
In diesem Dokument erfahren Sie, wie Festplattenklone funktionieren und wie Sie einen Festplattenklon erstellen. Mit dem Klonen von Laufwerken können Sie sofort verwendbare Kopien vorhandener Laufwerke am selben Standort (Zone oder Region) erstellen. Erstellen Sie einen Laufwerkklon in Szenarien, in denen Sie eine Kopie eines vorhandenen Laufwerks benötigen, die Sie sofort an eine VM anhängen können. Beispiele:
- Staging-Umgebungen erstellen, indem Produktionsdaten dupliziert werden, um Fehler zu beheben, ohne die Produktion zu stören
- Malwarescans einer Festplatte ohne Beeinträchtigung der Leistung einer Produktionsarbeitslast durchführen
- Kopien zur Überprüfung von Datenbanksicherungen erstellen
- Daten von Laufwerken ohne Bootfunktion in ein neues Projekt verschieben
- Laufwerke beim Skalieren von VMs duplizieren
Um die Notfallwiederherstellung für Ihre Daten zu aktivieren, sichern Sie Ihr Laufwerk mit Standard-Snapshots anstelle von Laufwerkklonen. Wenn Sie Laufwerkinhalte in regelmäßigen Abständen erfassen möchten, ohne neue Laufwerke zu erstellen, verwenden Sie Instant Snapshots, da sie speichereffizienter als Klone sind. Weitere Optionen zum Schutz von Laufwerken finden Sie unter Datenschutzoptionen.
Hinweise
-
Richten Sie die Authentifizierung ein, falls Sie dies noch nicht getan haben.
Bei der Authentifizierung wird Ihre Identität für den Zugriff auf Google Cloud Dienste und APIs überprüft. Zur Ausführung von Code oder Beispielen aus einer lokalen Entwicklungsumgebung können Sie sich so bei Compute Engine authentifizieren:
Wählen Sie den Tab aus, der Ihrer geplanten Verwendung der Beispiele auf dieser Seite entspricht:
Console
Wenn Sie über die Google Cloud Console auf Google Cloud Dienste und APIs zugreifen, müssen Sie die Authentifizierung nicht einrichten.
gcloud
-
Installieren Sie die Google Cloud CLI. Initialisieren Sie die Google Cloud CLI nach der Installation mit dem folgenden Befehl:
gcloud initWenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
- Legen Sie eine Standardregion und -zone fest.
-
Installieren Sie die Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Wenn Sie eine lokale Shell verwenden, erstellen Sie lokale Anmeldedaten zur Authentifizierung für Ihr Nutzerkonto:
gcloud auth application-default login
Wenn Sie Cloud Shell verwenden, müssen Sie das nicht tun.
Wenn ein Authentifizierungsfehler zurückgegeben wird und Sie einen externen Identitätsanbieter (IdP) verwenden, prüfen Sie, ob Sie sich mit Ihrer föderierten Identität in der gcloud CLI angemeldet haben.
-
Installieren Sie die Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Wenn Sie eine lokale Shell verwenden, erstellen Sie lokale Anmeldedaten zur Authentifizierung für Ihr Nutzerkonto:
gcloud auth application-default login
Wenn Sie Cloud Shell verwenden, müssen Sie das nicht tun.
Wenn ein Authentifizierungsfehler zurückgegeben wird und Sie einen externen Identitätsanbieter (IdP) verwenden, prüfen Sie, ob Sie sich mit Ihrer föderierten Identität in der gcloud CLI angemeldet haben.
-
Installieren Sie die Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Wenn Sie eine lokale Shell verwenden, erstellen Sie lokale Anmeldedaten zur Authentifizierung für Ihr Nutzerkonto:
gcloud auth application-default login
Wenn Sie Cloud Shell verwenden, müssen Sie das nicht tun.
Wenn ein Authentifizierungsfehler zurückgegeben wird und Sie einen externen Identitätsanbieter (IdP) verwenden, prüfen Sie, ob Sie sich mit Ihrer föderierten Identität in der gcloud CLI angemeldet haben.
-
Installieren Sie die Google Cloud CLI.
-
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
-
Wenn Sie eine lokale Shell verwenden, erstellen Sie lokale Anmeldedaten zur Authentifizierung für Ihr Nutzerkonto:
gcloud auth application-default login
Wenn Sie Cloud Shell verwenden, müssen Sie das nicht tun.
Wenn ein Authentifizierungsfehler zurückgegeben wird und Sie einen externen Identitätsanbieter (IdP) verwenden, prüfen Sie, ob Sie sich mit Ihrer föderierten Identität in der gcloud CLI angemeldet haben.
Terraform
Wenn Sie die Terraform-Beispiele auf dieser Seite in einer lokalen Entwicklungsumgebung verwenden möchten, installieren und initialisieren Sie die gcloud CLI und richten Sie dann die Standardanmeldedaten für Anwendungen mit Ihren Nutzeranmeldedaten ein.
Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Go
Wenn Sie die Go-Beispiele auf dieser Seite in einer lokalen Entwicklungsumgebung verwenden möchten, installieren und initialisieren Sie die gcloud CLI und richten Sie dann die Standardanmeldedaten für Anwendungen mit Ihren Nutzeranmeldedaten ein.
Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Java
Wenn Sie die Java-Beispiele auf dieser Seite in einer lokalen Entwicklungsumgebung verwenden möchten, installieren und initialisieren Sie die gcloud CLI und richten Sie dann die Standardanmeldedaten für Anwendungen mit Ihren Nutzeranmeldedaten ein.
Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
Python
Wenn Sie die Python-Beispiele auf dieser Seite in einer lokalen Entwicklungsumgebung verwenden möchten, installieren und initialisieren Sie die gcloud CLI und richten Sie dann die Standardanmeldedaten für Anwendungen mit Ihren Nutzeranmeldedaten ein.
Weitere Informationen finden Sie unter Authentifizierung für eine lokale Entwicklungsumgebung einrichten.
REST
Wenn Sie die REST API-Beispiele auf dieser Seite in einer lokalen Entwicklungsumgebung verwenden möchten, verwenden Sie die Anmeldedaten, die Sie der gcloud CLI bereitstellen.
Installieren Sie die Google Cloud CLI.
Wenn Sie einen externen Identitätsanbieter (IdP) verwenden, müssen Sie sich zuerst mit Ihrer föderierten Identität in der gcloud CLI anmelden.
Weitere Informationen finden Sie in der Dokumentation zur Google Cloud -Authentifizierung unter Für die Verwendung von REST authentifizieren.
Zusammenfassung der Anwendungsfälle
Sie können ein Laufwerk nicht nur duplizieren, um schnell Tests und Fehlerbehebungen durchzuführen, sondern auch Hochverfügbarkeit für ein zonales Laufwerk aktivieren, indem Sie einen regionalen Klon des zonalen Laufwerks erstellen. Wenn Sie ein regionales Laufwerk aus einem zonalen Laufwerk erstellen, hat das regionale Laufwerk ein Replikat des Laufwerks in zwei Zonen derselben Region. Nachdem Sie das regionale Laufwerk erstellt haben, verwenden Sie es anstelle des zonalen Laufwerks. Im seltenen Fall eines Ausfalls in einer Zone können Sie weiterhin auf die Daten des Replikats in der anderen Zone zugreifen.
In dieser Tabelle werden die verschiedenen Arten von Klonen zusammengefasst, die von Compute Engine unterstützt werden.
| Klonierungstyp | Geeignet für | Unterstützte Laufwerkstypen |
|---|---|---|
| Zonaler Klon aus einem zonalen Laufwerk |
Erstellen Sie eine identische Kopie eines Laufwerks in derselben Zone für eine der folgenden Aufgaben:
|
|
| Regionaler Klon eines zonalen Laufwerks |
|
|
| Regionaler Klon eines regionalen Laufwerks |
Erstellen Sie eine identische Kopie eines regionalen Laufwerks in derselben Region für:
|
|
So funktioniert das Klonen von Festplatten
Wenn Sie ein Laufwerk klonen, erstellen Sie ein neues Laufwerk, das alle Daten vom Quelllaufwerk enthält. Sie können einen Laufwerksklon erstellen, auch wenn das vorhandene Laufwerk an eine VM-Instanz angehängt ist. Nachdem Sie ein Laufwerk geklont haben, können Sie das Quelllaufwerk löschen, ohne den Klon zu löschen.
Standardmäßig erben Klone eines Laufwerks seine Größe, Leistungslimits, seinen Typ und die genaue Zone oder Region. Einige dieser Eigenschaften können Sie so ändern:
Größe: Sie können einen Klon erstellen, der größer als das Quelllaufwerk ist, aber nicht kleiner.
Leistung: Für Hyperdisk-Volumes können Sie ein anderes Leistungslimit für den Klon angeben. Regionale Klone von zonalen Hyperdisk-Volumes sind Hyperdisk Balanced High Availability-Volumes und haben möglicherweise andere Leistungslimits.
Standort: Standardmäßig wird ein Laufwerkklon für zonale Laufwerke in derselben Zone und für regionale Laufwerke in derselben Region erstellt. Wenn Sie jedoch einen regionalen Klon eines zonalen Laufwerks erstellen möchten, können Sie eine zweite Zone angeben, die sich in derselben Region wie das zonale Laufwerk befindet. Der neue Klon wird auch als regionaler Klon bezeichnet und hat jeweils ein Replikat in der Zone des Quelllaufwerks und in der zweiten Zone, die Sie angegeben haben.
Typ: Regionale Klone von zonalen Hyperdisk Balanced- oder Hyperdisk Extreme-Volumes sind Hyperdisk Balanced High Availability-Volumes.
Latenz beim Klonen von Datenlaufwerken
Compute Engine klont in der Regel Datenlaufwerke (nicht für den Startvorgang) mit einer Größe von bis zu 32 GiB in weniger als zehn Sekunden. Bei Datenlaufwerken im Unternehmensmaßstab, die bei 1 TiB gemessen wurden, dauert das Klonen in der Regel weniger als eine Minute.
Geklonte Laufwerke können an Instanzen angehängt werden und erreichen sofort nach der Erstellung die volle Leistung. Dadurch werden Initialisierungsverzögerungen vermieden und Workflows mit hohem Umfang wie Sicherheitsprüfungen und die Einrichtung von Entwicklungs- und Testumgebungen werden erheblich beschleunigt.
Regionale Hyperdisk-Volumes, die aus zonalen Hyperdisk-Volumes geklont wurden
Ein regionaler Klon eines vorhandenen zonalen Hyperdisk-Volumens ist immer ein neues Hyperdisk Balanced High Availability-Volume. Das liegt daran, dass Hyperdisk Balanced High Availability die einzige unterstützte regionale Hyperdisk ist. Wie Sie eine regionale Hyperdisk aus einer zonalen Hyperdisk erstellen, hängt vom Typ der zonalen Hyperdisk ab.
Bei zonalen Hyperdisk ML- und Hyperdisk Throughput-Volumes können Sie kein regionales Laufwerk erstellen, indem Sie das Quelllaufwerk klonen. Sie müssen ein neues Hyperdisk Balanced High Availability-Volume aus einem Snapshot des zonalen Laufwerks erstellen.
Für zonale Hyperdisk Balanced- und Hyperdisk Extreme-Volumes erstellen Sie ein neues Hyperdisk Balanced High Availability-Volume, indem Sie einen regionalen Klon eines zonalen Hyperdisk Balanced- oder Hyperdisk Extreme-Volumes erstellen.
Leistung von Hyperdisk Balanced High Availability-Volumes, die von zonalen Laufwerken geklont wurden
Wenn Sie ein neues Hyperdisk Balanced High Availability-Volume aus einem Hyperdisk Balanced- oder Hyperdisk Extreme-Volume erstellen, übernimmt das neue Laufwerk die Größe des Quelllaufwerks. Sie können jedoch eine andere Größe angeben.
Die maximal bereitgestellte Leistung des neuen Laufwerks ist möglicherweise geringer als die des Quelllaufwerks, da Hyperdisk Extreme und Hyperdisk Balanced höhere Leistungslimits haben als Hyperdisk Balanced High Availability, wie in der folgenden Tabelle aufgeführt.
| Hyperdisk-Typ | Maximale E/A-Vorgänge pro Sekunde (IOPS) | Maximaler Durchsatz ( MiB/s) |
|---|---|---|
| Hyperdisk mit ausgeglichener Hochverfügbarkeit | 100.000 | 2.400 |
| Hyperdisk Balanced | 160.000 | 2.400 |
| Hyperdisk Extrem | 350.000 | 5.000 |
Sie können Limits für das neue regionale Laufwerk angeben, die jedoch die maximalen Leistungslimits von Hyperdisk Balanced High Availability nicht überschreiten dürfen – 100.000 IOPS und 2.400 MiB/s.
Wenn Sie kein Leistungslimit für das neue Laufwerk angeben, stellt Compute Engine das Laufwerk mit den Standard-IOPS und dem Standarddurchsatz bereit, die von der Größe des Hyperdisk Balanced High Availability-Volumes abhängen. Die Standardlimits finden Sie unter Standardlimits für Größe und Leistung von Hyperdisk Balanced High Availability.
Um 100.000 IOPS zu erreichen, muss ein Hyperdisk Balanced High Availability-Volume mindestens 200 GiB groß sein. Möglicherweise müssen Sie also auch die bereitgestellte Größe des regionalen Klons erhöhen.
Beispiel
Angenommen, Sie haben ein 150 GiB großes Hyperdisk Extreme-Volume (hdx-1) mit 180.000 IOPS bereitgestellt.
Wenn Sie einen regionalen Klon von hdx-1 erstellen und keine neue Größe oder kein neues Leistungslimit angeben, erstellt Compute Engine ein 150 GiB großes Hyperdisk Balanced High Availability-Volume mit dem Standard-IOPS-Limit für diese Größe: 3.900 IOPS.
Wenn Sie die Größe nicht erhöhen, können Sie für den regionalen Klon bis zu 75.000 IOPS angeben.
Regionale Persistent Disk-Volumes, die aus zonalen Persistent Disk-Volumes geklont wurden
Ein regionales Persistent Disk-Volume, das aus einem zonalen Persistent Disk-Volume geklont wurde, hat denselben Typ wie der Klon. Wenn Sie beispielsweise einen zonalen nichtflüchtigen Standardspeicher klonen, erstellen Sie ein regionales Volume für nichtflüchtigen Standardspeicher.
Regionale Klone von nichtflüchtigen Speicher-Volumes können jedoch die folgenden unterschiedlichen Größen- und Leistungsbeschränkungen als der zonale Quelldatenträger haben.
Niedrigere Leistungslimits: Regionale Klone von Persistent Disk haben möglicherweise niedrigere IOPS- und Durchsatzleistungslimits als das Quelllaufwerk. Das liegt daran, dass zonale Persistent Disks höhere maximale Leistungslimits für Instanzen bieten. Ein zonaler abgestimmter nichtflüchtiger Speicher hat beispielsweise ein maximales Instanzlimit von 80.000 Schreib-IOPS, ein regionaler abgestimmter nichtflüchtiger Speicher jedoch ein Limit von 60.000 Schreib-IOPS.
Detaillierte Leistungslimits finden Sie unter Leistungslimits für zonale nichtflüchtige Speicher und Leistungslimits für regionale nichtflüchtige Speicher.
Mindestgröße von 200 GiB für regionale nichtflüchtige Standardspeicher: Regionale nichtflüchtige Standardspeicher haben eine Mindestgröße von 200 GiB. Wenn Sie also einen regionalen Klon eines zonalen nichtflüchtigen Standard-Speichervolumes mit einer Größe von 10 bis 199 GiB erstellen möchten, müssen Sie für den regionalen Speicher eine Größe von mindestens 200 GiB angeben.
Unterstützte Laufwerkstypen
Sie können alle Persistent Disk- und Hyperdisk-Typen klonen, wenn sich der Klon am selben Standort (Zone oder Region) wie das Quelllaufwerk befindet.
Das Klonen eines zonalen Laufwerks in ein regionales Laufwerk wird nur für die folgenden Laufwerkstypen unterstützt:
Google Cloud Hyperdisk:
- Hyperdisk Balanced
- Hyperdisk Extrem
Wenn Sie ein regionales Laufwerk aus einem Hyperdisk ML- oder Hyperdisk Throughput-Volume erstellen möchten, erstellen Sie einen Snapshot und dann ein Hyperdisk Balanced High Availability-Volume aus dem Snapshot.
Persistent Disk:
- Abgestimmter nichtflüchtiger Speicher
- Nichtflüchtiger SSD-Speicher
- Nichtflüchtiger Standardspeicher
Beschränkungen
Für Festplattenklone gelten die folgenden Einschränkungen:
- Sie können kein Hyperdisk Balanced High Availability-Volume erstellen, indem Sie ein zonales Hyperdisk ML- oder Hyperdisk Throughput-Volume klonen. Wenn Sie ein Hyperdisk Balanced High Availability-Volume für diese Hyperdisk-Typen erstellen möchten, führen Sie die Schritte unter Zonales Laufwerk in ein regionales Hyperdisk Balanced High Availability-Volume ändern aus.
- Sie können kein Laufwerk klonen, das sich in einem Speicherpool befindet.
- Sie können keinen zonalen Laufwerksklon eines vorhandenen zonalen Laufwerks in einer anderen Zone erstellen.
- Die Größe des Klons muss mindestens die Größe des Quelllaufwerks haben. Wenn Sie einen Klon mit der Google Cloud Konsole erstellen, können Sie keine Laufwerkgröße angeben. Der Klon hat dieselbe Größe wie das Quelllaufwerk.
- Wenn Sie ein Hyperdisk- oder Persistent Disk-Volume über die Google Cloud Konsole klonen, können Sie die bereitgestellte Leistung für die geklonte Festplatte nicht angeben.
- Wenn Sie das Quelllaufwerk mit einem vom Kunden bereitgestellten Verschlüsselungsschlüssel (Customer-Supplied Encryption Key, CSEK) oder einem kundenverwalteten Verschlüsselungsschlüssel (Customer-Managed Encryption Key, CMEK) verschlüsseln, müssen Sie denselben Schlüssel auch zum Verschlüsseln des Klons verwenden. Weitere Informationen finden Sie unter Klon eines verschlüsselten Quelllaufwerks erstellen.
- Sie können das Quelllaufwerk nicht löschen, während sein Klon erstellt wird.
- Die Compute-Instanz, an die das Quelllaufwerk angehängt ist, kann während der Erstellung des Klons nicht eingeschaltet werden.
- Wenn das Quelllaufwerk zum Löschen zusammen mit der VM markiert wurde, an die es angehängt ist, können Sie die VM nicht löschen, während der Klon erstellt wird.
- Pro 30 Sekunden können Sie maximal einen Klon eines bestimmten Quelllaufwerks oder seiner Klone erstellen.
- Es kann maximal 1.000 gleichzeitige Laufwerkklone eines bestimmten Quelllaufwerks (oder von dessen Klonen) geben.
Bei Überschreiten dieses Limits wird ein
internalErrorzurückgegeben. Wenn Sie jedoch einen Laufwerkklon erstellen und später löschen, wird der gelöschte Laufwerkklon nicht für dieses Limit berücksichtigt. - Nachdem ein Laufwerk geklont wurde, werden alle nachfolgenden Klone dieses Laufwerks oder seiner Klone auf das Limit von 1.000 gleichzeitigen Laufwerkklonen für das ursprüngliche Quelllaufwerk und auf das Limit für die Erstellung von höchstens einem Klon alle 30 Sekunden angerechnet.
- Wenn Sie einen regionalen nichtflüchtigen Speicher durch Klonen eines zonalen Laufwerks erstellen, können Sie alle 15 Minuten höchstens 1 TiB Kapazität klonen, mit einem Burst-Anfragelimit von 257 TiB.
- Sie können keinen zonalen Laufwerksklon aus einem regionalen Laufwerk erstellen.
- Zum Erstellen eines regionalen Laufwerkklons aus einem zonalen Quelllaufwerk muss eine der Replikatzonen des regionalen Laufwerkklons der Zone des Quelllaufwerks entsprechen.
- Nach der Erstellung kann ein regionaler Laufwerkklon innerhalb von durchschnittlich 3 Minuten verwendet werden. Es kann jedoch einige Minuten dauern, bis das Laufwerk vollständig repliziert wurde und einen Status erreicht, in dem das Recovery Point Objective (RPO) fast null erreicht.
- Wenn Sie ein zonales Laufwerk aus einem Image erstellt haben, können Sie dieses zonale Laufwerk nicht zum Erstellen eines regionalen Laufwerksklons verwenden.
Fehlermeldungen
Wenn Sie das Limit für das Klonen überschreiten, schlägt die Anfrage mit folgendem Fehler fehl:
RATE LIMIT: ERROR: (gcloud.compute.disks.create) Could not fetch resource: - Operation rate exceeded for resource RESOURCE. Too frequent operations from the source resource.
Laufwerkklone erstellen
In diesem Abschnitt wird erläutert, wie Sie ein vorhandenes Laufwerk duplizieren und einen Laufwerksklon erstellen.
Eine detaillierte Anleitung finden Sie je nach Art des Laufwerkklons in einem der folgenden Abschnitte in diesem Dokument:
- Wenn Sie ein Laufwerk für schnelle Tests, Fehlerbehebung oder Skalierung klonen möchten, erstellen Sie einen Laufwerkklon am selben Standort wie die Quelle.
- Um ein zonales Laufwerk hochverfügbar zu machen, erstellen Sie einen regionalen Laufwerksklon aus einem zonalen Laufwerk.
- Klon eines verschlüsselten Quelllaufwerks erstellen
Laufwerkklon am selben Speicherort wie die Quelle erstellen
Sie können einen Klon einer vorhandenen zonalen oder regionalen Festplatte erstellen, die sich in derselben Zone bzw. Region wie die Quellfestplatte befindet. Dazu können Sie dieGoogle Cloud Console, die Google Cloud CLI, REST oder Cloud-Clientbibliotheken verwenden.
Google Cloud Console
Rufen Sie in der Google Cloud Console die Seite Laufwerke auf.
Suchen Sie in der Liste der Laufwerke nach dem Laufwerk, das Sie klonen möchten.
Klicken Sie in der Spalte Aktionen auf die Menüschaltfläche und wählen Sie Laufwerk klonen aus.
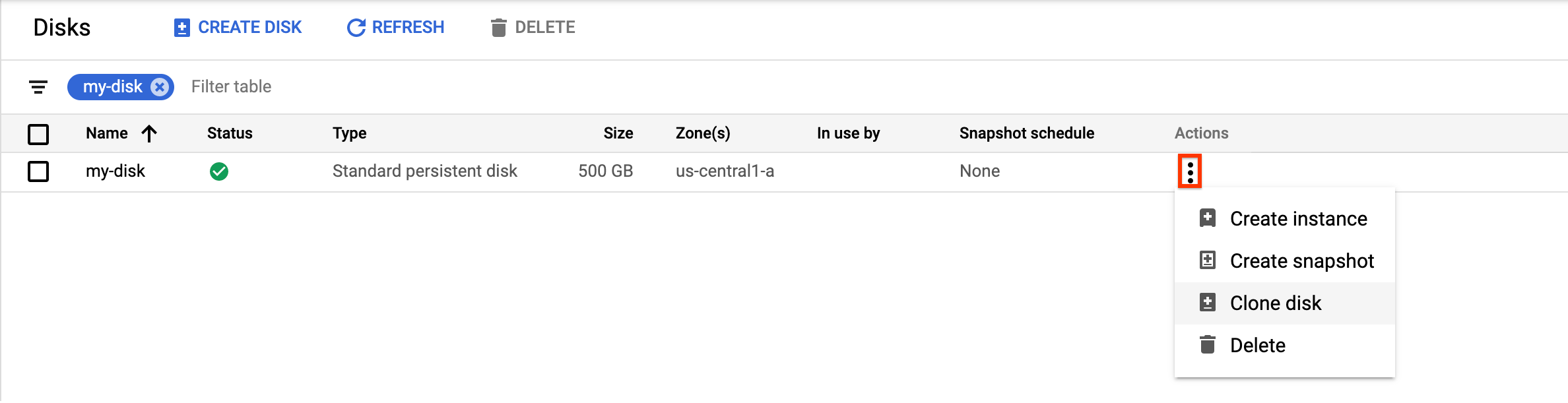
Führen Sie im angezeigten Bereich Laufwerk klonen die folgenden Schritte aus:
- Geben Sie im Feld Name einen Namen für das geklonte Laufwerk ein.
- Optional: Prüfen Sie bei zonalen Laufwerken unter Standort, ob Einzelne Zone ausgewählt ist.
- Prüfen Sie unter Attribute die anderen Details für das geklonte Laufwerk.
- Klicken Sie auf Erstellen, um die Erstellung des geklonten Laufwerks abzuschließen.
Google Cloud CLI
Führen Sie den Befehl disks create aus und geben Sie das Flag --source-disk an, um ein zonales Quelllaufwerk zu klonen und ein neues zonales Laufwerk zu erstellen:
gcloud compute disks create TARGET_DISK_NAME \
--description="cloned disk" \
--source-disk=projects/PROJECT_ID/zones/ZONE/disks/SOURCE_DISK_NAME
Ersetzen Sie Folgendes:
TARGET_DISK_NAME: Name des neuen Laufwerks.PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.ZONE: Zone des Quelllaufwerks und des neuen Laufwerks.SOURCE_DISK_NAME: der Name des Quelllaufwerks.
Terraform
Verwenden Sie zum Erstellen eines Laufwerkklons die Ressource google_compute_disk.
Informationen zum Anwenden oder Entfernen einer Terraform-Konfiguration finden Sie unter Grundlegende Terraform-Befehle.
Go
Go
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Go in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Go API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Java
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Java in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Java API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Python
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Python in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Python API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
REST
Senden Sie zum Klonen eines zonalen Quelllaufwerks und zum Erstellen eines neuen zonalen Laufwerks eine POST-Anfrage an die Methode compute.disks.insert.
Geben Sie im Anfragetext die Parameter name und sourceDisk an. Alle nicht angegebenen Attribute werden im Klon vom Quelllaufwerk übernommen.
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/disks
{
"name": "TARGET_DISK_NAME"
"sourceDisk": "projects/PROJECT_ID/zones/ZONE/disks/SOURCE_DISK_NAME"
}
Ersetzen Sie Folgendes:
PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.ZONE: Zone des Quelllaufwerks und des neuen Laufwerks.TARGET_DISK_NAME: Name des neuen Laufwerks.SOURCE_DISK_NAME: Name des Quelllaufwerks.
Regionalen Laufwerkklon aus einem zonalen Laufwerk erstellen
Sie können ein neues regionales Laufwerk erstellen, indem Sie ein vorhandenes zonales Laufwerk eines der folgenden Typen klonen:
- Hyperdisk Balanced
- Hyperdisk Extrem
- Nichtflüchtiger Standardspeicher, abgestimmter nichtflüchtiger Speicher und nichtflüchtiger SSD-Speicher
Wenn das Quelllaufwerk ein Hyperdisk Balanced- oder Hyperdisk Extreme-Volume ist, ist das regionale Laufwerk immer ein Hyperdisk Balanced High Availability-Volume und übernimmt nicht die bereitgestellte Leistung des zonalen Laufwerks. Wenn Sie die bereitgestellte Leistung des regionalen Laufwerks festlegen möchten, müssen Sie das Laufwerk mit der Google Cloud CLI oder REST klonen. Wenn Sie das Laufwerk mit der Google Cloud Konsole klonen, können Sie kein Leistungslimit angeben. Das Laufwerk wird mit den Standardlimits für seine Größe bereitgestellt.
Console
Rufen Sie in der Google Cloud Console die Seite Laufwerke auf.
Suchen Sie in der Liste der Laufwerke nach dem zonalen Persistent Disk-Volume, das Sie klonen möchten.
Klicken Sie in der Spalte Aktionen auf die Menüschaltfläche und wählen Sie Laufwerk klonen aus.
Führen Sie im angezeigten Bereich Laufwerk klonen die folgenden Schritte aus:
- Geben Sie im Feld Name einen Namen für das geklonte Laufwerk ein.
- Wählen Sie als Standort die Option Regional und dann die sekundäre Replikatzone für das neue regionale geklonte Laufwerk aus.
- Prüfen Sie unter Attribute die anderen Details für das geklonte Laufwerk.
- Klicken Sie auf Erstellen, um die Erstellung des geklonten Laufwerks abzuschließen.
gcloud
Führen Sie den Befehl gcloud compute disks create aus und geben Sie die Parameter --region und --replica-zones an, um einen regionalen Laufwerkklon aus einem zonalen Laufwerk zu erstellen.
Wenn das zonale Laufwerk ein Hyperdisk Balanced- oder Hyperdisk Extreme-Volume ist, geben Sie das Flag --disk-type=hyperdisk-balanced-high-availability an, da das regionale Laufwerk ein Hyperdisk Balanced High Availability-Volume sein muss.
Wenn Sie ein Persistent Disk-Volume klonen möchten, lassen Sie das Flag --disk-type weg.
gcloud compute disks create TARGET_DISK_NAME \ --description="zonal to regional cloned disk" \ --region=CLONED_REGION \ --source-disk=SOURCE_DISK_NAME \ --source-disk-zone=SOURCE_DISK_ZONE \ --replica-zones=SOURCE_DISK_ZONE,REPLICA_ZONE_2 \ --project=PROJECT_ID \ [ --disk-type=hyperdisk-balanced-high-availability ] \ [ --provisioned-iops=IOPS_LIMIT ] \ [ --provisioned-throughput=THROUGHPUT_LIMIT ]
Ersetzen Sie Folgendes:
TARGET_DISK_NAME: Name des neuen regionalen Laufwerks.CLONED_REGION: die Region des Quelllaufwerks und des geklonten Laufwerks.SOURCE_DISK_NAME: Name des zonalen Laufwerks, das geklont werden soll.SOURCE_DISK_ZONE: die Zone für das Quelllaufwerk. Dies ist auch die erste Replikatzone für den regionalen Laufwerksklon.REPLICA_ZONE_2: die zweite Replikatzone für den neuen regionalen Laufwerksklon.PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.IOPS_LIMIT: Optional: Wenn Sie ein regionales Hyperdisk Balanced High Availability-Laufwerk erstellen möchten, können Sie eine Anzahl von IOPS angeben, die das Laufwerk verarbeiten kann,bis zu 100.000 IOPS.THROUGHPUT_LIMIT: Optional: Wenn Sie ein regionales Hyperdisk Balanced High Availability-Laufwerk erstellen möchten, können Sie den maximalen Durchsatz in MiB/s angeben, den das Laufwerk bereitstellen kann, bis zu 2.400 MiB/s.
Terraform
Verwenden Sie die folgende Ressource, um einen regionalen Laufwerkklon aus einem zonalen Laufwerk zu erstellen. Wenn das Quelllaufwerk ein Hyperdisk Balanced- oder Hyperdisk Extreme-Volume ist, setzen Sie das type-Argument auf hyperdisk-balanced-high-availability.
Informationen zum Anwenden oder Entfernen einer Terraform-Konfiguration finden Sie unter Grundlegende Terraform-Befehle.
Go
Go
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Go in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Go API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Java
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Java in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Java API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Python
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Python in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Python API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
REST
Senden Sie zum Erstellen eines regionalen Laufwerksklons aus einem zonalen Laufwerk eine POST-Anfrage an die Methode compute.disks.insert und geben Sie die Parameter sourceDisk und replicaZone an.
Wenn es sich bei dem zonalen Laufwerk um ein Hyperdisk Balanced- oder Hyperdisk Extreme-Volume handelt, fügen Sie das Feld type ein, um ein Hyperdisk Balanced High Availability-Volume zu erstellen.
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/regions/CLONED_REGION/disks
{
"name": "TARGET_DISK_NAME",
"sourceDisk": "projects/PROJECT_ID/zones/SOURCE_DISK_ZONE/disks/SOURCE_DISK_NAME",
"replicaZone": "SOURCE_DISK_ZONE,REPLICA_ZONE_2",
"type": "projects/PROJECT_ID/regions/CLONED_REGION/diskTypes/hyperdisk-balanced-high-availability",
"provisionedIops": "IOPS_LIMIT",
"provisionedThroughput": "THROUGHPUT_LIMIT"
}
Ersetzen Sie Folgendes:
PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.TARGET_DISK_NAME: Name des neuen regionalen Laufwerks.CLONED_REGION: die Region des Quelllaufwerks und des geklonten Laufwerks.SOURCE_DISK_NAME: Name des zonalen Laufwerks, das geklont werden soll.SOURCE_DISK_ZONE: die Zone für das Quelllaufwerk. Dies ist auch die erste Replikatzone für den regionalen Laufwerksklon.REPLICA_ZONE_2: die zweite Replikatzone für den neuen regionalen Laufwerksklon.IOPS_LIMIT: Optional: Wenn Sie ein regionales Hyperdisk Balanced High Availability-Laufwerk erstellen möchten, können Sie eine Anzahl von IOPS angeben, die das Laufwerk verarbeiten kann,bis zu 100.000 IOPS.THROUGHPUT_LIMIT: Optional: Wenn Sie ein regionales Hyperdisk Balanced High Availability-Laufwerk erstellen möchten, können Sie den maximalen Durchsatz in MiB/s angeben, den das Laufwerk bereitstellen kann, bis zu 2.400 MiB/s.
Laufwerkklon eines CMEK- oder CSEK-verschlüsselten Quelllaufwerks erstellen
Wenn Sie einen zonalen oder regionalen Klon eines mit CSEK oder CMEK verschlüsselten Laufwerks erstellen möchten, folgen Sie der Anleitung in den vorherigen Abschnitten. Sie müssen jedoch auch den Schlüssel angeben, der zum Verschlüsseln des Quelllaufwerks verwendet wurde.
Laufwerkklone für CSEK-verschlüsselte Laufwerke erstellen
Wenn Sie das Quelllaufwerk mit einem CSEK verschlüsseln, müssen Sie denselben Schlüssel auch zum Verschlüsseln des Klons verwenden.
Console
Rufen Sie in der Google Cloud Console die Seite Laufwerke auf.
Suchen Sie in der Liste der zonalen nichtflüchtigen Laufwerke nach dem Laufwerk, das Sie klonen möchten.
Klicken Sie in der Spalte Aktionen auf die Menüschaltfläche und wählen Sie Laufwerk klonen aus.
Führen Sie im angezeigten Bereich Laufwerk klonen die folgenden Schritte aus:
- Geben Sie im Feld Name einen Namen für das geklonte Laufwerk ein.
- Geben Sie im Feld Entschlüsselung und Verschlüsselung den Verschlüsselungsschlüssel des Quelllaufwerks an.
- Prüfen Sie unter Attribute die anderen Details für das geklonte Laufwerk.
- Klicken Sie auf Erstellen, um die Erstellung des geklonten Laufwerks abzuschließen.
gcloud
Führen Sie den Befehl gcloud compute disks create aus und geben Sie den Verschlüsselungsschlüssel des Quelllaufwerks mit dem Flag --csek-key-file an, um einen Laufwerkklon für ein CSEK-verschlüsseltes Quelllaufwerk zu erstellen. Wenn Sie einen mit RSA verpackten Schlüssel verwenden, nutzen Sie den Befehl gcloud beta compute disks create.
gcloud compute disks create TARGET_DISK_NAME \ --description="cloned disk" \ --source-disk=projects/PROJECT_ID/zones/ZONE/disks/SOURCE_DISK_NAME \ --csek-key-file example-key-file.json
Ersetzen Sie Folgendes:
TARGET_DISK_NAME: Name des neuen Laufwerks.PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.ZONE: Zone des Quelllaufwerks und des neuen Laufwerks.SOURCE_DISK_NAME: Name des Quelllaufwerks.
Go
Go
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Go in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Go API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Java
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Java in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Java API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Python
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Python in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Python API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
REST
Um einen Laufwerkklon für ein CSEK-verschlüsseltes Quelllaufwerk zu erstellen, senden Sie eine POST-Anfrage an die Methode compute.disks.insert und geben Sie den Verschlüsselungsschlüssel des Quelllaufwerks mit dem Attribut diskEncryptionKey an. Wenn Sie einen mit RSA verpackten Schlüssel verwenden, nutzen Sie die beta-Version der Methode.
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/disks
{
"name": "TARGET_DISK_NAME"
"sourceDisk": "projects/PROJECT_ID/zones/ZONE/disks/SOURCE_DISK_NAME"
"diskEncryptionKey": {
"rsaEncryptedKey": "ieCx/NcW06PcT7Ep1X6LUTc/hLvUDYyzSZPPVCVPTVEohpeHASqC8uw5TzyO9U+Fka9JFHz0mBibXUInrC/jEk014kCK/NPjYgEMOyssZ4ZINPKxlUh2zn1bV+MCaTICrdmuSBTWlUUiFoDD6PYznLwh8ZNdaheCeZ8ewEXgFQ8V+sDroLaN3Xs3MDTXQEMMoNUXMCZEIpg9Vtp9x2oeQ5lAbtt7bYAAHf5l+gJWw3sUfs0/Glw5fpdjT8Uggrr+RMZezGrltJEF293rvTIjWOEB3z5OHyHwQkvdrPDFcTqsLfh+8Hr8g+mf+7zVPEC8nEbqpdl3GPv3A7AwpFp7MA=="
},
}
Ersetzen Sie Folgendes:
PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.ZONE: Zone des Quelllaufwerks und des neuen Laufwerks.TARGET_DISK_NAME: Name des neuen Laufwerks.SOURCE_DISK_NAME: Name des Quelllaufwerks.
Laufwerkklone für CMEK-verschlüsselte Laufwerke erstellen
Wenn Sie das Quelllaufwerk mit einem CMEK verschlüsseln, müssen Sie denselben Schlüssel auch zum Verschlüsseln des Klons verwenden.
Console
Compute Engine verschlüsselt den Klon automatisch mit dem Verschlüsselungsschlüssel des Quelllaufwerks.
gcloud
Führen Sie den Befehl gcloud compute disks create aus und geben Sie den Verschlüsselungsschlüssel des Quelllaufwerks mit dem Flag --kms-key an, um einen Laufwerksklon für ein CMEK-verschlüsseltes Quelllaufwerk zu erstellen.
Wenn Sie einen mit RSA verpackten Schlüssel verwenden, nutzen Sie den Befehl gcloud beta compute disks create.
gcloud compute disks create TARGET_DISK_NAME \ --description="cloned disk" \ --source-disk=projects/PROJECT_ID/zones/ZONE/disks/SOURCE_DISK_NAME \ --kms-key projects/KMS_PROJECT_ID/locations/REGION/keyRings/KEY_RING/cryptoKeys/KEY
Ersetzen Sie Folgendes:
TARGET_DISK_NAME: Name des neuen Laufwerks.PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.ZONE: Zone des Quelllaufwerks und des neuen Laufwerks.SOURCE_DISK_NAME: der Name des Quelllaufwerks.KMS_PROJECT_ID: Projekt-ID für den Verschlüsselungsschlüssel.REGION: Region des Verschlüsselungsschlüssels.KEY_RING: Schlüsselbund des Verschlüsselungsschlüssels.KEY: Name des Verschlüsselungsschlüssels.
Go
Go
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Go in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Go API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Java
Java
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Java in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Java API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
Python
Python
Bevor Sie dieses Beispiel verwenden, folgen Sie den Schritten zur Einrichtung von Python in der Compute Engine-Kurzanleitung zur Verwendung von Clientbibliotheken. Weitere Informationen finden Sie in der Referenzdokumentation zur Compute Engine Python API.
Richten Sie die Standardanmeldedaten für Anwendungen ein, um sich bei der Compute Engine zu authentifizieren. Weitere Informationen finden Sie unter Authentifizierung für Clientbibliotheken einrichten.
REST
Um einen Laufwerksklon für ein CMEK-verschlüsseltes Quelllaufwerk zu erstellen, senden Sie eine POST-Anfrage an die Methode compute.disks.insert und geben Sie den Verschlüsselungsschlüssel des Quelllaufwerks mit dem Attribut kmsKeyName an.
Wenn Sie einen mit RSA verpackten Schlüssel verwenden, nutzen Sie die beta-Version der Methode.
POST https://compute.googleapis.com/compute/v1/projects/PROJECT_ID/zones/ZONE/disks
{
"name": "TARGET_DISK_NAME"
"sourceDisk": "projects/PROJECT_ID/zones/ZONE/disks/SOURCE_DISK_NAME"
"diskEncryptionKey": {
"kmsKeyName": "projects/KMS_PROJECT_ID/locations/REGION/keyRings/KEY_RING/cryptoKeys/KEY"
},
}
Ersetzen Sie Folgendes:
PROJECT_ID: Die Projekt-ID, in der Sie das Laufwerk klonen möchten.ZONE: Zone des Quelllaufwerks und des neuen Laufwerks.TARGET_DISK_NAME: Name des neuen Laufwerks.SOURCE_DISK_NAME: der Name des Quelllaufwerks.KMS_PROJECT_ID: Projekt-ID für den Verschlüsselungsschlüssel.REGION: Region des Verschlüsselungsschlüssels.KEY_RING: Schlüsselbund des Verschlüsselungsschlüssels.KEY: Name des Verschlüsselungsschlüssels.
Nächste Schritte
- Laufwerke regelmäßig mit Standard-Snapshots sichern, um unbeabsichtigte Datenverluste zu vermeiden
- Laufwerke mit Instant Snapshots sichern
- Regionale nichtflüchtige Laufwerke für die synchrone Replikation zwischen zwei Zonen nutzen.
- Weitere Informationen zur asynchronen Replikation