
Cuando almacenas tus datos en diferentes sistemas de almacenamiento, administrar la seguridad fragmentada puede convertirse en un gran desafío. Quieres asegurarte de que la información sensible, como los registros financieros, permanezca protegida, incluso si la almacenas en formatos abiertos como Apache Iceberg en el Google Cloud almacenamiento.
Es fundamental que tus medidas de seguridad funcionen sin problemas en varios motores de consultas, como BigQuery SQL y Apache Spark. En esta arquitectura, Knowledge Catalog funciona como un motor de contexto universal para resolver este problema. Contiene los metadatos necesarios para garantizar que tu contexto de seguridad se aplique de manera coherente, independientemente del motor que consulte los datos.
En este instructivo, crearás un data lakehouse seguro para resolver estos desafíos. Con los secuencias de comandos, defines políticas de seguridad y ves cómo Knowledge Catalog (antes Dataplex Universal Catalog) y Lakehouse para Apache Iceberg trabajan en conjunto para aplicar las políticas en diferentes motores de consultas.
Descripción general de la arquitectura
Para configurar un control de acceso detallado en un formato de tabla abierta, como Apache Iceberg, debes crear una arquitectura de seguridad estricta y unificada.
Con este diseño, Knowledge Catalog actúa como el plano de control central. Knowledge Catalog aplica de forma dinámica tu contexto de seguridad en todos los motores compatibles.
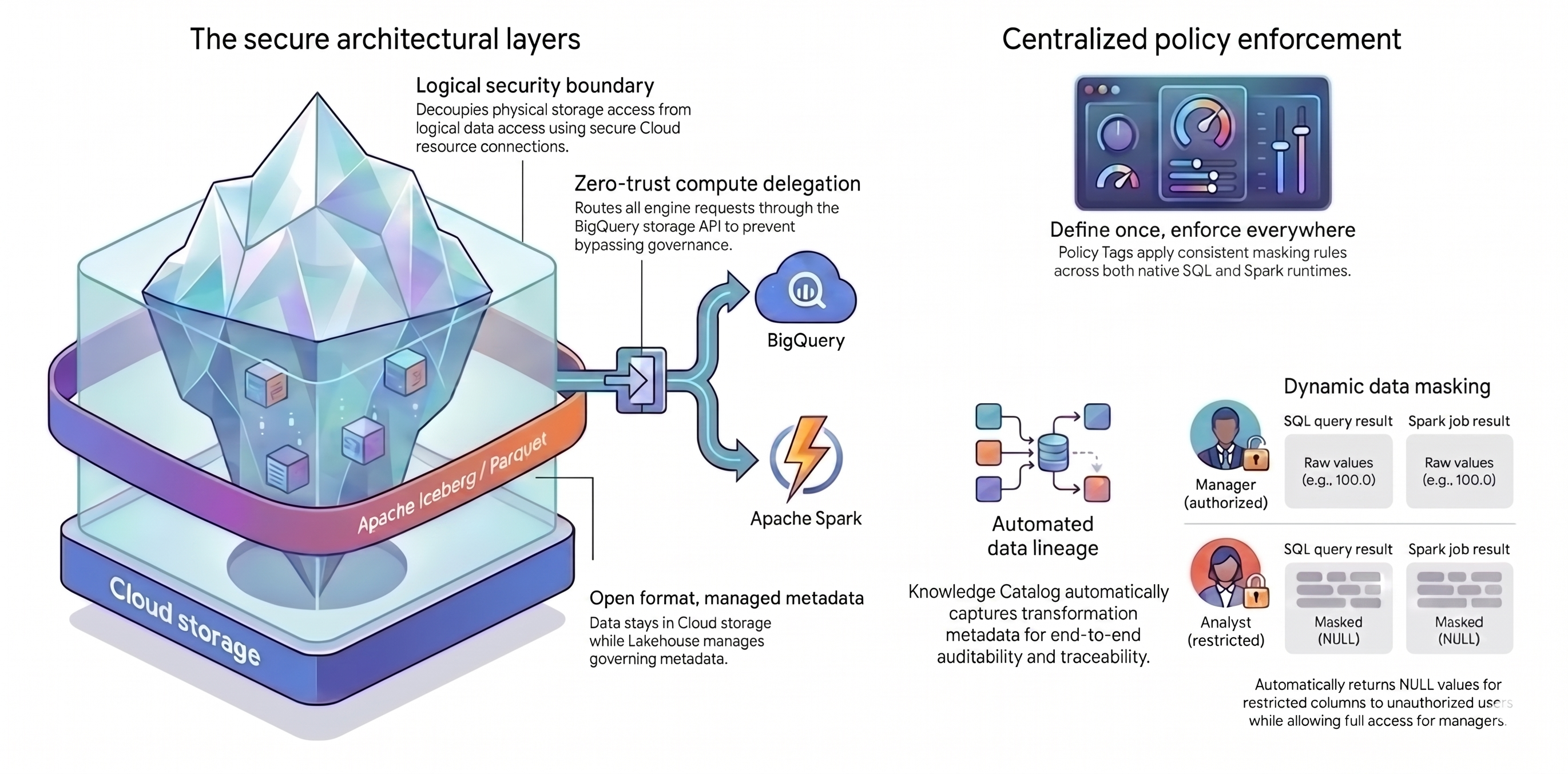
En este instructivo, se utilizan dos conceptos principales para crear esta arquitectura unificada:
- Capas arquitectónicas seguras: En lugar de permitir que los usuarios o los motores de consultas accedan directamente a tus buckets de Cloud Storage, puedes crear una base segura y en capas basada en los siguientes atributos:
- Formato abierto con metadatos administrados: Tus datos permanecen en su formato abierto Apache Iceberg (Parquet) dentro de Cloud Storage, mientras que Lakehouse para Apache Iceberg administra los metadatos de la tabla.
- Límite de seguridad lógica: Desvinculas los permisos de almacenamiento de las consultas de datos con una conexión a recursos de Cloud segura. Nunca otorgas a los usuarios finales acceso directo a los archivos.
- Delegación de procesamiento: Para evitar que los motores de consultas omitan tus reglas, debes enrutar todas las solicitudes de datos a través de la API de BigQuery Storage. El enrutamiento de solicitudes a través de la API de BigQuery Storage garantiza que Knowledge Catalog pueda interceptar y aplicar políticas incluso para los motores de procesamiento externos.
- Aplicación de políticas centralizada: Con una base segura, puedes usar Knowledge Catalog para aplicar tus reglas de forma universal:
- Definir una vez, aplicar en todas partes: Defines las etiquetas de política en Knowledge Catalog solo una vez, y la plataforma aplica reglas de enmascaramiento coherentes en todos los motores de búsqueda compatibles.
- Enmascaramiento de datos dinámico: El sistema evalúa la identidad del usuario durante las consultas. Los usuarios autorizados ven los valores sin procesar, mientras que los usuarios restringidos reciben resultados de
NULLen todos los motores de consultas. - Linaje de datos automatizado: Knowledge Catalog realiza un seguimiento automático de las transformaciones de datos, lo que crea un registro de auditoría sin código de registro personalizado.
Objetivos
- Crea tablas de Apache Iceberg administradas por BigQuery. Lakehouse administra los metadatos de Iceberg.
- Configura reglas de seguridad centrales con etiquetas de política para enmascarar y proteger las columnas sensibles.
- Separa los permisos de almacenamiento físico de las consultas de datos lógicos con una conexión a recursos de Cloud.
- Enruta las consultas de forma segura a través de Managed Service para Apache Spark para que los motores externos no puedan omitir tus reglas de seguridad.
- Explora un mapa interactivo de tus datos con el linaje de datos.
Antes de comenzar
Antes de comenzar, haz lo siguiente:
- Selecciona un Google Cloud proyecto para este instructivo.
- Confirma que la facturación esté habilitada para tu proyecto.
Prepara el entorno
En este instructivo, se usa Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En la Google Cloud consola, haz clic en el ícono de Cloud Shell en la barra de herramientas superior derecha.
Configura las variables del proyecto:
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"Define variables para dos arquetipos de usuarios: un analista de comercio minorista y un administrador de comercio minorista:
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)Habilita las Google Cloud APIs necesarias.
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
Descarga el código fuente del instructivo
Descarga las secuencias de comandos de Python para este instructivo desde el repositorio de Google Cloud DevRel:
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Crea un bucket de almacenamiento
Crea un bucket nuevo para contener los archivos de la tabla de Iceberg:
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Prepara la identidad y la seguridad
En este paso, configurarás la delegación de procesamiento creando una conexión a recursos de Cloud. Esta conexión actúa como una identidad segura y delegada que BigQuery usa para administrar y leer tus archivos de Iceberg. Esto ayuda a garantizar que los usuarios individuales nunca tengan acceso directo a tu bucket de Cloud Storage.
Ejecuta los siguientes comandos para crear la conexión, recuperar su cuenta de servicio generada automáticamente y otorgarle a esa cuenta los permisos necesarios para administrar tus datos de Iceberg:
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Crea cuentas de servicio para dos arquetipos: Analyst y Manager. Los siguientes comandos configuran estas cuentas de servicio, permiten que tu usuario actual las suplante para realizar pruebas y les otorgan roles específicos para ejecutar consultas y ver datos.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Crea tablas de Apache Iceberg
Usar el motor de BigQuery SQL para crear tablas de Apache Iceberg Aunque ejecutes los comandos de creación con BigQuery, Lakehouse actúa como la capa de administración que almacena los metadatos de la tabla y protege los archivos Parquet subyacentes en Cloud Storage.
Después de crear las tablas, ejecutarás una transformación rápida para ver cómo Knowledge Catalog controla la seguridad y hace un seguimiento automático del recorrido de tus datos.
Crea un conjunto de datos de BigQuery
Primero, crea un conjunto de datos de BigQuery para agrupar tus tablas:
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Crea las tablas de Iceberg
Ejecuta los siguientes comandos para crear tablas de inventario y transacciones:
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Inserta datos de muestra
Inserta datos de muestra en las tablas:
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Ahora tienes dos tablas de Iceberg con datos de muestra sin procesar. El lakehouse administra los metadatos, pero los archivos Parquet reales se encuentran en tu bucket de Cloud Storage.
Transforma datos para el linaje automatizado
Agrega tus transacciones sin procesar en un resumen de ventas diarias. Esta transformación crea una tabla nueva y genera los metadatos que Knowledge Catalog usa para asignar automáticamente el recorrido de tus datos.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Define políticas de administración de accesos
En un entorno de producción, escribir tus reglas de seguridad como código (infraestructura como código) hace que tus políticas sean repetibles, tengan control de versión y sean más fáciles de mantener. En esta sección, usarás el SDK de Python Google Cloud para definir y aplicar tus reglas de forma automática.
Prepara el entorno virtual de Python
Configura un entorno virtual aislado de Python para administrar tus dependencias y garantizar que las secuencias de comandos se ejecuten de forma confiable:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Define taxonomías y etiquetas de seguridad
Comienza por crear la base de tus reglas de seguridad. En este paso, crearás una taxonomía para que actúe como contenedor y una etiqueta de política para que sirva como etiqueta de seguridad específica para los datos sensibles.
Ejecuta la secuencia de comandos para crear los recursos:
python 1_create_taxonomy.py
Revisa 1_create_taxonomy.py para ver la lógica principal:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Si configuras de forma explícita el tipo de política FINE_GRAINED_ACCESS_CONTROL, transformas una etiqueta de metadatos estándar en un límite de seguridad estricto de denegación predeterminada. De forma predeterminada, cualquier columna con esta etiqueta deniega el acceso a todos los usuarios.
Crea una política de enmascaramiento de datos dinámico
Ahora, define qué sucede cuando alguien sin privilegios consulta una columna etiquetada. Crea una política de enmascaramiento de datos que reemplace automáticamente los valores sensibles por NULL para el arquetipo de analista.
Ejecuta la secuencia de comandos para configurar la regla de enmascaramiento:
python 2_create_masking.py
Dentro de 2_create_masking.py, la secuencia de comandos busca el ID de la etiqueta de política que creaste y aplica la política de datos a la cuenta de servicio de Analyst:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Otorga acceso con privilegios a tus datos
Debido a la configuración de denegación predeterminada, nadie puede leer la columna etiquetada. Debes otorgar acceso de forma explícita a los usuarios autorizados. Otorga el rol de lector de categorías de recursos al arquetipo de administrador y a tu propia cuenta. Esto permite que estos usuarios específicos omitan las reglas de enmascaramiento y lean los datos sin enmascarar.
Ejecuta la secuencia de comandos para otorgar acceso:
python 3_grant_access.py
Dentro de 3_grant_access.py, la secuencia de comandos modifica la política de IAM de la etiqueta de política:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Adjunta etiquetas de seguridad al esquema de la tabla
Por último, puedes conectar tus reglas lógicas a los datos reales. Actualiza el esquema de la tabla de Iceberg para adjuntar la etiqueta de política directamente a la columna amount. Después de hacerlo, Lakehouse aplicará instantáneamente tus protecciones en los archivos de la tabla de Iceberg de tu bucket.
Ejecuta la secuencia de comandos para adjuntar la etiqueta de política:
python 4_attach_tag.py
Revisa 4_attach_tag.py. La secuencia de comandos recupera el esquema de la tabla de BigQuery, itera por los campos y adjunta la etiqueta específicamente a la columna amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Verifica tus políticas de seguridad
Ejecuta algunas consultas de prueba para asegurarte de que tus permisos funcionen según lo esperado. Para demostrar que Knowledge Catalog actúa como un motor de contexto universal, ya que aplica las mismas políticas de seguridad cuando cambias de motor de consultas, ejecuta estas pruebas con BigQuery y Apache Spark.
Prueba con BigQuery SQL
Para comenzar, verifica tus políticas directamente en BigQuery. Esta es la forma más rápida de confirmar que tus reglas y permisos de enmascaramiento están activos.
Verificar como administrador
El arquetipo de administrador tiene acceso de lectura detallado y con privilegios. Deberían ver todos los detalles de la tabla, incluidos los valores de la columna amount.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Dado que el administrador tiene el rol de lector detallado, la consulta muestra los valores de cantidad sin procesar:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Verifica como analista
Cambia al arquetipo de analista y ejecuta la misma consulta.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Aunque ejecutes la misma consulta, Knowledge Catalog enmascara los valores sensibles en la columna amount:
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Cómo volver a acceder a tu cuenta
Limpia el estado de autenticación de Cloud Shell para volver a tu usuario administrador.
gcloud config unset auth/impersonate_service_account
Prueba con Apache Spark
La seguridad suele fallar cuando los usuarios acceden directamente a los archivos de datos en Cloud Storage. Si un científico de datos usa Apache Spark para leer los archivos de la tabla de Iceberg directamente, normalmente omitiría tus reglas porque Cloud Storage solo comprende los permisos a nivel del bucket.
Para evitar esto, usa la delegación de procesamiento. Con el conector de Spark-BigQuery, creas un puente seguro que enruta todas las solicitudes de Spark a través de la API de BigQuery Storage. Esto garantiza que Knowledge Catalog verifique los permisos y aplique las reglas de enmascaramiento antes de que los datos lleguen al clúster de Spark.
Sube la secuencia de comandos read_transactions.py a tu bucket de Cloud Storage para que Managed Service para Apache Spark pueda acceder a ella:
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Revisa la lógica principal de la secuencia de comandos que subiste:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
La secuencia de comandos no dirige Spark a la ruta de acceso gs:// de los archivos de Iceberg. Cuando se especifica .format("bigquery"), la API de BigQuery Storage intercepta la solicitud de lectura, verifica la identidad del usuario que ejecuta el trabajo de Spark, aplica las reglas de enmascaramiento de Knowledge Catalog y devuelve solo los datos autorizados al DataFrame de Spark.
Ejecuta Spark como administrador
Envía un trabajo de Spark como el arquetipo de administrador. Usa Managed Service para Apache Spark, un servicio administrado que te permite ejecutar cargas de trabajo de Spark sin la molestia de administrar tus propios clústeres:
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Revisa los registros de resultados del trabajo en la terminal. Debido a que el administrador tiene el rol de lector detallado, Spark recupera correctamente los importes sin enmascarar:
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Ejecuta Spark como el analista
Por último, ejecuta el mismo código de Spark que la persona Analyst:
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Vuelve a revisar los registros. Aunque el analista ejecutó el mismo código de Spark, la API de BigQuery Storage interceptó la solicitud y aplicó la política de Knowledge Catalog. El DataFrame de Spark del analista muestra null para los importes.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Acabas de demostrar que, como tu plano de control central, Knowledge Catalog aplica tus políticas de seguridad de manera coherente, independientemente del motor de consultas que uses.
Consulta el recorrido de tus datos con el linaje automatizado
Un lakehouse que cumpla con las políticas requiere más que solo controles de acceso; también requiere un registro de auditoría claro. El linaje de datos te ayuda a comprender de dónde provienen tus datos y cómo se transforman. Responder preguntas esenciales, como “¿Qué tablas sin procesar se usaron para generar este informe de ventas?”, te ayuda a mantener el cumplimiento, depurar rápidamente las canalizaciones de datos y crear una base de datos confiable.
En lugar de escribir código de registro complejo de forma manual, Knowledge Catalog hace un seguimiento automático de este ciclo de vida en toda tu arquitectura. Por ejemplo, cuando creaste una tabla de resumen anteriormente en este instructivo, BigQuery capturó los detalles de la transformación al instante y los envió a Knowledge Catalog. Esto actualizó de forma dinámica el contexto y el historial de tus datos.
Explora el gráfico de linaje interactivo
Consulta el mapa interactivo que generó Knowledge Catalog. Muestra cómo fluyen los datos sin procesar de la tabla transactions a la tabla transactions_summary. Dado que Knowledge Catalog recopila metadatos como un motor de contexto dinámico, este gráfico muestra la trazabilidad confiable y en tiempo real que necesitas para una auditoría de datos.
- En la consola de Google Cloud , navega a Knowledge Catalog > Search.
- Escribe
lakehouse_retail_demo.transactions_summaryen la barra de búsqueda y haz clic en la tabla. - Haz clic en la pestaña Linaje.
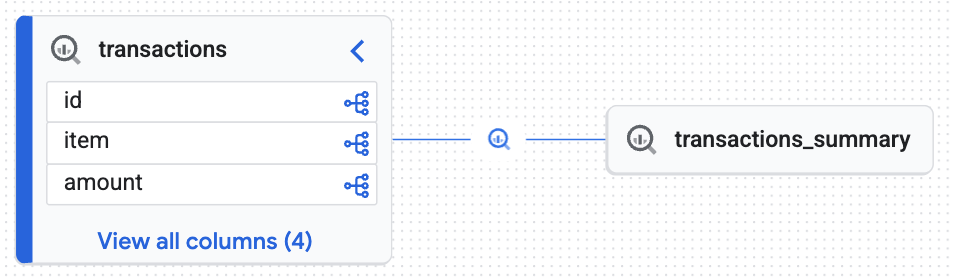
El gráfico interactivo confirma que la tabla de destino (transactions_summary) se deriva de la tabla Iceberg sin procesar y controlada (transactions). Esta visualización demuestra la trazabilidad integral de tus datos.
Realiza una limpieza
Para evitar cargos continuos, quita los recursos que creaste para este instructivo.
Quita los recursos de políticas y metadatos
Antes de borrar el conjunto de datos de BigQuery o el bucket de Cloud Storage, debes borrar las políticas de administración de datos y los recursos de metadatos.
Ejecuta la secuencia de comandos de limpieza de Python:
python cleanup_governance.py
Revisa la secuencia de comandos cleanup_governance.py del repositorio para encontrar la siguiente lógica de cierre. El orden de eliminación es fundamental. Primero, borra la política de enmascaramiento de datos. Luego, borra la taxonomía principal, lo que quita automáticamente todos los identificadores de política subyacentes y evita errores de dependencia de recursos.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Quita identidades, almacenamiento y recursos de procesamiento
Borra las tablas de BigQuery, los buckets de Cloud Storage, las cuentas de servicio y el entorno virtual de Python local.
Copia y ejecuta la siguiente secuencia de comandos de limpieza en Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
Limpia los archivos del proyecto:
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
Conclusión
Creaste correctamente un data lakehouse seguro. Con Lakehouse para Apache Iceberg, pudiste administrar las tablas de Iceberg y mantener seguros los archivos de la tabla subyacente en Cloud Storage. Al establecer Knowledge Catalog como tu motor de contexto universal, definiste etiquetas de política en una ubicación central y las aplicaste de manera coherente en diferentes motores de consultas, como BigQuery SQL y Apache Spark. Por último, realizaste un seguimiento automático de todo el recorrido de tus datos con el linaje de datos en tiempo real.
¿Qué sigue?
- Recupera el contexto de los datos para los agentes de IA: Recupera el contexto de los datos con la API de Context.
- Análisis en profundidad del linaje de datos: Consulta la información del linaje de datos.
- Explora el control de acceso avanzado: Para implementar situaciones de seguridad más complejas, revisa la documentación oficial sobre la personalización de Lakehouse con funciones adicionales.
- Managed Service para Apache Spark: Descubre cómo escalar canalizaciones de datos sin aprovisionar clústeres en la página de documentación de Serverless Spark.
- Prueba otros casos de uso: Prueba otros casos de uso de Knowledge Catalog.