
搜尋已建立索引的資料
本頁提供在 BigQuery 中搜尋資料表資料的範例。建立資料索引後,BigQuery 就能最佳化使用 SEARCH 函式或其他函式和運算子的查詢,例如 =、IN、LIKE 和 STARTS_WITH。
SQL 查詢會從所有擷取的資料傳回正確結果,即使部分資料尚未建立索引也一樣。不過,索引可大幅提升查詢效能。如果搜尋結果數量在資料表總列數中只占相對較小的比例,就能盡量減少處理的位元組數和處理單元毫秒數,因為掃描的資料較少。如要判斷查詢是否使用索引,請參閱搜尋索引使用情況。
建立搜尋索引
下表 (稱為 Logs) 用於顯示使用 SEARCH 函式的不同方式。這個範例資料表相當小,但實際上,資料表越大,使用 SEARCH 獲得的效能提升就越顯著。
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
資料表如下所示:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
使用預設文字分析器,在 Logs 資料表上建立搜尋索引:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
如要進一步瞭解搜尋索引,請參閱「管理搜尋索引」。
使用 SEARCH 函式
SEARCH 函式可對資料執行權杖化搜尋。SEARCH 旨在搭配索引使用,以最佳化搜尋作業。您可以使用 SEARCH 函式搜尋整個表格,或將搜尋範圍限制在特定資料欄。
搜尋整張表格
下列查詢會在 Logs 資料表的所有資料欄中搜尋值 bar,並傳回包含這個值的資料列,不論大小寫。由於搜尋索引使用預設文字分析器,因此您不需要在 SEARCH 函式中指定該分析器。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
以下查詢會在 Logs 資料表的所有資料欄中搜尋值 `94.60.64.181`,並傳回包含該值的資料列。反引號可進行精確搜尋,因此含有 181.94.60.64 的 Logs 資料表最後一列會遭到省略。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
搜尋部分資料欄
SEARCH 可讓您輕鬆指定要搜尋資料的欄子集。下列查詢會在 Logs 資料表的 Message 資料欄中搜尋 94.60.64.181 值,並傳回包含這個值的資料列。
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
下列查詢會搜尋 Logs 資料表的 Source 和 Message 欄。並傳回任一資料欄包含 94.60.64.181 值的資料列。
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
從搜尋中排除資料欄
如果表格有很多欄,且您想搜尋大部分的欄,或許只要指定要從搜尋中排除的欄,會比較容易。下列查詢會搜尋 Logs 資料表的所有資料欄,但 Message 資料欄除外。並傳回包含值 94.60.64.181 的任何資料欄資料列 (Message 除外)。
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
使用其他文字分析工具
下列範例會建立名為 contact_info 的資料表,並使用 NO_OP_ANALYZER
text 分析器建立索引:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
下列查詢會在 name 欄中搜尋 Kim,並在 email 欄中搜尋 kim。由於搜尋索引不會使用預設的文字分析工具,因此您必須將分析工具的名稱傳遞至 SEARCH 函式。
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
NO_OP_ANALYZER 不會修改文字,因此 SEARCH 函式只會針對完全相符的項目傳回 TRUE:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
設定文字分析器選項
您可以將 JSON 格式字串新增至設定選項,自訂 LOG_ANALYZER 和 PATTERN_ANALYZER 文字分析器。您可以在 SEARCH 函式、CREATE
SEARCH INDEX DDL 陳述式和 TEXT_ANALYZE 函式中設定文字分析器。
下列範例會建立名為 complex_table 的資料表,並使用 LOG_ANALYZER 文字分析器建立索引。它會使用 JSON 格式的字串來設定分析器選項:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalizer": {"mode": "NONE"} } ] }''');
下表顯示呼叫 SEARCH 函式的範例,其中包含不同的文字分析器及其結果。第一個表格會使用預設文字分析器 (即 LOG_ANALYZER) 呼叫 SEARCH 函式:
| 函式呼叫 | 傳回 | 原因 |
|---|---|---|
| SEARCH('foobarexample', NULL) | 錯誤 | search_terms 為 `NULL`。 |
| SEARCH('foobarexample', '') | 錯誤 | search_terms 不含任何權杖。 |
| SEARCH('foobar-example', 'foobar example') | TRUE | 「-」和「 」是分隔符號。 |
| SEARCH('foobar-example', 'foobarexample') | FALSE | search_terms 未分割。 |
| SEARCH('foobar-example', 'foobar\\&example') | TRUE | 雙反斜線會逸出連字符號,也就是分隔符。 |
| SEARCH('foobar-example', R'foobar\&example') | TRUE | 單一反斜線會逸出原始字串中的連字號。 |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | 反引號必須與 foobar&example 完全相符。 |
| SEARCH('foobar&example', '`foobar&example`') | TRUE | 找到完全相符的結果。 |
| SEARCH('foobar-example', 'example foobar') | TRUE | 條款的順序沒有影響。 |
| SEARCH('foobar-example', 'foobar example') | TRUE | 權杖會轉換為小寫。 |
| SEARCH('foobar-example', '`foobar-example`') | TRUE | 找到完全相符的結果。 |
| SEARCH('foobar-example', '`foobar`') | FALSE | 反引號會保留大小寫。 |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | 反引號對 data_to_search 和 |
| SEARCH('foobar@example.com', '`example.com`') | TRUE | 在 data_to_search 中的分隔符號後找到完全相符的項目。 |
| SEARCH('a foobar-example b', '`foobar-example`') | TRUE | 找到空格分隔符號之間的完全相符項目。 |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | 即使沒有任何一個陣列項目同時符合所有字詞,系統仍會將該陣列的項目全數傳回。 |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | search_terms 等於 foobar\=。 |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | 這與上一個範例相同。 |
| SEARCH('foobar=', 'foobar\\=') | TRUE | 等號是資料和查詢中的分隔符。 |
| SEARCH('foobar=', R'foobar\=') | TRUE | 這與上一個範例相同。 |
| SEARCH('foobar.example', '`foobar`') | TRUE | 找到完全相符的結果。 |
| SEARCH('foobar.example', '`foobar.`') | FALSE | `foobar.` 由於有反引號,因此不會分析, |
| SEARCH('foobar..example', '`foobar.`') | TRUE | `foobar.` 不會因反引號而受到分析,而是會遵循 |
下表顯示使用 NO_OP_ANALYZER 文字分析器呼叫 SEARCH 函式的範例,以及各種傳回值的原因:
| 函式呼叫 | 傳回 | 原因 |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | TRUE | 找到完全相符的結果。 |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | 反引號不是 NO_OP_ANALYZER 的特殊字元。 |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | 大小寫不符。 |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | NO_OP_ANALYZER 沒有分隔符。 |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | TRUE | NO_OP_ANALYZER 沒有分隔符。 |
其他運算子和函式
您可以使用多個運算子、函式和述詞,執行搜尋索引最佳化作業。
使用運算子和比較函式進行最佳化
BigQuery 可以最佳化部分查詢,這些查詢使用等號運算子 (=)、IN 運算子、LIKE 運算子、STARTS_WITH 函式,或ENDS_WITH 函式比較字串常值與已建立索引的資料。
使用字串述詞進行最佳化
下列述詞符合搜尋索引最佳化資格:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)column_name LIKE 'prefix%'STARTS_WITH(column_name, 'prefix')ENDS_WITH(column_name, 'some suffix')
使用數值述詞進行最佳化
如果搜尋索引是使用數值資料類型建立,BigQuery 就能針對使用等號運算子 (=) 或 IN 運算子的部分查詢,搭配索引資料進行最佳化。下列述詞符合搜尋索引最佳化資格:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
最佳化產生已建立索引資料的函式
對已建立索引的資料套用特定函式時,BigQuery 支援搜尋索引最佳化。如果搜尋索引使用預設的 LOG_ANALYZER 文字分析器,則可以將 UPPER 或 LOWER 函式套用至資料欄,例如 UPPER(column_name) = 'STRING_LITERAL'。
如要從已建立索引的 JSON 資料欄擷取 JSON 純量字串資料,可以套用 STRING 函式或其安全版本 SAFE.STRING。如果擷取的 JSON 值不是字串,則 STRING 函式會產生錯誤,而 SAFE.STRING 函式會傳回 NULL。
如果是以 JSON 格式編列索引的 STRING (而非 JSON) 資料,您可以套用下列函式:
舉例來說,假設您有名為 dataset.person_data 的索引資料表,其中包含 JSON 和 STRING 資料欄:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
下列查詢符合最佳化資格:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
系統也會針對這些函式的組合進行最佳化,例如 UPPER(JSON_VALUE(json_string_expression)) = 'FOO'。
使用 JSON_FLATTEN 進行最佳化
BigQuery 支援針對使用 JSON_FLATTEN 函式來扁平化 JSON 陣列的查詢,進行搜尋索引最佳化,通常會搭配 EXISTS 和 UNNEST 使用。
舉例來說,假設您有名為 dataset.logs 的資料表,其中包含 JSON 資料欄 json_payload。下列查詢符合最佳化資格:
SELECT json_payload FROM dataset.logs WHERE EXISTS( SELECT 1 FROM UNNEST(JSON_FLATTEN(JSON_QUERY(json_payload, "lax recursive $.message"))) AS f WHERE SEARCH(f, "nullpointerexception") );
搜尋索引使用情形
如要判斷查詢是否使用搜尋索引,可以查看工作詳細資料,或查詢其中一個 INFORMATION_SCHEMA.JOBS* 檢視區塊。
查看工作詳細資料
在「查詢結果」的「工作資訊」中,「索引使用模式」和「未使用索引的原因」欄位會提供搜尋索引使用情況的詳細資訊。
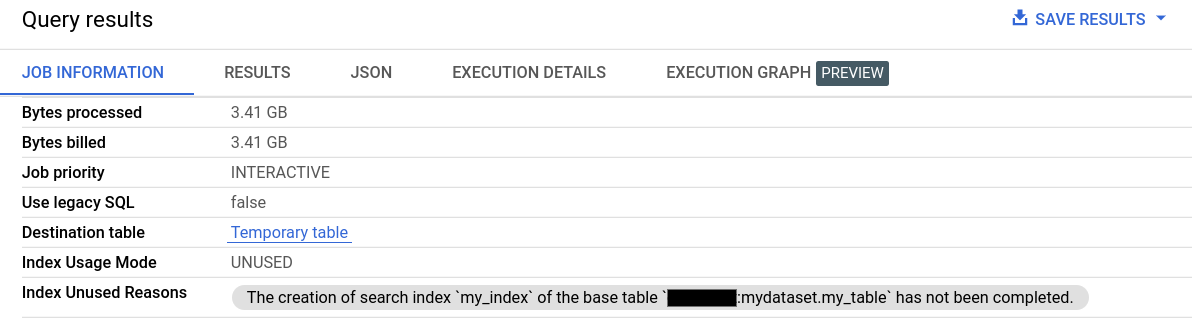
您也可以透過 Jobs.Get API 方法中的 searchStatistics 欄位,取得搜尋索引使用情況的相關資訊。searchStatistics 中的 indexUsageMode 欄位會指出是否使用搜尋索引,可能的值如下:
UNUSED:未使用任何搜尋索引。PARTIALLY_USED:部分查詢使用搜尋索引,部分則否。FULLY_USED:查詢中的每個SEARCH函式都使用搜尋索引。
如果 indexUsageMode 為 UNUSED 或 PARTIALLY_USED,則 indexUnusedReasons
欄位會包含查詢未使用的搜尋索引相關資訊。
如要查看查詢的 searchStatistics,請執行 bq show 指令。
bq show --format=prettyjson -j JOB_ID
範例
假設您執行查詢,對資料表中的資料呼叫 SEARCH 函式。您可以查看查詢的工作詳細資料,找出工作 ID,然後執行 bq show 指令來查看更多資訊:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
輸出內容包含許多欄位,包括 searchStatistics,看起來類似下列內容。在本範例中,indexUsageMode 表示系統未使用索引。原因是資料表沒有搜尋索引。如要解決這個問題,請在資料表上建立搜尋索引。如要查看查詢可能不會使用搜尋索引的所有原因,請參閱「indexUnusedReason code」欄位。
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
查詢 INFORMATION_SCHEMA 檢視區塊
您也可以在下列檢視畫面中,查看區域內多個工作的搜尋索引用量:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
下列查詢會顯示過去 7 天內,所有可最佳化搜尋索引查詢的索引使用資訊:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
結果大致如下:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
最佳做法
下列各節說明搜尋的最佳做法。
選擇性搜尋
如果搜尋結果不多,搜尋功能就能發揮最大效用。盡可能使用具體的搜尋字詞。
ORDER BY LIMIT 最佳化
如果查詢在非常大的分區資料表上使用 SEARCH、=、IN、LIKE 或 STARTS_WITH,您可以在分區欄位上使用 ORDER BY 子句和 LIMIT 子句,藉此最佳化查詢。如果查詢不含 SEARCH 函式,您可以使用其他運算子和函式來善用最佳化功能。無論資料表是否已建立索引,系統都會套用最佳化設定。如果您要搜尋常見字詞,這個做法很有效。舉例來說,假設先前建立的 Logs 資料表是根據名為 day 的額外 DATE 型別資料欄進行分區。最佳化後的查詢如下:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
縮小搜尋範圍
使用 SEARCH 函式時,請只搜尋您預期會包含搜尋字詞的資料表欄。這項作業可提升效能,並減少需要掃描的位元組數。
使用反引號
搭配 LOG_ANALYZER 文字分析器使用 SEARCH 函式時,將搜尋查詢內容放在反引號中,即可強制完全比對。如果搜尋內容區分大小寫,或包含不應解讀為分隔符的字元,這項功能就很有用。舉例來說,如要搜尋 IP 位址 192.0.2.1,請使用 `192.0.2.1`。如果沒有反引號,搜尋會傳回包含個別符記 192、0、2 和 1 的任何資料列,順序不限。