
本文說明附加 GPU 的 Compute Engine 執行個體網路頻寬功能和設定。瞭解各種 GPU 機型的最大網路頻寬、網路介面卡 (NIC) 配置,以及建議的 VPC 網路設定,包括 A4X Max、A4X、A4、A3、A2、G4、G2 和 N1 系列。瞭解這些設定有助於在 Compute Engine 上,為分散式工作負載最佳化效能。
總覽
下表大致比較各 GPU 機器類型的網路功能。
| 機型 | GPU 模型 | 總頻寬上限 | GPU 對 GPU 網路技術 |
|---|---|---|---|
| A4X Max | NVIDIA GB300 Ultra Superchips | 3,600 Gbps | GPUDirect RDMA |
| A4X | NVIDIA GB200 超級晶片 | 2,000 Gbps | GPUDirect RDMA |
| A4 | NVIDIA B200 | 3,600 Gbps | GPUDirect RDMA |
| A3 Ultra | NVIDIA H200 | 3,600 Gbps | GPUDirect RDMA |
| A3 Mega | NVIDIA H100 80GB | 1,800 Gbps | GPUDirect-TCPXO |
| A3 High | NVIDIA H100 80GB | 1,000 Gbps | GPUDirect-TCPX |
| A3 Edge | NVIDIA H100 80GB | 600 Gbps | GPUDirect-TCPX |
| G4 | NVIDIA RTX PRO 6000 | 400 Gbps | 不適用 |
| A2 Standard 和 A2 Ultra | NVIDIA A100 40GB、NVIDIA A100 80GB | 100 Gbps | 不適用 |
| G2 | NVIDIA L4 | 100 Gbps | 不適用 |
| N1 | NVIDIA T4、NVIDIA V100 | 100 Gbps | 不適用 |
| N1 | NVIDIA P100、NVIDIA P4 | 32 Gbps | 不適用 |
GPUDirect RDMA 和 MRDMA 函式
在特定加速器最佳化機型上, Google Cloud 會使用 MRDMA 做為 GPU 對 GPU 網路的網路介面實作項目,支援 GPUDirect RDMA。
GPUDirect RDMA 是 NVIDIA 技術,可讓網路介面卡 (NIC) 透過 PCIe 直接存取 GPU 記憶體,略過主機 CPU 和系統記憶體。網路卡與 GPU 之間的點對點通訊可大幅減少節點間 GPU 對 GPU 通訊的延遲時間。
MRDMA 是 A4X Max、A4X、A4 和 A3 Ultra 機型使用的網路介面實作項目,可提供 GPUDirect RDMA 功能。MRDMA 以 NVIDIA ConnectX NIC 為基礎,可透過下列任一方式部署:
- MRDMA 虛擬函式 (VF):用於 A3 Ultra、A4 和 A4X 系列。
- MRDMA 實體函式 (PF):用於 A4X Max 系列。
MRDMA 函式和網路監控工具
A4X、A4 和 A3 Ultra 機型會使用 MRDMA 虛擬函式 (VF),實作高效能的 GPU 對 GPU 網路。由於這些是虛擬化實體,與實體功能 (PF) 相比,某些硬體層級的監控功能會受到限制。
使用 MRDMA VF 時,標準實體連接埠計數器 (例如結尾為 _phy 的計數器) 會出現在 ethtool -S 輸出內容中,但不會在網路活動期間更新。這是 MRDMA VF 架構的特點。如要準確追蹤這些介面的網路效能,請查看 vPort 計數器表的項目,而非實體連接埠計數器表。
A4X Max 機型使用 MRDMA PF。與 MRDMA VF 型機器類型不同,A4X Max 支援 GPU 網路的完整實體連接埠計數器。
查看 GPU 機型的網路概念
請參閱下節,瞭解各 GPU 機器類型的網路配置和頻寬速度。
A4X Max 和 A4X 機型
A4X Max 和 A4X 系列機器均採用 NVIDIA Blackwell 架構,專為資源需求龐大的大規模分散式 AI 工作負載而設計。兩者的主要差異在於所連結的加速器和網路硬體,如下表所示:
| A4X Max 機器系列 | A4X 系列機型 | |
|---|---|---|
| 附加硬體 | NVIDIA GB300 Ultra Superchips | NVIDIA GB200 超級晶片 |
| GPU 對 GPU 網路 | 4 個 NVIDIA ConnectX-8 (CX-8) SuperNIC,在 8 向軌道對齊拓撲中提供 3,200 Gbps 頻寬 | 4 個 NVIDIA ConnectX-7 (CX-7) NIC,可在 4 向軌道對齊拓撲中提供 1,600 Gbps 頻寬 |
| GPU 對 GPU 網路實作 | 8 個 MRDMA 實體函式 (PF),每個 NIC 設為 2 個 PF | 4 個 MRDMA 虛擬函式 (VF),每個 NIC 設定 1 個 VF |
| 一般用途網路 | 2 個 Titanium 智慧型 NIC,提供 400 Gbps 頻寬 | 2 個 Titanium 智慧型 NIC,提供 400 Gbps 頻寬 |
| 網路頻寬總上限 | 3,600 Gbps | 2,000 Gbps |
多層式網路架構
A4X Max 和 A4X 運算執行個體採用多層式階層網路架構,並以符合軌道 (rail-aligned) 的設計,針對各種通訊類型最佳化效能。在這個拓撲中,執行個體會透過多個獨立網路平面 (稱為「軌道」) 連線。
- A4X Max 執行個體採用 8 向軌道對齊拓撲,其中四個 800 Gbps ConnectX-8 NIC 各自連接至兩個獨立的 400 Gbps 軌道。
- A4X 執行個體使用 4 向軌道對齊拓撲,其中四個 ConnectX-7 NIC 各自連線至不同的軌道。
這些機型的網路層如下:
節點內和子區塊內通訊 (NVLink):高速 NVLink 架構互連 GPU,可實現高頻寬、低延遲的通訊。這個架構會連結單一執行個體中的所有 GPU,並延伸至子區塊 (由 18 個 A4X Max 或 A4X 執行個體組成,總共 72 個 GPU)。這樣一來,子區塊中的所有 72 個 GPU 就能相互通訊, 就像位於單一的大型 GPU 伺服器中一樣。
子模塊間通訊 (採用 RoCE 的 ConnectX NIC):如要將工作負載擴展到單一子模塊以外,這些機器會使用 NVIDIA ConnectX NIC。這些 NIC 會使用基於融合乙太網路的 RDMA (RoCE),在子模塊之間提供高頻寬、低延遲的通訊,讓您建構數千個 GPU 的大規模訓練叢集。
一般用途網路 (Titanium 智慧型 NIC):除了專用 GPU 網路,每個執行個體都有兩個 Titanium 智慧型 NIC,可提供 400 Gbps 的總頻寬,用於一般網路工作。包括儲存、管理及連線至其他服務或公用網際網路的流量。 Google Cloud
A4X Max 架構
A4X Max 架構以 NVIDIA GB300 Ultra Superchip 為基礎建構而成。這項設計的主要特色是將四個 800 Gbps 的 NVIDIA ConnectX-8 (CX-8) SuperNIC 直接連線至 GPU。每個 ConnectX-8 都是雙連接埠 NIC,會以兩個實體函式 (PF) 的形式公開給執行個體。這些 NIC 屬於 8 向軌道對齊網路拓撲,每個 NIC 都會連線至兩個獨立的 400 Gbps 軌道。這條直接路徑可啟用 RDMA,為不同子模塊之間的 GPU 對 GPU 通訊提供高頻寬和低延遲。這些 Compute Engine 執行個體也包含附加至 ConnectX-8 NIC 的高效能本機 SSD,可略過 PCIe 匯流排,加快資料存取速度。
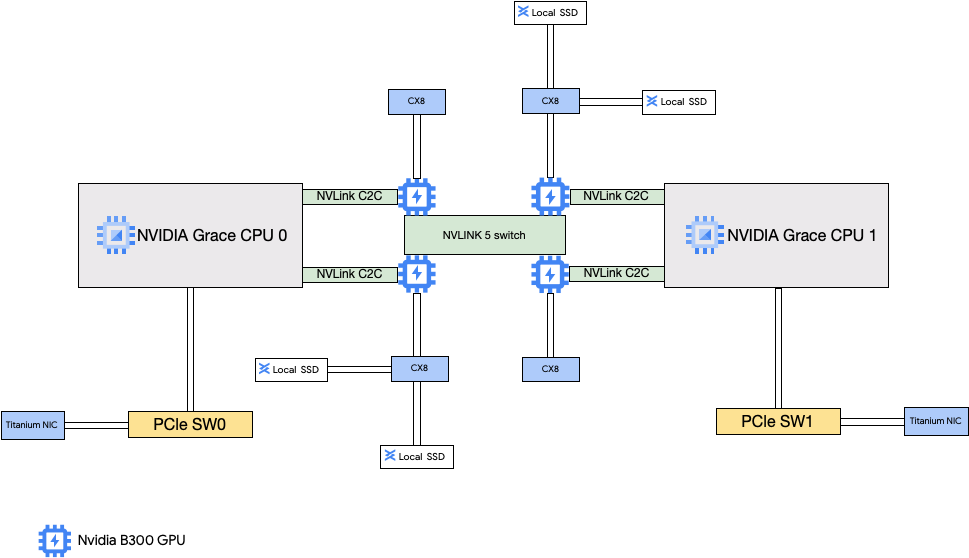
A4X 架構
A4X 架構採用 NVIDIA GB200 Superchip。在這個設定中,四個 NVIDIA ConnectX-7 (CX-7) NIC 會連線至主機 CPU。這個設定可為子區塊之間的 GPU 對 GPU 通訊提供高效能網路。
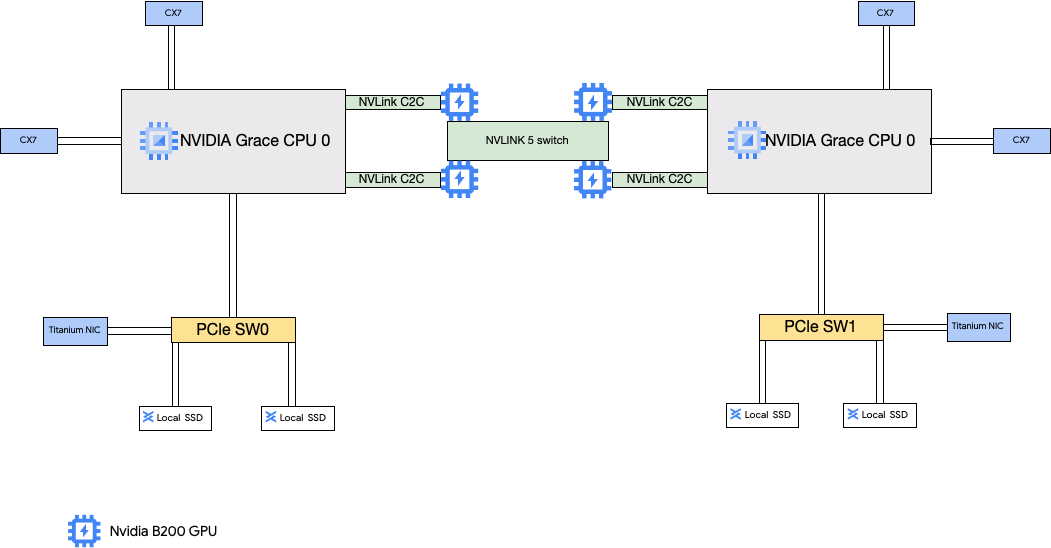
A4X Max 和 A4X 虛擬私有雲 (VPC) 網路設定
如要充分運用這些機型的網路功能,您需要建立虛擬私有雲網路,並將其附加至執行個體。如要使用所有可用的 NIC,請按照下列方式建立 VPC 網路:
Titanium Smart NIC 的兩個一般 VPC 網路。
- 對於 A4X Max,這些虛擬私有雲網路使用 Intel IDPF LAN PF 裝置驅動程式。
- 對於 A4X,這些 VPC 網路會使用 Google 虛擬 NIC (gVNIC) 網路介面。
建立多個 A4X Max 或 A4X 子區塊的叢集時,ConnectX NIC 必須使用具有 RoCE 網路設定檔的虛擬私有雲網路。RoCE 虛擬私有雲網路必須為每個網路軌道提供一個子網路。也就是說,A4X Max 執行個體有八個子網路,A4X 執行個體則有四個子網路。如果您使用單一子區塊,可以省略這個 VPC 網路,因為多節點 NVLink 網狀架構會處理 GPU 對 GPU 的直接通訊。
如要設定這些網路,請參閱 AI Hypercomputer 說明文件中的「建立虛擬私有雲網路」。
A4X Max 和 A4X 機型
A4X Max
| 已連結 NVIDIA GB300 Grace Blackwell Ultra Superchip | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3e) |
a4x-maxgpu-4g-metal |
144 | 960 | 12,000 | 6 | 3,600 | 4 | 1,116 |
A4X
| 已連結 NVIDIA GB200 Grace Blackwell 超級晶片 | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12,000 | 6 | 2,000 | 4 | 744 |
A4 和 A3 Ultra 機型
A4 機型連接的是 NVIDIA B200 GPU,A3 Ultra 機型連接的則是 NVIDIA H200 GPU。
這些機器類型提供八個 NVIDIA ConnectX-7 (CX-7) 網路介面卡 (NIC) 和兩個 Google 虛擬 NIC (gVNIC)。這八個 CX-7 NIC 可提供 3,200 Gbps 的網路總頻寬。這些 NIC 專門用於高頻寬 GPU 對 GPU 通訊,無法用於其他網路需求,例如存取公開網際網路。如下圖所示,每個 CX-7 NIC 都會對應到一個 GPU,以最佳化非一致性記憶體存取 (NUMA)。八個 GPU 均能透過全面 NVLink 橋接器與彼此快速通訊,另外兩個 gVNIC 網路介面卡是智慧型 NIC,可提供額外 400 Gbps 的網路頻寬,滿足一般用途網路需求。這些網路介面卡加總後,可為這些機器提供 3,600 Gbps 的網路頻寬上限。
A4 和 A3 Ultra 執行個體上的高效能 GPU 對 GPU 網路,是透過八個 ConnectX-7 NIC 的每個 MRDMA 虛擬函式 (VF) 實作。
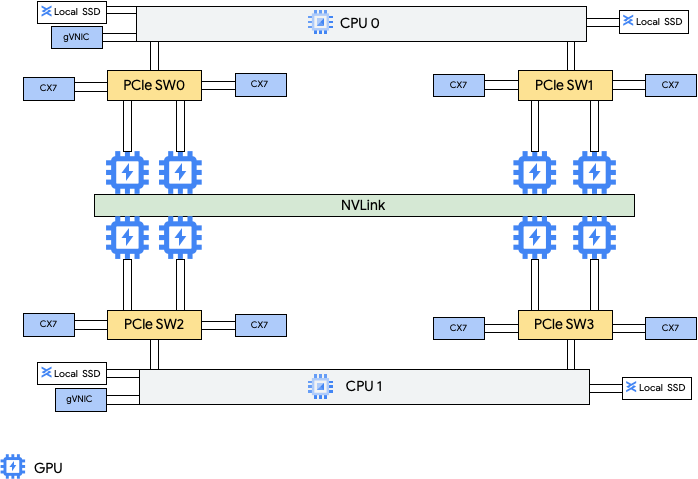
如要使用這些多重 NIC,您需要建立 3 個虛擬私有雲網路,如下所示:
- 兩個一般虛擬私有雲網路:每個 gVNIC 都必須連接至不同的虛擬私有雲網路
- 一個 RoCE VPC 網路:所有八個 CX-7 NIC 共用同一個 RoCE VPC 網路
如要設定這些網路,請參閱 AI Hypercomputer 說明文件中的「建立虛擬私有雲網路」。
A4
| 已連結的 NVIDIA B200 Blackwell GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3,968 | 12,000 | 10 | 3,600 | 8 | 1,440 |
A3 Ultra
| 已附加的 NVIDIA H200 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2,952 | 12,000 | 10 | 3,600 | 8 | 1128 |
A3 Mega、High 和 Edge 機型
這類機型連接 H100 GPU。這些機型都配備固定數量的 GPU、vCPU 和記憶體。
- 單一 NIC A3 VM:如為附加 1 到 4 個 GPU 的 A3 VM,則只有單一實體網路介面卡 (NIC) 可用。
- 多 NIC A3 VM:如果 A3 VM 附加 8 個 GPU,則可使用多個實體 NIC。在周邊元件互連高速 (PCIe) 匯流排上,這些 A3 機型的 NIC 排列方式如下:
- A3 Mega 機型:提供 8+1 的 NIC 配置。採用這種配置時,8 個 NIC 會共用同一個 PCIe 匯流排,而 1 個 NIC 則位於不同的 PCIe 匯流排上。
- A3 High 機型:提供 4+1 的 NIC 配置。 這樣一來,4 個 NIC 會共用同一個 PCIe 匯流排,1 個 NIC 則位於另一個 PCIe 匯流排。
- A3 Edge 機型:可使用 4+1 的 NIC 配置。 這樣一來,4 個 NIC 會共用同一個 PCIe 匯流排,1 個 NIC 則位於另一個 PCIe 匯流排上。 這 5 個 NIC 可為每個 VM 提供 400 Gbps 的網路總頻寬。
共用相同 PCIe 匯流排的 NIC,每兩個 NVIDIA H100 GPU 都有一個 NIC 的非統一記憶體存取 (NUMA) 對齊。這些 NIC 非常適合專用的高頻寬 GPU 對 GPU 通訊。位於獨立 PCIe 匯流排上的實體 NIC 非常適合其他網路需求。如要瞭解如何為 A3 High 和 A3 Edge VM 設定網路,請參閱設定巨型封包 MTU 網路。
A3 Mega
| 附加的 NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3) |
a3-megagpu-8g |
208 | 1,872 | 6,000 | 9 | 1,800 | 8 | 640 |
A3 High
| 附加的 NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1,500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3,000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1,872 | 6,000 | 5 | 1,000 | 8 | 640 |
A3 Edge
| 附加的 NVIDIA H100 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 實體 NIC 數量 | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1,872 | 6,000 | 5 |
|
8 | 640 |
1 在其中一個可用的 CPU 平台中,我們會以單一硬體超執行緒的形式提供 vCPU。
2輸出頻寬上限不得超過指定數量。實際輸出頻寬取決於目的地 IP 位址和其他因素。如要進一步瞭解網路頻寬,請參閱「網路頻寬」。
3GPU 記憶體是 GPU 裝置上的記憶體,可用於暫時儲存資料。這與執行個體的記憶體不同,專門用於處理需要高頻寬的繪圖密集型工作負載。
A2 機型
每個 A2 機型都配備固定數量的 NVIDIA A100 40GB 或 NVIDIA A100 80 GB GPU。每個機型也都有固定的 vCPU 數量和記憶體大小。
A2 系列機器分為兩種:
- A2 Ultra:這類機型連接 A100 80GB GPU 和本機 SSD 磁碟。
- A2 Standard:這類機型連接 A100 40GB GPU。
A2 Ultra
| 連接 NVIDIA A100 80GB GPU | ||||||
|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 附加的本機 SSD (GiB) | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1,500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1,360 | 3,000 | 100 | 8 | 640 |
A2 Standard
| 已連結 NVIDIA A100 40GB GPU | ||||||
|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 支援本機 SSD | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | 是 | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | 是 | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | 是 | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | 是 | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1,360 | 是 | 100 | 16 | 640 |
1 在其中一個可用的 CPU 平台中,我們會以單一硬體超執行緒的形式提供 vCPU。
2輸出頻寬上限不得超過指定數量。實際輸出頻寬取決於目的地 IP 位址和其他因素。如要進一步瞭解網路頻寬,請參閱「網路頻寬」。
3GPU 記憶體是 GPU 裝置上的記憶體,可用於暫時儲存資料。這與執行個體的記憶體不同,專門用於處理需要高頻寬的繪圖密集型工作負載。
G4 機型
G4 加速器最佳化
機型使用
NVIDIA RTX PRO 6000 Blackwell Server Edition GPU (nvidia-rtx-pro-6000),
適用於 NVIDIA Omniverse 模擬工作負載、需要大量圖形處理的應用程式、影片轉碼和虛擬桌面。與 A 系列機型相比,G4 機型也提供低成本解決方案,可執行單一主機推論和模型微調。
| 已連結的 NVIDIA RTX PRO 6000 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 執行個體記憶體 (GB) | 支援的 Titanium SSD 容量上限 (GiB)2 | 實體 NIC 數量 | 網路頻寬上限 (Gbps)3 | GPU 數量 | GPU 記憶體4 (GB GDDR7) |
g4-standard-6 |
6 | 22 | 0 | 1 | 20 | 1/8 | 12 |
g4-standard-12 |
12 | 45 | 375 | 1 | 20 | 1/4 | 24 |
g4-standard-24 |
24 | 90 | 750 | 1 | 20 | 1/2 | 48 |
g4-standard-48 |
48 | 180 | 1,500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3,000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6,000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1,440 | 12,000 | 2 | 400 | 8 | 768 |
1 在其中一個可用的 CPU 平台中,我們會以單一硬體超執行緒的形式提供 vCPU。
2建立 G4 執行個體時,您可以新增 Titanium SSD 磁碟。如要瞭解可附加的磁碟數量,請參閱必須選擇本機 SSD 磁碟數量的機器類型。
3輸出頻寬上限不得超過指定數量。實際輸出頻寬取決於目的地 IP 位址和其他因素。請參閱「網路頻寬」。
4GPU 記憶體是 GPU 裝置上的記憶體,可用於暫時儲存資料。這與執行個體的記憶體不同,專門用於處理需要高頻寬的繪圖密集型工作負載。
G2 機型
G2 加速器最佳化機型連接的是 NVIDIA L4 GPU,非常適合用於成本最佳化的推論、需要處理大量圖形,以及高效能運算工作負載。
每個 G2 機型也都有預設記憶體和自訂記憶體範圍。自訂記憶體範圍會定義每個機器類型可分配給執行個體的記憶體大小。您也可以在建立 G2 執行個體時新增本機 SSD 磁碟。如要瞭解可附加的磁碟數量,請參閱必須選擇本機 SSD 磁碟數量的機器類型。
如要為大多數 GPU 執行個體套用較高的網路頻寬速率 (50 Gbps 以上),建議使用 Google 虛擬 NIC (gVNIC)。如要進一步瞭解如何建立使用 gVNIC 的 GPU 執行個體,請參閱建立使用較高頻寬的 GPU 執行個體。
| 附加的 NVIDIA L4 GPU | |||||||
|---|---|---|---|---|---|---|---|
| 機型 | vCPU 數量1 | 預設執行個體記憶體 (GB) | 自訂執行個體記憶體範圍 (GB) | 支援的最大本機 SSD (GiB) | 網路頻寬上限 (Gbps)2 | GPU 數量 | GPU 記憶體3 (GB GDDR6) |
g2-standard-4 |
4 | 16 | 16 至 32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32 至 54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48 到 54 歲 | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54 到 64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96 至 108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96 到 128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192 至 216 | 1,500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384 至 432 | 3,000 | 100 | 8 | 192 |
1 在其中一個可用的 CPU 平台中,我們會以單一硬體超執行緒的形式提供 vCPU。
2輸出頻寬上限不得超過指定數量。實際輸出頻寬取決於目的地 IP 位址和其他因素。如要進一步瞭解網路頻寬,請參閱「網路頻寬」。
3GPU 記憶體是 GPU 裝置上的記憶體,可用於暫時儲存資料。這與執行個體的記憶體不同,專門用於處理需要高頻寬的繪圖密集型工作負載。
N1 + GPU 機型
如果 N1 一般用途虛擬機器 (VM) 執行個體附加 T4 和 V100 GPU,則網路頻寬上限最高可達 100 Gbps,實際頻寬取決於 GPU 和 vCPU 的組合。如要瞭解其他 N1 GPU 執行個體,請參閱「總覽」。
請參閱下節,根據 GPU 型號、vCPU 和 GPU 數量,計算 T4 和 V100 執行個體可用的網路頻寬上限。
少於 5 個 vCPU
如果 T4 和 V100 執行個體的 vCPU 數量為 5 個以下,則網路頻寬上限為 10 Gbps。
超過 5 個 vCPU
如果 T4 和 V100 執行個體的 vCPU 數量超過 5 個,系統會根據該 VM 的 vCPU 和 GPU 數量,計算網路頻寬上限。
如要為大多數 GPU 執行個體套用較高的網路頻寬速率 (50 Gbps 以上),建議使用 Google 虛擬 NIC (gVNIC)。如要進一步瞭解如何建立使用 gVNIC 的 GPU 執行個體,請參閱建立使用較高頻寬的 GPU 執行個體。
| GPU 模型 | GPU 數量 | 計算最大網路頻寬 |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
MTU 設定和 GPU 機型
如要提高網路總處理量,請為虛擬私有雲網路設定較高的最大傳輸單位 (MTU) 值。MTU 值越高,封包大小就越大,封包標頭的負擔也會減少,進而提高酬載資料的總處理量。
如果是 GPU 機型,建議您為虛擬私有雲網路採用下列 MTU 設定。
| GPU 機器類型 | 建議的 MTU (以位元組為單位) | |
|---|---|---|
| 一般虛擬私有雲網路 | RoCE 虛擬私有雲網路 | |
|
8896 | 8896 |
|
8244 | 不適用 |
|
8896 | 不適用 |
設定 MTU 值時,請注意下列事項:
- 8192 是兩個 4 KB 頁面。
- 如果 GPU NIC 已啟用標頭分割功能,建議在 A3 Mega、A3 High 和 A3 Edge VM 中使用 8244。
- 除非表格另有註明,否則請使用 8896 這個值。
建立高頻寬 GPU 機器
如要建立使用較高網路頻寬的 GPU 執行個體,請根據機型使用下列其中一種方法:
如要建立使用更高網路頻寬的 A2、G2 和 N1 執行個體,請參閱「為 A2、G2 和 N1 執行個體使用更高網路頻寬」。如要測試或驗證這些機器的頻寬速度,可以使用基準測試。詳情請參閱「檢查網路頻寬」。
如要建立使用較高網路頻寬的 A3 Mega 執行個體,請參閱「部署 A3 Mega Slurm 叢集以進行 ML 訓練」。如要測試或驗證這些機器的頻寬速度,請按照「檢查網路頻寬」一文中的步驟進行基準測試。
如要瞭解如何為使用較高網路頻寬的 A3 High 和 A3 Edge 執行個體啟用 GPUDirect-TCPX,請參閱這篇文章。如要測試或驗證這些機器的頻寬速度,可以使用基準測試。詳情請參閱「檢查網路頻寬」。
如果是其他加速器最佳化機型,您不需要採取任何行動,即可使用較高的網路頻寬;按照文件建立執行個體時,系統會使用高網路頻寬。如要瞭解如何為其他加速器最佳化機型建立執行個體,請參閱「建立附加 GPU 的 VM」。
後續步驟
- 進一步瞭解 GPU 平台。
- 瞭解如何建立附加 GPU 的執行個體。
- 瞭解如何使用較高的網路頻寬。
- 瞭解 GPU 定價。