
In diesem Dokument werden die Netzwerkbandbreitenfunktionen und ‑konfigurationen für Compute Engine-Instanzen mit angehängten GPUs beschrieben. Hier finden Sie Informationen zur maximalen Netzwerkbandbreite, zu NIC-Konfigurationen (Network Interface Card) und zu empfohlenen VPC-Netzwerkeinrichtungen für verschiedene GPU-Maschinentypen, einschließlich der Serien A4X Max, A4X, A4, A3, A2, G4, G2 und N1. Wenn Sie diese Konfigurationen kennen, können Sie die Leistung Ihrer verteilten Arbeitslasten in Compute Engine optimieren.
Übersicht
In der folgenden Tabelle finden Sie einen allgemeinen Vergleich der Netzwerkfunktionen für verschiedene GPU-Maschinentypen.
| Maschinentyp | GPU-Modell | Maximale Gesamtbandbreite | GPU-zu-GPU-Netzwerktechnologie |
|---|---|---|---|
| A4X Max | NVIDIA GB300 Ultra-Superchips | 3.600 Gbit/s | GPUDirect RDMA |
| A4X | NVIDIA GB200-Superchips | 2.000 Gbit/s | GPUDirect RDMA |
| A4 | NVIDIA B200 | 3.600 Gbit/s | GPUDirect RDMA |
| A3 Ultra | NVIDIA H200 | 3.600 Gbit/s | GPUDirect RDMA |
| A3 Mega | NVIDIA H100 80 GB | 1.800 Gbit/s | GPUDirect-TCPXO |
| A3 High | NVIDIA H100 80 GB | 1,000 Gbit/s | GPUDirect-TCPX |
| A3 Edge | NVIDIA H100 80 GB | 600 Gbit/s | GPUDirect-TCPX |
| G4 | NVIDIA RTX Pro 6000 | 400 Gbit/s | – |
| A2-Standard und A2-Ultra | NVIDIA A100 40 GB, NVIDIA A100 80 GB | 100 Gbit/s | – |
| G2 | NVIDIA L4 | 100 Gbit/s | – |
| N1 | NVIDIA T4, NVIDIA V100 | 100 Gbit/s | – |
| N1 | NVIDIA P100, NVIDIA P4 | 32 Gbit/s | – |
GPUDirect RDMA- und MRDMA-Funktionen
Bei bestimmten beschleunigungsoptimierten Maschinentypen verwendet Google Cloud MRDMA als Netzwerkschnittstellenimplementierung für die GPU-zu-GPU-Vernetzung,die GPUDirect RDMA unterstützt.
GPUDirect RDMA ist eine NVIDIA-Technologie, die es einer Netzwerkkarte (NIC) ermöglicht, über PCIe direkt auf den GPU-Speicher zuzugreifen und dabei die Host-CPU und den Systemspeicher zu umgehen. Diese Peer-to-Peer-Kommunikation zwischen NIC und GPU reduziert die Latenz für die GPU-zu-GPU-Kommunikation zwischen Knoten erheblich.
MRDMA ist die Netzwerkschnittstellenimplementierung, die auf den Maschinentypen A4X Max, A4X, A4 und A3 Ultra verwendet wird, um GPUDirect RDMA-Funktionen bereitzustellen. MRDMA basiert auf NVIDIA ConnectX-NICs und wird auf eine der folgenden Arten bereitgestellt:
- MRDMA-VFs (Virtual Functions): werden in den Serien A3 Ultra, A4 und A4X verwendet.
- MRDMA Physical Functions (PFs): werden in der A4X Max-Serie verwendet.
MRDMA-Funktionen und Tools zur Netzwerküberwachung
Die Maschinentypen A4X, A4 und A3 Ultra implementieren Hochleistungs-GPU-zu-GPU-Netzwerke mithilfe von MRDMA-Virtual Functions (VFs). Da es sich um virtualisierte Einheiten handelt, sind bestimmte Überwachungsfunktionen auf Hardwareebene im Vergleich zu physischen Funktionen (Physical Functions, PFs) eingeschränkt.
Bei MRDMA-VFs werden standardmäßige physische Portzähler (z. B. solche, die mit _phy enden) in der ethtool -S-Ausgabe angezeigt, aber während der Netzwerkaktivität nicht aktualisiert. Dies ist ein Merkmal der MRDMA-VF-Architektur. Wenn Sie die Netzwerkleistung auf diesen Schnittstellen genau erfassen möchten, sehen Sie sich die Einträge für die vPort Counter Table anstelle der Physical Port Counter Table an.
Der Maschinentyp „A4X Max“ verwendet MRDMA-PFs. Im Gegensatz zu den MRDMA-Maschinentypen, die auf virtuellen Funktionen basieren, unterstützt A4X Max die gesamte Bandbreite an physischen Portzählern für GPU-Netzwerke.
Netzwerkkonzepte für GPU-Maschinentypen
Im folgenden Abschnitt finden Sie Informationen zur Netzwerkanordnung und Bandbreitengeschwindigkeit für jeden GPU-Maschinentyp.
A4X Max- und A4X-Maschinentypen
Die Maschinenreihen A4X Max und A4X, die beide auf der NVIDIA Blackwell-Architektur basieren, sind für anspruchsvolle, große, verteilte KI-Arbeitslasten konzipiert. Der Hauptunterschied zwischen den beiden besteht in den angehängten Beschleunigern und der Netzwerkhardware, wie in der folgenden Tabelle beschrieben:
| A4X Max-Maschinenserie | A4X-Maschinenserie | |
|---|---|---|
| Angeschlossene Hardware | NVIDIA GB300 Ultra-Superchips | NVIDIA GB200-Superchips |
| GPU-zu-GPU-Netzwerk | 4 NVIDIA ConnectX-8-SuperNICs (CX-8) mit einer Bandbreite von 3.200 Gbit/s in einer 8-Way-Rail-Aligned-Topologie | 4 NVIDIA ConnectX-7-Netzwerkkarten (CX-7) mit einer Bandbreite von 1.600 Gbit/s in einer 4-Way-Rail-Aligned-Topologie |
| Implementierung der GPU-zu-GPU-Vernetzung | 8 MRDMA-Funktionen (Physical Functions, PFs), konfiguriert als 2 PFs pro NIC | 4 MRDMA-VFs (Virtual Functions), die als 1 VF pro NIC konfiguriert sind |
| Allgemeine Netzwerkfunktionen | 2 Titanium Smart-NICs mit einer Bandbreite von 400 Gbit/s | 2 Titanium Smart-NICs mit einer Bandbreite von 400 Gbit/s |
| Maximale Netzwerkbandbreite insgesamt | 3.600 Gbit/s | 2.000 Gbit/s |
Mehrschichtige Netzwerkarchitektur
A4X Max- und A4X-Compute-Instanzen verwenden eine mehrschichtige, hierarchische Netzwerkarchitektur mit einem Rail-Design, um die Leistung für verschiedene Kommunikationstypen zu optimieren. Bei dieser Topologie stellen Instanzen Verbindungen über mehrere unabhängige Netzwerkebenen (Rails) her.
- A4X Max-Instanzen verwenden eine 8-Way-Rail-Aligned-Topologie, in der jede der vier 800‑Gbit/s-ConnectX‑8-NICs mit zwei separaten 400‑Gbit/s-Rails verbunden ist.
- A4X-Instanzen verwenden eine 4-way-Rail-Aligned-Topologie, bei der jede der vier ConnectX-7-NICs mit einem separaten Rail verbunden ist.
Die Netzwerkschichten für diese Maschinentypen sind folgende:
Knoteninterne und Subblock-interne Kommunikation (NVLink): Eine NVLink-Hochgeschwindigkeitsstruktur verbindet GPUs für die Kommunikation mit hoher Bandbreite und niedriger Latenz. Dieses Fabric verbindet alle GPUs innerhalb einer einzelnen Instanz und erstreckt sich über einen Subblock, der aus 18 A4X Max- oder A4X-Instanzen besteht (insgesamt 72 GPUs). So können alle 72 GPUs in einem Subblock so kommunizieren, als wären sie auf einem einzelnen, großen GPU-Server.
Kommunikation zwischen Unterblöcken (ConnectX-NICs mit RoCE): Um Arbeitslasten über einen einzelnen Unterblock hinaus zu skalieren, verwenden diese Maschinen NVIDIA ConnectX-NICs. Diese NICs verwenden RDMA over Converged Ethernet (RoCE), um eine Kommunikation mit hoher Bandbreite und niedriger Latenz zwischen Unterblöcken zu ermöglichen. So können Sie Trainingscluster im großen Maßstab mit Tausenden von GPUs erstellen.
Allgemeine Netzwerkfunktionen (Titanium Smart NICs): Zusätzlich zu den spezialisierten GPU-Netzwerken hat jede Instanz zwei Titanium Smart NICs, die zusammen eine Bandbreite von 400 Gbit/s für allgemeine Netzwerkaufgaben bieten. Dazu gehört auch der Traffic für die Speicherung, Verwaltung und Verbindung mit anderen Google Cloud Diensten oder dem öffentlichen Internet.
A4X Max-Architektur
Die A4X Max-Architektur basiert auf NVIDIA GB300 Ultra-Superchips. Ein wichtiges Merkmal dieses Designs ist die direkte Verbindung der vier 800 Gbit/s-NVIDIA ConnectX-8 (CX-8) SuperNICs mit den GPUs. Jede ConnectX-8-Netzwerkkarte ist eine Dual-Port-Netzwerkkarte, die der Instanz als zwei physische Funktionen (Physical Functions, PFs) zur Verfügung gestellt wird. Diese NICs sind Teil einer 8-fach-Rail-kompatiblen Netzwerktopologie, in der jede NIC mit zwei separaten 400‑Gbit/s-Rails verbunden ist. Dieser direkte Pfad ermöglicht RDMA und bietet so eine hohe Bandbreite und niedrige Latenz für die GPU-zu-GPU-Kommunikation über verschiedene Unterblöcke hinweg. Diese Compute Engine-Instanzen enthalten auch leistungsstarke lokale SSDs, die an die ConnectX-8-NICs angehängt sind und den PCIe-Bus für einen schnelleren Datenzugriff umgehen.
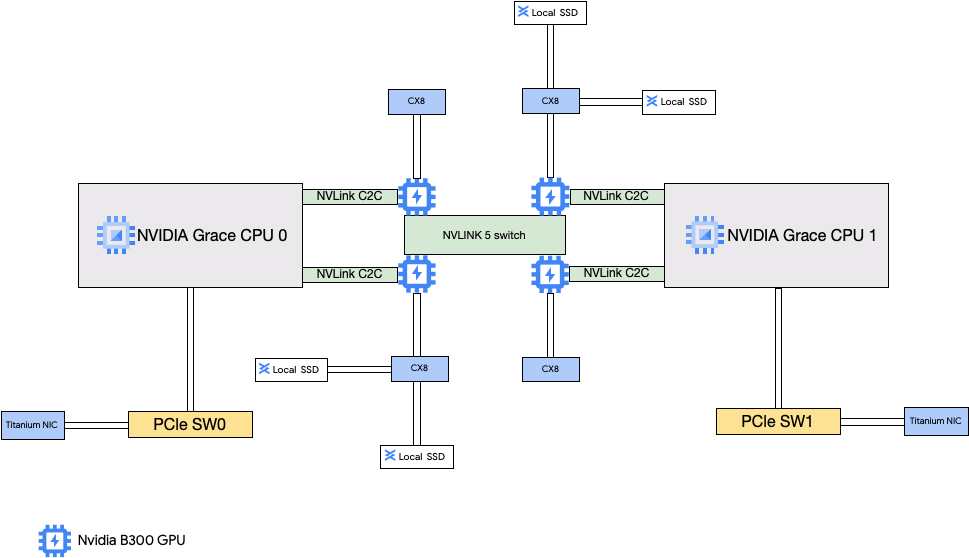
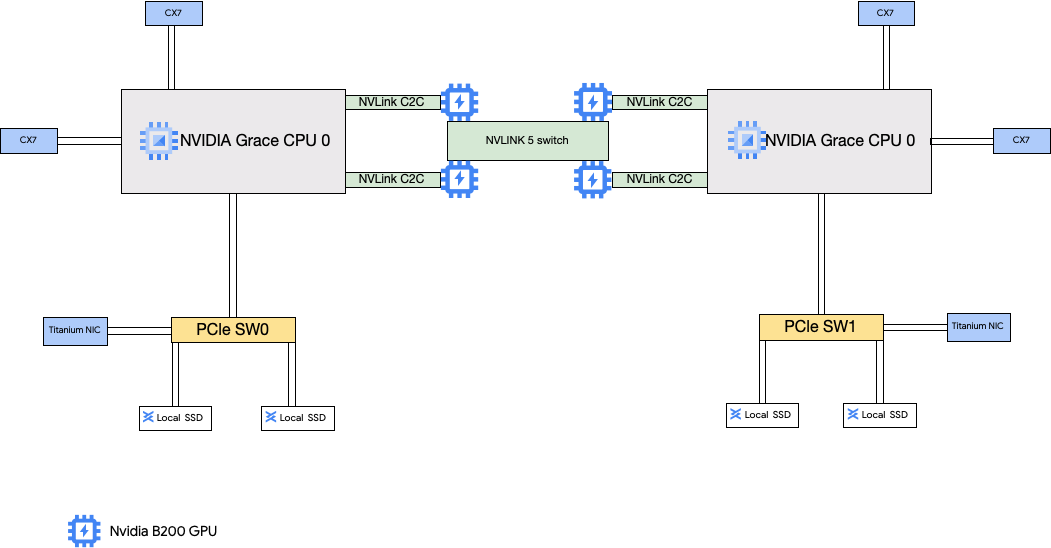
A4X-Architektur
Die A4X-Architektur verwendet NVIDIA GB200-Superchips. In dieser Konfiguration sind die vier NVIDIA ConnectX-7-Netzwerkkarten (CX-7) mit der Host-CPU verbunden. Diese Einrichtung bietet eine leistungsstarke Vernetzung für die GPU-zu-GPU-Kommunikation zwischen Unterblöcken.
A4X Max- und A4X-VPC-Netzwerkkonfiguration (Virtual Private Cloud)
Wenn Sie die vollständigen Netzwerkfunktionen dieser Maschinentypen nutzen möchten, müssen Sie VPC-Netzwerke erstellen und an Ihre Instanzen anhängen. Wenn Sie alle verfügbaren NICs verwenden möchten, müssen Sie VPC-Netzwerke so erstellen:
Zwei reguläre VPC-Netzwerke für die Titanium Smart-NICs.
- Für A4X Max verwenden diese VPC-Netzwerke den Intel IDPF LAN PF-Gerätetreiber.
- Für A4X verwenden diese VPC-Netzwerke die Netzwerkschnittstelle Google Virtual NIC (gVNIC).
Ein VPC-Netzwerk mit dem RoCE-Netzwerkprofil ist für die ConnectX-NICs erforderlich, wenn Sie Cluster mit mehreren A4X Max- oder A4X-Subblöcken erstellen. Das RoCE-VPC-Netzwerk muss für jede Netzwerkschiene ein Subnetz haben. Das bedeutet acht Subnetze für A4X Max-Instanzen und vier Subnetze für A4X-Instanzen. Wenn Sie einen einzelnen Subblock verwenden, können Sie dieses VPC-Netzwerk weglassen, da die direkte GPU-zu-GPU-Kommunikation über das Multi-Node-NVLink-Fabric erfolgt.
Informationen zum Einrichten dieser Netzwerke finden Sie in der AI Hypercomputer-Dokumentation unter VPC-Netzwerke erstellen.
A4X Max- und A4X-Maschinentypen
A4X Max
| Angehängte NVIDIA GB300 Grace Blackwell Ultra-Superchips | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3e) |
a4x-maxgpu-4g-metal |
144 | 960 | 12.000 | 6 | 3.600 | 4 | 1.116 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
A4X
| Angehängte NVIDIA GB200 Grace Blackwell-Superchips | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12.000 | 6 | 2.000 | 4 | 744 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
A4- und A3-Ultra-Maschinentypen
An die A4-Maschinentypen sind NVIDIA B200-GPUs angehängt und an die A3 Ultra-Maschinentypen NVIDIA H200-GPUs.
Diese Maschinentypen bieten acht NVIDIA ConnectX-7-Netzwerkkarten (CX-7) und zwei Google Virtual NICs (gVNIC). Die acht CX-7-Netzwerkkarten bieten eine Netzwerkbandbreite von insgesamt 3.200 Gbit/s. Diese NICs sind ausschließlich für die GPU-zu-GPU-Kommunikation mit hoher Bandbreite vorgesehen und können nicht für andere Netzwerkanforderungen wie den öffentlichen Internetzugriff verwendet werden. Wie im folgenden Diagramm dargestellt, ist jede CX-7-Netzwerkkarte einer GPU zugeordnet, um den uneinheitlichen Arbeitsspeicherzugriff (Non-Uniform Memory Access, NUMA) zu optimieren. Alle acht GPUs können über die NVLink-Bridge, die sie in einer Alle-zu-alle-Topologie miteinander verbindet, schnell miteinander kommunizieren. Die beiden anderen gVNIC-Netzwerkkarten sind intelligente Netzwerkkarten, die eine zusätzliche Netzwerkbandbreite von 400 Gbit/s für allgemeine Netzwerkanforderungen bieten. Zusammen bieten die Netzwerkkarten eine maximale Netzwerkbandbreite von insgesamt 3.600 Gbit/s für diese Maschinen.
Die leistungsstarke GPU-zu-GPU-Vernetzung auf A4- und A3 Ultra-Instanzen wird mithilfe von MRDMA-Virtual Functions (VFs) für jede der acht ConnectX-7-NICs implementiert.
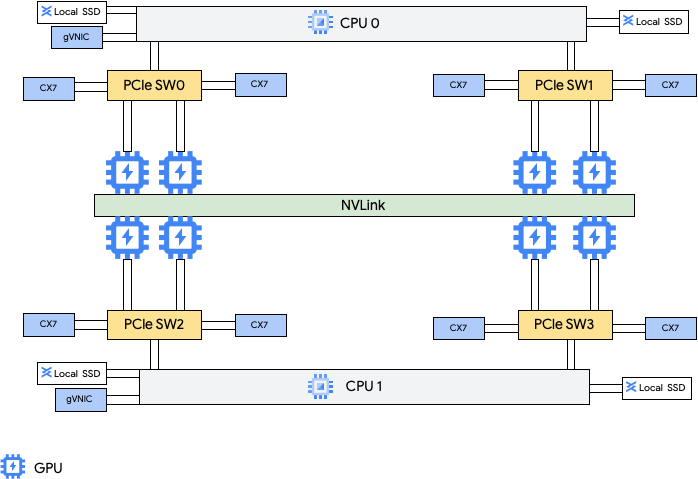
Wenn Sie diese mehreren NICs verwenden möchten, müssen Sie drei VPC-Netzwerke (Virtual Private Cloud) erstellen:
- Zwei reguläre VPC-Netzwerke: Jede gVNIC muss an ein anderes VPC-Netzwerk angehängt werden.
- Ein RoCE-VPC-Netzwerk: Alle acht CX-7-NICs verwenden dasselbe RoCE-VPC-Netzwerk.
Informationen zum Einrichten dieser Netzwerke finden Sie in der AI Hypercomputer-Dokumentation unter VPC-Netzwerke erstellen.
A4
| Angehängte NVIDIA B200 Blackwell-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3.968 | 12.000 | 10 | 3.600 | 8 | 1.440 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
A3 Ultra
| Angehängte NVIDIA H200-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2.952 | 12.000 | 10 | 3.600 | 8 | 1128 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
A3 Mega-, High- und Edge-Maschinentypen
An diese Maschinentypen sind H100-GPUs angehängt. Jeder dieser Maschinentypen hat eine feste GPU-Anzahl, eine Anzahl von vCPUs und eine vorgegebene Speichergröße.
- A3-VMs mit einer einzelnen NIC: Für A3-VMs mit 1 bis 4 angehängten GPUs ist nur eine einzelne physische Netzwerkkarte (NIC) verfügbar.
- A3-VMs mit mehreren NICs: Für A3-VMs mit 8 angehängten GPUs sind mehrere physische NICs verfügbar. Bei diesen A3-Maschinentypen sind die NICs auf einem Peripheral Component Interconnect Express-Bus (PCIe) so angeordnet:
- Für den Maschinentyp „A3 Mega“ ist eine NIC-Anordnung von 8+1 verfügbar. Bei dieser Anordnung teilen sich 8 NICs denselben PCIe-Bus und 1 NIC befindet sich auf einem separaten PCIe-Bus.
- Für den Maschinentyp „A3 High“ ist eine NIC-Anordnung von 4+1 verfügbar. Bei dieser Anordnung teilen sich 4 NICs denselben PCIe-Bus und eine NIC befindet sich auf einem separaten PCIe-Bus.
- Für den Maschinentyp „A3 Edge“ ist eine NIC-Anordnung von 4+1 verfügbar. Bei dieser Anordnung teilen sich 4 NICs denselben PCIe-Bus und eine NIC befindet sich auf einem separaten PCIe-Bus. Diese fünf NICs bieten eine Netzwerkbandbreite von insgesamt 400 Gbit/s für jede VM.
NICs, die denselben PCIe-Bus verwenden, haben eine uneinheitliche Ausrichtung des Arbeitsspeicherzugriffs (NUMA) von einer NIC pro zwei NVIDIA H100-GPUs. Diese NICs sind ideal für die dedizierte GPU-zu-GPU-Kommunikation mit hoher Bandbreite. Die physische NIC, die sich auf einem separaten PCIe-Bus befindet, ist ideal für andere Netzwerkanforderungen. Eine Anleitung zum Einrichten von Netzwerken für A3 High- und A3 Edge-VMs finden Sie unter MTU-Netzwerke im Jumbo Frame einrichten.
A3 Mega
| Angehängte NVIDIA H100-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3) |
a3-megagpu-8g |
208 | 1.872 | 6.000 | 9 | 1.800 | 8 | 640 |
A3 High
| Angehängte NVIDIA H100-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1.500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3.000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1.872 | 6.000 | 5 | 1.000 | 8 | 640 |
A3 Edge
| Angehängte NVIDIA H100-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1.872 | 6.000 | 5 |
|
8 | 640 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
A2-Maschinentypen
Jeder A2-Maschinentyp hat eine feste Anzahl von angehängten NVIDIA A100-GPUs mit 40 GB oder NVIDIA A100-GPUs mit 80 GB. Jeder Maschinentyp hat außerdem eine feste Anzahl an vCPUs und eine feste Arbeitsspeichergröße.
A2-Maschinenserien sind in zwei Typen verfügbar:
- A2 Ultra: Bei diesen Maschinentypen sind A100-GPUs mit 80 GB und eine lokale SSD angehängt.
- A2 Standard: An diese Maschinentypen sind A100-GPUs mit 40 GB angehängt.
A2-Ultra
| Angehängte NVIDIA A100-GPUs mit 80 GB | ||||||
|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Verbundene lokale SSD (GiB) | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1.500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1.360 | 3.000 | 100 | 8 | 640 |
A2-Standard
| Angehängte NVIDIA A100-GPUs mit 40 GB | ||||||
|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Unterstützung lokaler SSDs | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | Ja | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | Ja | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | Ja | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | Ja | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1.360 | Ja | 100 | 16 | 640 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
G4-Maschinentypen
Beschleunigungsoptimierte G4-Maschinentypen
verwenden
NVIDIA RTX PRO 6000 Blackwell Server Edition-GPUs (nvidia-rtx-pro-6000)
und eignen sich für NVIDIA Omniverse-Simulationsarbeitslasten, grafikintensive Anwendungen, Videotranscodierung und virtuelle Desktops. G4-Maschinentypen bieten im Vergleich zu Maschinentypen der A-Serie auch eine kostengünstige Lösung für die Durchführung von Single-Host-Inferenz und Modelloptimierung.
| Angehängte NVIDIA RTX PRO 6000-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Instanzarbeitsspeicher (GB) | Maximal unterstützte Titanium-SSD (GiB)2 | Anzahl der physischen NICs | Maximale Netzwerkbandbreite (Gbit/s)3 | GPU-Anzahl | GPU-Arbeitsspeicher4 (GB GDDR7) |
g4-standard-6 |
6 | 22 | 0 | 1 | 20 | 1/8 | 12 |
g4-standard-12 |
12 | 45 | 375 | 1 | 20 | 1/4 | 24 |
g4-standard-24 |
24 | 90 | 750 | 1 | 20 | 1/2 | 48 |
g4-standard-48 |
48 | 180 | 1.500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3.000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6.000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1.440 | 12.000 | 2 | 400 | 8 | 768 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Sie können Titanium-SSD-Laufwerke hinzufügen, wenn Sie eine G4-Instanz erstellen. Informationen zur Anzahl der Laufwerke, die Sie anhängen können, finden Sie unter Maschinentypen, bei denen Sie eine bestimmte Anzahl von lokalen SSD-Laufwerken auswählen müssen.
3 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Siehe Netzwerkbandbreite.
4 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
G2-Maschinentypen
Beschleunigungsoptimierte G2-Maschinentypen haben NVIDIA L4-GPUs angehängt und sind ideal für kostenoptimierte Inferenz-, grafikintensive und Hochleistungs-Computing-Arbeitslasten.
Jeder G2-Maschinentyp hat auch einen Standardarbeitsspeicher und einen benutzerdefinierten Arbeitsspeicherbereich. Der benutzerdefinierte Arbeitsspeicherbereich definiert die Größe des Arbeitsspeichers, den Sie Ihrer Instanz für jeden Maschinentyp zuweisen können. Sie können auch beim Erstellen einer G2-Instanz lokale SSD-Laufwerke hinzufügen. Informationen zur Anzahl der Laufwerke, die Sie anhängen können, finden Sie unter Maschinentypen, bei denen Sie eine bestimmte Anzahl von lokalen SSD-Laufwerken auswählen müssen.
Um die höheren Netzwerkbandbreitenraten (50 Gbit/s oder höher) für die meisten GPU-Instanzen zu erhalten, wird die Verwendung von Google Virtual NIC (gVNIC) empfohlen. Weitere Informationen zum Erstellen von GPU-Instanzen, die gVNIC verwenden, finden Sie unter GPU-Instanzen mit höheren Bandbreiten erstellen.
| Angehängte NVIDIA L4-GPUs | |||||||
|---|---|---|---|---|---|---|---|
| Maschinentyp | vCPU-Anzahl1 | Standard-Instanzarbeitsspeicher (GB) | Benutzerdefinierter Instanzarbeitsspeicherbereich (GB) | Maximal unterstützte lokale SSD (GiB) | Maximale Netzwerkbandbreite (Gbit/s)2 | GPU-Anzahl | GPU-Arbeitsspeicher3 (GB GDDR6) |
g2-standard-4 |
4 | 16 | 16 bis 32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32 bis 54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48 bis 54 | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54 bis 64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96 bis 108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96 bis 128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192 bis 216 | 1.500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384 bis 432 | 3.000 | 100 | 8 | 192 |
1 Eine vCPU ist als einzelner Hardware-Hyper-Thread auf einer der verfügbaren CPU-Plattformen implementiert.
2 Die maximale Bandbreite für ausgehenden Traffic darf die angegebene Zahl nicht überschreiten. Die tatsächliche Bandbreite für ausgehenden Traffic hängt von der Ziel-IP-Adresse und anderen Faktoren ab.
Weitere Informationen zur Netzwerkbandbreite finden Sie unter Netzwerkbandbreite.
3 GPU-Arbeitsspeicher ist der Speicher auf einem GPU-Gerät, der zum temporären Speichern von Daten verwendet werden kann. Es ist vom Arbeitsspeicher der Instanz getrennt und wurde speziell für die höheren Bandbreitenanforderungen grafikintensiver Arbeitslasten entwickelt.
N1 + GPU-Maschinentypen
Bei N1-VM-Instanzen für allgemeine Zwecke, an die T4- und V100-GPUs angeschlossen sind, können Sie basierend auf der Kombination aus GPU und Anzahl der vCPUs eine maximale Netzwerkbandbreite von bis zu 100 Gbit/s erhalten. Informationen zu allen anderen N1-GPU-Instanzen finden Sie unter Übersicht.
Lesen Sie den folgenden Abschnitt, um die maximale Netzwerkbandbreite zu berechnen, die für Ihre T4- und V100-Instanzen basierend auf dem GPU-Modell, der vCPU und der GPU-Anzahl verfügbar ist.
Weniger als 5 vCPUs
Für T4- und V100-Instanzen mit maximal 5 vCPUs steht eine maximale Netzwerkbandbreite von 10 Gbit/s zur Verfügung.
Mehr als 5 vCPUs
Bei T4- und V100-Instanzen mit mehr als 5 vCPUs wird die maximale Netzwerkbandbreite anhand der Anzahl der vCPUs und GPUs für diese VM berechnet.
Um die höheren Netzwerkbandbreitenraten (50 Gbit/s oder höher) für die meisten GPU-Instanzen zu erhalten, wird die Verwendung von Google Virtual NIC (gVNIC) empfohlen. Weitere Informationen zum Erstellen von GPU-Instanzen, die gVNIC verwenden, finden Sie unter GPU-Instanzen mit höheren Bandbreiten erstellen.
| GPU-Modell | Anzahl der GPUs | Berechnung der maximalen Netzwerkbandbreite |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
MTU-Einstellungen und GPU-Maschinentypen
Um den Netzwerkdurchsatz zu erhöhen, legen Sie für Ihre VPC-Netzwerke einen höheren MTU-Wert (Maximum Transmission Unit) fest. Höhere MTU-Werte steigern die Paketgröße und reduzieren den Paketheader-Overhead, wodurch der Nutzlastdatendurchsatz erhöht wird.
Für GPU-Maschinentypen empfehlen wir die folgenden MTU-Einstellungen für Ihre VPC-Netzwerke.
| GPU-Maschinentyp | Empfohlene MTU (in Byte) | |
|---|---|---|
| Reguläres VPC-Netzwerk | RoCE-VPC-Netzwerk | |
|
8896 | 8896 |
|
8244 | – |
|
8896 | – |
Beachten Sie beim Festlegen des MTU-Werts Folgendes:
- 8.192 Zeichen entsprechen zwei 4‑KB-Seiten.
- 8244 wird in A3 Mega-, A3 High- und A3 Edge-VMs für GPU-NICs empfohlen, für die die Header-Aufteilung aktiviert ist.
- Verwenden Sie den Wert 8896, sofern in der Tabelle nichts anderes angegeben ist.
GPU-Maschinen mit hoher Bandbreite erstellen
Verwenden Sie eine der folgenden Methoden, um GPU-Instanzen mit höherer Netzwerkbandbreite zu erstellen, je nach Maschinentyp:
Informationen zum Erstellen von A2-, G2- und N1-Instanzen, die höhere Netzwerkbandbreiten verwenden, finden Sie unter Höhere Netzwerkbandbreite für A2-, G2- und N1-Instanzen verwenden. Zum Testen oder Prüfen der Bandbreitengeschwindigkeit für diese Maschinen können Sie den Benchmarking-Test verwenden. Weitere Informationen finden Sie unter Netzwerkbandbreite prüfen.
Informationen zum Erstellen von A3 Mega-Instanzen mit höherer Netzwerkbandbreite finden Sie unter A3 Mega-Slurm-Cluster für ML-Training bereitstellen. Zum Testen oder Prüfen der Bandbreitengeschwindigkeit für diese Maschinen können Sie einen Benchmarking-Test durchführen. Folgen Sie dazu der Anleitung unter Netzwerkbandbreite prüfen.
Informationen zu A3-High- und A3-Edge-Instanzen, die höhere Netzwerkbandbreiten verwenden, finden Sie unter A3-VM mit aktiviertem GPUDirect-TCPX erstellen. Zum Testen oder Prüfen der Bandbreitengeschwindigkeit für diese Maschinen können Sie den Benchmarking-Test verwenden. Weitere Informationen finden Sie unter Netzwerkbandbreite prüfen.
Für andere beschleunigungsoptimierte Maschinentypen ist keine Aktion erforderlich, um eine höhere Netzwerkbandbreite zu nutzen. Beim Erstellen einer Instanz wird bereits eine hohe Netzwerkbandbreite verwendet. Informationen zum Erstellen von Instanzen für andere beschleunigungsoptimierte Maschinentypen finden Sie unter VM mit angehängten GPUs erstellen.
Nächste Schritte
- Weitere Informationen zu GPU-Plattformen
- Instanzen mit angehängten GPUs erstellen
- Weitere Informationen
- GPU-Preisübersicht