
本文提供資料混合的建議和深入資訊,協助您瞭解混合的運作方式,並解決複雜的用途。如要充分瞭解本文,您應已熟悉資料混合的基本概念,這部分內容已在本主題的其他文章中說明。
混搭資料應只包含部分可用資料
最佳做法是只納入您想在混合資料來源的圖表中顯示的特定欄位。這項功能的重要性如下:
- 混搭功能可能會建立非常龐大的資料集,導致效能降低,並可能增加 BigQuery 等付費服務的查詢費用。
- 以混合為基礎的圖表會計算混合中的所有資料列,即使這些資料列未在圖表中使用也是如此。
- 舉例來說,假設您建立的混合資料包含 10 個欄位。接著,定義只使用其中一個欄位的圖表。數據分析會計算 10 個欄位的混合資料,然後查詢混合資料輸出內容中的 1 個欄位,藉此建立圖表。
- 只有在混合資料包含基礎資料的子集時,才會重新彙整。
使用混合功能重新匯總指標
您從基礎資料來源納入的指標,在混合資料中會變成未經匯總的數字。如果混合資料包含的欄位少於基礎資料來源的完整欄位集,系統會根據新資料重新彙整這些數字。如果您需要對已匯總的欄位套用不同的匯總,例如計算平均值的平均值,這種方式的資料混合就很有用。
詳情請參閱「使用混合功能重新彙整資料」。
從單一資料來源建立混合資料
混搭不一定要使用不同的資料來源。您也可以混合來自相同資料來源的多個資料表,重新彙整資料。
舉例來說,假設您有一個資料集,其中包含美國人口最多的前三個郡的人口資料,如下表所示:
| 州 |
郡/縣 |
人口數 (2023 年估計) |
|---|---|---|
| 加州 |
洛杉磯郡 |
10,014,009 |
| 加州 |
聖地牙哥郡 |
3,298,634 |
| 加州 |
橘郡 |
3,186,989 |
| 德州 |
哈里斯郡 |
4,731,145 |
| 德州 |
達拉斯郡 |
2,613,539 |
| 德州 |
塔蘭特郡 |
2,110,640 |
| 紐約 |
金斯郡 (布魯克林) |
2,736,074 |
| 紐約 |
皇后區 |
2,405,464 |
| 紐約 |
布朗克斯郡 |
1,418,890 |
您想計算州內每個郡的人口百分比,但為此需要將每個州的人口總數做為獨立欄位。資料集中沒有這項指標,但您可以按照下列步驟,將人口資料來源與自身混合,即可取得這項指標:
- 使用基礎資料集建立資料來源。
- 將使用該資料來源的圖表新增至報表。
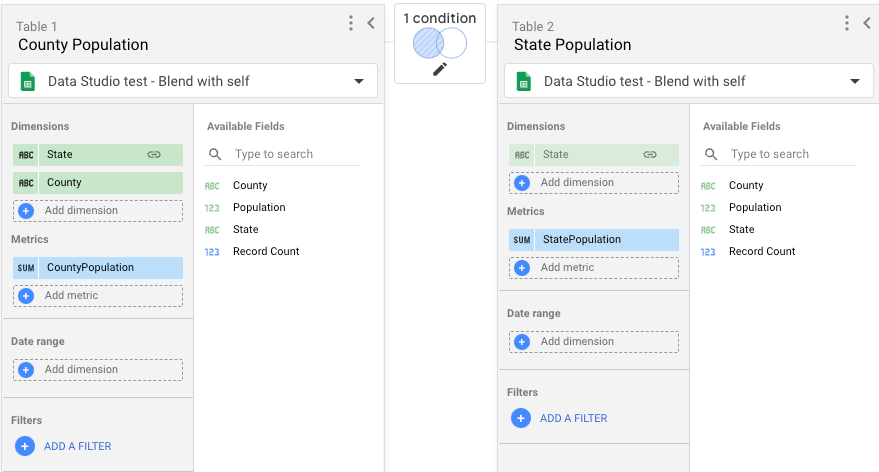
- 使用兩個資料表建立混合資料。每個資料表都會使用您在步驟 1 中建立的相同資料來源。
- 針對表 1,請加入下列欄位:
- 州/省、縣/市、人口。
- 將「Population」重新命名為「CountyPopulation」。
- 在資料表 2 中,只納入「Population」(人口) 欄位,並將該欄位重新命名為「StatePopulation」(州人口)。
- 針對表 1,請加入下列欄位:
- 彙整條件請使用「Left Outer」(左外部) 彙整,將資料表 1 中的「State」(州) 連結至資料表 2 中的「State」(州)。
- 按一下 [儲存]。
- 按一下「X」X返回報表編輯器。
接著,在報表中新增圖表 (例如表格),然後按照下列步驟,選取資料混合做為圖表的資料來源:
- 在圖表中新增「State」(州)、「County」(郡)、「CountyPopulation」(郡人口) 和「StatePopulation」(州人口) 欄位。
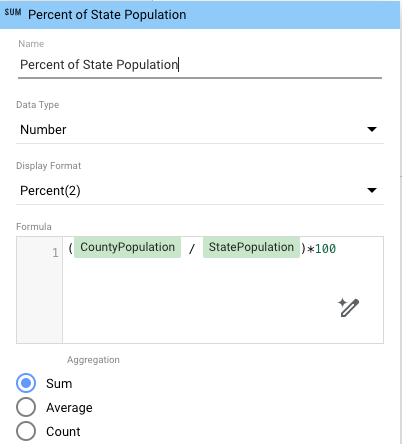
- 如要計算每個縣市的州人口百分比,請在圖表中新增計算結果欄位,並使用重新彙整的新資料:
- 在「屬性」面板中,依序點按「新增指標」和「新增欄位」。
- 為欄位命名 (例如「州人口百分比」)。
- 在「公式」方塊中輸入
(CountyPopulation / StatePopulation)*100。 - (選用) 設定「顯示格式」,將百分比值顯示到特定位數 (例如「百分比 (2)」表示顯示到小數點後兩位)。
完成後,表格應如下所示:
| 州 |
郡/縣 |
CountyPopulation |
StatePopulation |
州人口百分比 |
|---|---|---|---|---|
| 加州 |
洛杉磯郡 |
10014009 |
16499632 |
60.69 |
| 德州 |
哈里斯郡 |
4731145 |
9455324 |
50.04 |
| 加州 |
聖地牙哥郡 |
3298634 |
16499632 |
19.99 |
| 加州 |
橘郡 |
3186989 |
16499632 |
19.32 |
| 紐約 |
金斯郡 (布魯克林) |
2736074 |
6560428 |
41.71 |
| 德州 |
達拉斯郡 |
2613539 |
9455324 |
27.64 |
| 紐約 |
皇后區 |
2405464 |
6560428 |
36.67 |
| 德州 |
塔蘭特郡 |
2110640 |
9455324 |
22.32 |
| 紐約 |
布朗克斯郡 |
1418890 |
6560428 |
21.63 |
混合中的表格順序
數據分析 會依序評估混合中的聯結設定,從最左側的設定開始。然後,每個聯結的結果都會套用至右側的下一個聯結。舉例來說,在三個資料表的混合中,系統會評估資料表 1 (最左側) 和資料表 2 (中間) 之間的聯結設定,然後資料表 2 和資料表 3 (最右側) 之間的聯結設定會使用這些結果。
自動建立的混合資料表中的資料表順序
混合選取的圖表時,數據分析 會為每個圖表建立資料表,然後將圖表中的欄位新增至對應的資料表。混合中的資料表順序與您選取圖表的順序一致:選取的第一個圖表會成為第一個 (最左側) 資料表,選取的第二個圖表會成為第二個資料表,依此類推。
數據分析 也會自動為每個資料表建立彙整設定,並使用左外部聯結類型。
如果預設設定不符合需求,或資料表之間沒有明確的連結,您可以編輯混合資料,以符合目標。
在混合前建立資料表
系統會先查詢混合中每個資料表的資料,再將這些資料併入最終混合。系統會先將資料表中的日期範圍、篩選器和計算欄位套用至產生資料表的查詢,然後再執行任何聯結。這些因素可能會影響混合資料表所含的資料,並改變混合結果。
混搭的資料列可能比 SQL 聯結少
在資料併入最終混合資料前,系統會根據您在表格中加入的維度,將混合資料中每個表格的資料分組並匯總。如果您選取的維度未包含每筆記錄的專屬 ID,系統會在表格合併前,於預先分組階段摺疊相同資料列。這項摺疊作業可能會導致列數比直接對相同資料執行 SQL JOIN 查詢時還少,因為 SQL JOIN 會在匯總前獨立評估資料列。
為避免資料列過早收合,並確保數據分析中的混合作業產生的資料列數量與 SQL 聯結作業產生的數量相似,請在混合編輯器中,為每個資料表新增專屬 ID 欄位 (例如主鍵或專屬資料列 ID) 至維度清單。這個 ID 欄位不需顯示在圖表中;在混合設定中加入這個欄位,可確保每個記錄在預先彙整步驟中都會視為不同的資料列。
混合資料可能包含的資料列比原始資料多
與根據混合資料來源的個別圖表相比,混合圖表可能會顯示更多資料。結果取決於您的資料,以及為混合資料選擇的聯結設定。舉例來說,左外部聯結會納入左側資料表的所有記錄,以及右側資料表中與聯結條件共用相同值的所有記錄。如果彙整條件有多個相符項目,彙整資料中的資料列可能會比最左側資料來源中的資料列還多。
混合和明確的日期範圍和篩選條件
如要限制混合資料中的列數,可以使用日期範圍或套用篩選器。您可以限制以混合資料為基礎的圖表,或組成混合資料的表格中的資料列。建議將這個程序視為「混合前」或「混合後」。
如果您對混合中的資料表套用日期範圍或篩選器,系統會先套用這些設定,再將資料與混合中的其他資料表聯結。如果資料列超出日期範圍或遭篩選器排除,聯結查詢就無法處理。
如果根據混合資料對圖表套用日期範圍或篩選器,系統會對混合資料建立「後」的資料套用這些設定。
視資料和混合設定而定,這項差異可能會對圖表中的結果造成重大影響。
混合和繼承的篩選器
只要篩選條件與前混合或後混合資料相容,混合資料就會沿用報表、頁面或群組層級的篩選條件。如果篩選器與混合使用的基礎資料來源相容,篩選器就會對混合前資料套用篩選條件。否則,篩選條件會套用至混合後的資料。如果篩選器與前融合或後融合資料不相容,系統會忽略該篩選器。
進一步瞭解篩選器沿用。
如果以混合資料為基礎的圖表套用沿用篩選器,數據分析會依下列五個步驟處理資料:
(前置混合):
- 步驟 1:系統會根據「混合資料」面板中指定的維度,將資料分組並匯總。
- 步驟 2:系統會將沿用的維度篩選器和相容的指標篩選器,套用至「混合資料」面板中包含的資料來源。
(混合):
- 步驟 3:系統會使用指定的聯結設定混合資料。
(後混合):
- 步驟 4:系統會根據圖表中的維度,將資料分組並匯總。
- 步驟 5:如果指標篩選器與混合資料相容,系統會將篩選器套用至圖表。