
אתם יכולים לעקוב אחרי מדדים כמו ניצול GPU וזיכרון GPU מהמכונות הווירטואליות (VM) באמצעות Ops Agent, שהוא הפתרון המומלץ של Google לאיסוף טלמטריה ב-Compute Engine. באמצעות סוכן תפעול, אתם יכולים לנהל את מכונות ה-GPU הווירטואליות שלכם באופן הבא:
- אפשר להשתמש בלוחות הבקרה המוגדרים מראש כדי להציג את מצב הצי של NVIDIA GPU.
- אפשר לצמצם עלויות על ידי זיהוי של יחידות GPU שלא מנוצלות מספיק ואיחוד של עומסי עבודה.
- כדי לתכנן את ההרחבה, כדאי לבדוק את המגמות כדי להחליט מתי להרחיב את קיבולת ה-GPU או לשדרג את יחידות ה-GPU הקיימות.
- אפשר להשתמש במדדי פרופילים של NVIDIA Data Center GPU Manager (DCGM) כדי לזהות צווארי בקבוק ובעיות בביצועים ב-GPU.
- כדי להגדיר שינוי אוטומטי של גודל המשאבים, צריך להגדיר קבוצות של מופעי מכונה מנוהלים (MIG).
- קבלת התראות על מדדים ממעבדי ה-GPU של NVIDIA.
במסמך הזה מוסבר איך לעקוב אחרי יחידות GPU במכונות וירטואליות של Linux באמצעות סוכן תפעול. לחלופין, אפשר להגדיר סקריפט דיווח שזמין ב-GitHub כדי לעקוב אחרי השימוש ב-GPU במכונות וירטואליות ב-Linux. מידע נוסף זמין במאמר בנושא compute-gpu-monitoring סקריפט מעקב.
הסקריפט הזה לא מתוחזק באופן פעיל.
למידע על מעקב אחרי מעבדים גרפיים במכונות וירטואליות של Windows, אפשר לעיין במאמר בנושא מעקב אחרי ביצועים של מעבדים גרפיים (Windows).
סקירה כללית
סוכן תפעול, גרסה 2.38.0 ואילך, יכול לעקוב באופן אוטומטי אחרי שיעורי ניצול ה-GPU ושימוש בזיכרון ה-GPU במכונות וירטואליות של Linux שבהן מותקן הסוכן. המדדים האלה, שמתקבלים מ-NVIDIA Management Library (NVML), נמדדים לפי GPU ולפי תהליך, לכל תהליך שמשתמש ב-GPU. כדי לראות את המדדים שבמעקב של סוכן תפעול, אפשר לעיין במאמר מדדי סוכן: gpu.
אפשר גם להגדיר את השילוב של NVIDIA Data Center GPU Manager (DCGM) עם סוכן תפעול. השילוב הזה מאפשר לסוכן תפעול לעקוב אחרי מדדים באמצעות מוני החומרה ב-GPU. DCGM מספק גישה למדדים ברמת מכשיר ה-GPU. המדדים האלה כוללים את ניצול הבלוק של בלוק SM (Streaming Multiprocessor), את רמת התפוסה של ה-SM, את ניצול הצינור של ה-SM, את קצב תעבורת הנתונים של PCIe ואת קצב תעבורת הנתונים של NVLink. כדי לראות את המדדים שבמעקב של סוכן תפעול, אפשר לעיין במאמר מדדים של אפליקציות צד שלישי: NVIDIA Data Center GPU Manager (DCGM).
כדי לבדוק את מדדי ה-GPU באמצעות סוכן תפעול, מבצעים את השלבים הבאים:
- בכל מכונה וירטואלית, בודקים אם עומדים בדרישות.
- בכל מכונה וירטואלית, מתקינים את סוכן התפעול.
- אופציונלי: בכל מכונה וירטואלית, מגדירים את השילוב של NVIDIA Data Center GPU Manager (DCGM).
- בודקים את המדדים ב-Cloud Monitoring.
מגבלות
- סוכן תפעול לא עוקב אחרי השימוש ב-GPU במכונות וירטואליות שמשתמשות במערכת הפעלה שמותאמת לקונטיינרים.
דרישות
בכל מכונה וירטואלית, בודקים שאתם עומדים בדרישות הבאות:
- לכל מכונה וירטואלית צריך להיות GPU מצורף.
- בכל מכונה וירטואלית צריך להתקין מנהל התקן של GPU.
- מערכת ההפעלה וגרסת Linux של כל מכונה וירטואלית צריכות לתמוך ב-סוכן תפעול. ראו את רשימת מערכות ההפעלה של Linux שתומכות בסוכן תפעול.
- מוודאים שיש לכם גישת
sudoלכל מכונה וירטואלית.
התקנת סוכן התפעול
כדי להתקין את סוכן תפעול, מבצעים את השלבים הבאים:
אם השתמשתם בעבר בסקריפט המעקב
compute-gpu-monitoringכדי לעקוב אחרי השימוש ב-GPU, צריך להשבית את השירות לפני שמתקינים את סוכן תפעול. כדי להשבית את סקריפט המעקב, מריצים את הפקודה הבאה:sudo systemctl --no-reload --now disable google_gpu_monitoring_agent
מתקינים את הגרסה האחרונה של סוכן התפעול. הוראות מפורטות זמינות במאמר בנושא התקנת סוכן תפעול.
אחרי שמתקינים את Ops Agent, אם צריך להתקין או לשדרג את מנהלי ההתקנים של ה-GPU באמצעות סקריפטים להתקנה שסופקו על ידי Compute Engine, צריך לעיין בקטע מגבלות.
בדיקת מדדי NVML ב-Compute Engine
אפשר לבדוק את מדדי NVML שסוכן התפעול אוסף ממכונות וירטואליות של Linux ב-Compute Engine בכרטיסיות Observability.
כדי לראות את המדדים של מכונה וירטואלית אחת:
נכנסים לדף VM instances במסוף Google Cloud .
בוחרים מכונה וירטואלית כדי לפתוח את הדף פרטים.
לוחצים על הכרטיסייה Observability כדי להציג מידע על המכונה הווירטואלית.
בוחרים במסנן המהיר GPU.
כדי לראות את המדדים של כמה מכונות וירטואליות:
נכנסים לדף VM instances במסוף Google Cloud .
לוחצים על הכרטיסייה Observability (יכולת תצפית).
בוחרים במסנן המהיר GPU.
אופציונלי: הגדרת שילוב של NVIDIA Data Center GPU Manager (DCGM)
בנוסף, סוכן תפעול מספק שילוב עם NVIDIA Data Center GPU Manager (DCGM) כדי לאסוף מדדי GPU מתקדמים מרכזיים, כמו ניצול בלוקים של Streaming Multiprocessor (SM), תפוסת SM, ניצול צינורות SM, קצב תנועה ב-PCIe וקצב תנועה ב-NVLink.
מדדי ה-GPU המתקדמים האלה לא נאספים ממודלים של NVIDIA P100 ו-P4.
הוראות מפורטות להגדרה ולשימוש בשילוב הזה בכל מכונה וירטואלית זמינות במאמר בנושא NVIDIA Data Center GPU Manager (DCGM).
בדיקת מדדי DCGM ב-Cloud Monitoring
במסוף Google Cloud , נכנסים לדף Monitoring > Dashboards.
בוחרים בכרטיסייה ספריית דוגמאות.
בשדה Filter, מקלידים NVIDIA. מוצג לוח הבקרה NVIDIA GPU Monitoring Overview (GCE and GKE).
אם הגדרתם את השילוב של NVIDIA Data Center GPU Manager (DCGM), יוצג גם לוח הבקרה NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only).
לוחצים על תצוגה מקדימה של לוח הבקרה הרצוי. מוצג הדף תצוגה מקדימה של מרכז בקרה לדוגמה.
בדף Sample dashboard preview (תצוגה מקדימה של מרכז בקרה לדוגמה), לוחצים על Import sample dashboard (ייבוא מרכז בקרה לדוגמה).
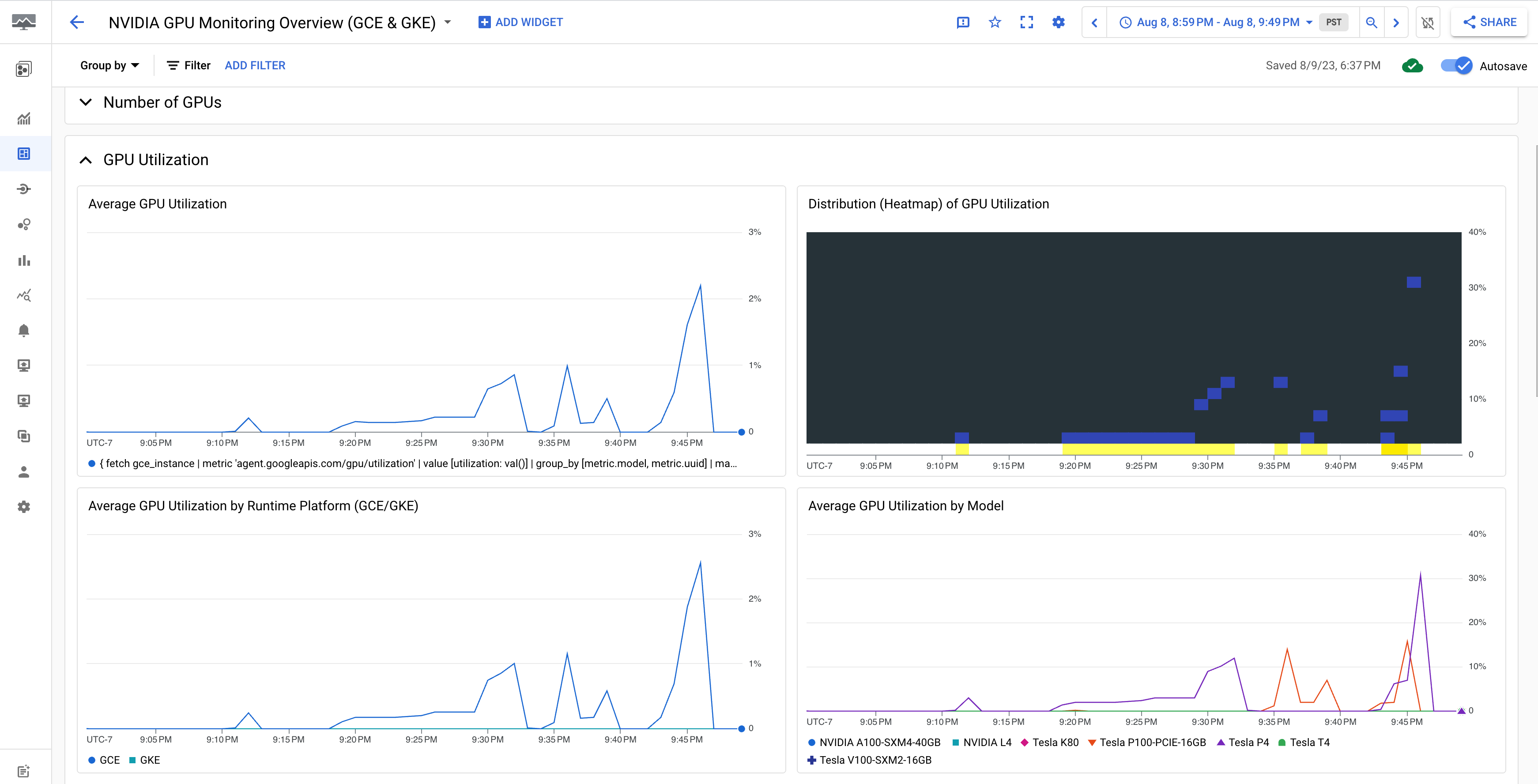
בלוח הבקרה NVIDIA GPU Monitoring Overview (GCE and GKE) מוצגים מדדי ה-GPU, כמו ניצול ה-GPU, קצב התנועה של NIC ושימוש בזיכרון ה-GPU.
תצוגת השימוש ב-GPU דומה לפלט הבא:
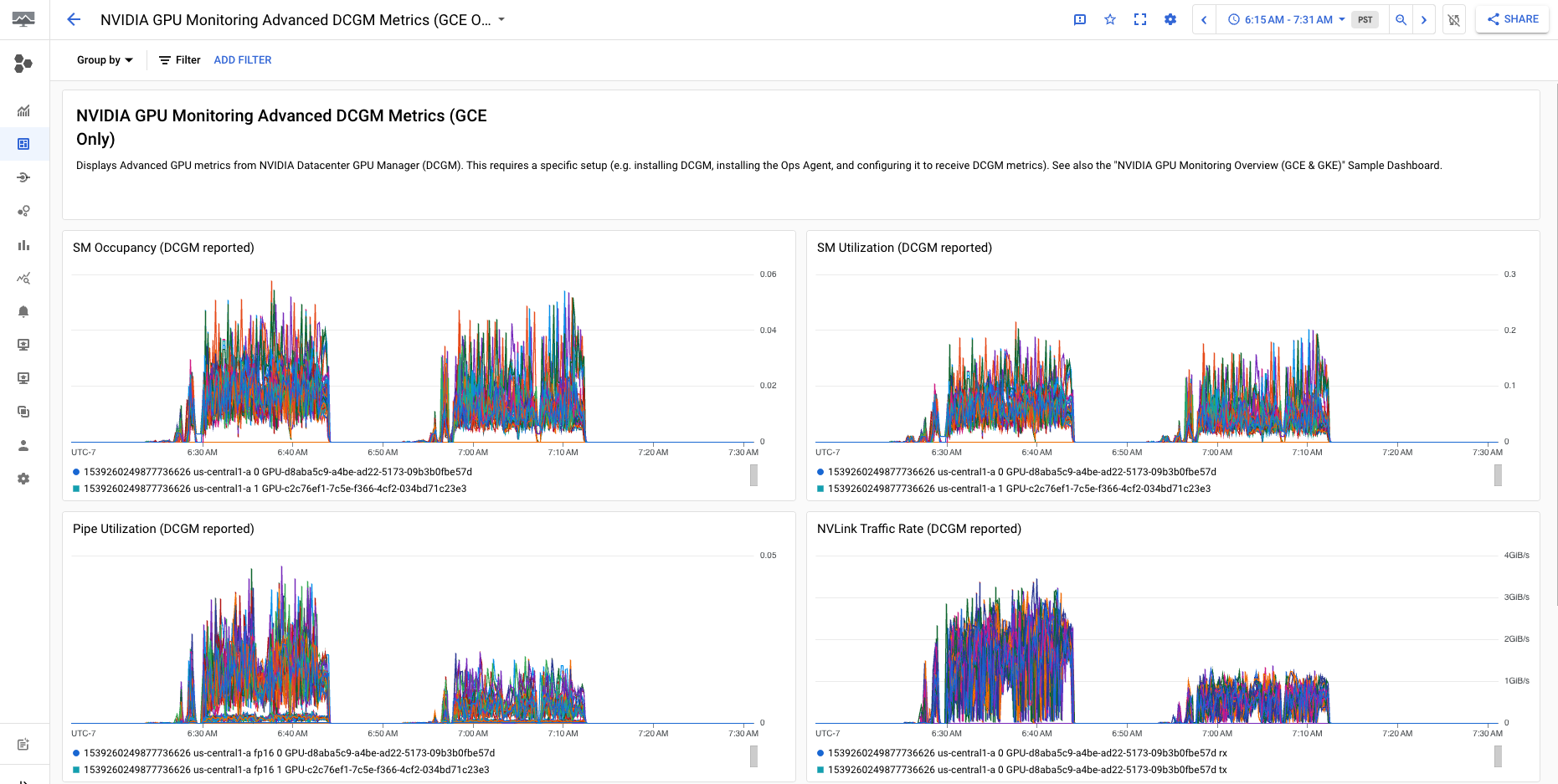
בלוח הבקרה NVIDIA GPU Monitoring Advanced DCGM Metrics (GCE Only) מוצגים מדדים מתקדמים מרכזיים כמו ניצול SM, תפוסת SM, ניצול צינור SM, קצב תנועה ב-PCIe וקצב תנועה ב-NVLink.
התצוגה של מדדי DCGM מתקדמים אמורה להיראות כך:
מה השלב הבא?
- במאמר טיפול באירועי תחזוקה של מארחי GPU מוסבר איך לטפל בתחזוקה של מארחי GPU.
- כדי לשפר את ביצועי הרשת, אפשר לקרוא את המאמר בנושא שימוש ברוחב פס רשת גבוה יותר.