
BigQuery 是 Google 推出的全代管式低成本分析型数据仓库,可支持 PB 级数据规模。利用数据洞察 BigQuery 连接器,您可以在数据洞察内访问 BigQuery 表中的数据。
准备工作
如需在 Data Studio 中访问 BigQuery 数据,您需要提供 Google Cloud 结算账号。BigQuery 是一款付费产品,通过数据洞察访问 BigQuery 时可能会产生 BigQuery 使用费。详细了解 BigQuery 定价。
如何连接到 BigQuery
您可以将数据洞察连接到 Google BigQuery 中的表、视图或自定义查询。
连接步骤
依次点击 创建 和报告 。
报告编辑器随即显示,将数据添加到报告 面板也会打开。
如需创建新的嵌入式 数据源,请选择 BigQuery 连接器。
- 如需选择现有的可重复使用的数据源,请点击我的数据源 标签页,然后选择您之前创建的或与您共享的任何类型的数据源。
配置数据源连接,以连接到您的 BigQuery 数据。您可以连接到 BigQuery 表或视图,也可以使用 自定义 SQL 查询 进行连接。
点击 Add (添加)。
片刻之后,与数据源关联的表会显示在报告画布上。
嵌入式数据源与可重复使用的数据源说明
数据源可以是嵌入式数据源,也可以是可重复使用的数据源。报告可以同时包含嵌入式数据源和可重复使用的数据源。
在修改报告时创建的数据源是嵌入式数据源 。如需修改嵌入式数据源,您需要在该报告内进行修改。嵌入式数据源可让您更轻松地协作处理报告和数据源。任何有权修改报告的用户都可以修改数据源及其连接。当您共享或复制报告时,系统也会共享或复制所有嵌入式数据源。
从首页创建的数据源是可重复使用的数据源 。您可以在不同的报告中重复使用这些数据源。借助可重复使用的数据源,您可以在组织内创建和共享一致的数据模型。只有您选择与之共享可重复使用的数据源的用户才能修改该数据源。只有数据源凭据的所有者才能修改连接。
详细了解数据源。
您是数据洞察新手吗?
您可以使用属性面板更改表的数据和样式。您可以使用工具栏向报告添加更多图表、控件和其他组件。
连接到 BigQuery 表或视图
BigQuery 表包含按行整理的各条记录。每条记录都由列(也称为 字段)组成。BigQuery 视图是由 SQL 查询定义的虚拟表,该查询在 BigQuery 控制台中执行。
如需连接到表或视图,您需要提供以下信息:
- BigQuery 项目
- 数据集
- 表或视图
项目
项目用于整理 BigQuery 资源,并在报告超出 BigQuery 的免费配额时提供结算所需的信息。您可以将同一个项目用于结算和数据管理,也可以将一个项目用于数据,同时将另一个项目用于结算。详细了解 Google Cloud 项目。
选择以下选项之一来选择您的项目:
- 近期的项目
- 我的项目
- 共享项目
近期的项目
近期的项目 选项会显示您最近在 Google Cloud 控制台中访问过的项目。您也可以手动输入项目 ID。您选择的项目将同时用于结算和数据访问权限。选择项目后,您需要选择数据集。
我的项目
借助我的项目 选项,您可以选择您有权访问的任何项目。您也可以手动输入项目 ID。您选择的项目将同时用于结算和数据访问权限。选择项目后,您需要选择数据集。
如果您有权访问多个项目,则这些项目可能不会全部显示在列表中。当列表中的项目数超出上限时,您可以在输入字段中直接输入未列出的项目。
共享项目
借助共享项目 选项,您可以访问与您共享的项目。您可以为数据和结算选择不同的项目。
数据集
数据集用于整理数据并控制对数据的访问权限。您可以从列表中选择数据集,也可以按名称搜索数据集。
公共数据集
BigQuery 公共数据集 是公共示例,其中数据集是共享的,但项目不是共享的。如需查询此数据,您必须指定自己的结算项目,该项目将用于结算共享数据的处理费用。
表
您可以将数据洞察数据源连接到单个表或视图。
连接到按日期分区的表
数据洞察 可以利用 BigQuery 按日期分区的表。当您连接到按 DATE、DATETIME 或 TIMESTAMP 字段分区的表时,数据洞察可以将该字段用作基于此数据源的图表的日期范围维度。
详细了解如何将 Data Studio 连接到 BigQuery 按日期分区的表。
使用自定义 SQL 查询连接到 BigQuery
借助自定义查询 选项,您可以通过编写 SQL 来连接到数据。自定义查询语法遵循 标准 SQL 方言。如需使用旧版 BigQuery SQL 方言,请选择 使用旧版 SQL 选项。
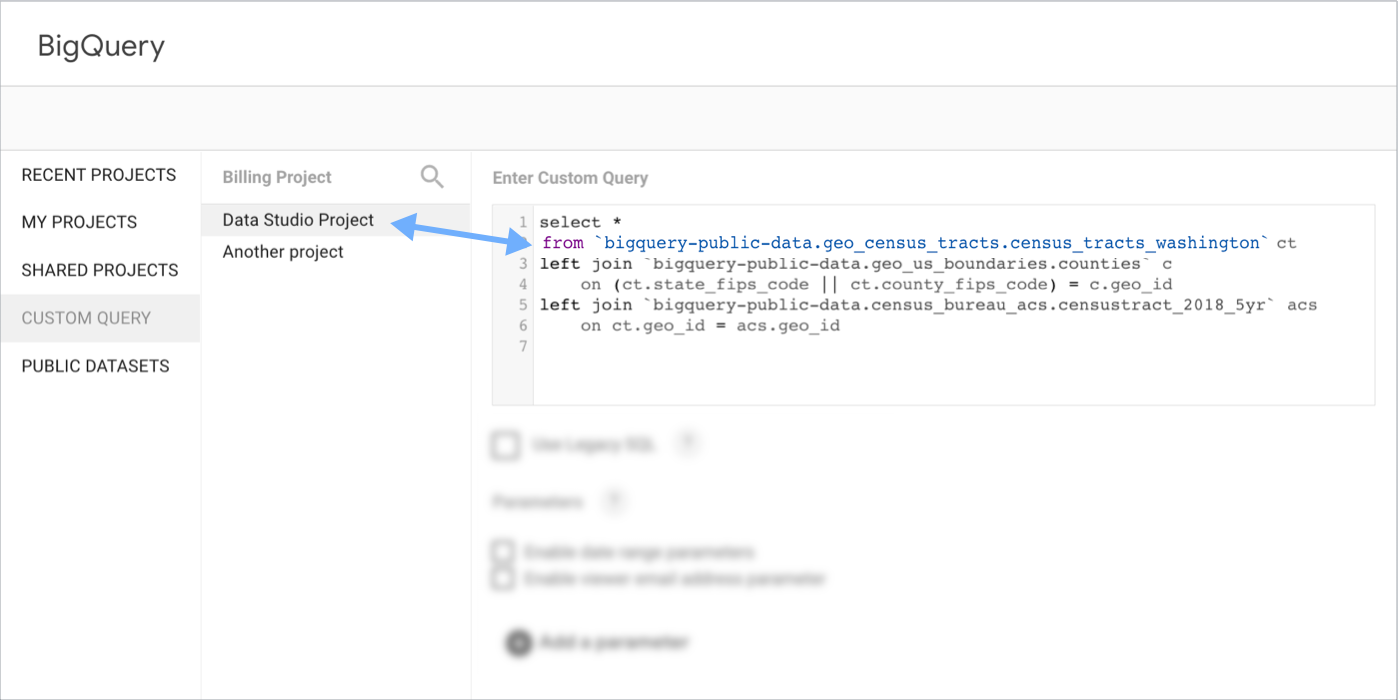
使用 BigQuery 界面 编写和测试查询,然后将该查询复制并粘贴到数据洞察自定义查询框中。
结算项目
借助结算项目 选项,您可以通过搜索或手动输入项目 ID 来为自定义查询提供结算项目。如果您的组织有多个 BigQuery 项目,您可能需要使用手动输入方法来查找项目。
如需将一个项目用于结算,并将另一个项目用于数据,请在界面中选择或输入结算项目,然后在自定义查询的 SELECT...FROM 子句中添加数据项目。
查询参数
借助参数,您可以构建响应速度更快、可自定义的报告。您可以在 BigQuery 数据源中将参数传递回底层查询。如需在自定义查询中使用参数,请遵循在 BigQuery 中运行参数化查询的语法指南。
自定义查询的限制
对于发送到数据库的每个查询,数据洞察都会将您的自定义 SQL 用作内部 SELECT 语句。实际上,您的自定义查询会生成一个新的虚拟表,然后 Data Studio 会使用其自己生成的“外部”SQL 查询该表。因此,数据洞察中的自定义查询受到以下限制:
自定义 SQL 查询只能包含一条语句
例如,以下查询将不起作用,因为它包含多条 SQL 语句:
DECLARE cost_per_tb_in_dollar FLOAT64 DEFAULT 4.2;
SELECT total_bytes_billed / (1024 * 1024)* cost_per_tb_in_dollar)/(1024*1024))) FROM billing-table;
在联接中使用明确的字段名称
自定义联接查询无法处理重复的列名称。如果图表使用的数据源基于包含重复字段的自定义查询,则会返回类似于以下内容的用户配置错误:
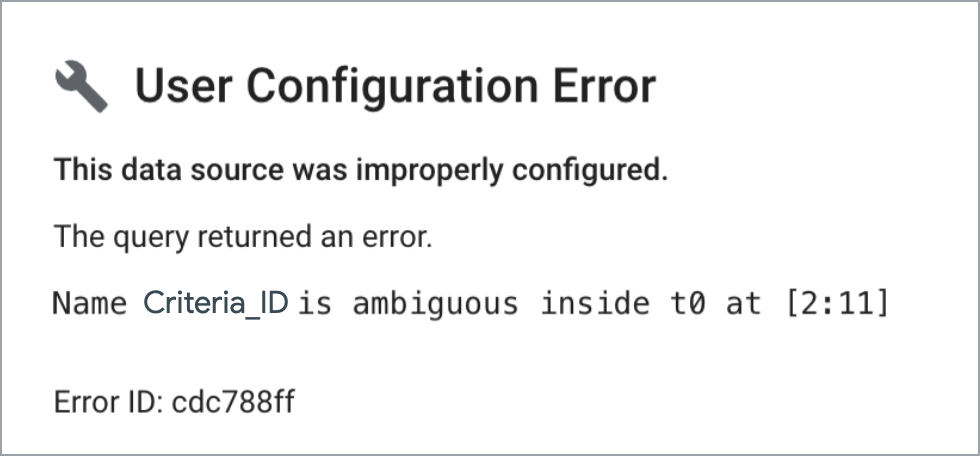
为避免此问题,请务必在自定义查询中使用明确的字段名称。
例如,假设您要联接两个具有相同架构的表,并联接两个表中都存在的 Criteria_ID 字段。
SELECT * FROM (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_1'
) As table_1
LEFT JOIN (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_2'
) As table_2
ON
table_1.Criteria_ID = table_2.Criteria_ID
此查询包含以下重复的列名称:
Criteria_IDParent_IDName
为避免 Field is ambiguous 错误,您可以使用 AS 关键字显式重命名重复的字段:
SELECT *
FROM (
SELECT
Criteria_ID AS Criteria_ID_1,
Parent_ID AS Parent_ID_1,
Name AS NAME_1
FROM
'table_1' ) AS table_1
LEFT JOIN (
SELECT
Criteria_ID AS Criteria_ID_2,
Parent_ID AS Parent_ID_2,
Name AS NAME_2
FROM
'table_2' ) AS table_2
ON
table_1.Criteria_ID_1 = table_2.Criteria_ID_2;
如果您只需要重命名几个字段,可以选择除要重命名的字段之外的所有字段,例如:
SELECT * EXCEPT (city), city AS city_1 FROM 'table_1'
查询超时
数据洞察中的自定义查询可能会在三到五分钟后超时。如果您的自定义查询超时,请尝试以下方法来解决此问题:
- 简化查询,使其运行速度更快。
- 在数据库中运行查询,并将结果存储在单独的表中。然后在数据源中连接到该表。
- 如果您的查询继续失败并显示
HTTP 504 Gateway timeout错误,请将自定义查询迁移到 BigQuery 视图 或 物化视图,然后更新数据洞察数据源以连接到该视图。
多日表
BigQuery 支持 跨多个表进行查询,其中每个表都包含一天的相关数据。这些表的格式为 YYYYMMDD。当数据洞察遇到格式为 YYYYMMDD 的表时,该表将被标记为多日表,并且表选择器中只会显示名称前缀_YYYYMMDD。
创建图表以直观呈现此表时,数据洞察会自动创建过去 28 天的默认日期范围,然后正确查询过去 28 个表。您可以通过以下方式配置此设置:修改报告,选择图表,然后在图表的数据 标签页中调整日期范围 属性。
查看发送到 BigQuery 的 SQL
您可以在 BigQuery 查询历史记录界面 中查看数据洞察生成的所有 BigQuery SQL。
记录数指标
BigQuery 数据源会自动提供默认的记录数 指标。您可以使用此指标细分维度,以显示图表汇总的记录数。
支持 VPC Service Controls
数据洞察 可以通过查看者基于 IP 的访问权限级别连接到受 VPC Service Controls (VPC-SC) 边界保护的 BigQuery 项目。BigQuery 连接器会将报告查看者的 IP 地址传递给 BigQuery,然后 BigQuery 可以强制执行已设置的任何基于 IP 的访问权限级别。
对 VPC Service Controls 失败进行问题排查
以下介绍了意外的 VPC Service Controls 失败以及如何对其进行问题排查:
- 问题说明 :用户在 VPN 之外查看报告时可能会遇到
Service Control Failure错误,即使主要数据集位于 VPC-SC 边界之外也是如此。 - 根本原因 :此错误通常是由报告中受 VPC-SC 边界保护的结算项目使用的旧版或“幽灵”BigQuery 自定义查询数据源引起的。
解决方法 :如需识别和修复这些隐藏的数据源,请按以下步骤操作:
- 复制 受影响的报告。
- 在新副本中,依次前往资源 > 管理添加的数据源 。
- 找到并更新所有“BigQuery 自定义 SQL”来源,以使用非边界化的结算项目;如果不再需要这些来源,请将其删除。
直观呈现 BigQuery GEOGRAPHY 多边形
您可以在报告中使用 Google 地图可视化图表显示 GEOGRAPHY 多边形。如需查看教程,请参阅使用数据洞察直观呈现 BigQuery GEOGRAPHY 多边形。
使用作业标签分析数据洞察查询
数据洞察 发送到 BigQuery 的所有查询都具有 BigQuery 作业标签 requestor:looker_studio。您可以使用此作业标签来识别与数据洞察相关的 BigQuery 查询。如需详细了解 BigQuery 中的标签,请参阅查看标签 BigQuery 文档页面。
如果您是 BigQuery 数据源的所有者,还可以点击 Powered by BigQuery 图标来查看作业详情。
如需详细了解如何跟踪数据洞察图表和报告的性能和费用,请参阅使用数据洞察分析数据 BigQuery 文档页面。
BigQuery 对话框
如果您拥有 BigQuery 数据源的所有者凭据,数据洞察 将在任何使用 BigQuery 的图表的右上角显示 BigQuery 图标。将鼠标悬停在图表上,然后点击 BigQuery 图标以打开 BigQuery 对话框。该对话框会显示指向 BigQuery 作业详情页面的链接。BigQuery 作业详情页面包含以下信息:
- 图表的 SQL 查询
- SQL 查询返回的数据
- 查询步骤的每个阶段的细分
- 查询统计信息,例如总运行时和使用的槽数
使用 BigQuery Storage Read API 提升性能
对于使用分页结果的查询,启用 BigQuery Storage Read API 可以缩短查询时间。当使用 Storage Read API 可以缩短查询运行时时,数据洞察会自动使用该 API。
如需启用 BigQuery Storage Read API,请向连接到 Data Studio 的 BigQuery 用户授予以下权限:
bigquery.readsessions.createbigquery.readsessions.getData
配额和一般限制
一般来说,BigQuery 数据源受与 BigQuery 本身相同的 速率限制和配额限制 约束。
最大行数
使用 BigQuery 连接器可以返回的最大行数为 200 万行。当数据超过 200 万行时,数据洞察会进行提示,但不会指定行数。
最大表数
对于 BigQuery 连接,使用数据洞察连接器时,每个数据集的表数上限为 5,000 个。如果超出此限制,当数据洞察加载数据集的表列表时,界面可能会变得无响应。
如果遇到此限制,您可以使用以下解决方法之一:
- 使用自定义查询:使用自定义 SQL 查询连接到 BigQuery,而不是连接到表。例如:
SELECT * FROM project.dataset.table。 - 从 BigQuery 连接:在 BigQuery 控制台中,使用导出 或探索数据 选项,然后选择在 Looker Studio 中打开。
- 管理数据集:将表重新整理为较小的数据集(表数少于 5,000 个),或创建仅包含必要表或视图的专用报告数据集。
MEDIAN 和 PERCENTILE 函数
对于 BigQuery 数据源,MEDIAN 和 PERCENTILE 是使用 BigQuery APPROX_QUANTILES 函数实现的。将 MEDIAN 或 PERCENTILE 应用于 BigQuery 中的数据时,返回的结果可能与将 MEDIAN 或 PERCENTILE 应用于其他数据源类型中的相同数据时返回的结果略有不同。
客户管理的加密密钥 (CMEK)
BigQuery 连接器不支持客户管理的加密密钥 (CMEK)。如果您的 Google Cloud 项目受需要 CMEK 的 组织政策 约束,数据洞察 将无法查询数据,并返回 CONDITION_NOT_MET 错误。
TIME 数据类型
数据洞察不支持 BigQuery TIME 数据类型。数据集中的任何 TIME 字段都会在 数据洞察 中转换为 TEXT 字段。如需在报告中直观呈现时间数据,您可以使用以下解决方法之一将 TIME 数据转换为 DATETIME 数据类型:
解决方法 1:使用自定义查询
在数据洞察中使用 BigQuery 自定义查询作为数据源。将 TIME 字段与“虚拟”日期相结合,以创建数据洞察支持的 DATETIME 值。
自定义 SQL 查询
SELECT
*,
-- Combine a dummy date (1970-01-01) with your TIME field
DATETIME(DATE "1970-01-01", your_time_field) AS time_as_datetime
FROM
`your_project.your_dataset.your_table`
- 结果 :数据洞察 将
time_as_datetime视为日期和时间 数据类型。 - 自定义:如需隐藏虚拟日期并仅显示时间部分,请在报告中修改 time_as_datetime 字段的显示格式,然后选择一种格式,例如小时或分钟,或者提供自定义格式,例如 h:mm:ss。详细了解字段显示格式。
解决方法 2:使用计算字段
如果您不想更改 SQL 查询,可以使用计算字段直接在数据洞察中处理转换。此示例假定 BigQuery TIME 字段包含“小时:分钟:秒”格式的数据(例如 23:59:59)。
计算字段公式
PARSE_DATETIME("%H:%M:%S", CAST(your_time_field AS TEXT))
- 结果 :
PARSE_DATETIME函数会将字符串转换为日期和时间 对象。CAST函数可确保将your_time_field视为TEXT。由于字符串中未指定日期,因此数据洞察会自动将日期部分默认设置为 1970 年 1 月 1 日 。详细了解 PARSEDATE 函数。 - 自定义 :与自定义查询解决方法一样,您随后可以在图表的设置 标签页中更改字段的显示格式 ,以确保图表中仅显示相关时间信息。