
Este documento descreve as capacidades e configurações de largura de banda de rede para instâncias do Compute Engine com GPUs anexadas. Saiba mais sobre a largura de banda máxima de rede, as configurações de placa de interface de rede (NIC) e as configurações de rede VPC recomendadas para vários tipos de máquinas com GPU, incluindo as séries A4X Max, A4X, A4, A3, A2, G4, G2 e N1. Entender essas configurações pode ajudar você a otimizar a performance das cargas de trabalho distribuídas no Compute Engine.
Visão geral
A tabela a seguir oferece uma comparação geral dos recursos de rede em tipos de máquinas com GPU.
| Tipo de máquina | Modelo de GPU | Largura de banda total máxima | Tecnologia de rede de GPU para GPU |
|---|---|---|---|
| A4X Max | Superchips NVIDIA GB300 Ultra | 3.600 Gbps | RDMA do GPUDirect |
| A4X | Superchips NVIDIA GB200 | 2.000 Gbps | GPUDirect RDMA |
| A4 | NVIDIA B200 | 3.600 Gbps | RDMA do GPUDirect |
| A3 Ultra | NVIDIA H200 | 3.600 Gbps | RDMA do GPUDirect |
| A3 Mega | NVIDIA H100 80GB | 1.800 Gbps | GPUDirect-TCPXO |
| A3 Alto | NVIDIA H100 80GB | 1.000 Gbps | GPUDirect-TCPX |
| A3 Edge | NVIDIA H100 80GB | 600 Gbps | GPUDirect-TCPX |
| G4 | NVIDIA RTX PRO 6000 | 400 Gbps | N/A |
| A2 Standard e A2 Ultra | NVIDIA A100 40GB, NVIDIA A100 80GB | 100 Gbps | N/A |
| G2 | NVIDIA L4 | 100 Gbps | N/A |
| N1 | NVIDIA T4, NVIDIA V100 | 100 Gbps | N/A |
| N1 | NVIDIA P100, NVIDIA P4 | 32 Gbps | N/A |
Funções GPUDirect RDMA e MRDMA
Em determinados tipos de máquinas otimizadas para aceleradores,o Google Cloud usa o MRDMA como a implementação da interface de rede para a rede de GPU para GPU que oferece suporte ao GPUDirect RDMA.
O GPUDirect RDMA é uma tecnologia da NVIDIA que permite que uma placa de interface de rede (NIC) acesse diretamente a memória da GPU via PCIe, ignorando a CPU do host e a memória do sistema. Essa comunicação ponto a ponto entre a NIC e a GPU reduz significativamente a latência da comunicação entre GPUs de diferentes nós.
O MRDMA é a implementação de interface de rede usada nos tipos de máquina A4X Max, A4X, A4 e A3 Ultra para oferecer recursos de GPUDirect RDMA. O MRDMA é baseado em NICs NVIDIA ConnectX e implantado de uma das seguintes maneiras:
- Funções virtuais (VFs) do MRDMA: usadas nas séries A3 Ultra, A4 e A4X.
- Funções físicas (PFs) do MRDMA: usadas na série A4X Max.
Funções do MRDMA e ferramentas de monitoramento de rede
Os tipos de máquina A4X, A4 e A3 Ultra implementam redes de alto desempenho de GPU para GPU usando funções virtuais (VFs) do MRDMA. Como essas são entidades virtualizadas, algumas capacidades de monitoramento no nível do hardware são restritas em comparação com as funções físicas (PFs, na sigla em inglês).
Com VFs MRDMA, os contadores de porta física padrão (como aqueles que terminam em _phy) aparecem na saída ethtool -S, mas não são atualizados durante a atividade de rede. Essa é uma característica da arquitetura MRDMA VF. Para rastrear com precisão a performance da rede nessas interfaces, revise as entradas da Tabela de contadores de vPort em vez da Tabela de contadores de porta física.
O tipo de máquina A4X Max usa PFs de MRDMA. Ao contrário dos tipos de máquina baseados em VF do MRDMA, o A4X Max é compatível com toda a variedade de contadores de portas físicas para rede de GPU.
Revise os conceitos de rede para tipos de máquina com GPU
Use a seção a seguir para analisar a organização da rede e a velocidade da largura de banda para cada tipo de máquina com GPU.
Tipos de máquina A4X Max e A4X
As séries de máquinas A4X Max e A4X, ambas baseadas na arquitetura NVIDIA Blackwell, foram projetadas para cargas de trabalho de IA distribuídas, exigentes e de grande escala. O principal diferencial entre os dois é o hardware de rede e os aceleradores conectados, conforme descrito na tabela a seguir:
| Série de máquinas A4X Max | Série de máquinas A4X | |
|---|---|---|
| Hardware conectado | Superchips NVIDIA GB300 Ultra | Superchips NVIDIA GB200 |
| Redes de GPU para GPU | Quatro SuperNICs NVIDIA ConnectX-8 (CX-8) que fornecem largura de banda de 3.200 Gbps em uma topologia alinhada a trilhos de oito vias | Quatro NICs NVIDIA ConnectX-7 (CX-7) que fornecem largura de banda de 1.600 Gbps em uma topologia alinhada a trilhos de quatro vias |
| Implementação de rede entre GPUs | 8 funções físicas (PFs, na sigla em inglês) do MRDMA configuradas como 2 PFs por NIC | Quatro funções virtuais (VFs) de MRDMA configuradas como uma VF por NIC |
| Rede de uso geral | 2 NICs inteligentes Titanium que fornecem largura de banda de 400 Gbps | 2 NICs inteligentes Titanium que fornecem largura de banda de 400 Gbps |
| Largura de banda máxima total da rede | 3.600 Gbps | 2.000 Gbps |
Arquitetura de rede com várias camadas
As instâncias de computação A4X Max e A4X usam uma arquitetura de rede hierárquica e multicamadas com um design alinhado por rails para otimizar o desempenho de vários tipos de comunicação. Nessa topologia, as instâncias se conectam em vários planos de rede independentes, chamados de trilhos.
- As instâncias A4X Max usam uma topologia alinhada a trilhos de oito vias em que cada uma das quatro NICs ConnectX-8 de 800 Gbps se conecta a dois trilhos separados de 400 Gbps.
- As instâncias A4X usam uma topologia alinhada a trilhos de quatro vias, em que cada uma das quatro NICs ConnectX-7 se conecta a um trilho separado.
As camadas de rede para esses tipos de máquina são as seguintes:
Comunicação intranó e intrasubbloco (NVLink): uma malha NVLink de alta velocidade interconecta GPUs para comunicação de alta largura de banda e baixa latência. Essa estrutura conecta todas as GPUs em uma única instância e se estende por um subbloco, que consiste em 18 instâncias A4X Max ou A4X (um total de 72 GPUs). Isso permite que todas as 72 GPUs em um subbloco se comuniquem como se estivessem em um único servidor de GPU em grande escala.
Comunicação entre subblocos (NICs ConnectX com RoCE): para escalonar cargas de trabalho além de um único subbloco, essas máquinas usam NICs NVIDIA ConnectX. Essas NICs usam RDMA em Ethernet convergente (RoCE) para fornecer comunicação de alta largura de banda e baixa latência entre sub-blocos, permitindo criar clusters de treinamento em grande escala com milhares de GPUs.
Rede de uso geral (NICs inteligentes Titanium): além das redes de GPU especializadas, cada instância tem duas NICs inteligentes Titanium, fornecendo um total de 400 Gbps de largura de banda para tarefas gerais de rede. Isso inclui o tráfego para armazenamento, gerenciamento e conexão com outros serviços do Google Cloud ou com a Internet pública.
Arquitetura A4X Max
A arquitetura A4X Max é criada com base nos superchips NVIDIA GB300 Ultra. Um recurso fundamental desse design é a conexão direta das quatro SuperNICs NVIDIA ConnectX-8 (CX-8) de 800 Gbps às GPUs. Cada ConnectX-8 é uma NIC de porta dupla, que é exposta à instância como duas funções físicas (PFs, na sigla em inglês). Essas NICs fazem parte de uma topologia de rede alinhada a trilhos de oito vias, em que cada NIC se conecta a dois trilhos separados de 400 Gbps. Esse caminho direto permite o RDMA, fornecendo alta largura de banda e baixa latência para comunicação de GPU para GPU em diferentes sub-blocos. Essas instâncias do Compute Engine também incluem SSDs locais de alto desempenho anexados às NICs ConnectX-8, ignorando o barramento PCIe para acesso mais rápido aos dados.
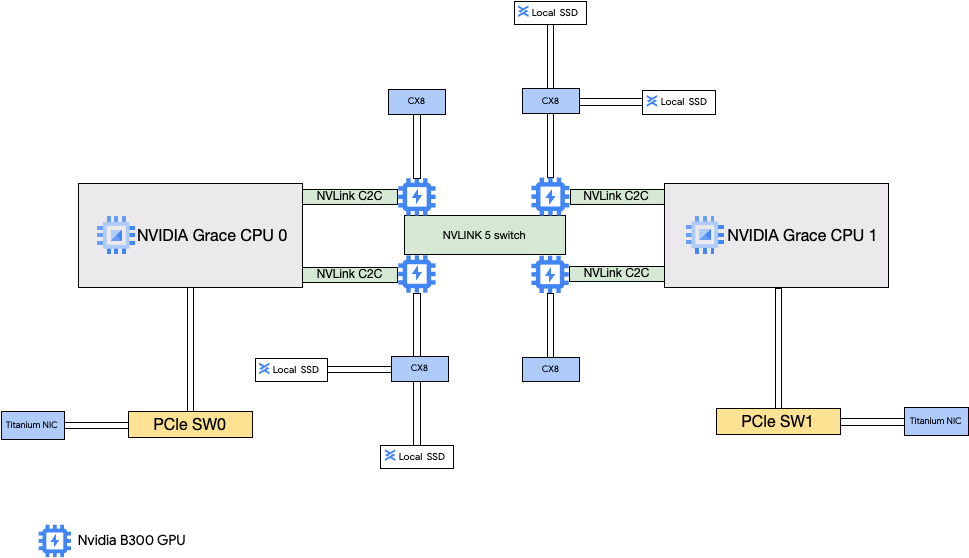
Arquitetura A4X
A arquitetura A4X usa superchips NVIDIA GB200. Nessa configuração, as quatro NICs NVIDIA ConnectX-7 (CX-7) estão conectadas à CPU do host. Essa configuração oferece rede de alto desempenho para comunicação entre GPUs e subblocos.

Configuração de rede de nuvem privada virtual (VPC) A4X Max e A4X
Para usar todos os recursos de rede desses tipos de máquina, crie e anexe redes VPC às suas instâncias. Para usar todas as NICs disponíveis, crie redes VPC da seguinte maneira:
Duas redes VPC regulares para as NICs inteligentes do Titanium.
- Para o A4X Max, essas redes VPC usam o driver de dispositivo PF de LAN IDPF da Intel.
- Para o A4X, essas redes VPC usam a interface de rede NIC virtual do Google (gVNIC).
Uma rede VPC com o perfil de rede RoCE é necessária para as NICs ConnectX ao criar clusters de vários subblocos A4X Max ou A4X. A rede VPC RoCE precisa ter uma sub-rede para cada trilho de rede. Isso significa oito sub-redes para instâncias A4X Max e quatro sub-redes para instâncias A4X. Se você usar um único subbloco, poderá omitir essa rede VPC porque a estrutura NVLink de vários nós processa a comunicação direta de GPU para GPU.
Para configurar essas redes, consulte Criar redes VPC na documentação do AI Hypercomputer.
Tipos de máquina A4X Max e A4X
A4X Max
| Superchips NVIDIA GB300 Grace Blackwell Ultra conectados | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3e) |
a4x-maxgpu-4g-metal |
144 | 960 | 12.000 | 6 | 3.600 | 4 | 1.116 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
A4X
| Superchips NVIDIA GB200 Grace Blackwell conectados | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3e) |
a4x-highgpu-4g |
140 | 884 | 12.000 | 6 | 2.000 | 4 | 744 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
Tipos de máquina A4 e A3 Ultra
Os tipos de máquina A4 têm GPUs NVIDIA B200 anexadas, e os tipos de máquina A3 Ultra têm GPUs NVIDIA H200 anexadas.
Esses tipos de máquina oferecem oito placas de rede (NICs) NVIDIA ConnectX-7 (CX-7) e duas NICs virtuais do Google (gVNIC). As oito NICs CX-7 fornecem uma largura de banda total de rede de 3.200 Gbps. Essas NICs são dedicadas apenas à comunicação de GPU para GPU de alta largura de banda e não podem ser usadas para outras necessidades de rede, como acesso à Internet pública. Conforme descrito no diagrama a seguir, cada NIC CX-7 fica alinhada a uma GPU para otimizar o acesso à memória não uniforme (NUMA). As oito GPUs podem se comunicar rapidamente entre si usando a ponte NVLink "todos com todos" que as conecta. As outras duas placas de rede gVNIC são NICs inteligentes que oferecem mais 400 Gbps de largura de banda para requisitos de rede de uso geral. Juntas, as placas de interface de rede oferecem uma largura de banda máxima total de 3.600 Gbps para essas máquinas.
A rede de alto desempenho entre GPUs nas instâncias A4 e A3 Ultra é implementada usando funções virtuais (VFs) do MRDMA para cada uma das oito placas de rede ConnectX-7.
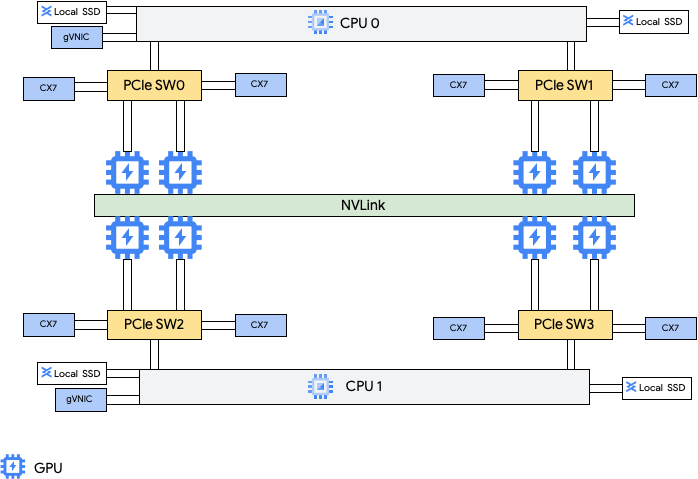
Para usar essas várias NICs, crie três redes de nuvem privada virtual da seguinte forma:
- Duas redes VPC regulares: cada gVNIC precisa ser anexada a uma rede VPC diferente
- Uma rede VPC RoCE: todas as oito NICs CX-7 compartilham a mesma rede VPC RoCE.
Para configurar essas redes, consulte Criar redes VPC na documentação do AI Hypercomputer.
A4
| GPUs NVIDIA B200 Blackwell anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3e) |
a4-highgpu-8g |
224 | 3.968 | 12.000 | 10 | 3.600 | 8 | 1,440 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte
Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
A3 Ultra
| GPUs NVIDIA H200 anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3e) |
a3-ultragpu-8g |
224 | 2.952 | 12.000 | 10 | 3.600 | 8 | 1128 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
Tipos de máquina A3 Mega, High e Edge
Esses tipos de máquina têm GPUs H100 anexadas. Cada um desses tipos de máquina tem uma contagem de GPU, uma contagem de vCPU e um tamanho de memória fixos.
- VMs A3 com uma única NIC: para VMs A3 com 1 a 4 GPUs anexadas, apenas uma placa de rede física (NIC) está disponível.
- VMs A3 com várias NICs: para VMs A3 com 8 GPUs anexadas, várias NICs físicas estão disponíveis. Para esses tipos de máquina A3, as NICs são organizadas da seguinte maneira em um barramento Peripheral Component Interconnect Express (PCIe):
- Para o tipo de máquina A3 Mega: um arranjo de NIC de 8+1 está disponível. Com esse arranjo, oito NICs compartilham o mesmo barramento PCIe, e uma NIC reside em um barramento PCIe separado.
- Para o tipo de máquina A3 High: um arranjo de NIC de 4+1 está disponível. Com esse arranjo, quatro NICs compartilham o mesmo barramento PCIe, e uma NIC reside em um barramento PCIe separado.
- Para o tipo de máquina A3 Edge: um arranjo de NIC de 4+1 está disponível. Com esse arranjo, quatro NICs compartilham o mesmo barramento PCIe, e uma NIC reside em um barramento PCIe separado. Essas cinco NICs oferecem uma largura de banda total de 400 Gbps para cada VM.
As NICs que compartilham o mesmo barramento PCIe têm um alinhamento de acesso à memória não uniforme (NUMA) de um NIC por duas GPUs NVIDIA H100. Essas NICs são ideais para comunicação dedicada de GPU para GPU de alta largura de banda. A NIC física que reside em um barramento PCIe separado é ideal para outras necessidades de rede. Para instruções sobre como configurar a rede para VMs A3 High e A3 Edge, consulte configurar redes MTU de frame jumbo.
A3 Mega
| GPUs NVIDIA H100 anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3) |
a3-megagpu-8g |
208 | 1.872 | 6.000 | 9 | 1.800 | 8 | 640 |
A3 High
| GPUs NVIDIA H100 anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3) |
a3-highgpu-1g |
26 | 234 | 750 | 1 | 25 | 1 | 80 |
a3-highgpu-2g |
52 | 468 | 1.500 | 1 | 50 | 2 | 160 |
a3-highgpu-4g |
104 | 936 | 3.000 | 1 | 100 | 4 | 320 |
a3-highgpu-8g |
208 | 1.872 | 6.000 | 5 | 1.000 | 8 | 640 |
A3 Edge
| GPUs NVIDIA H100 anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM3) |
a3-edgegpu-8g |
208 | 1.872 | 6.000 | 5 |
|
8 | 640 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
Tipos de máquina A2
Cada tipo de máquina A2 tem um número fixo de GPUs NVIDIA A100 de 40 GB ou NVIDIA A100 de 80 GB anexadas. Cada tipo de máquina também tem uma contagem fixa de vCPUs e um tamanho de memória.
A série de máquinas A2 está disponível em dois tipos:
- A2 Ultra: esses tipos de máquina têm GPUs A100 de 80 GB e discos SSD locais conectados.
- A2 Standard (, ): esses tipos de máquina têm GPUs A100 de 40 GB anexadas.
A2 Ultra
| GPUs NVIDIA A100 de 80 GB anexadas | ||||||
|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | SSD local anexado (GiB) | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM2e) |
a2-ultragpu-1g |
12 | 170 | 375 | 24 | 1 | 80 |
a2-ultragpu-2g |
24 | 340 | 750 | 32 | 2 | 160 |
a2-ultragpu-4g |
48 | 680 | 1.500 | 50 | 4 | 320 |
a2-ultragpu-8g |
96 | 1.360 | 3.000 | 100 | 8 | 640 |
A2 Padrão
| GPUs NVIDIA A100 de 40 GB anexadas | ||||||
|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | Compatível com SSD local | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB HBM2) |
a2-highgpu-1g |
12 | 85 | Sim | 24 | 1 | 40 |
a2-highgpu-2g |
24 | 170 | Sim | 32 | 2 | 80 |
a2-highgpu-4g |
48 | 340 | Sim | 50 | 4 | 160 |
a2-highgpu-8g |
96 | 680 | Sim | 100 | 8 | 320 |
a2-megagpu-16g |
96 | 1.360 | Sim | 100 | 16 | 640 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
Tipos de máquina G4
Os tipos de máquina G4 otimizados para acelerador
usam
GPUs NVIDIA RTX PRO 6000 Blackwell Server Edition (nvidia-rtx-pro-6000)
e são
adequados para cargas de trabalho de simulação do NVIDIA Omniverse, aplicativos com muitos gráficos, transcodificação
de vídeo e desktops virtuais. Os tipos de máquina G4 também oferecem uma solução de baixo custo para realizar inferência de host único e ajuste de modelo em comparação com os tipos de máquina da série A.
| GPUs NVIDIA RTX PRO 6000 anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória da instância (GB) | Máximo de SSD Titanium compatível (GiB)2 | Contagem de NICs físicas | Largura de banda máxima da rede (Gbps)3 | Contagem de GPUs | Memória da GPU4 (GB GDDR7) |
g4-standard-6 |
6 | 22 | 0 | 1 | 20 | 1/8 | 12 |
g4-standard-12 |
12 | 45 | 375 | 1 | 20 | 1/4 | 24 |
g4-standard-24 |
24 | 90 | 750 | 1 | 20 | 1/2 | 48 |
g4-standard-48 |
48 | 180 | 1.500 | 1 | 50 | 1 | 96 |
g4-standard-96 |
96 | 360 | 3.000 | 1 | 100 | 2 | 192 |
g4-standard-192 |
192 | 720 | 6.000 | 1 | 200 | 4 | 384 |
g4-standard-384 |
384 | 1,440 | 12.000 | 2 | 400 | 8 | 768 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2É possível adicionar discos SSD Titanium ao criar uma instância G4. Para saber o número de discos que podem ser anexados, consulte Tipos de máquina que exigem que você escolha um número de discos SSD locais.
3A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Consulte Largura de banda de rede.
4A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
Tipos de máquina G2
Os tipos de máquina otimizados para acelerador G2 têm GPUs NVIDIA L4 anexadas e são ideais para inferência otimizada para custos, cargas de trabalho de computação de alto desempenho e com uso intenso de gráficos.
Cada tipo de máquina G2 também tem uma memória padrão e um intervalo de memória personalizado. O intervalo de memória personalizado define a quantidade de memória que pode ser alocada à instância para cada tipo de máquina. Você também pode adicionar discos SSD locais ao criar uma instância G2. Para saber o número de discos que podem ser anexados, consulte Tipos de máquina que exigem que você escolha um número de discos SSD locais.
Para aplicar as taxas mais altas de largura de banda de rede (50 Gbps ou mais) à maioria das instâncias de GPU, é recomendado usar a placa de rede virtual do Google (gVNIC). Para mais informações sobre como criar instâncias de GPU que usam a gVNIC, consulte Como criar instâncias de GPU que usam larguras de banda maiores.
| GPUs NVIDIA L4 anexadas | |||||||
|---|---|---|---|---|---|---|---|
| Tipo de máquina | Contagem de vCPU1 | Memória padrão da instância (GB) | Intervalo de memória personalizada da instância (GB) | Suporte máximo para SSD local (GiB) | Largura de banda máxima da rede (Gbps)2 | Contagem de GPUs | Memória da GPU3 (GB GDDR6) |
g2-standard-4 |
4 | 16 | 16 a 32 | 375 | 10 | 1 | 24 |
g2-standard-8 |
8 | 32 | 32 a 54 | 375 | 16 | 1 | 24 |
g2-standard-12 |
12 | 48 | 48 a 54 | 375 | 16 | 1 | 24 |
g2-standard-16 |
16 | 64 | 54 a 64 | 375 | 32 | 1 | 24 |
g2-standard-24 |
24 | 96 | 96 a 108 | 750 | 32 | 2 | 48 |
g2-standard-32 |
32 | 128 | 96 a 128 | 375 | 32 | 1 | 24 |
g2-standard-48 |
48 | 192 | 192 a 216 | 1.500 | 50 | 4 | 96 |
g2-standard-96 |
96 | 384 | 384 a 432 | 3.000 | 100 | 8 | 192 |
1Uma vCPU é implementada como um único hyper-thread de hardware em
uma das plataformas de CPU disponíveis.
2A largura de banda de saída máxima não pode exceder o número informado. A largura
de banda de saída real depende do endereço IP de destino e de outros fatores.
Para mais informações sobre largura de banda de rede, consulte Largura de banda de rede.
3A memória da GPU é a memória em um dispositivo GPU que pode ser usada para
armazenamento temporário de dados. Ela é separada da memória da instância e foi projetada especificamente para lidar com as demandas de largura de banda mais altas das cargas de trabalho com uso intensivo de gráficos.
Tipos de máquina N1 + GPU
Para instâncias de máquina virtual (VMs) de uso geral N1 com GPUs T4 e V100 anexadas, é possível ter uma largura de banda de rede máxima de até 100 Gbps, com base na combinação da contagem de GPUs e vCPUs. Para todas as outras instâncias de GPU N1, consulte a Visão geral.
Consulte a seção a seguir para calcular a largura de banda de rede máxima disponível para as instâncias T4 e V100 com base no modelo de GPU, na vCPU e na contagem de GPUs.
Menos de cinco vCPUs
Para instâncias T4 e V100 com cinco vCPUs ou menos, está disponível uma largura de banda de rede máxima de 10 Gbps.
Mais de cinco vCPUs
Para instâncias T4 e V100 com mais de cinco vCPUs, a largura de banda de rede máxima é calculada com base no número de vCPUs e GPUs da VM.
Para aplicar as taxas mais altas de largura de banda de rede (50 Gbps ou mais) à maioria das instâncias de GPU, é recomendado usar a placa de rede virtual do Google (gVNIC). Para mais informações sobre como criar instâncias de GPU que usam a gVNIC, consulte Como criar instâncias de GPU que usam larguras de banda maiores.
| Modelo de GPU | Número de GPUs | Cálculo da largura de banda de rede máxima |
|---|---|---|
| NVIDIA V100 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 32) |
|
| 4 | min(vcpu_count * 2, 50) |
|
| 8 | min(vcpu_count * 2, 100) |
|
| NVIDIA T4 | 1 | min(vcpu_count * 2, 32) |
| 2 | min(vcpu_count * 2, 50) |
|
| 4 | min(vcpu_count * 2, 100) |
Configurações de MTU e tipos de máquina de GPU
Para aumentar a capacidade da rede, defina um valor maior de unidade máxima de transmissão (MTU) para suas redes VPC. Valores de MTU mais altos aumentam o tamanho do pacote e reduzem a sobrecarga do cabeçalho do pacote, o que aumenta a capacidade de dados do payload.
Para tipos de máquina de GPU, recomendamos as seguintes configurações de MTU para suas redes VPC.
| Tipo de máquina de GPU | MTU recomendada (em bytes) | |
|---|---|---|
| Rede VPC comum | Rede VPC RoCE | |
|
8896 | 8896 |
|
8244 | N/A |
|
8896 | N/A |
Ao definir o valor de MTU, observe o seguinte:
- 8192 são duas páginas de 4 KB.
- O 8244 é recomendado em VMs A3 Mega, A3 High e A3 Edge para NICs de GPU que têm divisão de cabeçalho ativada.
- Use o valor 8896, a menos que indicado de outra forma na tabela.
Criar máquinas de GPU com largura de banda alta
Para criar instâncias de GPU que usam larguras de banda de rede maiores, use um dos métodos a seguir com base no tipo de máquina:
Para criar instâncias A2, G2 e N1 que usam larguras de banda de rede maiores, consulte Usar largura de banda de rede maior para instâncias A2, G2 e N1. Para testar ou verificar a velocidade de largura de banda dessas máquinas, use o teste de comparação. Para mais informações, consulte Como verificar a largura de banda da rede.
Para criar instâncias A3 Mega que usam larguras de banda de rede maiores, consulte Implantar um cluster A3 Mega Slurm para treinamento de ML. Para testar ou verificar a velocidade de largura de banda dessas máquinas, use um teste de comparação seguindo as etapas em Como verificar a largura de banda da rede.
Para instâncias A3 High e A3 Edge que usam larguras de banda de rede maiores, consulte Criar uma VM A3 com o GPUDirect-TCPX ativado. Para testar ou verificar a velocidade de largura de banda dessas máquinas, use o teste de comparação. Para mais informações, consulte Como verificar a largura de banda da rede.
Para outros tipos de máquinas otimizadas para aceleradores, não é necessário fazer nada para usar uma largura de banda de rede maior. A criação de uma instância conforme documentado já usa uma largura de banda de rede alta. Para saber como criar instâncias para outros tipos de máquinas otimizadas para aceleradores, consulte Criar uma VM com GPUs anexadas.
A seguir
- Saiba mais sobre as plataformas de GPU.
- Saiba como criar instâncias com GPUs anexadas.
- Saiba como usar uma largura de banda de rede maior.
- Saiba mais sobre os preços da GPU.