
בתוך משימות של שאילתות, BigQuery כולל תוכנית שאילתה לאבחון ומידע על תזמון. זה דומה למידע שמופיע בהצהרות כמו EXPLAIN במערכות אחרות של מסדי נתונים וניתוח נתונים. אפשר לאחזר את המידע הזה מתשובות ה-API של שיטות כמו jobs.get.
בשאילתות שפועלות במשך זמן רב, BigQuery מעדכן את הנתונים הסטטיסטיים האלה מדי פעם. העדכונים האלה מתבצעים באופן עצמאי מהקצב שבו מתבצעת בדיקת הסטטוס של העבודה, אבל בדרך כלל הם לא מתבצעים בתדירות גבוהה יותר מאשר כל 30 שניות. בנוסף, שאילתות שלא משתמשות במשאבי ביצוע, כמו בקשות להרצה יבשה או תוצאות שאפשר להציג מתוצאות שנשמרו במטמון, לא יכללו את מידע האבחון הנוסף, אבל יכול להיות שיופיעו נתונים סטטיסטיים אחרים.
רקע
כשמריצים שאילתה ב-BigQuery, המערכת ממירה את ה-SQL לתרשים ביצוע שמורכב משלבים. השלבים מורכבים מפעולות, שהן הפעולות הבסיסיות שמבצעות את הלוגיקה של השאילתה. BigQuery משתמש בארכיטקטורה מקבילית מבוזרת מאוד שמבצעת שלבים במקביל כדי להקטין את זמן האחזור. השלבים מתקשרים ביניהם באמצעות ערבוב, ארכיטקטורה של זיכרון מבוזר מהיר.
בתוכנית השאילתה נעשה שימוש במונחים יחידות עבודה ועובדים כדי לתאר את המקביליות של השלב. במקומות אחרים ב-BigQuery, יכול להיות שתיתקלו במונח slot, שהוא ייצוג מופשט של היבטים שונים של ביצוע שאילתות, כולל משאבי מחשוב, זיכרון וקלט/פלט. משבצות זמן מריצות במקביל את יחידות העבודה של שלב מסוים. סטטיסטיקות של משימות ברמה העליונה מספקות עלות שאילתה פרטנית באמצעות totalSlotMs על סמך הנהלת חשבונות מופשטת.
מאפיין חשוב נוסף של ביצוע השאילתה הוא ש-BigQuery יכול לשנות את תוכנית השאילתה בזמן שהשאילתה פועלת. לדוגמה, ב-BigQuery נוספו שלבים של חלוקה מחדש כדי לשפר את חלוקת הנתונים בין תהליכי העבודה של השאילתות, וכך לשפר את ההקביליות ולהקטין את זמן האחזור של השאילתות.
בנוסף לתוכנית השאילתות, משימות של שאילתות חושפות גם ציר זמן של הביצוע, שמספק דיווח על יחידות העבודה שהושלמו, ממתינות ופעילות. לשאילתה יכולים להיות כמה שלבים עם עובדים פעילים בו-זמנית, וציר הזמן נועד להציג את ההתקדמות הכוללת של השאילתה.
צפייה בתרשים הביצוע באמצעות מסוף Google Cloud
בGoogle Cloud מסוף, אפשר לראות את פרטי תוכנית השאילתה של שאילתה שהושלמה בלחיצה על הלחצן פרטי הביצוע.
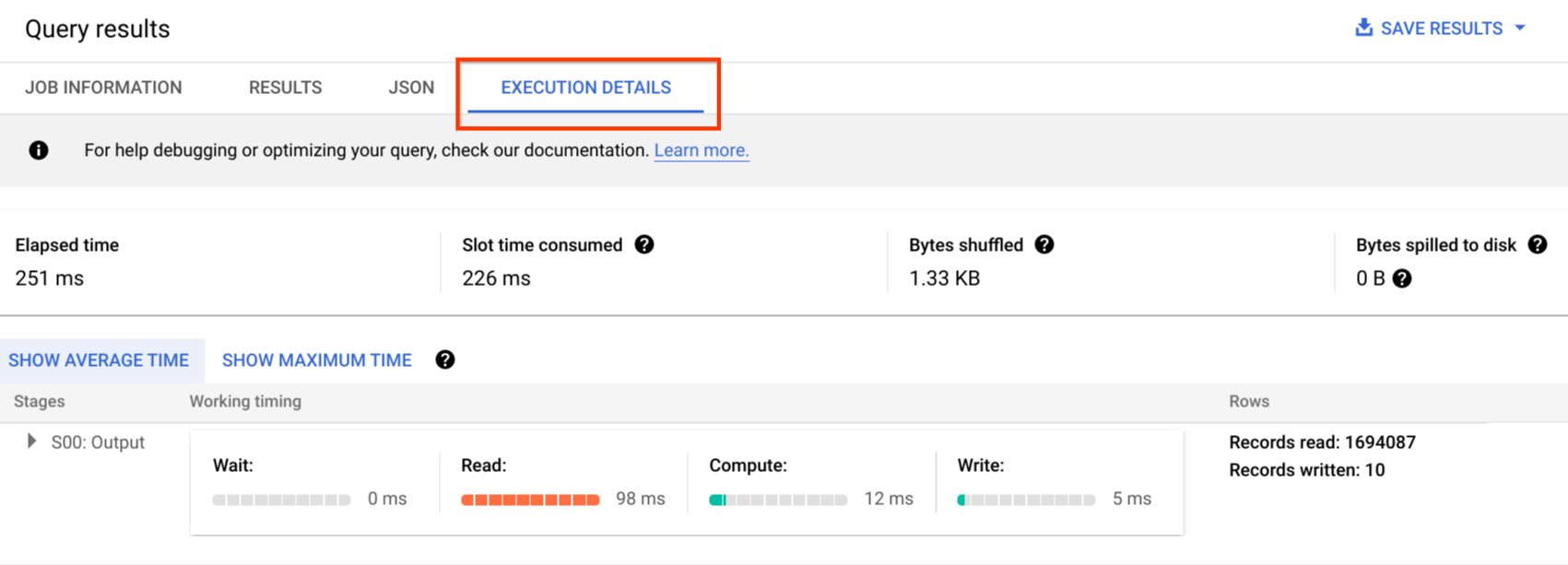
מידע על תוכנית השאילתה
בתגובת ה-API, תוכניות השאילתות מיוצגות כרשימה של שלבי שאילתה. בכל פריט ברשימה מוצגים נתונים סטטיסטיים של סקירה כללית לכל שלב, מידע מפורט על השלב וסיווגים של תזמון השלבים. לא כל הפרטים מוצגים במסוף Google Cloud , אבל כולם יכולים להופיע בתגובות של ה-API.
הסבר על גרף הביצוע
במסוף Google Cloud , אפשר לראות את פרטי תוכנית השאילתה בלחיצה על הכרטיסייה Execution graph.
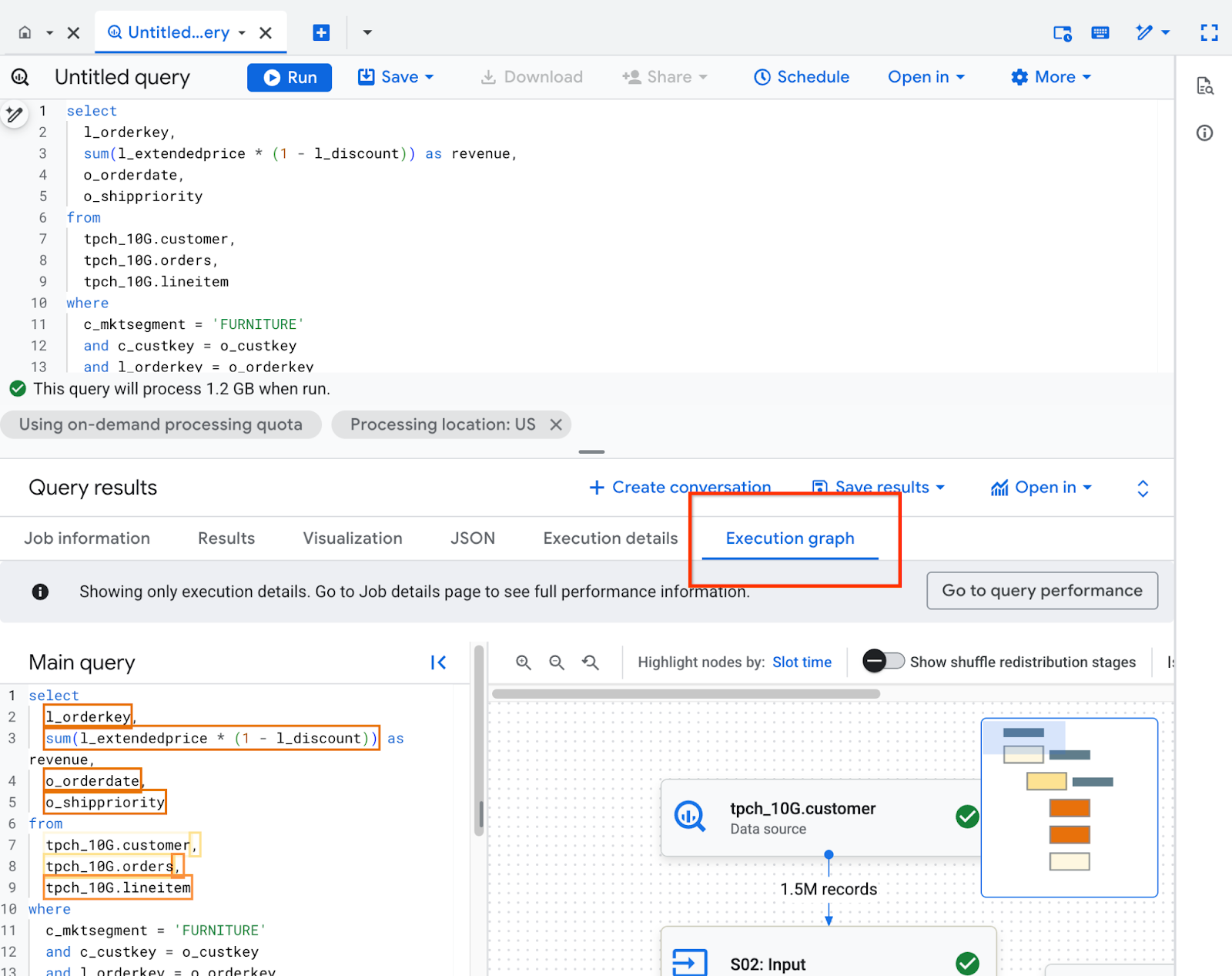
החלונית תרשים הביצוע מאורגנת באופן הבא:
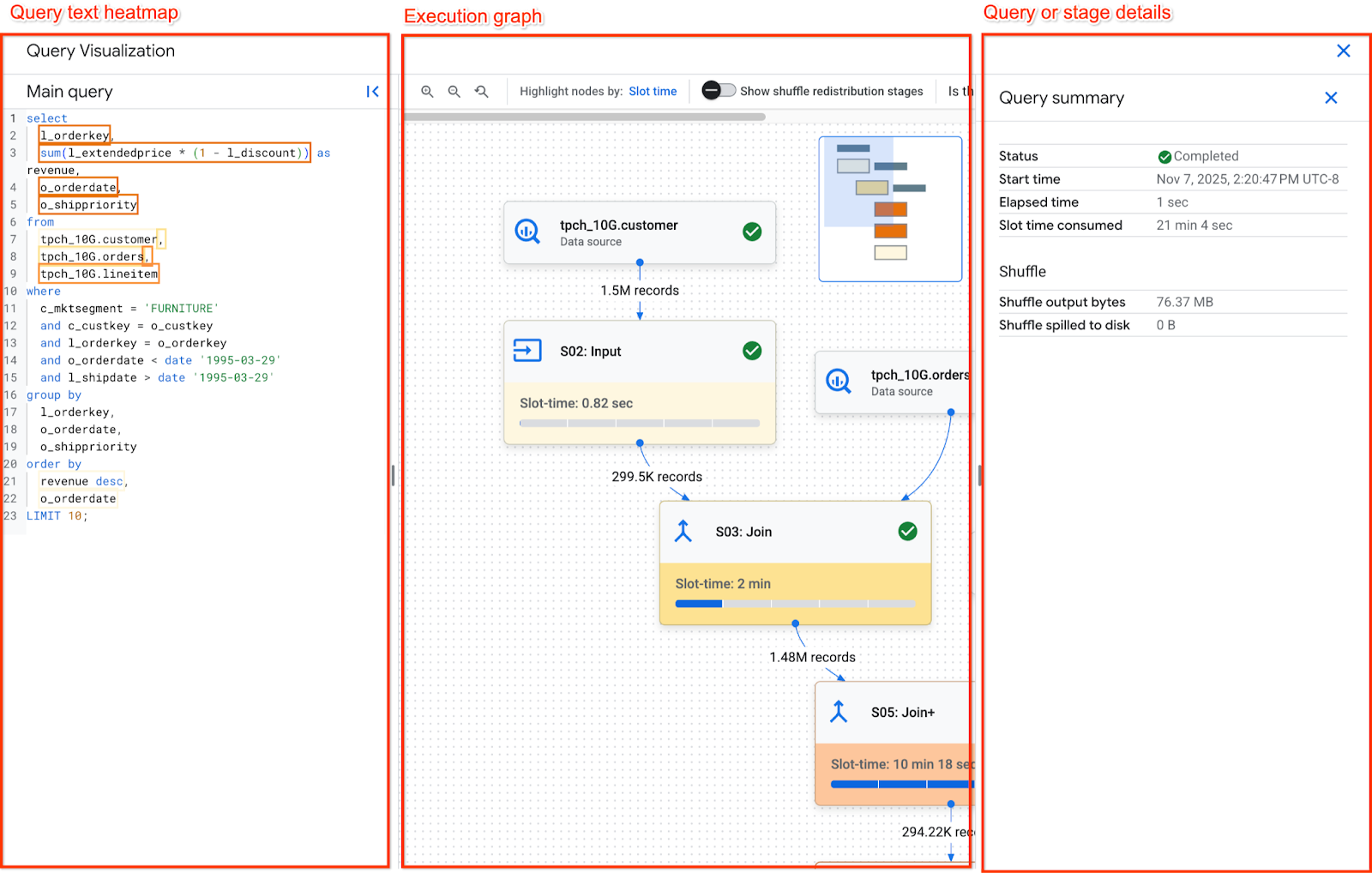
- במרכז נמצא גרף הביצוע. השלבים מוצגים כצמתים, והזיכרון של ערבוב הנתונים שמועבר בין השלבים מוצג כקשתות.
- בחלונית הימנית מופיעה מפת החום של טקסט השאילתה. מוצג בו הטקסט הראשי של השאילתה שהשאילתה ביצעה, יחד עם תצוגות שהופנו אליהן.
- בחלונית השמאלית מופיעים פרטי השאילתה או השלב.
ניווט בתרשים הביצוע
בתרשים הביצוע מוחלת ערכת צבעים על הצמתים בתרשים על סמך זמן המשבצת, כאשר צמתים עם אדום כהה יותר צורכים יותר זמן משבצת ביחס לשאר השלבים בתרשים.
כדי לנווט בתרשים הביצוע, אתם יכולים:
- לוחצים לחיצה ארוכה על הרקע של הגרף כדי להזיז אותו לאזורים שונים.
- משתמשים בגלגל הגלילה של העכבר כדי להגדיל או להקטין את התצוגה של הגרף.
- לוחצים לחיצה ארוכה על המפה הקטנה בפינה השמאלית העליונה כדי להזיז את התצוגה לאזורים שונים בתרשים.
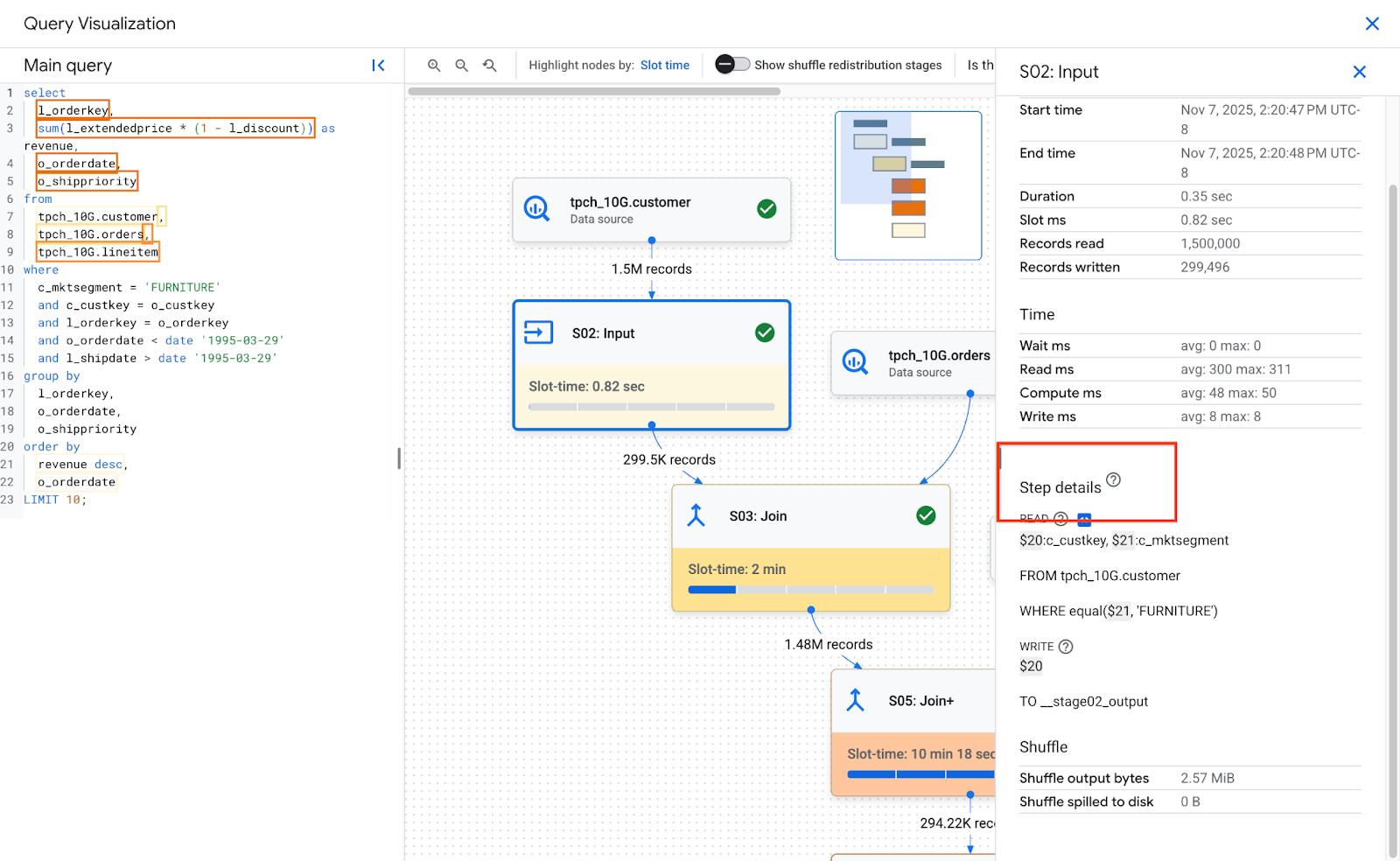
לחיצה על שלב בתרשים מציגה את פרטי השלב שנבחר. פרטי השלב כוללים:
- נתונים סטטיסטיים. פרטים נוספים על הנתונים הסטטיסטיים מופיעים במאמר סקירה כללית של השלב.
- פרטי השלב. השלבים מתארים את הפעולות הבודדות שמבצעות את הלוגיקה של השאילתה.
פרטי השלב
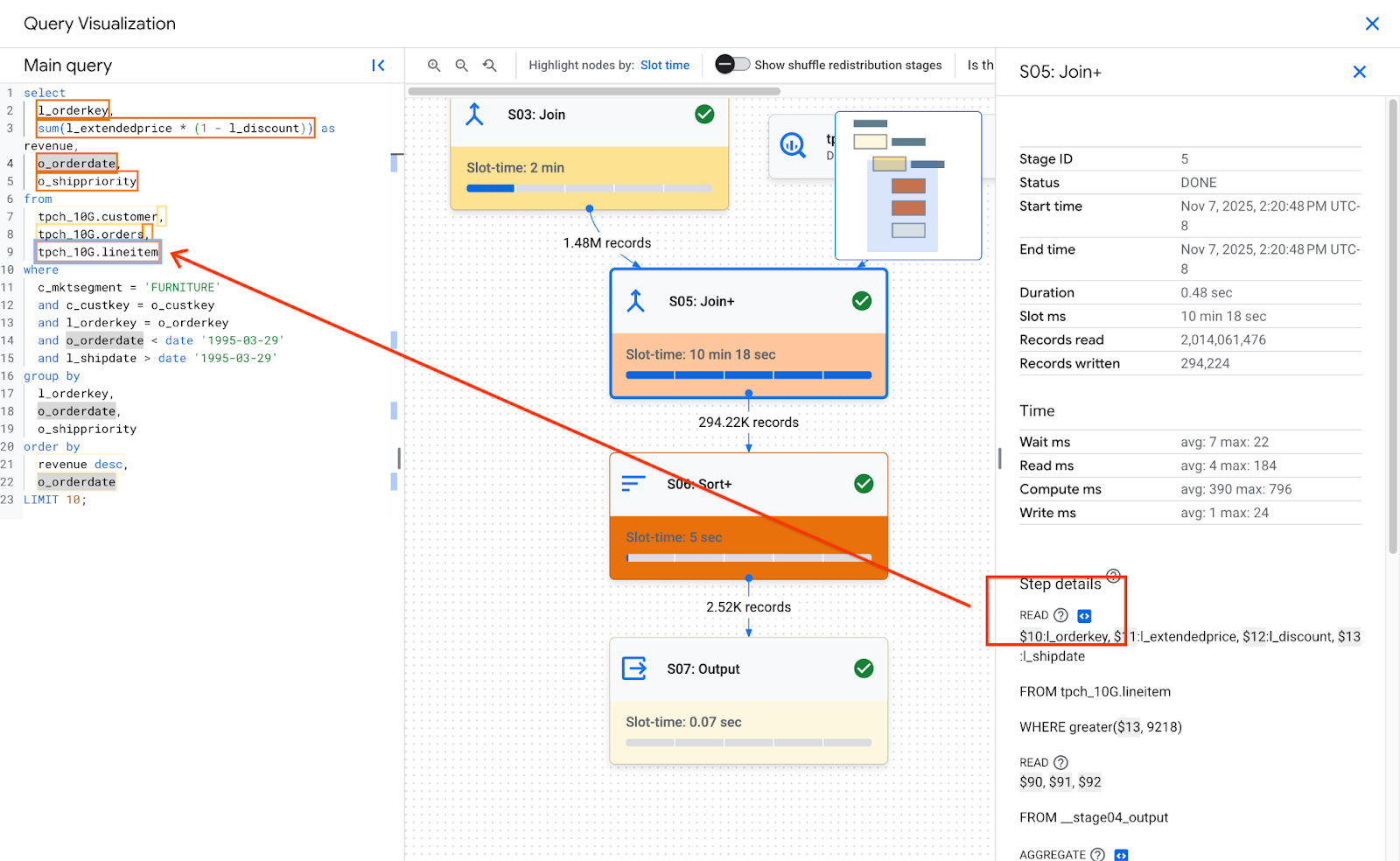
שלבים מורכבים מפעולות, שהן הפעולות הבודדות שמבצעות את הלוגיקה של השאילתה. לשלבים יש שלבי משנה שמתארים מה השלב עשה בפסאודו-קוד. בשלבי משנה נעשה שימוש במשתנים כדי לתאר את הקשרים בין השלבים. משתנים מתחילים בסימן דולר ואחריו מספר ייחודי. מספרים משתנים לא משותפים בין שלבים.
בתמונה הבאה מוצגים השלבים של שלב:
דוגמה לשלבים בשלב:
READ $30:l_orderkey, $31:l_quantity FROM lineitem AGGREGATE GROUP BY $100 := $30 $70 := SUM($31) WRITE $100, $70 TO __stage00_output BY HASH($100)
השלבים בדוגמה מתארים את הפעולות הבאות:
- בשלב הזה, העמודות l_orderkey ו-l_quantity נקראות מהטבלה lineitem והערכים מאוחסנים במשתנים $30 ו- $31, בהתאמה.
- בשלב הזה, המשתנים $30 ו-$31 צורפו, והערכים המצורפים נשמרו במשתנים $100 ו-$70, בהתאמה.
- השלב כתב את התוצאות של המשתנים $100 ו-$70 ל-shuffle. השלב סידר את התוצאות בזיכרון של ערבוב הנתונים על סמך 100$.
בקטע הסבר על השלבים ואופטימיזציה שלהם מפורט מידע על סוגי השלבים ועל אופטימיזציה שלהם.
יכול להיות ש-BigQuery יקצץ את שלבי המשנה אם גרף הביצוע של השאילתה היה מורכב מספיק כדי שמתן שלבי משנה מלאים יגרום לבעיות בגודל מטען הייעודי (payload) בזמן אחזור פרטי השאילתה.
מפת חום של טקסט השאילתה
BigQuery יכול למפות חלק מהשלבים של שלב לנתחים של טקסט השאילתה. במפת החום של טקסט השאילתה מוצג כל טקסט השאילתה התואם עם שלבי ההמרה. הכלי מדגיש את טקסט השאילתה על סמך סך הזמן של שלבים שבהם מופיע טקסט השאילתה.
בתמונה הבאה אפשר לראות את הטקסט של השאילתה שמודגש:
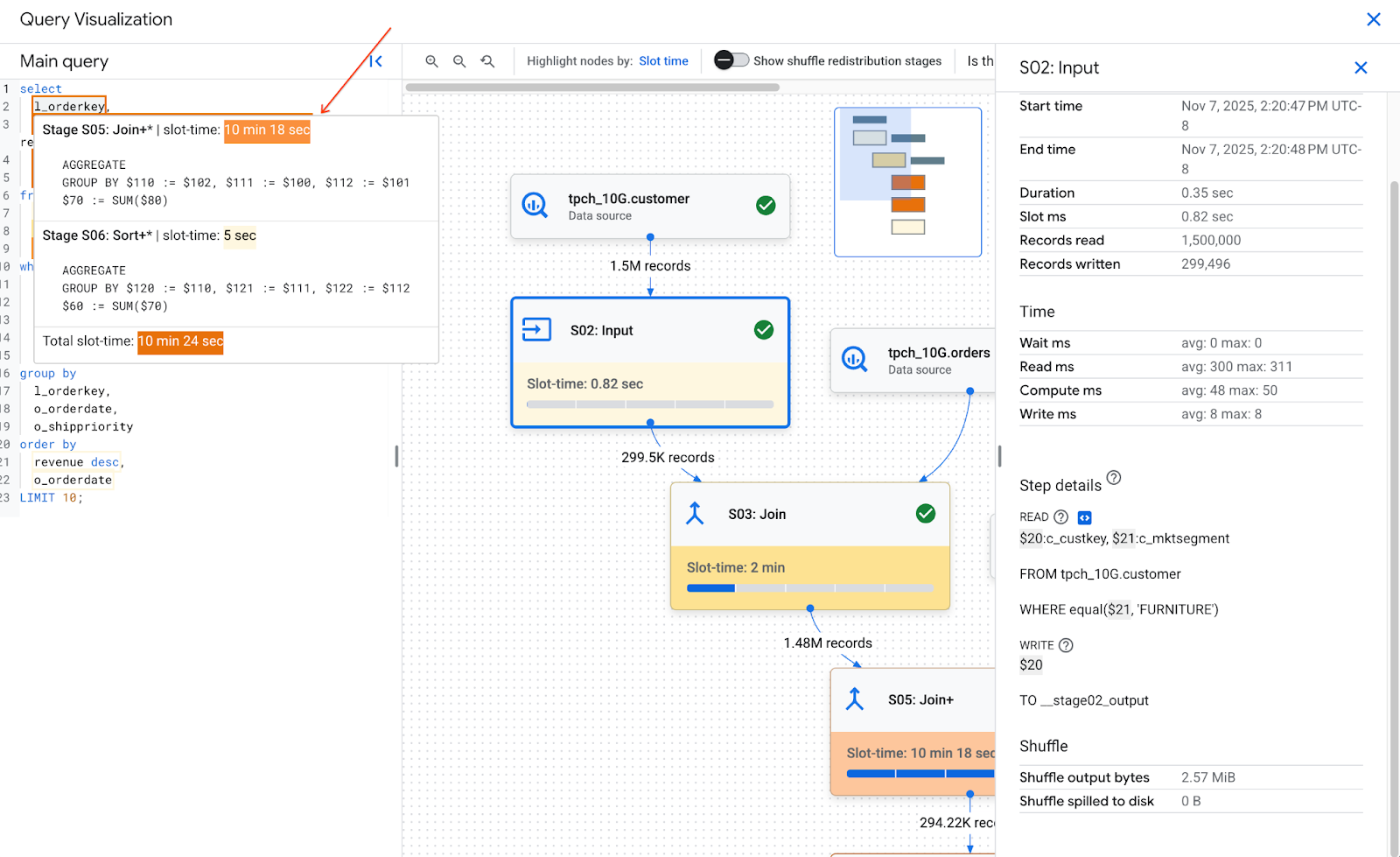
כשמעבירים את מצביע העכבר מעל חלק ממופה של טקסט השאילתה, מוצג תיאור קצר שבו מפורטים כל השלבים של שלב המיפוי לטקסט השאילתה, יחד עם משך הזמן של משבצת הזמן של השלב. אם לוחצים על טקסט של שאילתה ממופה, השלב נבחר בתרשים הביצוע ופרטי השלב נפתחים בחלונית השמאלית.
חלק אחד של טקסט השאילתה יכול להיות ממופה לכמה שלבים. בהסבר הקצר מופיעה רשימה של כל שלב ממופה ומשבצת הזמן שלו. כשלוחצים על טקסט השאילתה, השלבים התואמים מודגשים ושאר התרשים מוצג באפור. אחר כך לוחצים על שלב ספציפי כדי לראות את הפרטים שלו.
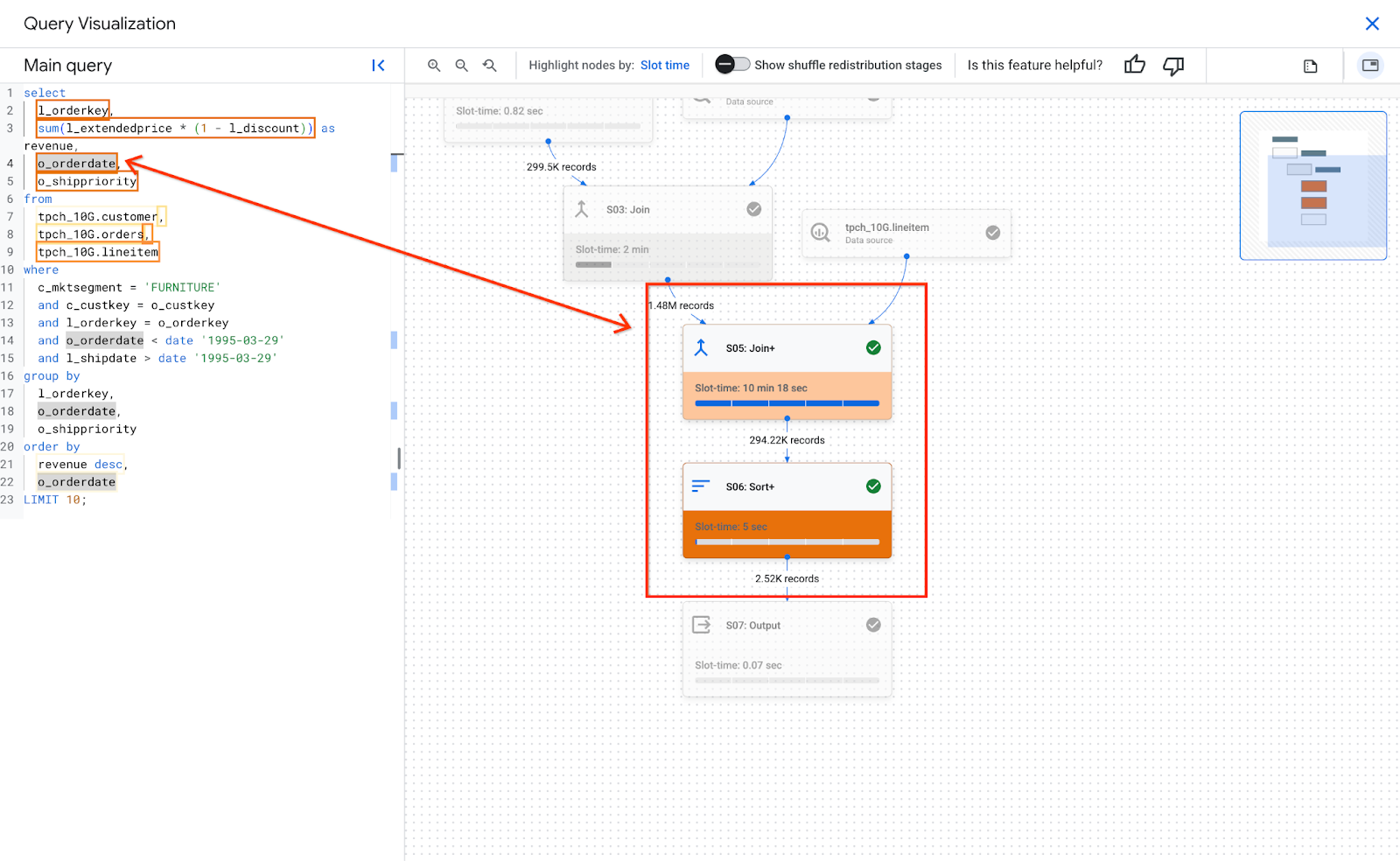
בתמונה הבאה אפשר לראות איך הטקסט של השאילתה קשור לפרטי השלב:
בקטע פרטי השלב של שלב מסוים, אם השלב ממופה לטקסט של שאילתה, מופיע ליד השלב סמל של קוד. כשלוחצים על סמל הקוד, החלק הממופה של טקסט השאילתה בצד ימין מודגש.
חשוב לזכור שצבע מפת החום מבוסס על משבצת הזמן של כל השלב. מכיוון ש-BigQuery לא מודד את זמן המשבצת של השלבים, מפת החום לא מייצגת את זמן המשבצת בפועל עבור החלק הספציפי הזה של טקסט השאילתה הממופה. ברוב המקרים, שלב מבצע רק פעולה מורכבת אחת, כמו צירוף או צבירה. לכן, צבע מפת החום מתאים. עם זאת, כששלב מורכב משלבים שמבצעים כמה פעולות מורכבות, יכול להיות שהצבע במפת החום ייצג בצורה מוגזמת את הזמן בפועל של משבצת הזמן במפת החום. במקרים כאלה, חשוב להבין את השלבים האחרים שמרכיבים את השלב כדי לקבל תמונה מלאה יותר של ביצועי השאילתה.
אם שאילתה משתמשת בתצוגות, ולשלבים של השלב יש מיפוי לטקסט השאילתה של התצוגה, מפת החום של טקסט השאילתה מציגה את שם התצוגה ואת טקסט השאילתה של התצוגה עם המיפויים שלהם. עם זאת, אם התצוגה המפורטת נמחקת או אם מאבדים את bigquery.tables.get הרשאת IAM בתצוגה המפורטת, מפת החום של טקסט השאילתה לא מציגה את המיפויים של שלבי השלב בתצוגה המפורטת.
סקירה כללית של השלב
השדות של הסקירה הכללית בכל שלב יכולים לכלול את הפרטים הבאים:
| שדה API | תיאור |
|---|---|
id |
מזהה מספרי ייחודי של השלב. |
name |
שם פשוט של השלב. הsteps בשלב מספקים פרטים נוספים על שלבי הביצוע. |
status |
סטטוס הביצוע של השלב. הסטטוסים האפשריים הם PENDING, RUNNING, COMPLETE, FAILED ו-CANCELLED. |
inputStages |
רשימה של המזהים שיוצרים את גרף התלות של השלב. לדוגמה, שלב JOIN לרוב צריך שני שלבים תלויים שמכינים את הנתונים בצד שמאל ובצד ימין של קשר ה-JOIN. |
startMs |
חותמת זמן, במיליוניות השנייה של תקופת ה-Epoch, שמייצגת את המועד שבו העובד הראשון בשלב התחיל את ההרצה. |
endMs |
חותמת זמן, באלפיות השנייה של תקופת Unix, שמייצגת את הזמן שבו העובד האחרון סיים את ההרצה. |
steps |
רשימה מפורטת יותר של שלבי הביצוע בשלב. מידע נוסף מפורט בקטע הבא. |
recordsRead |
גודל הקלט של השלב כמספר רשומות, בכל העובדים של השלב. |
recordsWritten |
גודל הפלט של השלב כמספר רשומות, בכל העובדים בשלב. |
parallelInputs |
מספר יחידות העבודה שניתן להריץ במקביל בשלב. בהתאם לשלב ולשאילתה, הערך הזה יכול לייצג את מספר המקטעים העמודתיים בטבלה, או את מספר המחיצות בערבוב ביניים. |
completedParallelInputs |
מספר היחידות שבוצעו בשלב. בחלק מהשאילתות, לא צריך להשלים את כל הקלט בשלב מסוים כדי שהשלב יושלם. |
shuffleOutputBytes |
מייצג את מספר הבייטים הכולל שנכתב בכל העובדים בשלב של שאילתה. |
shuffleOutputBytesSpilled |
יכול להיות ששאילתות שמעבירות נתונים משמעותיים בין שלבים יצטרכו לחזור להעברה מבוססת-דיסק. הנתון הסטטיסטי 'בייטים שנשפכו' מציין כמה נתונים נשפכו לדיסק. היא תלויה באלגוריתם אופטימיזציה, ולכן היא לא דטרמיניסטית עבור שאילתה נתונה. |
סיווג תזמון לפי שלב
בשלבי השאילתה מופיעות סיווגים של תזמון השלבים, גם יחסיים וגם מוחלטים. כל שלב בהפעלה מייצג עבודה שבוצעה על ידי עובד עצמאי אחד או יותר, ולכן המידע מסופק גם בזמנים ממוצעים וגם בזמנים של המקרה הגרוע ביותר. הזמנים האלה מייצגים את הביצועים הממוצעים של כל העובדים בשלב מסוים, וגם את הביצועים של העובד הכי איטי בזנב הארוך של ההתפלגות, בסיווג נתון. בנוסף, זמני הממוצע והמקסימום מחולקים לייצוגים מוחלטים ויחסיים. בנתונים סטטיסטיים שמבוססים על יחס, הנתונים מוצגים כשבר של הזמן הארוך ביותר שכל עובד בילה בכל פלח.
במסוף Google Cloud מוצגות תזמונים של שלבים באמצעות ייצוגים של תזמון יחסי.
המידע על התזמון של השלבים מדווח באופן הבא:
| תזמון יחסי | תזמון מוחלט | מונה היחס |
|---|---|---|
waitRatioAvg |
waitMsAvg |
משך הזמן הממוצע שבו עובד המתין לשיבוץ. |
waitRatioMax |
waitMsMax |
הזמן שבו העובד האיטי ביותר המתין לשיבוץ. |
readRatioAvg |
readMsAvg |
הזמן הממוצע שבו העובד קרא את נתוני הקלט. |
readRatioMax |
readMsMax |
הזמן שהעובד הכי איטי השקיע בקריאת נתוני הקלט. |
computeRatioAvg |
computeMsAvg |
הזמן הממוצע שבו עובד היה מוגבל על ידי המעבד. |
computeRatioMax |
computeMsMax |
הזמן שבו העובד הכי איטי היה מוגבל על ידי המעבד. |
writeRatioAvg |
writeMsAvg |
הזמן הממוצע שבו עובד השקיע בכתיבת נתוני הפלט. |
writeRatioMax |
writeMsMax |
הזמן שחלף מההתחלה עד הסיום של העובד הכי איטי בכתיבת נתוני הפלט. |
סקירת השלב
השלבים מכילים את הפעולות שכל עובד בשלב מסוים מבצע, והם מוצגים כרשימה מסודרת של פעולות. לכל פעולה בשלב יש קטגוריה, ובחלק מהפעולות יש מידע מפורט יותר. קטגוריות הפעולות שמוצגות בתוכנית השאילתה כוללות את הפעולות הבאות:
| קטגוריית השלב | תיאור |
|---|---|
READ |
קריאה של עמודה אחת או יותר מטבלת קלט או מפעולת ערבוב ביניים. רק שש עשרה העמודות הראשונות שנקראות מוחזרות בפרטי השלב. |
WRITE |
פעולת כתיבה של עמודה אחת או יותר לטבלת פלט או לערבוב ביניים. עבור HASH פלט מחולק למחיצות משלב, כולל גם העמודות שמשמשות כמפתח המחיצה. |
COMPUTE |
הערכת ביטויים ופונקציות SQL. |
FILTER |
השימוש הוא בסעיפים WHERE, OMIT IF ו-HAVING. |
SORT |
פעולת ORDER BY שכוללת את מפתחות העמודות ואת סדר המיון. |
AGGREGATE |
מיישם צבירות עבור סעיפים כמו GROUP BY או COUNT, בין היתר. |
LIMIT |
מטמיע את סעיף LIMIT. |
JOIN |
מיישם הצטרפות לסעיפים כמו JOIN, בין היתר; כולל את סוג ההצטרפות ואולי את תנאי ההצטרפות. |
ANALYTIC_FUNCTION |
הפעלה של פונקציית חלון (נקראת גם 'פונקציה אנליטית'). |
USER_DEFINED_FUNCTION |
קריאה לפונקציה בהגדרת המשתמש. |
פרשנות ואופטימיזציה של השלבים
בקטעים הבאים מוסבר איך לפרש את השלבים בתוכנית שאילתה ומוצגות דרכים לאופטימיזציה של השאילתות.
READ צעד
בשלב READ מתבצעת גישה לנתונים לצורך עיבוד. אפשר לקרוא את הנתונים ישירות מהטבלאות שאליהן מתייחסת השאילתה, או מזיכרון ה-Shuffle.
כשקוראים נתונים משלב קודם, BigQuery קורא נתונים מזיכרון ה-shuffle. כמות הנתונים שנסרקים משפיעה על העלות כשמשתמשים במשבצות על פי דרישה, ועל הביצועים כשמשתמשים בהזמנות.
בעיות אפשריות בביצועים
- סריקה גדולה של טבלה לא מחולקת: אם השאילתה צריכה רק חלק קטן מהנתונים, יכול להיות שסריקת הטבלה לא יעילה. חלוקה למחיצות יכולה להיות אסטרטגיית אופטימיזציה טובה.
- סריקה של טבלה גדולה עם יחס סינון קטן: מצב כזה מצביע על כך שהמסנן לא מצליח לצמצם את כמות הנתונים שנסרקים. כדאי לשנות את תנאי המסנן.
- ערבוב של בייטים שגולשים לדיסק: מצביע על כך שהנתונים לא מאוחסנים בצורה יעילה באמצעות טכניקות אופטימיזציה כמו אשכולות, שיכולות לשמור נתונים דומים באשכולות.
אופטימיזציה
- סינון ממוקד: כדאי להשתמש בסעיפי
WHEREבאופן אסטרטגי כדי לסנן נתונים לא רלוונטיים מוקדם ככל האפשר בשאילתה. כך מצמצמים את כמות הנתונים שצריך לעבד בשאילתה. - חלוקה למחיצות וסידור באשכולות: BigQuery משתמש בחלוקה למחיצות ובסידור באשכולות של טבלאות כדי לאתר ביעילות פלחי נתונים ספציפיים.
כדי לצמצם את כמות הנתונים שנסרקים במהלך השלבים של
READ, חשוב לוודא שהטבלאות מחולקות למחיצות ומקובצות באשכולות על סמך דפוסי השאילתות האופייניים. - בחירת עמודות רלוונטיות: מומלץ להימנע משימוש בהצהרות
SELECT *. במקום זאת, בוחרים עמודות ספציפיות או משתמשים ב-SELECT * EXCEPTכדי להימנע מקריאת נתונים מיותרים. - תצוגות חומריות: תצוגות חומריות יכולות לבצע מראש חישובים ולאחסן צבירות בשימוש תדיר, וכך לצמצם את הצורך בקריאת טבלאות בסיס במהלך שלבי
READשל שאילתות שמשתמשות בתצוגות האלה.
COMPUTE צעד
בשלב COMPUTE, מערכת BigQuery מבצעת את הפעולות הבאות על הנתונים שלכם:
- הפונקציה מעריכה ביטויים בסעיפים
SELECT,WHERE,HAVINGוסעיפים אחרים בשאילתה, כולל חישובים, השוואות ופעולות לוגיות. - מבצעת פונקציות SQL מובנות ופונקציות בהגדרת המשתמש.
- מסננים שורות של נתונים על סמך תנאים בשאילתה.
אופטימיזציה
תוכנית השאילתה יכולה לחשוף צווארי בקבוק בשלב COMPUTE. כדאי לחפש שלבים עם חישובים נרחבים או מספר גדול של שורות שעברו עיבוד.
- השוואה בין שלב
COMPUTEלבין נפח הנתונים: אם בשלב מסוים מתבצעים חישובים משמעותיים והוא מעבד נפח גדול של נתונים, יכול להיות שכדאי לבצע אופטימיזציה לשלב הזה. - Skewed data: for stages where the compute maximum is significantly higher than the compute average, this indicates that the stage spent a disproportionate amount of time processing a few slices of data. כדאי לבדוק את התפלגות הנתונים כדי לראות אם יש חלוקת נתונים לא מאוזנת.
- שימוש בסוגי נתונים: חשוב להשתמש בסוגי נתונים מתאימים לעמודות. לדוגמה, שימוש במספרים שלמים, בתאריכים ובחותמות זמן במקום במחרוזות יכול לשפר את הביצועים.
WRITE צעד
WRITE השלבים מתבצעים עבור נתונים ביניים ופלט סופי.
- כתיבה לזיכרון של ערבוב: בשאילתה מרובת שלבים, שלב
WRITEלרוב כולל שליחת הנתונים המעובדים לשלב אחר לעיבוד נוסף. זה אופייני לזיכרון של פעולת ערבוב, שמשלב או צובר נתונים מכמה מקורות. הנתונים שנכתבים בשלב הזה הם בדרך כלל תוצאת ביניים, ולא הפלט הסופי. - פלט סופי: תוצאת השאילתה נכתבת ליעד או לטבלה זמנית.
חלוקה למחיצות באמצעות גיבוב
כששלב בתוכנית השאילתה כותב נתונים לפלט עם חלוקה למחיצות באמצעות גיבוב, BigQuery כותב את העמודות שכלולות בפלט ואת העמודה שנבחרה כמפתח המחיצה.
אופטימיזציה
יכול להיות שאי אפשר לבצע אופטימיזציה ישירה של שלב WRITE, אבל הבנת התפקיד שלו יכולה לעזור לכם לזהות צווארי בקבוק פוטנציאליים בשלבים מוקדמים יותר:
- צמצום כמות הנתונים שנכתבים: כדאי להתמקד באופטימיזציה של השלבים הקודמים באמצעות סינון וצבירה כדי לצמצם את כמות הנתונים שנכתבים במהלך השלב הזה.
חלוקה למחיצות: כתיבה נהנית מאוד מחלוקה למחיצות בטבלה. אם הנתונים שאתם כותבים מוגבלים למחיצות ספציפיות, BigQuery יכול לבצע כתיבה מהירה יותר.
אם פקודת ה-DML כוללת פסקה
WHEREעם תנאי סטטי ביחס לעמודת חלוקה למחיצות של טבלה, BigQuery משנה רק את המחיצות הרלוונטיות של הטבלה.הפשרות של דה-נורמליזציה: לפעמים דה-נורמליזציה יכולה להוביל לתוצאות קטנות יותר בשלב הביניים
WRITE. עם זאת, יש חסרונות כמו שימוש מוגבר בנפח אחסון נדרש ובעיות בעקביות הנתונים.
JOIN צעד
בשלב JOIN, BigQuery משלב נתונים משני מקורות נתונים.
הצטרפות יכולה לכלול תנאי הצטרפות. הצטרפות הן פעולות שדורשות הרבה משאבים. כשמבצעים איחוד של נתונים גדולים ב-BigQuery, מפתחות האיחוד עוברים מיון (shuffle) באופן עצמאי כדי להתאים למשבצת זמן זהה, כך שהאיחוד מתבצע באופן מקומי בכל משבצת זמן.
בדרך כלל, תוכנית השאילתה של שלב JOIN חושפת את הפרטים הבאים:
- דפוס הצטרפות: מציין את סוג ההצטרפות שנעשה בו שימוש. כל סוג מגדיר כמה שורות מהטבלאות המצורפות נכללות בקבוצת התוצאות.
- עמודות לאיחוד: אלה העמודות שמשמשות להתאמת שורות בין מקורות הנתונים. בחירת העמודות היא קריטית לביצועים של הפעולה join.
דפוסי הצטרפות
- איחוד שידור: אם טבלה אחת, בדרך כלל הקטנה יותר, יכולה להיכנס לזיכרון בצומת עובד או במשבצת אחת, BigQuery יכול לשדר אותה לכל הצמתים האחרים כדי לבצע את האיחוד ביעילות. מחפשים את
JOIN EACH WITH ALLבפרטי השלב. - Hash join: כשמדובר בטבלאות גדולות או כש-broadcast join לא מתאים, יכול להיות שייעשה שימוש ב-hash join. מערכת BigQuery משתמשת בפעולות של גיבוב (hash) וערבוב (shuffle) כדי לערבב את הטבלאות השמאלית והימנית, כך שהמפתחות התואמים יגיעו לאותו משבצת כדי לבצע איחוד מקומי. הצטרפות באמצעות Hash היא פעולה יקרה כי צריך להעביר את הנתונים, אבל היא מאפשרת התאמה יעילה של שורות בין ערכי ה-Hash. מחפשים את
JOIN EACH WITH EACHבפרטי השלב. - צירוף עצמי: תבנית אנטי ב-SQL שבה טבלה מצורפת לעצמה.
- Cross join: תבנית אנטי-תבנית של SQL שיכולה לגרום לבעיות משמעותיות בביצועים כי היא יוצרת נתוני פלט גדולים יותר מהנתונים שהוזנו.
- הצטרפות מוטה: פיזור הנתונים במפתח ההצטרפות בטבלה אחת מוטה מאוד ויכול להוביל לבעיות בביצועים. מחפשים מקרים שבהם זמן החישוב המקסימלי גדול בהרבה מזמן החישוב הממוצע בתוכנית השאילתה. מידע נוסף זמין במאמרים בנושא צירוף עם עוצמה גבוהה והטיה של מחיצה.
ניפוי באגים
- נפח נתונים גדול: אם תוכנית השאילתה מראה כמות משמעותית של נתונים שעברו עיבוד במהלך שלב
JOIN, כדאי לבדוק את תנאי הצירוף ואת מפתחות הצירוף. כדאי לסנן או להשתמש במפתחות איחוד סלקטיביים יותר. - התפלגות נתונים מוטה: ניתוח של התפלגות הנתונים של מפתחות האיחוד. אם טבלה אחת מוטה מאוד, כדאי לנסות אסטרטגיות כמו פיצול השאילתה או סינון מראש.
- צירופים עם עוצמה גבוהה: צירופים שמניבים הרבה יותר שורות ממספר שורות הקלט בצד שמאל ובצד ימין יכולים להפחית באופן משמעותי את ביצועי השאילתה. כדאי להימנע מצירופים שמפיקים מספר גדול מאוד של שורות.
- סדר לא נכון של הטבלה: צריך לוודא שבחרתם את סוג הצירוף המתאים, כמו
INNERאוLEFT, ושהטבלאות מסודרות מהגדולה ביותר לקטנה ביותר בהתאם לדרישות של השאילתה.
אופטימיזציה
- מקשי צירוף סלקטיביים: כשמשתמשים במקשי צירוף, כדאי להשתמש ב-
INT64במקום ב-STRINGאם אפשר. השוואות שלSTRINGאיטיות יותר מהשוואות שלINT64כי הן משוות כל תו במחרוזת. מספרים שלמים דורשים השוואה אחת בלבד. - סינון לפני הצטרפות: החלת מסנני פסקה
WHEREעל טבלאות נפרדות לפני ההצטרפות. כך מצמצמים את כמות הנתונים שמשתתפים בפעולת הצירוף. - מומלץ להימנע משימוש בפונקציות בעמודות של הצטרפות: מומלץ להימנע מהפעלת פונקציות בעמודות של הצטרפות. במקום זאת, אפשר לתקנן את נתוני הטבלה במהלך תהליך ההטמעה או אחריו באמצעות צינורות ELT SQL. הגישה הזו מבטלת את הצורך לשנות באופן דינמי עמודות של צירוף, וכך מאפשרת צירופים יעילים יותר בלי לפגוע בתקינות הנתונים.
- הימנעות מ-self-joins: בדרך כלל משתמשים ב-self-joins כדי לחשב קשרים שתלויים בשורה. עם זאת, שאילתות איחוד עצמי יכולות להגדיל פי ארבע את מספר השורות בתוצאה, ולגרום לבעיות בביצועים. במקום להסתמך על צירופים עצמיים, כדאי להשתמש בפונקציות אנליטיות (window functions).
- קודם טבלאות גדולות: למרות שאופטימיזציית שאילתות ה-SQL יכולה לקבוע איזו טבלה צריכה להיות בכל צד של הצירוף, כדאי לסדר את הטבלאות המצורפות בהתאם. השיטה המומלצת היא להציב את הטבלה הגדולה ביותר ראשונה, ואחריה את הטבלה הקטנה ביותר, ואז את הטבלאות לפי סדר יורד של הגודל.
- דה-נורמליזציה: במקרים מסוימים, ביצוע דה-נורמליזציה אסטרטגית של טבלאות (הוספת נתונים מיותרים) יכול לבטל את הצורך בצירופים. עם זאת, לגישה הזו יש חסרונות מבחינת אחסון ועקביות הנתונים.
- חלוקה למחיצות וקיבוץ לאשכולות: חלוקת טבלאות למחיצות על סמך מפתחות איחוד וקיבוץ נתונים שמוצבים יחד לאשכולות יכולים להאיץ משמעותית את האיחודים, כי הם מאפשרים ל-BigQuery להתמקד במחיצות נתונים רלוונטיות.
- אופטימיזציה של שאילתות איחוד מוטות: כדי למנוע בעיות בביצועים שקשורות לשאילתות איחוד מוטות, כדאי לסנן מראש נתונים מהטבלה מוקדם ככל האפשר או לפצל את השאילתה לשתי שאילתות או יותר.
AGGREGATE צעד
בAGGREGATE, מערכת BigQuery מצברת ומקבצת את הנתונים.
ניפוי באגים
- פרטי השלב: בודקים את מספר שורות הקלט ומספר שורות הפלט של הצבירה, ואת גודל הערבוב כדי לקבוע כמה נתונים צומצמו בשלב הצבירה והאם היה מעורב ערבוב נתונים.
- גודל הערבוב: גודל ערבוב גדול עשוי להצביע על כך שכמות משמעותית של נתונים הועברה בין צמתי עובדים במהלך הצבירה.
- בודקים את חלוקת הנתונים: מוודאים שהנתונים מחולקים באופן שווה בין המחיצות. התפלגות נתונים מוטה עלולה להוביל לעומסי עבודה לא מאוזנים בשלב הצבירה.
- בדיקת צבירות: ניתוח של סעיפי הצבירה כדי לוודא שהם נחוצים ויעילים.
אופטימיזציה
- אשכולות: כדאי ליצור אשכולות בטבלאות בעמודות שנמצאות בשימוש תדיר ב-
GROUP BY, ב-COUNTאו בסעיפים אחרים של צבירת נתונים. - חלוקה למחיצות: בוחרים שיטת חלוקה למחיצות שמתאימה לדפוסי השאילתות שלכם. מומלץ להשתמש בטבלאות מחולקות למחיצות בזמן ההטמעה כדי לצמצם את כמות הנתונים שנסרקים במהלך הצבירה.
- צריך לצבור נתונים מוקדם יותר: אם אפשר, כדאי לבצע צבירות בשלב מוקדם יותר בצינור של השאילתה. כך אפשר לצמצם את כמות הנתונים שצריך לעבד במהלך הצבירה.
- אופטימיזציה של ערבוב: אם ערבוב הוא צוואר בקבוק, כדאי לחפש דרכים לצמצם אותו. לדוגמה, אפשר לבצע דה-נורמליזציה של טבלאות או להשתמש באשכולות כדי למקם נתונים רלוונטיים באותו מקום.
מקרי קצה
- מצטברים מסוג DISTINCT: שאילתות עם מצטברים מסוג
DISTINCTיכולות להיות יקרות מבחינת חישובים, במיוחד במערכי נתונים גדולים. כדי לקבל תוצאות משוערות, אפשר להשתמש בחלופות כמוAPPROX_COUNT_DISTINCT. - מספר גדול של קבוצות: אם השאילתה יוצרת מספר גדול של קבוצות, יכול להיות שהיא תצרוך כמות גדולה של זיכרון. במקרים כאלה, כדאי לחשוב על הגבלת מספר הקבוצות או על שימוש באסטרטגיית צבירה אחרת.
REPARTITION צעד
REPARTITION ו-COALESCE הן טכניקות אופטימיזציה ש-BigQuery מחיל ישירות על הנתונים המעורבבים בשאילתה.
-
REPARTITION: המטרה של הפעולה הזו היא לאזן מחדש את חלוקת הנתונים בין צמתי העובדים. נניח שאחרי הערבוב, צומת עובד אחד מקבל כמות גדולה באופן לא פרופורציונלי של נתונים. בשלבREPARTITION, הנתונים מחולקים מחדש בצורה אחידה יותר, כדי למנוע מצב שבו עובד יחיד יהפוך לצוואר בקבוק. הדבר חשוב במיוחד לפעולות שדורשות הרבה משאבי מחשוב, כמו פעולות join. -
COALESCE: השלב הזה מתרחש כשמערבבים הרבה קבוצות קטנות של נתונים. בשלבCOALESCE, המערכת משלבת את הקטגוריות האלה לקטגוריות גדולות יותר, וכך מצמצמת את התקורה שקשורה לניהול של הרבה נתונים קטנים. האפשרות הזו יכולה להיות שימושית במיוחד כשעובדים עם קבוצות קטנות מאוד של תוצאות ביניים.
אם אתם רואים שלבים עם REPARTITION או COALESCE בתוכנית השאילתה, זה לא אומר בהכרח שיש בעיה בשאילתה. לרוב זהו סימן לכך ש-BigQuery מבצע אופטימיזציה פרואקטיבית של חלוקת הנתונים כדי לשפר את הביצועים. עם זאת, אם אתם רואים את הפעולות האלה שוב ושוב, יכול להיות שהנתונים שלכם מוטים באופן מובנה או שהשאילתה גורמת לערבוב מוגזם של נתונים.
אופטימיזציה
כדי לצמצם את מספר השלבים של REPARTITION, אפשר לנסות את הפעולות הבאות:
- חלוקת נתונים: מוודאים שהטבלאות מחולקות למחיצות ומקובצות בצורה יעילה. נתונים שמפוזרים בצורה טובה מקטינים את הסיכוי לחוסר איזון משמעותי אחרי ערבוב.
- מבנה השאילתה: ניתוח השאילתה כדי לזהות מקורות פוטנציאליים של חלוקת נתונים לא מאוזנת (partition skew). לדוגמה, האם יש מסננים או הצטרפויות סלקטיביים מאוד שגורמים לעיבוד של קבוצת משנה קטנה של נתונים על עובד יחיד?
- אסטרטגיות של צירוף: כדאי להתנסות באסטרטגיות שונות של צירוף כדי לראות אם הן מובילות לפיזור נתונים מאוזן יותר.
כדי לצמצם את מספר השלבים של COALESCE, אפשר לנסות את הפעולות הבאות:
- שיטות צבירה: מומלץ לבצע צבירות מוקדם יותר בצינור של שאילתות. הפעולה הזו יכולה לעזור לצמצם את מספר קבוצות התוצאות הקטנות שמתקבלות בשלבים שונים, שעלולות לגרום ל
COALESCE. - נפח הנתונים: אם מדובר במערכי נתונים קטנים מאוד, יכול להיות ש
COALESCEלא יהיה גורם משמעותי.
אל תגזימו עם האופטימיזציה. אופטימיזציה מוקדמת מדי עלולה להפוך את השאילתות למורכבות יותר בלי להניב יתרונות משמעותיים.
הסבר על שאילתות לכמה מסדי נתונים
שאילתות מאוחדות מאפשרות לשלוח הצהרת שאילתה למקור נתונים חיצוני באמצעות הפונקציה EXTERNAL_QUERY.
שאילתות מאוחדות כפופות לטכניקת האופטימיזציה שנקראת SQL pushdowns, ובתוכנית השאילתות מוצגות פעולות שנדחפו למקור הנתונים החיצוני, אם יש כאלה. לדוגמה, אם מריצים את השאילתה הבאה:
SELECT id, name
FROM EXTERNAL_QUERY("<connection>", "SELECT * FROM company")
WHERE country_code IN ('ee', 'hu') AND name like '%TV%'
בתוכנית השאילתה יוצגו שלבי התהליך הבאים:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, country_code
FROM (
/*native_query*/
SELECT * FROM company
)
WHERE in(country_code, 'ee', 'hu')
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
במינוי הזה, table_for_external_query_$_0(...) מייצג את הפונקציה EXTERNAL_QUERY. בסוגריים אפשר לראות את השאילתה שמקור הנתונים החיצוני מריץ. על סמך זה, אפשר לראות ש:
- מקור נתונים חיצוני מחזיר רק 3 עמודות שנבחרו.
- מקור נתונים חיצוני מחזיר רק שורות שבהן
country_codeהוא'ee'או'hu'. - האופרטור
LIKEלא מועבר למטה ומחושב על ידי BigQuery.
לשם השוואה, אם אין פעולות pushdown, תוכנית השאילתה תציג את שלבי השלב הבאים:
$1:id, $2:name, $3:country_code
FROM table_for_external_query_$_0(
SELECT id, name, description, country_code, primary_address, secondary address
FROM (
/*native_query*/
SELECT * FROM company
)
)
WHERE and(in($3, 'ee', 'hu'), like($2, '%TV%'))
$1, $2
TO __stage00_output
במקרה הזה, מקור נתונים חיצוני מחזיר את כל העמודות ואת כל השורות מהטבלה company, ו-BigQuery מבצע סינון.
מטא-נתונים של ציר הזמן
ציר הזמן של השאילתה מציג את ההתקדמות בנקודות זמן ספציפיות, ומספק תמונות מצב של ההתקדמות הכוללת של השאילתה. ציר הזמן מיוצג כסדרה של דוגמאות שמדווחות על הפרטים הבאים:
| שדה | תיאור |
|---|---|
elapsedMs |
אלפיות השנייה שעברו מאז תחילת הביצוע של השאילתה. |
totalSlotMs |
ייצוג מצטבר של אלפיות השנייה של משבצת הזמן שבהן נעשה שימוש בשאילתה. |
pendingUnits |
סך כל יחידות העבודה שנקבעו להפעלה וממתינות להפעלה. |
activeUnits |
המספר הכולל של יחידות עבודה פעילות שעוברות עיבוד על ידי העובדים. |
completedUnits |
סך יחידות העבודה שהושלמו במהלך ביצוע השאילתה הזו. |
שאילתה לדוגמה
השאילתה הבאה סופרת את מספר השורות במערך הנתונים הציבורי של שייקספיר, ויש בה ספירה מותנית שנייה שמגבילה את התוצאות לשורות שכוללות את המילה hamlet:
SELECT
COUNT(1) as rowcount,
COUNTIF(corpus = 'hamlet') as rowcount_hamlet
FROM `publicdata.samples.shakespeare`
לוחצים על פרטי הביצוע כדי לראות את תוכנית השאילתה:
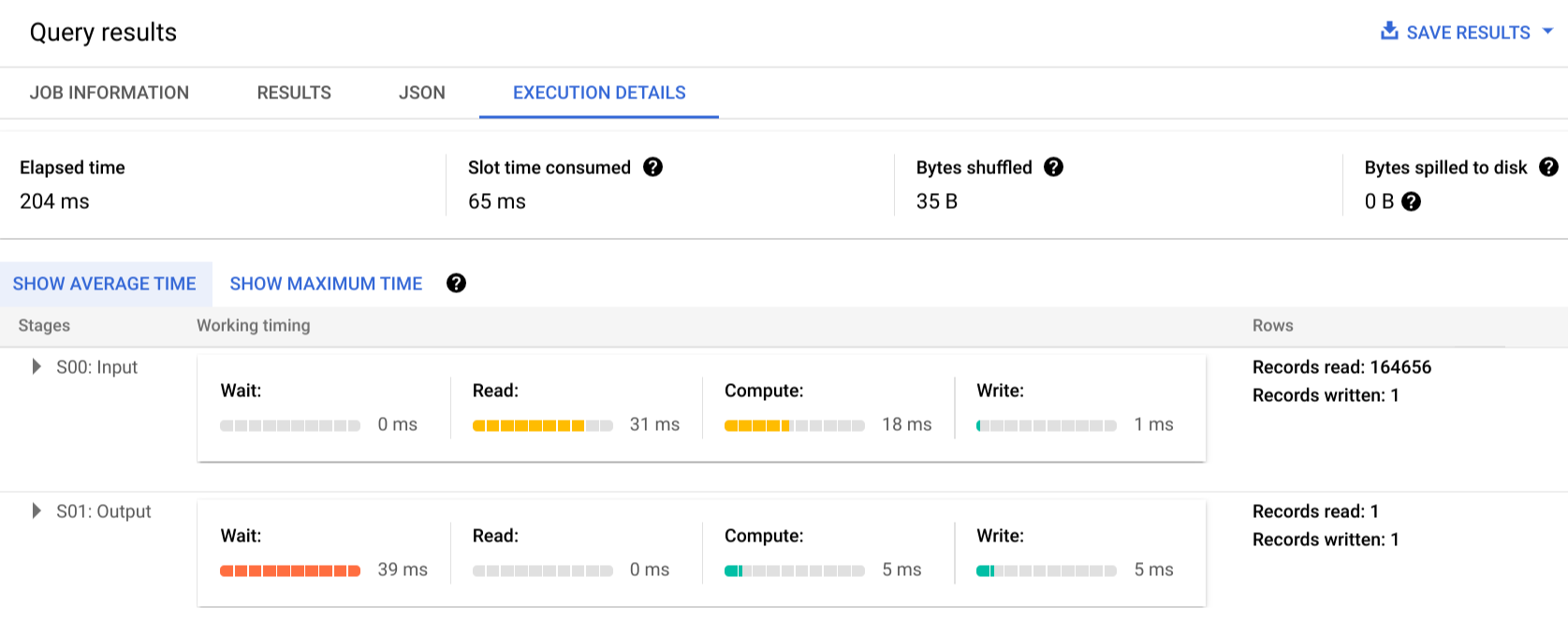
האינדיקטורים הצבעוניים מראים את התזמונים היחסיים של כל השלבים בכל השלבים.
כדי לקבל מידע נוסף על השלבים של שלבי ההרצה, לוחצים על כדי להרחיב את הפרטים של השלב:
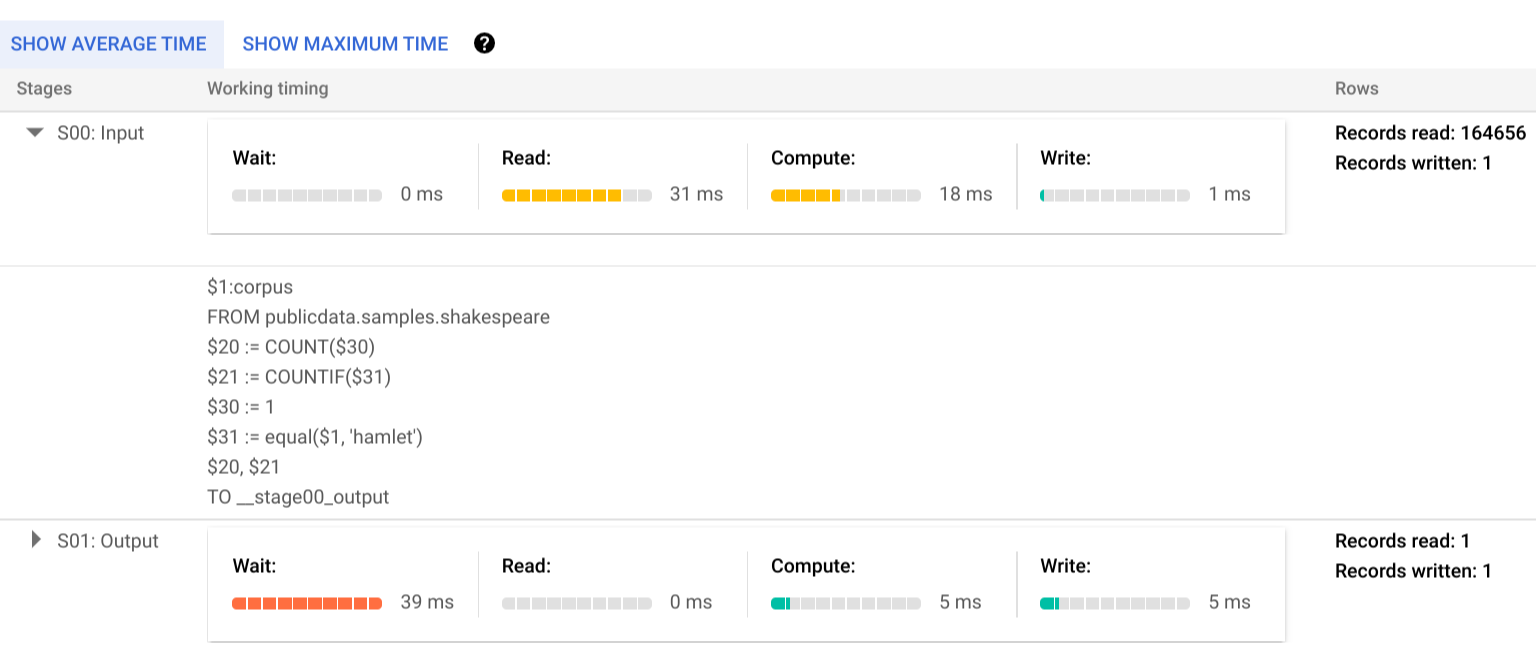
בדוגמה הזו, הזמן הארוך ביותר בכל קטע היה הזמן שבו העובד היחיד בשלב 01 המתין לסיום שלב 00. הסיבה לכך היא שהשלב 01 היה תלוי בקלט של השלב 00, ולא יכול היה להתחיל עד שהשלב הראשון כתב את הפלט שלו לערבוב הביניים.
דיווח על שגיאות
יכול להיות שמשימות של שאילתות ייכשלו באמצע ההרצה. המידע על התוכנית מתעדכן מעת לעת, כך שאפשר לראות בתרשים הביצוע איפה התרחשה השגיאה. במסוף Google Cloud , שלבים שהושלמו בהצלחה או נכשלו מסומנים בסימן וי או בסימן קריאה לצד שם השלב.
מידע נוסף על פירוש שגיאות ופתרון שלהן זמין במדריך לפתרון בעיות.
ייצוג לדוגמה של API
מידע על תוכנית השאילתה מוטמע במידע על תגובת העבודה, ואפשר לאחזר אותו על ידי קריאה ל-jobs.get.
לדוגמה, בקטע הבא של תגובת JSON לעיבוד משימה שבה מוחזרת שאילתת המלט לדוגמה, מוצגים גם תוכנית השאילתה וגם פרטי ציר הזמן.
"statistics": {
"creationTime": "1576544129234",
"startTime": "1576544129348",
"endTime": "1576544129681",
"totalBytesProcessed": "2464625",
"query": {
"queryPlan": [
{
"name": "S00: Input",
"id": "0",
"startMs": "1576544129436",
"endMs": "1576544129465",
"waitRatioAvg": 0.04,
"waitMsAvg": "1",
"waitRatioMax": 0.04,
"waitMsMax": "1",
"readRatioAvg": 0.32,
"readMsAvg": "8",
"readRatioMax": 0.32,
"readMsMax": "8",
"computeRatioAvg": 1,
"computeMsAvg": "25",
"computeRatioMax": 1,
"computeMsMax": "25",
"writeRatioAvg": 0.08,
"writeMsAvg": "2",
"writeRatioMax": 0.08,
"writeMsMax": "2",
"shuffleOutputBytes": "18",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "164656",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$1:corpus",
"FROM publicdata.samples.shakespeare"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$20 := COUNT($30)",
"$21 := COUNTIF($31)"
]
},
{
"kind": "COMPUTE",
"substeps": [
"$30 := 1",
"$31 := equal($1, 'hamlet')"
]
},
{
"kind": "WRITE",
"substeps": [
"$20, $21",
"TO __stage00_output"
]
}
]
},
{
"name": "S01: Output",
"id": "1",
"startMs": "1576544129465",
"endMs": "1576544129480",
"inputStages": [
"0"
],
"waitRatioAvg": 0.44,
"waitMsAvg": "11",
"waitRatioMax": 0.44,
"waitMsMax": "11",
"readRatioAvg": 0,
"readMsAvg": "0",
"readRatioMax": 0,
"readMsMax": "0",
"computeRatioAvg": 0.2,
"computeMsAvg": "5",
"computeRatioMax": 0.2,
"computeMsMax": "5",
"writeRatioAvg": 0.16,
"writeMsAvg": "4",
"writeRatioMax": 0.16,
"writeMsMax": "4",
"shuffleOutputBytes": "17",
"shuffleOutputBytesSpilled": "0",
"recordsRead": "1",
"recordsWritten": "1",
"parallelInputs": "1",
"completedParallelInputs": "1",
"status": "COMPLETE",
"steps": [
{
"kind": "READ",
"substeps": [
"$20, $21",
"FROM __stage00_output"
]
},
{
"kind": "AGGREGATE",
"substeps": [
"$10 := SUM_OF_COUNTS($20)",
"$11 := SUM_OF_COUNTS($21)"
]
},
{
"kind": "WRITE",
"substeps": [
"$10, $11",
"TO __stage01_output"
]
}
]
}
],
"estimatedBytesProcessed": "2464625",
"timeline": [
{
"elapsedMs": "304",
"totalSlotMs": "50",
"pendingUnits": "0",
"completedUnits": "2"
}
],
"totalPartitionsProcessed": "0",
"totalBytesProcessed": "2464625",
"totalBytesBilled": "10485760",
"billingTier": 1,
"totalSlotMs": "50",
"cacheHit": false,
"referencedTables": [
{
"projectId": "publicdata",
"datasetId": "samples",
"tableId": "shakespeare"
}
],
"statementType": "SELECT"
},
"totalSlotMs": "50"
},
שימוש בפרטי ההרצה
תוכניות השאילתות של BigQuery מספקות מידע על האופן שבו השירות מבצע שאילתות, אבל אופי השירות כמנוהל מגביל את האפשרות לפעול ישירות לפי חלק מהפרטים. הרבה אופטימיזציות מתבצעות באופן אוטומטי באמצעות השירות, וזה יכול להיות שונה מסביבות אחרות שבהן יכול להיות שיידרש צוות ייעודי ומיומן לצורך כוונון, הקצאת משאבים ומעקב.
טכניקות ספציפיות לשיפור הביצועים של שאילתות מפורטות במסמכי השיטות המומלצות. הנתונים הסטטיסטיים של תוכנית השאילתה וציר הזמן יכולים לעזור לכם להבין אם שלבים מסוימים תופסים חלק גדול מניצול המשאבים. לדוגמה, שלב JOIN שמייצר הרבה יותר שורות פלט משורות קלט יכול להצביע על הזדמנות לסנן מוקדם יותר בשאילתה.
בנוסף, המידע בציר הזמן יכול לעזור לזהות אם שאילתה מסוימת פועלת לאט בבידוד או בגלל השפעות משאילתות אחרות שמתחרות על אותם משאבים. אם אתם רואים שמספר היחידות הפעילות נשאר מוגבל לאורך משך החיים של השאילתה, אבל מספר היחידות של העבודה בתור נשאר גבוה, יכול להיות שמדובר במקרים שבהם צמצום מספר השאילתות המקבילות יכול לשפר באופן משמעותי את זמן הביצוע הכולל של שאילתות מסוימות.