
Casos de uso de Knowledge Catalog
Ejecuta consultas complejas en lenguaje natural sobre los recursos de datos empresariales con un agente de descubrimiento que realiza llamadas a la API de Knowledge Catalog (Python).
Genera resúmenes potenciados por IA para tus recursos de datos a gran escala con un agente de enriquecimiento que realiza llamadas a la API de Knowledge Catalog (Python).
Diseña flujos de trabajo de estadísticas en varias nubes en almacenes de datos distribuidos con agentes de IA y Knowledge Catalog como el gráfico de contexto.
Adjunta metadatos estructurados y basados en esquemas (aspectos) y definiciones comerciales (glosarios) a tus activos de datos (entradas) con la consola de Google Cloud.
Crea tablas de Apache Iceberg, aplica políticas de datos centralizadas para la seguridad a nivel de la columna, define políticas de seguridad y visualiza el linaje de datos automatizado.
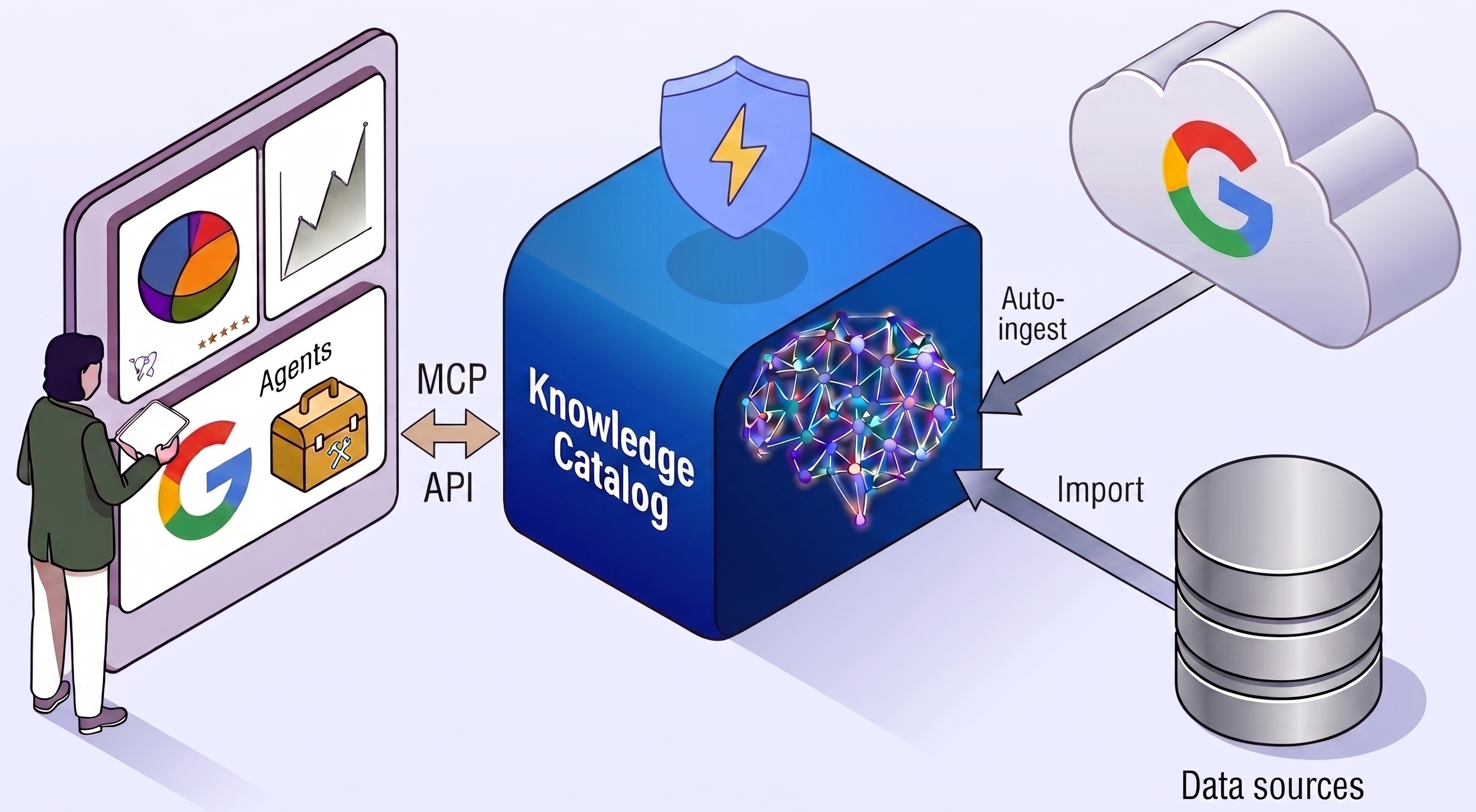
Ingiere automáticamente metadatos de servicios de Google, como BigQuery.
Indexa metadatos de fuentes de datos personalizadas con APIs abiertas.
A través de Gemini CLI, usa consultas en lenguaje natural para crear perfiles de datos y generar reglas de calidad, y, luego, implementa reglas de calidad de los datos como análisis automatizados.
Verifica que Knowledge Catalog pueda distinguir entre los datos de origen y los derivados temporales con consultas en lenguaje natural a la Gemini CLI.
Identificar cómo las transformaciones de datos afectan los recursos, la integridad de los datos y los flujos de trabajo posteriores
Haz un seguimiento del flujo de datos sensibles hasta el proceso que los mueve de una ubicación de confianza a una que no lo es.
Identifica los activos que no se usan de forma activa como fuentes para otros procesos y, así, reduce los costos de almacenamiento.
Recupera contexto preformateado y listo para LLM para los recursos de datos con una sola solicitud a la API.