
本文中的信息提供了有关数据混合的建议和深入信息,可帮助您了解混合的工作原理并解决复杂的用例。为了充分理解本文,您应该已经熟悉数据混合的基础知识,这些知识在本文档的其他文章中有所介绍。
混合应仅包含可用数据的子集
最佳做法是,您应仅在基于混合的图表中包含要可视化的特定字段。原因如下:
- 混合可能会创建非常大的数据集,这可能会导致性能下降,并可能增加 BigQuery 等付费服务的查询费用。
- 基于混合的图表会计算混合中的所有行,即使这些行未在图表中用到也是如此。
- 例如,假设您创建了一个包含 10 个字段的混合。然后,您定义了一个仅使用其中 1 个字段的图表。数据洞察会计算包含 10 个字段的混合,然后在混合的输出中查询该 1 个字段,以创建图表。
- 仅当混合包含底层数据的子集时,才会重新汇总。
使用混合重新聚合指标
您从底层数据源中添加的指标在混合中会变成未聚合的数字。当混合包含的字段少于底层数据源中的完整字段集时,这些数字会根据新数据重新聚合。如果您需要对已聚合的字段应用不同的聚合,例如计算平均值的平均值,则以这种方式使用混合可能会很有用。
如需了解详情,请参阅使用混合重新聚合数据。
从单个数据源创建混合
混合不一定需要使用不同的数据源。您可能还会发现,通过混合来自同一数据源的多个表来重新聚合数据也很有用。
例如,假设您有一个数据集,其中包含人口最多的美国各州中人口最多的三个县的人口数据,如下表所示:
| 州 |
县 |
人口(2023 年估计值) |
|---|---|---|
| 加利福尼亚州 |
洛杉矶县 |
10,014,009 |
| 加利福尼亚州 |
圣迭戈县 |
3,298,634 |
| 加利福尼亚州 |
橙县 |
3,186,989 |
| 得克萨斯州 |
哈里斯县 |
4,731,145 |
| 得克萨斯州 |
达拉斯县 |
2,613,539 |
| 得克萨斯州 |
塔兰特县 |
2,110,640 |
| 纽约州 |
金斯县(布鲁克林) |
2,736,074 |
| 纽约州 |
皇后区 |
2,405,464 |
| 纽约州 |
布朗克斯区 |
1,418,890 |
您想要计算每个县在州内的人口百分比;但是,为此,您需要将每个州的总人口作为自己的字段。在数据集中,该指标不可用,但您可以通过将人口数据源与自身混合来获取该指标,具体方法是执行以下步骤:
- 使用基本数据集创建数据源。
- 向报告添加使用该数据源的图表。
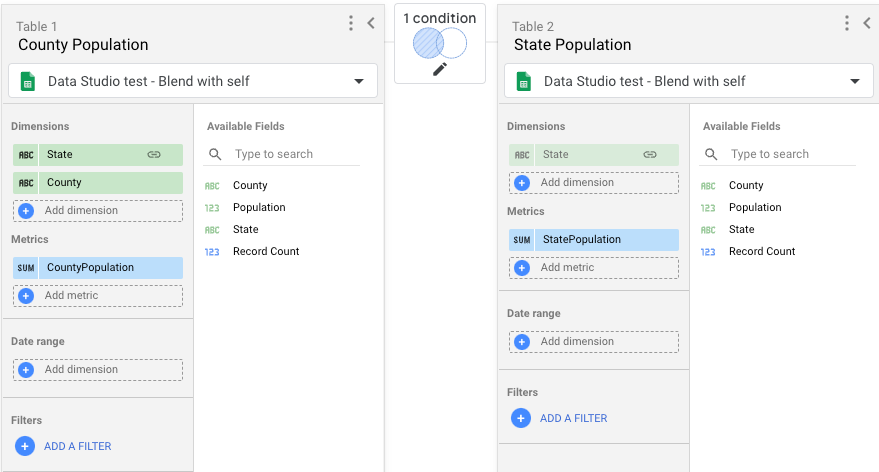
- 创建包含两个表的混合。每个表都将使用您在第 1 步中创建的同一数据源。
- 对于表 1,请添加以下字段:
- 州、县、人口。
- 将人口 重命名为 CountyPopulation 。
- 对于表 2,仅添加人口 字段,并将该字段重命名为 StatePopulation 。
- 对于表 1,请添加以下字段:
- 对于联接条件,请使用左外 联接,将表 1 中的州 链接到表 2 中的州 。
- 点击保存 。
- 点击 X 返回到报告编辑器。
接下来,向报告添加新图表(例如表格),然后执行以下步骤,选择混合作为图表的数据源:
- 将州 、县 、CountyPopulation 和 StatePopulation 字段添加到图表中。
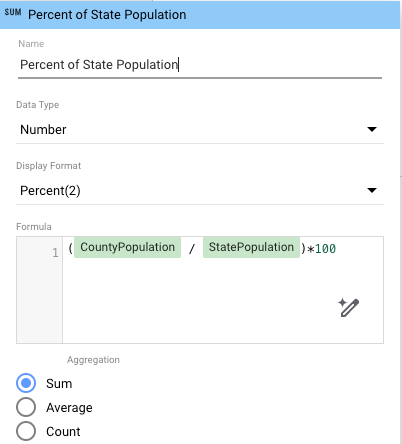
- 如需计算每个县在州内的人口百分比,请向图表添加一个计算字段,该字段使用您新重新聚合的数据:
- 在属性面板中,点击添加指标 ,然后点击添加字段 。
- 为该字段命名(例如)Percent of State Population 。
- 在公式 框中,输入
(CountyPopulation / StatePopulation)*100。 - (可选)设置显示格式 ,以将百分比值显示到特定级别(例如,百分比 (2) 表示保留两位小数)。
完成后,您的表格应如下所示:
| 州 |
县 |
CountyPopulation |
StatePopulation |
Percent of State Population |
|---|---|---|---|---|
| 加利福尼亚州 |
洛杉矶县 |
10014009 |
16499632 |
60.69 |
| 得克萨斯州 |
哈里斯县 |
4731145 |
9455324 |
50.04 |
| 加利福尼亚州 |
圣迭戈县 |
3298634 |
16499632 |
19.99 |
| 加利福尼亚州 |
橙县 |
3186989 |
16499632 |
19.32 |
| 纽约州 |
金斯县(布鲁克林) |
2736074 |
6560428 |
41.71 |
| 得克萨斯州 |
达拉斯县 |
2613539 |
9455324 |
27.64 |
| 纽约州 |
皇后区 |
2405464 |
6560428 |
36.67 |
| 得克萨斯州 |
塔兰特县 |
2110640 |
9455324 |
22.32 |
| 纽约州 |
布朗克斯区 |
1418890 |
6560428 |
21.63 |
混合中的表格顺序
数据洞察会按顺序评估混合中的联接配置,从最左侧的配置开始。然后,每个联接的结果会应用于右侧的下一个联接。例如,在包含三个表的混合中,系统会评估表 1(最左侧)和表 2(中间)之间的联接配置,然后表 2 和表 3(最右侧)之间的联接配置会使用这些结果。
自动创建的混合中的表格顺序
当您混合所选的图表时,数据洞察会为每个图表创建一个表,然后将图表中的字段添加到相应的表中。混合中的表格顺序与您选择图表的顺序一致:选择的第一个图表会成为第一个(最左侧)表,选择的第二个图表会成为第二个表,依此类推。
数据洞察还会自动为每个表创建一个联接配置,并使用左外联接类型。
如果默认配置不符合您的要求,或者表之间没有明确的关联,您可以修改混合以满足您的目标。
先创建表,然后再混合
在将混合中每个表的数据联接到最终混合之前,系统会先查询这些数据。在执行任何联接之前,系统会将表中的日期范围、过滤条件和计算字段应用于生成表的查询。这些因素可能会影响混合表中包含的数据,并更改混合的输出。
混合可能包含的行数少于 SQL 联接
在将混合中每个表的数据联接到最终混合之前,系统会根据您在表中添加的维度对这些数据进行分组和聚合。如果您选择的维度不包含每条记录的唯一标识符,则在联接表之前,系统会在预分组阶段折叠相同的行。这种折叠可能会导致行数低于您直接对相同数据运行 SQL 联接查询所获得的行数,因为 SQL 联接会在聚合之前独立评估行。
为防止行过早折叠,并确保数据洞察中的混合生成的行数与 SQL 联接生成的行数相似,请向混合编辑器中每个表的维度列表添加唯一标识符字段(例如主键或唯一行 ID)。此 ID 字段不需要显示在图表中;将其包含在混合配置中可确保在预聚合步骤中将每条记录视为不同的行。
混合可能包含的行数多于原始数据
您可能会在混合图表中看到比在基于构成混合的各个数据源的图表中看到更多的数据。结果可能取决于您的数据以及为混合选择的联接配置。例如,左外联接包含左侧表中的所有记录,以及右侧表中在联接条件中共享相同值的所有记录。联接条件的多个匹配项可能会导致混合数据中显示的行数多于最左侧数据源中的行数。
混合以及明确的日期范围和过滤条件
限制混合中行数的两种方法是使用日期范围或应用过滤条件。您可以限制基于混合的图表中的行,也可以限制构成混合的表中的行。不妨将该过程视为“混合前”或“混合后”。
当您向混合中的表应用日期范围或过滤条件时,它会在数据与混合中的其他表联接之前生效。联接查询无法处理超出日期范围或被过滤条件排除的行。
当您向基于混合的图表应用日期范围或过滤条件时,您是在混合创建后(“混合后”)向数据应用该日期范围或过滤条件。
根据您的数据以及您配置混合的方式,这种差异可能会对您在图表中看到的结果产生重大影响。
混合和继承的过滤条件
只要过滤条件与混合前或混合后的数据兼容,混合就会继承报告、页面或组级过滤条件。如果过滤条件与混合使用的底层数据源兼容,则过滤条件会作用于混合前的数据。否则,过滤条件会作用于混合后的数据。如果过滤条件与混合前或混合后的数据都不兼容,则系统会忽略该过滤条件。
详细了解过滤条件继承。
当基于混合的图表受到继承的过滤条件的限制时,数据洞察会按以下五个步骤处理数据:
(混合前):
- 第 1 步: 系统会根据混合数据 面板中指定的维度对数据进行分组和聚合。
- 第 2 步: 系统会将继承的维度过滤条件和兼容的指标过滤条件应用于混合数据 面板中包含的数据源。
(混合):
- 第 3 步: 系统会使用指定的联接配置混合数据。
(混合后):
- 第 4 步: 系统会根据图表中的维度对数据进行分组和聚合。
- 第 5 步: 如果指标过滤条件与混合数据兼容,则系统会将这些过滤条件应用于图表。