
Ricercare dati indicizzati
Questa pagina fornisce esempi di ricerca di dati di tabelle in BigQuery.
Quando indicizzi i dati, BigQuery può ottimizzare alcune query
che utilizzano la funzione SEARCH
o altre funzioni e operatori,
come =, IN, LIKE e STARTS_WITH.
Le query SQL restituiscono risultati corretti da tutti i dati importati, anche se alcuni non sono ancora indicizzati. Tuttavia, le prestazioni delle query possono essere notevolmente migliorate con un indice. Il risparmio in termini di byte elaborati e millisecondi di slot viene massimizzato quando il numero di risultati di ricerca costituisce una frazione relativamente piccola del totale delle righe della tabella perché vengono scansionati meno dati. Per determinare se è stato utilizzato un indice per una query, vedi Utilizzo dell'indice di ricerca.
Crea un indice di ricerca
La tabella seguente, denominata Logs, viene utilizzata per mostrare diversi modi di utilizzare la funzione SEARCH. Questa tabella di esempio è piuttosto piccola, ma in
pratica i miglioramenti delle prestazioni che ottieni con SEARCH aumentano con le dimensioni
della tabella.
CREATE TABLE my_dataset.Logs (Level STRING, Source STRING, Message STRING) AS ( SELECT 'INFO' as Level, '65.177.8.234' as Source, 'Entry Foo-Bar created' as Message UNION ALL SELECT 'WARNING', '132.249.240.10', 'Entry Foo-Bar already exists, created by 65.177.8.234' UNION ALL SELECT 'INFO', '94.60.64.181', 'Entry Foo-Bar deleted' UNION ALL SELECT 'SEVERE', '4.113.82.10', 'Entry Foo-Bar does not exist, deleted by 94.60.64.181' UNION ALL SELECT 'INFO', '181.94.60.64', 'Entry Foo-Baz created' );
La tabella è simile alla seguente:
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | | INFO | 181.94.60.64 | Entry Foo-Baz created | +---------+----------------+-------------------------------------------------------+
Crea un indice di ricerca nella tabella Logs utilizzando l'analizzatore di testo predefinito:
CREATE SEARCH INDEX my_index ON my_dataset.Logs(ALL COLUMNS);
Per saperne di più sugli indici di ricerca, vedi Gestire gli indici di ricerca.
Utilizzare la funzione SEARCH
La funzione SEARCH fornisce la ricerca tokenizzata sui dati.
SEARCH è progettato per essere utilizzato con un indice per
ottimizzare le ricerche.
Puoi utilizzare la funzione SEARCH per cercare in un'intera tabella o limitare la ricerca a colonne specifiche.
Cercare in un'intera tabella
La seguente query esegue la ricerca in tutte le colonne della tabella Logs del valore bar e restituisce le righe che contengono questo valore, indipendentemente dalla capitalizzazione. Poiché l'indice di ricerca utilizza l'analizzatore di testo predefinito, non
devi specificarlo nella funzione SEARCH.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, 'bar');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 65.177.8.234 | Entry Foo-Bar created | | WARNING | 132.249.240.10 | Entry Foo-Bar already exists, created by 65.177.8.234 | | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
La seguente query esegue la ricerca in tutte le colonne della tabella Logs del valore `94.60.64.181` e restituisce le righe che contengono questo valore. I
backtick consentono una ricerca esatta, motivo per cui l'ultima riga della tabella Logs
che contiene 181.94.60.64 viene omessa.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Logs, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Cercare un sottoinsieme di colonne
SEARCH consente di specificare facilmente un sottoinsieme di colonne in cui cercare
i dati. La seguente query cerca nella colonna Message della tabella Logs il valore 94.60.64.181 e restituisce le righe che contengono questo valore.
SELECT * FROM my_dataset.Logs WHERE SEARCH(Message, '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
La seguente query esegue la ricerca nelle colonne Source e Message della tabella
Logs. Restituisce le righe che contengono il valore 94.60.64.181 di
una delle due colonne.
SELECT * FROM my_dataset.Logs WHERE SEARCH((Source, Message), '`94.60.64.181`');
+---------+----------------+-------------------------------------------------------+ | Level | Source | Message | +---------+----------------+-------------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | | SEVERE | 4.113.82.10 | Entry Foo-Bar does not exist, deleted by 94.60.64.181 | +---------+----------------+-------------------------------------------------------+
Escludere colonne da una ricerca
Se una tabella ha molte colonne e vuoi cercarne la maggior parte, potrebbe essere
più semplice specificare solo le colonne da escludere dalla ricerca. La seguente
query esegue la ricerca in tutte le colonne della tabella Logs, ad eccezione
della colonna Message. Restituisce le righe di qualsiasi colonna diversa da Message
che contiene il valore 94.60.64.181.
SELECT * FROM my_dataset.Logs WHERE SEARCH( (SELECT AS STRUCT Logs.* EXCEPT (Message)), '`94.60.64.181`');
+---------+----------------+---------------------------------------------------+ | Level | Source | Message | +---------+----------------+---------------------------------------------------+ | INFO | 94.60.64.181 | Entry Foo-Bar deleted | +---------+----------------+---------------------------------------------------+
Utilizzare un altro analizzatore di testo
L'esempio seguente crea una tabella denominata contact_info con un indice che
utilizza l'analizzatore di testo
NO_OP_ANALYZER:
CREATE TABLE my_dataset.contact_info (name STRING, email STRING) AS ( SELECT 'Kim Lee' AS name, 'kim.lee@example.com' AS email UNION ALL SELECT 'Kim' AS name, 'kim@example.com' AS email UNION ALL SELECT 'Sasha' AS name, 'sasha@example.com' AS email ); CREATE SEARCH INDEX noop_index ON my_dataset.contact_info(ALL COLUMNS) OPTIONS (analyzer = 'NO_OP_ANALYZER');
+---------+---------------------+ | name | email | +---------+---------------------+ | Kim Lee | kim.lee@example.com | | Kim | kim@example.com | | Sasha | sasha@example.com | +---------+---------------------+
La seguente query cerca Kim nella colonna name e kim
nella colonna email.
Poiché l'indice di ricerca non utilizza l'analizzatore di testo predefinito, devi passare il
nome dell'analizzatore alla funzione SEARCH.
SELECT name, SEARCH(name, 'Kim', analyzer=>'NO_OP_ANALYZER') AS name_Kim, email, SEARCH(email, 'kim', analyzer=>'NO_OP_ANALYZER') AS email_kim FROM my_dataset.contact_info;
La funzione NO_OP_ANALYZER non modifica il testo, quindi la funzione SEARCH restituisce solo
TRUE per le corrispondenze esatte:
+---------+----------+---------------------+-----------+ | name | name_Kim | email | email_kim | +---------+----------+---------------------+-----------+ | Kim Lee | FALSE | kim.lee@example.com | FALSE | | Kim | TRUE | kim@example.com | FALSE | | Sasha | FALSE | sasha@example.com | FALSE | +---------+----------+---------------------+-----------+
Configurare le opzioni dell'analizzatore di testo
Gli analizzatori di testo LOG_ANALYZER e PATTERN_ANALYZER possono essere personalizzati aggiungendo una stringa in formato JSON alle opzioni di configurazione. Puoi configurare gli analizzatori di testo nella funzione SEARCH, nell'istruzione DDL CREATE
SEARCH INDEX e nella funzione TEXT_ANALYZE.
L'esempio seguente crea una tabella denominata complex_table con un indice che
utilizza l'analizzatore di testo LOG_ANALYZER. Utilizza una stringa in formato JSON per
configurare le opzioni dell'analizzatore:
CREATE TABLE dataset.complex_table( a STRING, my_struct STRUCT<string_field STRING, int_field INT64>, b ARRAY<STRING> ); CREATE SEARCH INDEX my_index ON dataset.complex_table(a, my_struct, b) OPTIONS (analyzer = 'LOG_ANALYZER', analyzer_options = '''{ "token_filters": [ { "normalizer": {"mode": "NONE"} } ] }''');
La tabella seguente mostra esempi di chiamate alla funzione SEARCH con
diversi analizzatori di testo e i relativi risultati. La prima tabella chiama la funzione SEARCH
utilizzando l'analizzatore di testo predefinito, LOG_ANALYZER:
| Chiamata di funzione | Restituisce | Motivo |
|---|---|---|
| SEARCH('foobarexample', NULL) | ERRORE | search_terms è "NULL". |
| SEARCH('foobarexample', '') | ERRORE | search_terms non contiene token. |
| SEARCH('foobar-example', 'foobar example') | VERO | "-" e " " sono delimitatori. |
| SEARCH('foobar-example', 'foobarexample') | FALSE | search_terms non è suddiviso. |
| SEARCH('foobar-example', 'foobar\\&example') | VERO | La doppia barra rovesciata esegue l'escape della e commerciale, che è un delimitatore. |
| SEARCH('foobar-example', R'foobar\&example') | VERO | La singola barra rovesciata esegue l'escape della e commerciale in una stringa non elaborata. |
| SEARCH('foobar-example', '`foobar&example`') | FALSE | I backtick richiedono una corrispondenza esatta per foobar&example. |
| SEARCH('foobar&example', '`foobar&example`') | VERO | Viene trovata una corrispondenza esatta. |
| SEARCH('foobar-example', 'example foobar') | VERO | L'ordine dei termini non è importante. |
| SEARCH('foobar-example', 'foobar example') | VERO | I token vengono convertiti in minuscolo. |
| SEARCH('foobar-example', '`foobar-example`') | VERO | Viene trovata una corrispondenza esatta. |
| SEARCH('foobar-example', '`foobar`') | FALSE | I backtick mantengono le maiuscole. |
| SEARCH('`foobar-example`', '`foobar-example`') | FALSE | I backtick non hanno un significato speciale per data_to_search e |
| SEARCH('foobar@example.com', '`example.com`') | VERO | Viene trovata una corrispondenza esatta dopo il delimitatore in data_to_search. |
| SEARCH('a foobar-example b', '`foobar-example`') | VERO | Viene trovata una corrispondenza esatta tra i delimitatori di spazio. |
| SEARCH(['foobar', 'example'], 'foobar example') | FALSE | Nessuna singola voce dell'array corrisponde a tutti i termini di ricerca. |
| SEARCH('foobar=', '`foobar\\=`') | FALSE | search_terms equivale a foobar\=. |
| SEARCH('foobar=', R'`foobar\=`') | FALSE | Equivale all'esempio precedente. |
| SEARCH('foobar=', 'foobar\\=') | VERO | Il segno uguale è un delimitatore nei dati e nella query. |
| SEARCH('foobar=', R'foobar\=') | VERO | Equivale all'esempio precedente. |
| SEARCH('foobar.example', '`foobar`') | VERO | Viene trovata una corrispondenza esatta. |
| SEARCH('foobar.example', '`foobar.`') | FALSE | `foobar.` non viene analizzato a causa dei backtick; non è |
| SEARCH('foobar..example', '`foobar.`') | VERO | `foobar.` non viene analizzato a causa dei backtick; è seguito |
La tabella seguente mostra esempi di chiamate alla funzione SEARCH utilizzando l'analizzatore di testo NO_OP_ANALYZER e i motivi di vari valori restituiti:
| Chiamata di funzione | Restituisce | Motivo |
|---|---|---|
| SEARCH('foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | VERO | Viene trovata una corrispondenza esatta. |
| SEARCH('foobar', '`foobar`', analyzer=>'NO_OP_ANALYZER') | FALSE | Il carattere accento grave non è un carattere speciale per NO_OP_ANALYZER. |
| SEARCH('Foobar', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | La capitalizzazione non corrisponde. |
| SEARCH('foobar example', 'foobar', analyzer=>'NO_OP_ANALYZER') | FALSE | Non sono presenti delimitatori per NO_OP_ANALYZER. |
| SEARCH('', '', analyzer=>'NO_OP_ANALYZER') | VERO | Non sono presenti delimitatori per NO_OP_ANALYZER. |
Altri operatori e funzioni
Puoi eseguire ottimizzazioni dell'indice di ricerca con diversi operatori, funzioni e predicati.
Ottimizza con operatori e funzioni di confronto
BigQuery può ottimizzare alcune query che utilizzano l'operatore di uguaglianza (=), l'operatore IN, l'operatore LIKE, la funzione STARTS_WITH o la funzione ENDS_WITH per confrontare i valori letterali stringa con i dati indicizzati.
Ottimizza con i predicati stringa
I seguenti predicati sono idonei per l'ottimizzazione dell'indice di ricerca:
column_name = 'string_literal''string_literal' = column_namestruct_column.nested_field = 'string_literal'string_array_column[OFFSET(0)] = 'string_literal'string_array_column[ORDINAL(1)] = 'string_literal'column_name IN ('string_literal1', 'string_literal2', ...)column_name LIKE 'prefix%'STARTS_WITH(column_name, 'prefix')ENDS_WITH(column_name, 'some suffix')
Ottimizzare con i predicati numerici
Se l'indice di ricerca è stato creato con tipi di dati numerici, BigQuery
può ottimizzare alcune query che utilizzano l'operatore di uguaglianza (=) o l'operatore IN
con i dati indicizzati. I seguenti predicati sono idonei per l'ottimizzazione dell'indice di ricerca:
INT64(json_column.int64_field) = 1int64_column = 1int64_array_column[OFFSET(0)] = 1int64_column IN (1, 2)struct_column.nested_int64_field = 1struct_column.nested_timestamp_field = TIMESTAMP "2024-02-15 21:31:40"timestamp_column = "2024-02-15 21:31:40"timestamp_column IN ("2024-02-15 21:31:40", "2024-02-16 21:31:40")
Ottimizzare le funzioni che producono dati indicizzati
BigQuery supporta l'ottimizzazione dell'indice di ricerca quando vengono applicate determinate funzioni ai dati indicizzati.
Se l'indice di ricerca utilizza l'analizzatore di testo LOG_ANALYZER predefinito, puoi applicare le funzioni UPPER o LOWER alla colonna, ad esempio UPPER(column_name) = 'STRING_LITERAL'.
Per i dati stringa scalari JSON estratti da una colonna JSON indicizzata, puoi
applicare la
funzione
STRING
o la sua versione sicura,
SAFE.STRING.
Se il valore JSON estratto non è una stringa, la funzione STRING
genera un errore e la funzione SAFE.STRING restituisce NULL.
Per i dati STRING (non JSON) in formato JSON indicizzati, puoi applicare le seguenti funzioni:
Ad esempio, supponiamo di avere la seguente tabella indicizzata denominata
dataset.person_data con una colonna JSON e una colonna STRING:
+----------------------------------------------------------------+-----------------------------------------+
| json_column | string_column |
+----------------------------------------------------------------+-----------------------------------------+
| { "name" : "Ariel", "email" : "cloudysanfrancisco@gmail.com" } | { "name" : "Ariel", "job" : "doctor" } |
+----------------------------------------------------------------+-----------------------------------------+
Le seguenti query sono idonee per l'ottimizzazione:
SELECT * FROM dataset.person_data WHERE SAFE.STRING(json_column.email) = 'cloudysanfrancisco@gmail.com';
SELECT * FROM dataset.person_data WHERE JSON_VALUE(string_column, '$.job') IN ('doctor', 'lawyer', 'teacher');
Anche le combinazioni di queste funzioni sono ottimizzate, ad esempio
UPPER(JSON_VALUE(json_string_expression)) = 'FOO'.
Ottimizza con JSON_FLATTEN
BigQuery supporta l'ottimizzazione dell'indice di ricerca per le query che utilizzano la funzione JSON_FLATTEN per appiattire gli array JSON, in genere in combinazione con EXISTS e UNNEST.
Ad esempio, supponiamo di avere una tabella denominata dataset.logs con una colonna JSON json_payload. La seguente query è idonea per l'ottimizzazione:
SELECT json_payload FROM dataset.logs WHERE EXISTS( SELECT 1 FROM UNNEST(JSON_FLATTEN(JSON_QUERY(json_payload, "lax recursive $.message"))) AS f WHERE SEARCH(f, "nullpointerexception") );
Utilizzo dell'indice di ricerca
Per determinare se è stato utilizzato un indice di ricerca per una query, puoi visualizzare i
dettagli del job o eseguire una query su una delle visualizzazioni INFORMATION_SCHEMA.JOBS*.
Visualizza i dettagli del job
In Informazioni sul job dei Risultati della query, i campi Modalità di utilizzo dell'indice e Motivi del mancato utilizzo dell'indice forniscono informazioni dettagliate sull'utilizzo dell'indice di ricerca.
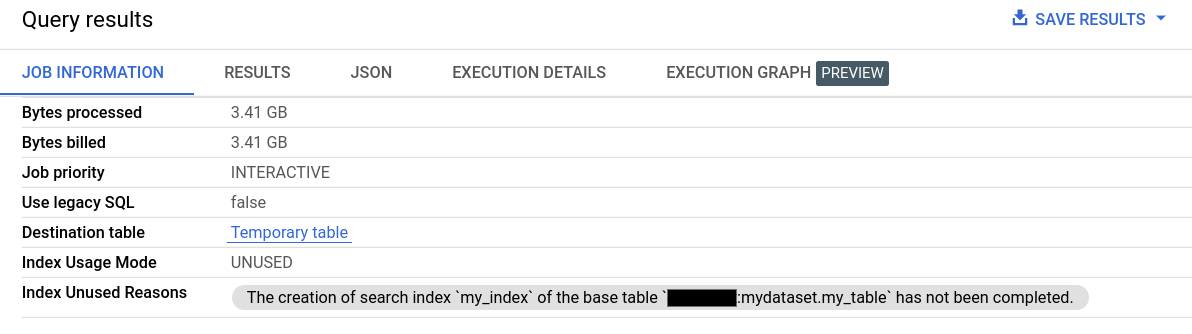
Le informazioni sull'utilizzo dell'indice di ricerca sono disponibili anche tramite il
campo searchStatistics
nel metodo API Jobs.Get. Il campo
indexUsageMode in searchStatistics indica se è stato utilizzato un indice di ricerca
con i seguenti valori:
UNUSED: non è stato utilizzato alcun indice di ricerca.PARTIALLY_USED: parte della query utilizzava gli indici di ricerca e parte no.FULLY_USED: ogni funzioneSEARCHnella query ha utilizzato un indice di ricerca.
Quando indexUsageMode è UNUSED o PARTIALLY_USED, il campo indexUnusedReasons
contiene informazioni sul motivo per cui gli indici di ricerca non sono stati utilizzati nella query.
Per visualizzare searchStatistics per una query, esegui il comando bq show.
bq show --format=prettyjson -j JOB_ID
Esempio
Supponiamo di eseguire una query che chiama la funzione SEARCH sui dati di una tabella. Puoi visualizzare i dettagli del job della query per trovare l'ID job, quindi eseguire il comando bq show per visualizzare ulteriori informazioni:
bq show --format=prettyjson --j my_project:US.bquijob_123x456_789y123z456c
L'output contiene molti campi, tra cui searchStatistics, simile al seguente. In questo esempio, indexUsageMode indica che l'indice non è stato utilizzato. Il motivo è che la tabella non ha un indice di ricerca. Per
risolvere questo problema, crea un indice di ricerca nella
tabella. Consulta il campo
indexUnusedReason code
per un elenco di tutti i motivi per cui un indice di ricerca potrebbe non essere utilizzato in una query.
"searchStatistics": {
"indexUnusedReasons": [
{
"baseTable": {
"datasetId": "my_dataset",
"projectId": "my_project",
"tableId": "my_table"
},
"code": "INDEX_CONFIG_NOT_AVAILABLE",
"message": "There is no search index configuration for the base table `my_project:my_dataset.my_table`."
}
],
"indexUsageMode": "UNUSED"
},
Esegui query sulle viste INFORMATION_SCHEMA
Puoi anche visualizzare l'utilizzo dell'indice di ricerca per più job in una regione nelle seguenti visualizzazioni:
INFORMATION_SCHEMA.JOBSINFORMATION_SCHEMA.JOBS_BY_USERINFORMATION_SCHEMA.JOBS_BY_FOLDERINFORMATION_SCHEMA.JOBS_BY_ORGANIZATION
La seguente query mostra informazioni sull'utilizzo dell'indice per tutte le query ottimizzabili dell'indice di ricerca negli ultimi 7 giorni:
SELECT job_id, search_statistics.index_usage_mode, index_unused_reason.code, index_unused_reason.base_table.table_id, index_unused_reason.index_name FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS, UNNEST(search_statistics.index_unused_reasons) AS index_unused_reason WHERE end_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP();
Il risultato è simile al seguente:
+-----------+----------------------------------------+-----------------------+ | job_id | index_usage_mode | code | table_id | index_name | +-----------+------------------+---------------------+-----------------------+ | bquxjob_1 | UNUSED | BASE_TABLE_TOO_SMALL| my_table | my_index | | bquxjob_2 | FULLY_USED | NULL | my_table | my_index | +-----------+----------------------------------------+-----------------------+
Best practice
Le sezioni seguenti descrivono le best practice per la ricerca.
Ricerca selettiva
La ricerca funziona meglio quando restituisce pochi risultati. Rendi le tue ricerche il più specifiche possibile.
Ottimizzazione di ORDER BY LIMIT
Le query che utilizzano SEARCH, =, IN, LIKE o STARTS_WITH su una tabella partizionata molto grande possono essere ottimizzate quando utilizzi una clausola ORDER BY sul campo partizionato e una clausola LIMIT.
Per le query che non contengono la funzione SEARCH, puoi utilizzare
altri operatori e funzioni per sfruttare
l'ottimizzazione. L'ottimizzazione viene applicata indipendentemente dal fatto che la tabella sia indicizzata. Questo approccio è ideale se cerchi un termine comune.
Ad esempio, supponiamo che la tabella Logs creata in precedenza
sia partizionata in base a una colonna di tipo DATE aggiuntiva
denominata day. La seguente query è ottimizzata:
SELECT Level, Source, Message FROM my_dataset.Logs WHERE SEARCH(Message, "foo") ORDER BY day LIMIT 10;
Definisci l'ambito della ricerca
Quando utilizzi la funzione SEARCH, cerca solo nelle colonne della tabella che
prevedi che contengano i termini di ricerca. Ciò migliora il rendimento e
riduce il numero di byte da analizzare.
Utilizzare gli apici inversi
Quando utilizzi la funzione SEARCH con l'analizzatore di testo LOG_ANALYZER,
racchiudere la query di ricerca tra apici inversi
forza una corrispondenza esatta. Questa opzione è utile
se la ricerca è sensibile alle maiuscole o contiene caratteri che non devono essere
interpretati come delimitatori. Ad esempio, per cercare l'indirizzo IP
192.0.2.1, utilizza `192.0.2.1`. Senza gli apici inversi, la ricerca restituisce
qualsiasi riga che contenga i singoli token 192, 0, 2 e 1, in qualsiasi
ordine.