
Trabalhar com funções definidas pelo usuário em Python
Com uma função definida pelo usuário (UDF) do Python, é possível implementar uma função escalar em Python e usá-la em uma consulta SQL. As UDFs em Python são semelhantes às UDFs em SQL e JavaScript, mas com recursos adicionais. As UDFs do Python permitem instalar bibliotecas de terceiros do índice de pacotes do Python (PyPI) e acessar serviços externos usando uma conexão a recursos do Cloud.
As UDFs em Python são criadas e executadas em recursos gerenciados do BigQuery.
Limitações
python-3.11é o único ambiente de execução compatível.- Não é possível criar uma UDF temporária em Python.
- Não é possível usar uma UDF do Python com uma visualização materializada.
- Os resultados de uma consulta que chama uma UDF em Python não são armazenados em cache porque o valor de retorno de uma UDF em Python é sempre considerado não determinístico.
- Assured Workloads não é compatível.
- Estes tipos de dados não são aceitos:
JSON,RANGE,INTERVALeGEOGRAPHY. - Os contêineres que executam UDFs do Python só podem ser configurados com até 4 vCPU e 16 GiB.
- Não é possível criptografar o código de UDF em Python com chaves de criptografia gerenciadas pelo cliente (CMEK).
- As UDFs em Python são compatíveis com o VPC Service Controls, mas as redes VPC não são.
Funções exigidas
Os papéis necessários do IAM dependem de você ser proprietário ou usuário de uma UDF do Python.
Proprietários UDF
Normalmente, o proprietário de uma UDF em Python cria ou atualiza uma UDF. Outras funções também são necessárias se você criar uma UDF em Python que faça referência a uma conexão a recursos do Cloud.
Essa conexão só é necessária se a UDF usar a cláusula
WITH CONNECTION para acessar
um serviço externo.
Para receber as permissões necessárias para criar ou atualizar uma UDF em Python, peça ao administrador que conceda a você os seguintes papéis do IAM:
- Editor de dados do BigQuery (
roles/bigquery.dataEditor) no conjunto de dados - Usuário de jobs do BigQuery (
roles/bigquery.jobUser) no projeto - Administrador de conexão do BigQuery (
roles/bigquery.connectionAdmin) no projeto
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Esses papéis predefinidos contêm as permissões necessárias para criar ou atualizar uma UDF em Python. Para acessar as permissões exatas necessárias, expanda a seção Permissões necessárias:
Permissões necessárias
As seguintes permissões são necessárias para criar ou atualizar uma UDF em Python:
-
Crie uma UDF do Python usando a instrução
CREATE FUNCTION:bigquery.routines.createno conjunto de dados -
Atualize uma UDF do Python usando a instrução
CREATE FUNCTION:bigquery.routines.updateno conjunto de dados -
Execute um job de consulta de instrução
CREATE FUNCTION:bigquery.jobs.createno projeto -
Crie uma conexão de recursos do Cloud:
bigquery.connections.createno projeto -
Use uma conexão na instrução
CREATE FUNCTION:bigquery.connections.delegatena conexão
Essas permissões também podem ser concedidas com funções personalizadas ou outros papéis predefinidos.
Para mais informações sobre os papéis no BigQuery, consulte Papéis predefinidos do IAM.
Usuários de UDF
Um usuário de UDF em Python invoca uma UDF criada por outra pessoa. Outras funções também são necessárias se você invocar uma UDF do Python que faz referência a uma conexão de recurso do Cloud.
Para receber as permissões necessárias para invocar uma UDF em Python criada por outra pessoa, peça ao administrador para conceder a você os seguintes papéis do IAM:
- Usuário do BigQuery (
roles/bigquery.user) no projeto - Leitor de dados do BigQuery (
roles/bigquery.dataViewer) no conjunto de dados - Usuário de conexão do BigQuery (
roles/bigquery.connectionUser) na conexão
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Esses papéis predefinidos contêm as permissões necessárias para invocar uma UDF em Python criada por outra pessoa. Para acessar as permissões exatas necessárias, expanda a seção Permissões necessárias:
Permissões necessárias
As seguintes permissões são necessárias para invocar uma UDF em Python criada por outra pessoa:
-
Para executar um job de consulta que faz referência a uma UDF em Python:
bigquery.jobs.createno projeto -
Para invocar uma UDF em Python criada por outra pessoa:
bigquery.routines.getno conjunto de dados -
Para executar uma UDF em Python que faz referência a uma conexão a recursos do Cloud:
bigquery.connections.usena conexão
Essas permissões também podem ser concedidas com funções personalizadas ou outros papéis predefinidos.
Para mais informações sobre os papéis no BigQuery, consulte Papéis predefinidos do IAM.
Criar uma UDF Python permanente
Siga estas regras ao criar uma UDF em Python:
O corpo da UDF em Python precisa ser um literal de string entre aspas que representa o código Python. Para saber mais sobre literais de string entre aspas, consulte Formatos para literais entre aspas.
O corpo da UDF em Python precisa incluir uma função Python usada no argumento
entry_pointna lista de opções da UDF em Python.Uma versão do ambiente de execução do Python precisa ser especificada na opção
runtime_version. A única versão compatível do ambiente de execução do Python épython-3.11. Para uma lista completa das opções disponíveis, consulte a Lista de opções de função para a instruçãoCREATE FUNCTION.
Para criar uma UDF permanente em Python, use a instrução CREATE FUNCTION
sem a palavra-chave TEMP ou TEMPORARY. Para excluir uma UDF Python permanente, use a instrução DROP FUNCTION.
Exemplo
Para ver um exemplo de como criar uma UDF permanente em Python, escolha uma das seguintes opções:
Console
O exemplo a seguir cria uma UDF em Python permanente chamada multiplyInputs
e a chama de dentro de uma instrução SELECT:
Acessar a página do BigQuery.
No editor de consultas, insira a seguinte instrução
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyInputs(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="multiply") AS r''' def multiply(x, y): return x * y '''; -- Call the Python UDF. WITH numbers AS (SELECT 1 AS x, 5 as y UNION ALL SELECT 2 AS x, 10 as y UNION ALL SELECT 3 as x, 15 as y) SELECT x, y, `PROJECT_ID.DATASET_ID`.multiplyInputs(x, y) AS product FROM numbers;
Substitua PROJECT_ID.DATASET_ID com o ID do projeto e do conjunto de dados.
Clique em Executar.
Este exemplo produz a saída a seguir:
+-----+-----+--------------+ | x | y | product | +-----+-----+--------------+ | 1 | 5 | 5.0 | | 2 | 10 | 20.0 | | 3 | 15 | 45.0 | +-----+-----+--------------+
BigQuery DataFrames
O exemplo a seguir usa o BigQuery DataFrames para transformar uma função personalizada em uma UDF do Python:
Status da criação do contêiner
Quando você cria uma UDF em Python usando a instrução CREATE FUNCTION,
o BigQuery cria ou atualiza uma imagem do contêiner com base em uma
imagem de base. O contêiner é criado na imagem de base usando seu código e as dependências de pacote especificadas.
A criação do contêiner é um processo de longa duração. A primeira consulta depois de executar
a instrução CREATE FUNCTION aguarda a conclusão do build da imagem. Se não houver dependências externas, a imagem do contêiner será criada em menos de um minuto.
O tamanho de todos os contêineres de UDF em Python por projeto e região é restrito a um total de 10 GiB. Para mais informações, consulte Limites de funções definidas pelo usuário para UDFs permanentes. A criação do contêiner falha se o projeto atingiu a cota.
Para conferir o status do build do contêiner, escolha uma das seguintes opções:
Console
Acesse a página do Studio do BigQuery.
No painel à esquerda, expanda o projeto e clique em Conjuntos de dados.
Clique no link para abrir o conjunto de dados que contém sua UDF em Python.
Na página do conjunto de dados, clique na guia Rotinas.
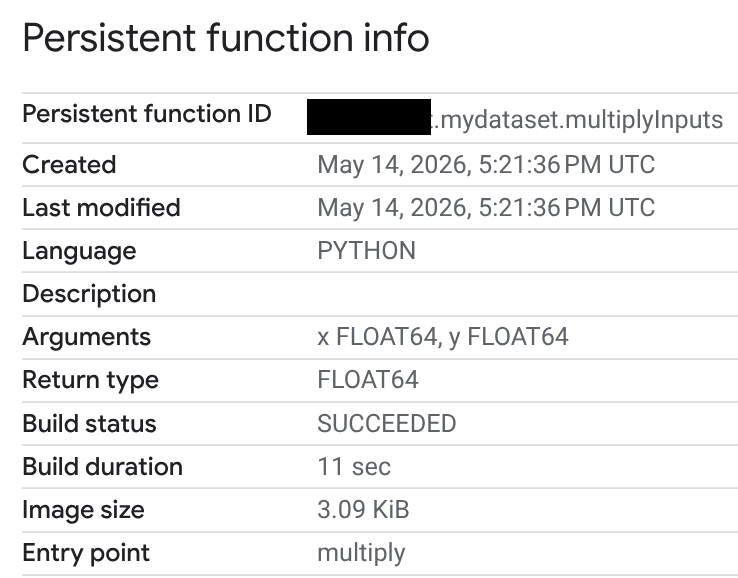
Na coluna ID da rotina, clique na sua UDF em Python.
Na página Informações da função permanente, é possível conferir o status e a duração da build, além do tamanho da imagem. O status do build é um dos seguintes:
- Em andamento
- Concluído
- Falha
Se um build falhar, a página de informações da função vai fornecer mensagens de erro detalhadas para que você possa resolver problemas como erros de sintaxe ou problemas na instalação de pacotes externos.
SQL
Para consultar os campos de status do build na visualização INFORMATION_SCHEMA.ROUTINES, siga estas etapas:
Acesse a página do Studio do BigQuery.
Mude para o editor de consultas ou clique em Consulta SQL.
Insira a consulta a seguir para extrair os campos
BUILD_STATUSda visualizaçãoINFORMATION_SCHEMA.ROUTINES. A colunaBUILD_STATUSé um tipoSTRUCTno GoogleSQL:SELECT build_status.* FROM `PROJECT_ID.DATASET_ID`.INFORMATION_SCHEMA.ROUTINES;Substitua PROJECT_ID.DATASET_ID com o ID do projeto e do conjunto de dados.
Os resultados terão a seguinte aparência: Os campos de erro são omitidos:
+---------------+--------------------------------+------------------------+------------------+ | build_state | build_state_update_time | build_duration_seconds | image_size_bytes | +---------------+--------------------------------+------------------------+------------------+ | SUCCEEDED | 2026-05-14 17:21:49.736000 UTC | 11 | 3167 | +---------------+--------------------------------+------------------------+------------------+
API
Confira o status da build do contêiner usando RoutineBuildStatus na API.
Criar uma UDF Python vetorizada
É possível implementar sua UDF em Python para processar um lote de linhas em vez de uma única linha usando a vetorização. A vetorização pode melhorar o desempenho da consulta. É possível criar uma UDF vetorizada usando Pandas ou Apache Arrow.
Para controlar o comportamento de agrupamento em lotes, especifique o número máximo de linhas em cada lote usando a opção max_batching_rows na lista de opções CREATE OR REPLACE FUNCTION. Se você especificar max_batching_rows, o BigQuery vai determinar o número de linhas em um lote, até o limite de max_batching_rows.
Se max_batching_rows não for especificado, o número de linhas a serem agrupadas será determinado automaticamente.
Usar o Pandas
Uma UDF Python vetorizada tem um único argumento pandas.DataFrame que precisa ser anotado. O argumento pandas.DataFrame tem o mesmo número de colunas que os parâmetros da UDF do Python definidos na instrução CREATE FUNCTION. Os nomes das colunas no argumento pandas.DataFrame são os mesmos dos parâmetros da UDF.
Sua função precisa retornar um pandas.Series ou um pandas.DataFrame de coluna única com o mesmo número de linhas da entrada.
O exemplo a seguir cria uma UDF Python vetorizada chamada multiplyInputs
com dois parâmetros: x e y:
Acessar a página do BigQuery.
No editor de consultas, insira a seguinte instrução
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorized(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS(runtime_version="python-3.11", entry_point="vectorized_multiply") AS r''' import pandas as pd def vectorized_multiply(df: pd.DataFrame): return df['x'] * df['y'] ''';
Substitua PROJECT_ID.DATASET_ID com o ID do projeto e do conjunto de dados.
Chamar a UDF é o mesmo que no exemplo anterior.
Clique em Executar.
Usar o Apache Arrow
O exemplo a seguir usa a interface RecordBatch do Apache Arrow. Ao usar a interface RecordBatch, a função transmite um lote de linhas de colunas de igual comprimento ao ponto de entrada.
O exemplo a seguir usa o Apache Arrow para criar uma UDF Python vetorizada chamada multiplyVectorizedArrow.
Acessar a página do BigQuery.
No editor de consultas, insira a seguinte instrução
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.multiplyVectorizedArrow(x FLOAT64, y FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS( runtime_version="python-3.11", entry_point="vectorized_multiply_arrow" ) AS r''' import pyarrow as pa import pyarrow.compute as pc def vectorized_multiply_arrow(batch: pa.RecordBatch): # Access columns directly from the Arrow RecordBatch x = batch.column('x') y = batch.column('y') # Use pyarrow.compute for vectorized operations return pc.multiply(x, y) ''';
Substitua PROJECT_ID.DATASET_ID com o ID do projeto e do conjunto de dados.
Chamar a UDF é o mesmo que nos exemplos anteriores.
Clique em Executar.
Chamar uma UDF em Python
Se você tiver permissão para invocar uma UDF em Python, poderá chamá-la como qualquer
outra função. Para usar uma função definida em um projeto diferente, use o nome totalmente qualificado dela. Por exemplo, para chamar uma função de extração de XML
chamada cw_xml_extract
em outro projeto, siga estas etapas.
Console
Acessar a página do BigQuery.
No editor de consultas, insira o seguinte exemplo:
SELECT `PROJECT_ID.DATASET_ID`.`cw_xml_extract`(xml, '//title/text()') AS `title` FROM UNNEST([ STRUCT('''<book id="1"> <title>The Great Gatsby</title> <author>F. Scott Fitzgerald</author> </book>''' AS xml), STRUCT('''<book id="2"> <title>1984</title> <author>George Orwell</author> </book>''' AS xml), STRUCT('''<book id="3"> <title>Brave New World</title> <author>Aldous Huxley</author> </book>''' AS xml) ])Clique em Executar.
Este exemplo produz a saída a seguir:
+--------------------------+ | title | +--------------------------+ | The Great Gatsby | | 1984 | | Brave New World | +--------------------------+
BigQuery DataFrames
O exemplo a seguir usa os métodos BigQuery
DataFrames
sql_scalar,
read_gbq_function,
e
apply
para chamar uma UDF em Python:
Tipos de dados de UDF em Python compatíveis
A tabela a seguir define o mapeamento entre os tipos de dados do BigQuery, do Python e do Pandas:
| Tipo de dados do BigQuery | Tipo de dados integrado do Python usado pela UDF padrão. | Tipo de dados do Pandas usado pela UDF vetorizada | Tipo de dados PyArrow usado para ARRAY e STRUCT em UDF vetorizada. |
|---|---|---|---|
BOOL |
bool |
BooleanDtype |
DataType(bool) |
INT64 |
int |
Int64Dtype |
DataType(int64) |
FLOAT64 |
float |
FloatDtype |
DataType(double) |
STRING |
str |
StringDtype |
DataType(string) |
BYTES |
bytes |
binary[pyarrow] |
DataType(binary) |
TIMESTAMP |
Parâmetro de função: Valor de retorno da função: |
Parâmetro da função: Valor de retorno da função: |
TimestampType(timestamp[us]), com fuso horário |
DATE |
datetime.date |
date32[pyarrow] |
DataType(date32[day]) |
TIME |
datetime.time |
time64[pyarrow] |
Time64Type(time64[us]) |
DATETIME |
datetime.datetime (sem fuso horário) |
timestamp[us][pyarrow] |
TimestampType(timestamp[us]), sem fuso horário |
ARRAY |
list |
list<...>[pyarrow], em que o tipo de dados do elemento é um pandas.ArrowDtype |
ListType |
STRUCT |
dict |
struct<...>[pyarrow], em que o tipo de dados do campo é um pandas.ArrowDtype |
StructType |
Versões de ambiente de execução compatíveis
As UDFs do BigQuery em Python são compatíveis com o ambiente de execução python-3.11. Essa versão do Python inclui alguns pacotes pré-instalados adicionais. Para bibliotecas
do sistema, verifique a imagem de base do ambiente de execução.
| Versão do ambiente de execução | Versão do Python | Inclui |
|---|---|---|
| python-3.11 | Python 3.11 | numpy 1.26.3 pyarrow 14.0.2 pandas 2.1.4 python-dateutil 2.8.2 absl-py 2.0.0 pytz 2023.3.post1 tzdata 2023.4 six 1.16.0 |
Usar pacotes de terceiros
Use a lista de opções CREATE FUNCTION para usar módulos diferentes dos fornecidos pela biblioteca padrão do Python e pacotes pré-instalados.
É possível instalar pacotes do índice de pacotes do Python (PyPI) ou importar arquivos do Python do Cloud Storage.
Instalar um pacote do índice de pacotes do Python
Ao instalar um pacote, é necessário fornecer o nome dele e, opcionalmente, a versão usando especificadores de versão de pacote do Python.
Se o pacote estiver no ambiente de execução, ele será usado, a menos que uma versão específica seja especificada na lista de opções CREATE FUNCTION. Se uma versão do pacote
não for especificada e o pacote não estiver no ambiente de execução, a versão mais recente disponível
será usada. Somente pacotes com o formato binário wheels são compatíveis.
O exemplo a seguir mostra como criar uma UDF do Python que instala o pacote
scipy usando a lista de opções CREATE OR REPLACE FUNCTION:
Acessar a página do BigQuery.
No editor de consultas, insira a seguinte instrução
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.area(radius FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='area_handler', runtime_version='python-3.11', packages=['scipy==1.15.3']) AS r""" import scipy def area_handler(radius): return scipy.constants.pi*radius*radius """; SELECT `PROJECT_ID.DATASET_ID`.area(4.5);
Substitua PROJECT_ID.DATASET_ID com o ID do projeto e do conjunto de dados.
Clique em Executar.
Importar outros arquivos Python como bibliotecas
É possível estender suas UDFs do Python usando a lista de opções de função ao importar arquivos Python do Cloud Storage.
No código Python da sua UDF, é possível importar os arquivos do Cloud Storage como módulos usando a instrução "import" seguida pelo caminho do objeto do Cloud Storage. Por exemplo, se você estiver importando
gs://BUCKET_NAME/path/to/lib1.py, a instrução de importação será import
path.to.lib1.
O nome do arquivo Python precisa ser um identificador do Python. Cada nome de folder no nome do objeto (após o /) precisa ser um identificador Python válido. No intervalo ASCII (U+0001..U+007F), os seguintes caracteres podem ser usados em identificadores:
- Letras maiúsculas e minúsculas de A a Z.
- Sublinhados.
- Os dígitos de zero a nove, mas um número não pode aparecer como o primeiro caractere no identificador.
O exemplo a seguir mostra como criar uma UDF em Python que importa o pacote da biblioteca de cliente
lib1.py de um bucket do Cloud Storage chamado
my_bucket:
Acessar a página do BigQuery.
No editor de consultas, insira a seguinte instrução
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.myFunc(a FLOAT64, b STRING) RETURNS STRING LANGUAGE python OPTIONS ( entry_point='compute', runtime_version='python-3.11', library=['gs://BUCKET_NAME/PATH/lib1.py']) AS r""" import path.to.lib1 as lib1 def compute(a, b): # doInterestingStuff is a function defined in # gs://BUCKET_NAME/PATH/lib1.py return lib1.doInterestingStuff(a, b); """;
Substitua:
- PROJECT_ID: o ID do projeto.
- DATASET_ID: o ID do conjunto de dados.
- BUCKET_NAME: o nome do bucket do Cloud Storage que contém
lib1.py. - PATH: o caminho para o bucket do Cloud Storage.
Clique em Executar.
Configurar limites de contêiner para UDFs do Python
Use a lista de opções CREATE FUNCTION para especificar os limites de simultaneidade de solicitações de CPU, memória e contêineres para contêineres que executam UDFs em Python.
Por padrão, os contêineres recebem os seguintes recursos:
- A memória alocada é
512Mi. - A CPU alocada é de
1.0vCPU. - O limite de simultaneidade de solicitações de contêiner é
80.
O exemplo a seguir cria uma UDF do Python usando a lista de opções CREATE FUNCTION para especificar limites de contêiner:
Acessar a página do BigQuery.
No editor de consultas, insira a seguinte instrução
CREATE FUNCTION:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.square_area(length FLOAT64) RETURNS FLOAT64 LANGUAGE python OPTIONS (entry_point='square_area', runtime_version='python-3.11', container_memory='CONTAINER_MEMORY', container_cpu=CONTAINER_CPU, container_request_concurrency=CONTAINER_REQUEST_CONCURRENCY) AS r""" def square_area(length): return length*length """; SELECT `PROJECT_ID.DATASET_ID`.square_area(4.5);
Substitua:
- PROJECT_ID.DATASET_ID: o ID do projeto e do conjunto de dados.
- CONTAINER_MEMORY: o valor da memória no formato
<integer_number><unit>. A unidade precisa ser um destes valores:Mi(MiB),M(MB),Gi(GiB) ouG(GB). Por exemplo,2Gi. - CONTAINER_CPU: o valor da CPU. As UDFs em Python aceitam valores fracionários de CPU entre
0.33e1.0e valores não fracionários de CPU de1,2e4. - CONTAINER_REQUEST_CONCURRENCY: o número máximo de solicitações simultâneas por instância de contêiner de UDF do Python. O valor precisa ser um número inteiro de
1a1000.
Clique em Executar.
Valores de CPU compatíveis
As UDFs do Python são compatíveis com valores fracionários de CPU entre 0.33 e 1.0 e valores não fracionários de CPU de 1, 2 e 4. Os contêineres que executam UDFs do Python podem ser configurados com até 4 vCPUs. O valor padrão é 1.0. Os valores de entrada fracionários são arredondados para duas casas decimais antes de serem aplicados ao contêiner.
Valores de memória aceitos
Os contêineres de UDF do Python aceitam valores de memória no seguinte formato: <integer_number><unit>. A unidade precisa ser um destes valores: Mi, M, Gi e G. A quantidade mínima de memória que pode ser configurada é 256Mi. A quantidade máxima de memória que pode ser configurada é 16Gi.
Com base no valor de memória escolhido, você também precisa especificar uma quantidade adequada de CPU. A tabela a seguir mostra os valores mínimos e máximos de CPU para cada valor de memória:
| Memória | CPU mínima | CPU máxima |
|---|---|---|
256Mi a 512Mi |
0.33 |
2 |
Maior que 512Mi e menor ou igual a 1Gi |
0.5 |
2 |
Maior que 1Gi e menor que 2Gi |
1 |
2 |
2Gi a 4Gi |
1 |
4 |
Maior que 4Gi e até 8Gi |
2 |
4 |
Maior que 8Gi e até 16Gi |
4 |
4 |
Como alternativa, se você já determinou a quantidade de CPU que está alocando, use a tabela a seguir para determinar o intervalo de memória adequado:
| CPU | Memória mínima | Máximo de memória |
|---|---|---|
Menos de 0.5 |
256Mi |
512Mi |
0.5 para menos de 1 |
256Mi |
1Gi |
1 |
256Mi |
4Gi |
2 |
256Mi |
8Gi |
4 |
2Gi |
16Gi |
Chamar Google Cloud ou serviços on-line em código Python
Uma UDF em Python acessa um serviço Google Cloud ou um serviço externo usando a conta de serviço da conexão a recursos do Cloud. A conta de serviço da conexão precisa receber permissões para acessar o serviço. As permissões necessárias variam dependendo do serviço acessado e das APIs chamadas no seu código Python.
Se você criar uma UDF em Python sem usar uma conexão a recursos do Cloud, a função será executada em um ambiente que bloqueia o acesso à rede. Se a UDF acessar serviços on-line, crie-a com uma conexão de recursos do Cloud. Caso contrário, a UDF não poderá acessar a rede até que um tempo limite de conexão interna seja atingido. Ao usar uma conexão de recursos do Cloud, implemente o seguinte:
Tempos limite. Ao fazer chamadas de rede em uma UDF do Python, sempre inclua um tempo limite razoável. Isso evita que a UDF fique travada indefinidamente se o serviço externo demorar para responder ou estiver inacessível.
Use o tratamento de erros. Encapsule o código de chamada de rede em um bloco
try...exceptpara processar normalmente possíveis erros, como erros de conexão, tempos limite ou códigos de status de falha HTTP. Isso permite que a UDF retorne um erro significativo ou um valor substituto em vez de fazer com que a consulta falhe ou pare de responder.
O exemplo a seguir mostra como acessar o serviço Cloud Translation
de uma UDF do Python. Este exemplo tem dois projetos: um chamado my_query_project, em que você cria a UDF e a conexão a recursos do Cloud, e outro em que você executa o Cloud Translation, chamado my_translate_project.
Criar uma conexão a recursos do Cloud
Primeiro, crie uma conexão a recursos do Cloud em my_query_project. Para criar a conexão a recursos do Cloud, siga estas etapas.
Console
Acessar a página do BigQuery.
No painel à esquerda, clique em Explorer:

Se o painel esquerdo não aparecer, clique em Expandir painel esquerdo para abrir.
No painel Explorer, expanda o nome do projeto e clique em Conexões.
Na página Conexões, clique em Criar conexão.
Em Tipo de conexão, escolha Modelos remotos da Vertex AI, funções remotas, BigLake e Spanner (recurso do Cloud).
No campo ID da conexão, insira um nome para a conexão.
Em Tipo de local, selecione um local para sua conexão. A conexão precisa estar alocada com seus outros recursos, como conjuntos de dados.
Clique em Criar conexão.
Clique em Ir para conexão.
No painel Informações da conexão, copie o ID da conta de serviço para usar em uma etapa posterior.
SQL
Use a instrução CREATE CONNECTION:
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
CREATE CONNECTION [IF NOT EXISTS] `CONNECTION_NAME` OPTIONS ( connection_type = "CLOUD_RESOURCE", friendly_name = "FRIENDLY_NAME", description = "DESCRIPTION" );
Substitua:
-
CONNECTION_NAME: o nome da conexão no formatoPROJECT_ID.LOCATION.CONNECTION_ID,LOCATION.CONNECTION_IDouCONNECTION_ID. Se o projeto ou local for omitido, eles serão inferidos do projeto e do local em que a instrução é executada. -
FRIENDLY_NAME(opcional): um nome descritivo para a conexão. -
DESCRIPTION(opcional): uma descrição da conexão.
-
Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
bq
Em um ambiente de linha de comando, crie uma conexão:
bq mk --connection --location=REGION --project_id=PROJECT_ID \ --connection_type=CLOUD_RESOURCE CONNECTION_ID
O parâmetro
--project_idsubstitui o projeto padrão.Substitua:
REGION: sua região de conexãoPROJECT_ID: o ID do projeto do Google CloudCONNECTION_ID: um ID para sua conexão
Quando você cria um recurso de conexão, o BigQuery cria uma conta de serviço do sistema exclusiva e a associa à conexão.
Solução de problemas: se você receber o seguinte erro de conexão, atualize o SDK Google Cloud:
Flags parsing error: flag --connection_type=CLOUD_RESOURCE: value should be one of...
Recupere e copie o ID da conta de serviço para uso em uma etapa posterior:
bq show --connection PROJECT_ID.REGION.CONNECTION_ID
O resultado será o seguinte:
name properties 1234.REGION.CONNECTION_ID {"serviceAccountId": "connection-1234-9u56h9@gcp-sa-bigquery-condel.iam.gserviceaccount.com"}
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Python.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Node.js
Antes de testar esta amostra, siga as instruções de configuração do Node.js no Guia de início rápido do BigQuery: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API BigQuery em Node.js.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
Terraform
Use o
recurso
google_bigquery_connection.
Para autenticar no BigQuery, configure o Application Default Credentials. Para mais informações, acesse Configurar a autenticação para bibliotecas de cliente.
O exemplo a seguir cria uma conexão a recursos do Cloud chamada
my_cloud_resource_connection na região US:
Para aplicar a configuração do Terraform em um projeto Google Cloud , siga as etapas nas seções a seguir.
Preparar o Cloud Shell
- Inicie o Cloud Shell.
-
Defina o projeto Google Cloud padrão em que você quer aplicar as configurações do Terraform.
Você só precisa executar esse comando uma vez por projeto, e ele pode ser executado em qualquer diretório.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
As variáveis de ambiente serão substituídas se você definir valores explícitos no arquivo de configuração do Terraform.
Preparar o diretório
Cada arquivo de configuração do Terraform precisa ter o próprio diretório, também chamado de módulo raiz.
-
No Cloud Shell, crie um diretório e um novo
arquivo dentro dele. O nome do arquivo precisa ter a extensão
.tf, por exemplo,main.tf. Neste tutorial, o arquivo é chamado demain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
Se você estiver seguindo um tutorial, poderá copiar o exemplo de código em cada seção ou etapa.
Copie o exemplo de código no
main.tfrecém-criado.Se preferir, copie o código do GitHub. Isso é recomendado quando o snippet do Terraform faz parte de uma solução de ponta a ponta.
- Revise e modifique os parâmetros de amostra para aplicar ao seu ambiente.
- Salve as alterações.
-
Inicialize o Terraform. Você só precisa fazer isso uma vez por diretório.
terraform init
Opcionalmente, para usar a versão mais recente do provedor do Google, inclua a opção
-upgrade:terraform init -upgrade
Aplique as alterações
-
Revise a configuração e verifique se os recursos que o Terraform vai criar ou
atualizar correspondem às suas expectativas:
terraform plan
Faça as correções necessárias na configuração.
-
Para aplicar a configuração do Terraform, execute o comando a seguir e digite
yesno prompt:terraform apply
Aguarde até que o Terraform exiba a mensagem "Apply complete!".
- Abra seu Google Cloud projeto para conferir os resultados. No console do Google Cloud , navegue até seus recursos na UI para verificar se foram criados ou atualizados pelo Terraform.
Conceder acesso à conta de serviço da conexão
Você precisa do ID da conta de serviço que copiou anteriormente ao configurar permissões para a conexão. Quando você cria um recurso de conexão, o BigQuery cria uma conta de serviço do sistema exclusiva e a associa à conexão.
Para conceder à conta de serviço de conexão a recursos do Cloud acesso aos seus projetos, conceda a ela o papel de consumidor de uso do serviço (roles/serviceusage.serviceUsageConsumer) em my_query_project e o papel de usuário da API Cloud Translation (roles/cloudtranslate.user) em my_translate_project.
Console
Acessar a página IAM
Verifique se
my_query_projectestá selecionado.Clique em Conceder acesso.
No campo Novos principais, insira o ID da conta de serviço da conexão de recurso do Cloud que você copiou anteriormente.
No campo Selecionar um papel, escolha Service Usage e selecione Consumidor do Service Usage.
Clique em Salvar.
No seletor de projetos, escolha
my_translate_project.Acessar a página IAM
Clique em Conceder acesso.
No campo Novos principais, insira o ID da conta de serviço da conexão de recurso do Cloud que você copiou anteriormente.
No campo Selecionar um papel, escolha Cloud Translation e, em seguida, selecione Usuário da API Cloud Translation.
Clique em Salvar.
SQL
Use a instrução GRANT
para conceder o papel de consumidor do Service Usage (roles/serviceusage.serviceUsageConsumer)
à conta de serviço em my_query_project:
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
GRANT `roles/serviceusage.serviceUsageConsumer` ON PROJECT `my_query_project` TO "connection:SERVICE_ACCOUNT_ID";
Substitua
SERVICE_ACCOUNT_IDpelo ID da conta de serviço que você copiou anteriormente.Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Use a instrução GRANT
para conceder a função de usuário da API Cloud Translation (roles/cloudtranslate.user)
em my_translate_project:
No console do Google Cloud , acesse a página BigQuery.
No editor de consultas, digite a seguinte instrução:
GRANT `roles/cloudtranslate.user` ON PROJECT `my_translate_project` TO "connection:SERVICE_ACCOUNT_ID";
Substitua
SERVICE_ACCOUNT_IDpelo ID da conta de serviço que você copiou anteriormente.Clique em Executar.
Para mais informações sobre como executar consultas, acesse Executar uma consulta interativa.
Criar uma UDF em Python que chama o serviço do Cloud Translation
Em my_query_project, crie uma UDF em Python que chame o serviço Cloud Translation usando sua conexão a recursos do Cloud.
No console do Google Cloud , acesse a página BigQuery.
Insira a seguinte instrução
CREATE FUNCTIONno editor de consultas:CREATE FUNCTION `PROJECT_ID.DATASET_ID`.translate_to_es(x STRING) RETURNS STRING LANGUAGE python WITH CONNECTION `PROJECT_ID.REGION.CONNECTION_ID` OPTIONS (entry_point='do_translate', runtime_version='python-3.11', packages=['google-cloud-translate>=3.11', 'google-api-core']) AS r""" from google.api_core.retry import Retry from google.cloud import translate project = "my_translate_project" translate_client = translate.TranslationServiceClient() def do_translate(x : str) -> str: response = translate_client.translate_text( request={ "parent": f"projects/PROJECT_ID/locations/us-central1", "contents": [x], "target_language_code": "es", "mime_type": "text/plain", }, retry=Retry(), ) return response.translations[0].translated_text """; -- Call the UDF. WITH text_table AS (SELECT "Hello" AS text UNION ALL SELECT "Good morning" AS text UNION ALL SELECT "Goodbye" AS text) SELECT text, `PROJECT_ID.DATASET_ID`.translate_to_es(text) AS translated_text FROM text_table;
Substitua:
PROJECT_ID: o ID do projeto;DATASET_ID: o ID do conjunto de dadosREGION: a região da sua conexão.CONNECTION_ID: o ID da conexão.
Clique em Executar.
A saída será semelhante a esta:
+--------------------------+-------------------------------+ | text | translated_text | +--------------------------+-------------------------------+ | Hello | Hola | | Good morning | Buen dia | | Goodbye | Adios | +--------------------------+-------------------------------+
Usar o VPC Service Controls
As UDFs em Python herdam o perímetro do VPC Service Controls do projeto que executa o job de consulta. Esse perímetro protege seus jobs contra exfiltração de dados e garante que as interações de serviço sejam seguras.
Quando você invoca uma UDF do Python dentro do perímetro do VPC Service Controls, ela tem a seguinte conectividade de rede:
- As UDFs em Python que não usam uma conexão a recursos do Cloud são totalmente isoladas. Todo o tráfego de saída é bloqueado.
- As UDFs do Python que usam uma conexão a recursos do Cloud são bloqueadas para acesso à Internet pública. As UDFs em Python só podem acessar serviços Google Cloud que
são compatíveis com o VPC Service Controls. O tráfego de saída para qualquer destino que não seja
restricted.googleapis.comé bloqueado.
Configurar UDFs do Python para acessar serviços Google Cloud com segurança no VPC Service Controls
Para acessar serviços Google Cloud de UDFs do Python e aplicar o VPC Service Controls, siga estas etapas:
- Crie a UDF em Python usando a cláusula
WITH CONNECTIONda instrução CREATE FUNCTION. - Inclua o projeto do BigQuery em que o job de consulta é executado e o projeto de serviço de destino no perímetro de serviço. Como alternativa, configure uma ponte do perímetro.
- Adicione a API de serviço de destino à configuração do perímetro. Por exemplo,
translate.googleapis.comse você estiver se conectando à API Cloud Translation.
Para mais detalhes sobre como configurar um perímetro do VPC Service Controls, consulte:
Práticas recomendadas
Ao criar UDFs em Python, siga estas práticas recomendadas:
- Otimize a lógica de consulta para o agrupamento em lotes. Estruturas de consulta complexas podem desativar o agrupamento em lotes. Isso força um processamento lento, linha por linha, o que aumenta significativamente a latência em conjuntos de dados grandes.
- Otimize a carga útil de dados. O tamanho das linhas individuais pode afetar a eficiência do recurso de lote. Mantenha cada linha o menor possível para maximizar o número de linhas que podem ser processadas em um único lote.
- Configure limites de contêineres de forma eficiente. A escalonabilidade é uma função da CPU, da memória e da simultaneidade de solicitações. Verifique as métricas de monitoramento para ajustar a configuração do contêiner.
Se a utilização da CPU estiver alta, aumente a alocação usando o limite
container_cpuou reduza a simultaneidade de solicitações de contêineres usando o limitecontainer_request_concurrency. - Ao usar o ajuste iterativo, comece com os valores padrão. Se o desempenho não for ideal, analise as métricas de monitoramento para identificar gargalos específicos.
- Implemente tempos limite de API. Quando sua UDF do Python acessar a Internet, defina um tempo limite na chamada de API para evitar comportamentos inesperados. Um exemplo de acesso à Internet é a leitura de um bucket do Cloud Storage.
Ver métricas de UDF em Python
As UDFs em Python exportam métricas para o Cloud Monitoring. Essas métricas ajudam a monitorar vários aspectos da integridade operacional e do consumo de recursos da UDF, fornecendo insights sobre a performance e o comportamento das instâncias de UDF.
Tipo de recurso de monitoramento
As métricas para UDFs do Python são informadas no seguinte tipo de recurso do Cloud Monitoring:
- Tipo:
bigquery.googleapis.com/ManagedRoutineInvocation - Nome de exibição: invocação de rotina gerenciada do BigQuery
- Rótulos:
resource_container: o ID do projeto em que o job de consulta foi executado.location: o local em que o job de consulta foi executado.query_job_id: o ID do job de consulta que invocou a UDF do Python.routine_project_id: o ID do projeto em que a rotina invocada é armazenada.routine_dataset_id: o ID do conjunto de dados em que a rotina invocada está armazenada.routine_id: o ID da rotina invocada.
Métricas
As seguintes métricas estão disponíveis para o tipo de recurso bigquery.googleapis.com/ManagedRoutineInvocation:
| Métrica | Descrição | Unidade | Tipo de valor |
|---|---|---|---|
bigquery.googleapis.com/managed_routine/python/cpu_utilizations |
Quando uma UDF do Python é invocada, essa métrica mostra a distribuição da utilização da CPU em todas as instâncias de UDF do Python para o job de consulta. | Um valor percentual | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/memory_utilizations |
Quando uma UDF do Python é invocada, essa métrica mostra a distribuição da utilização da memória em todas as instâncias de UDF do Python para o job de consulta. | Um valor percentual | DISTRIBUTION |
bigquery.googleapis.com/managed_routine/python/max_request_concurrencies |
Essa métrica mostra a distribuição do número máximo de solicitações simultâneas atendidas por cada instância de UDF em Python. | Contagem | DISTRIBUTION |
Ver métricas
Para conferir as métricas das suas UDFs em Python, escolha uma das opções nas seções a seguir.
Detalhes do job
Para conferir as métricas de UDF do Python de um job de consulta específico, siga estas etapas:
Acessar a página do BigQuery.
Clique em Histórico de jobs.
Na coluna código da tarefa, clique no ID da tarefa de consulta.
Na página Detalhes do job de consulta, clique em Painel do Cloud Monitoring. Esse link mostra um painel filtrado para exibir as métricas de UDF em Python do job.
Metrics Explorer
Para conferir as métricas de UDFs do Python no Metrics Explorer, siga estas etapas:
Acesse a página Metrics Explorer do Cloud Monitoring.
Clique em Selecionar uma métrica e, no campo Filtro, digite
BigQuery Managed Routine Invocationoubigquery.googleapis.com/ManagedRoutineInvocation.Escolha Rotina gerenciada do BigQuery > Managed_routine.
Clique em qualquer uma das métricas disponíveis, como:
- Utilização da CPU da instância
- Utilização da memória da instância
- Máximo de solicitações simultâneas
Clique em Aplicar.
Por padrão, as métricas são mostradas em um gráfico.
É possível filtrar e agrupar as métricas usando os rótulos definidos nos tipos de recursos do Monitoring. Para filtrar as métricas, siga estas etapas:
No campo Filtro, escolha um tipo de recurso, como
query_job_idouroutine_id.No campo Valor, insira o ID do job ou da rotina ou escolha um na lista.
Painéis do Cloud Monitoring
Para conferir as métricas de UDF do Python usando os painéis de monitoramento, siga estas etapas:
Acesse a página Painéis do Cloud Monitoring.
Clique no painel Monitoramento de consultas de rotina gerenciada do BigQuery.
Esse painel oferece uma visão geral das principais métricas nas suas UDFs.
Para filtrar este painel, siga estas etapas:
Clique em Filtrar.
Na lista Filtrar por recurso, escolha uma opção, como ID do projeto, local, ID da rotina ou ID do job.
Locais suportados
As UDFs do Python são compatíveis com todos os locais multirregionais e regionais do BigQuery.
Preços
As cobranças de UDFs em Python são faturadas usando a SKU dos serviços do BigQuery.
As cobranças incluem o seguinte:
Criar ou recriar a imagem do contêiner da UDF. Essa cobrança é proporcional à duração necessária para criar a imagem correspondente com o código e as dependências do cliente.
- Se você estiver usando a API Routines, a duração mais recente do build estará no
campo
BuildStatus. Também é possível conferir a duração do build na colunaBuildStatusda visualizaçãoINFORMATION_SCHEMA.ROUTINES. - Para conferir o custo total dos builds por projeto, filtre seu
relatório de faturamento usando o seguinte:
- Chave:
goog-bq-feature-type - Valor:
MANAGED_ROUTINE_BUILD
- Chave:
- Se você estiver usando a API Routines, a duração mais recente do build estará no
campo
Os clientes de UDFs em Python também pagam pelo custo de invocar uma UDF em Python. Essa cobrança é proporcional à quantidade de computação e memória consumida quando a UDF do Python é invocada.
- Para conferir os custos de UDFs em Python por consulta, consulte o campo
ExternalServiceCostsusando a API Job. Você também pode conferir os custos por consulta na colunaexternal_service_costsda visualizaçãoINFORMATION_SCHEMA.JOBSe aplicar o filtro'external_service_costs.external_service="MANAGED_ROUTINE_EXECUTION"'. - Para conferir o custo total da execução de UDFs em Python por projeto, filtre o relatório de faturamento usando o seguinte:
- Chave:
goog-bq-feature-type - Valor:
MANAGED_ROUTINE_EXECUTION
- Chave:
- Para conferir os custos de UDFs em Python por consulta, consulte o campo
Se as UDFs em Python resultarem em saída de rede externa ou da Internet, você também vai receber uma cobrança de saída da Internet do nível Premium com base nas SKUs de saída do BigQuery.
Cotas
Consulte Cotas e limites de UDF.