_request):
print(f" Run: {run.name}")
events_request = datacatalog_lineage_v1.ListLineageEventsRequest(parent=run.name)
for event in client.list_lineage_events(request=events_request):
for event_link in event.links:
source_fqn = event_link.source.fully_qualified_name
# If exploring upstream, queue the source
if source_fqn and source_fqn not in visited_nodes:
visited_nodes.add(source_fqn)
queue.append((source_fqn, current_depth + 1))
except GoogleAPICallError as e:
print(f" Failed to retrieve processes/runs: {e.message}")
Refinar a visualização de linhagem
Para refinar a visualização de linhagem, use as opções de destaque e filtragem no Explorador de linhagem:
Para pesquisar projetos, conjuntos de dados ou nomes de entidades específicos, use o painel Filtros.
Depois de aplicar os filtros, os nós de linhagem que correspondem aos seus critérios são considerados nós correspondentes. Você pode refinar a forma como os nós correspondentes e não correspondentes são mostrados.
No gráfico de linhagem, clique no ícone Mais ações ao lado do botão Limpar filtros para ver as opções de exibição.
Selecione uma ou ambas as opções a seguir:
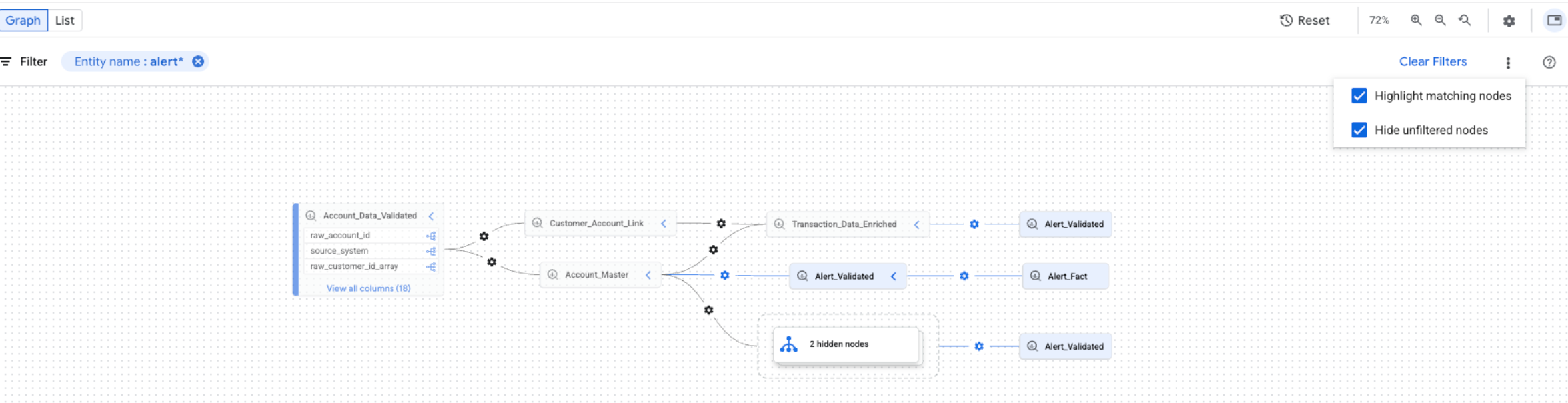
Você pode selecionar as duas opções ao mesmo tempo. Se as duas opções estiverem selecionadas, os nós sem filtro serão ocultados, e os nós correspondentes serão destacados na visualização filtrada do gráfico.
A seguir
- Rastrear a linhagem de dados dos jobs de cópia e consulta de uma tabela do BigQuery.
- Saiba mais sobre o modelo de informações de linhagem de dados.
- Saiba mais sobre considerações e limitações da linhagem de dados.
- Saiba mais sobre a geração de registros de auditoria da linhagem de dados.
- Saiba como resolver problemas com a linhagem de dados.
- Saiba como fazer a integração com o OpenLineage.
- Saiba como usar a linhagem de dados com o Serviço Gerenciado para Apache Spark.