
Obtén estadísticas de rendimiento de las consultas
El gráfico de ejecución de una consulta es una representación visual de los pasos que realiza BigQuery para ejecutar la consulta. En este documento, se describe cómo usar el gráfico de ejecución de consultas para diagnosticar problemas de rendimiento de consultas y ver estadísticas de rendimiento de las consultas.
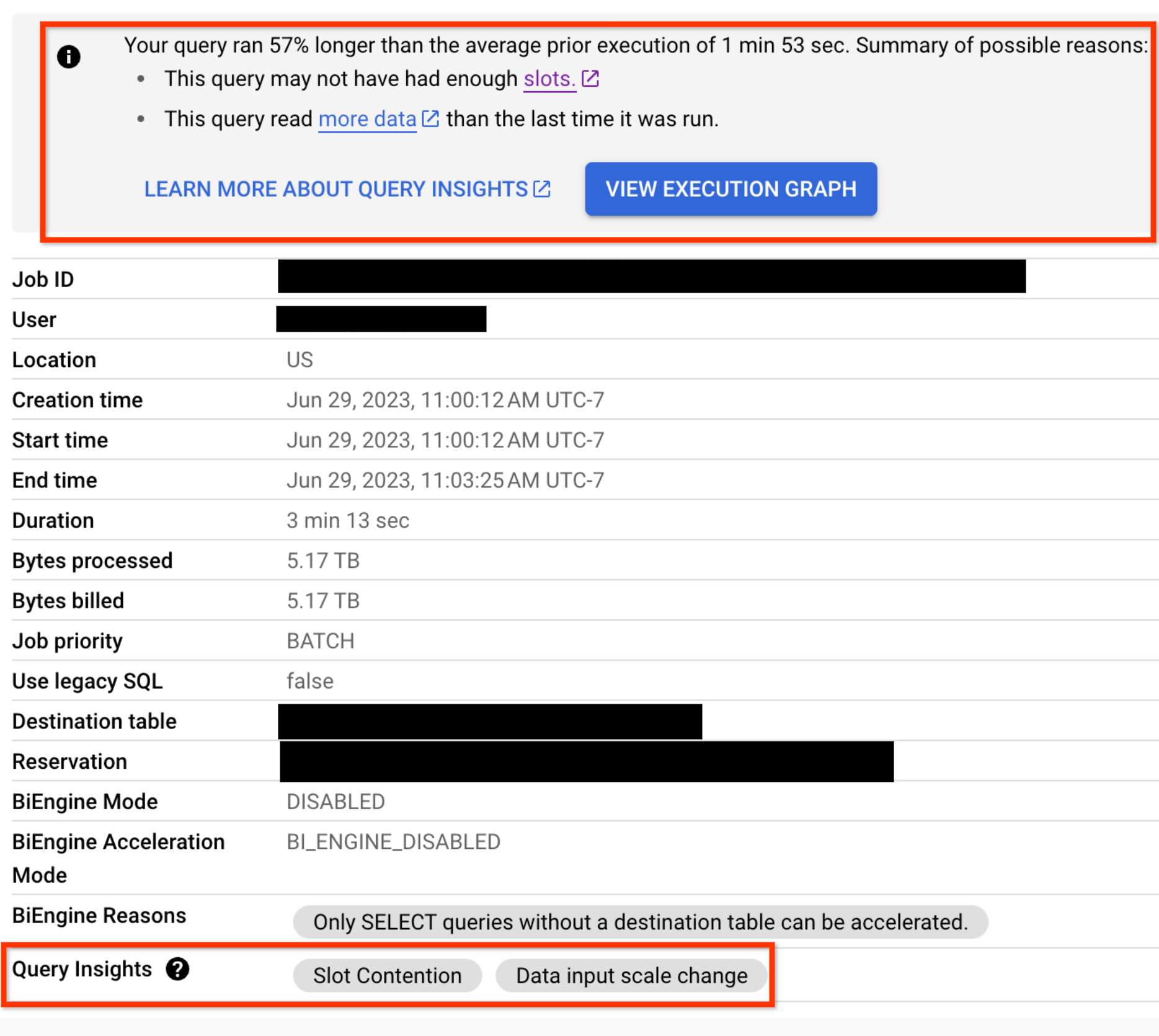
BigQuery ofrece un rendimiento de consultas sólido, pero también es un sistema distribuido con muchos factores internos y externos que pueden afectar la velocidad de consulta. La naturaleza declarativa de SQL también puede ocultar la complejidad de la ejecución de consultas. Esto significa que cuando las consultas se ejecutan de forma más lenta de lo previsto o más lento que las ejecuciones anteriores, comprender lo que sucedió puede ser un desafío.
El gráfico de ejecución de consultas proporciona una interfaz gráfica dinámica para inspeccionar el plan de consulta y los detalles de rendimiento de la consulta. Puedes revisar el gráfico de ejecución de consultas para cualquier consulta en ejecución o completada.
También puedes usar el gráfico de ejecución de consultas a fin de obtener estadísticas de rendimiento para las consultas. Las estadísticas de rendimiento proporcionan las mejores sugerencias posibles para ayudarte a mejorar el rendimiento de las consultas. Dado que el rendimiento de las consultas es multifacético, las estadísticas de rendimiento solo pueden proporcionar un panorama parcial del rendimiento general de las consultas.
Permisos necesarios
Para usar el grafo de ejecución de consultas, debes tener los siguientes permisos:
bigquery.jobs.getbigquery.jobs.listAll
Estos permisos están disponibles a través de las siguientes funciones predefinidas de Identity and Access Management (IAM) de BigQuery:
roles/bigquery.adminroles/bigquery.resourceAdminroles/bigquery.resourceEditorroles/bigquery.resourceViewer
Estructura del gráfico de ejecución
El gráfico de ejecución de consultas proporciona una vista gráfica del plan de consulta en la consola. Cada cuadro representa una etapa en el plan de consulta como las siguientes:
- Input: Lectura de datos de una tabla o selección de columnas específicas
- Join: Combinación de datos de dos tablas según la condición
JOIN - Aggregate: Realización de cálculos como
SUM - Sort: Ordenamiento de los resultados
Las etapas se componen de
pasos
que describen las operaciones individuales que ejecuta cada trabajador dentro de una etapa. Puedes hacer clic en una etapa para abrirla y ver sus pasos. Las etapas también incluyen
información de tiempo relativa y absoluta.
Los nombres de las etapas resumen los pasos que realizan. Por ejemplo, una etapa con join en su nombre significa que el paso principal en la etapa es una operación JOIN. Los nombres de las etapas que tienen + al final significan que realizan pasos importantes adicionales. Por ejemplo, una etapa con JOIN+ en su nombre significa que la etapa realiza una operación de unión y otros pasos importantes.
Las líneas que conectan las etapas representan el intercambio de datos intermedios entre las etapas. BigQuery almacena los datos intermedios en la memoria de redistribución mientras se ejecutan las etapas. Los números en los bordes indican la cantidad estimada de filas intercambiadas entre las etapas. La cuota de memoria de redistribución se correlaciona con la cantidad de ranuras asignadas a la cuenta. Si se excede la cuota de redistribución, la memoria de redistribución puede desbordarse al disco y hacer que el rendimiento de la consulta se ralentice de forma drástica.
Visualiza las estadísticas de rendimiento de las consultas
Console
Sigue estos pasos para ver las estadísticas de rendimiento de las consultas:
Abre la página de BigQuery en la Google Cloud consola de.
En el panel de la izquierda, haz clic en Explorador:

Si no ves el panel izquierdo, haz clic en Expandir panel izquierdo para abrirlo.
En el panel Explorer, haz clic en Historial de trabajos.
Haz clic en Historial personal o Historial del proyecto.
En la lista de trabajos, identifica el trabajo de consulta que te interesa. Haz clic en Acciones y selecciona Ver trabajo en el editor.
Selecciona la pestaña Gráfico de ejecución para ver una representación gráfica de cada etapa de la consulta:
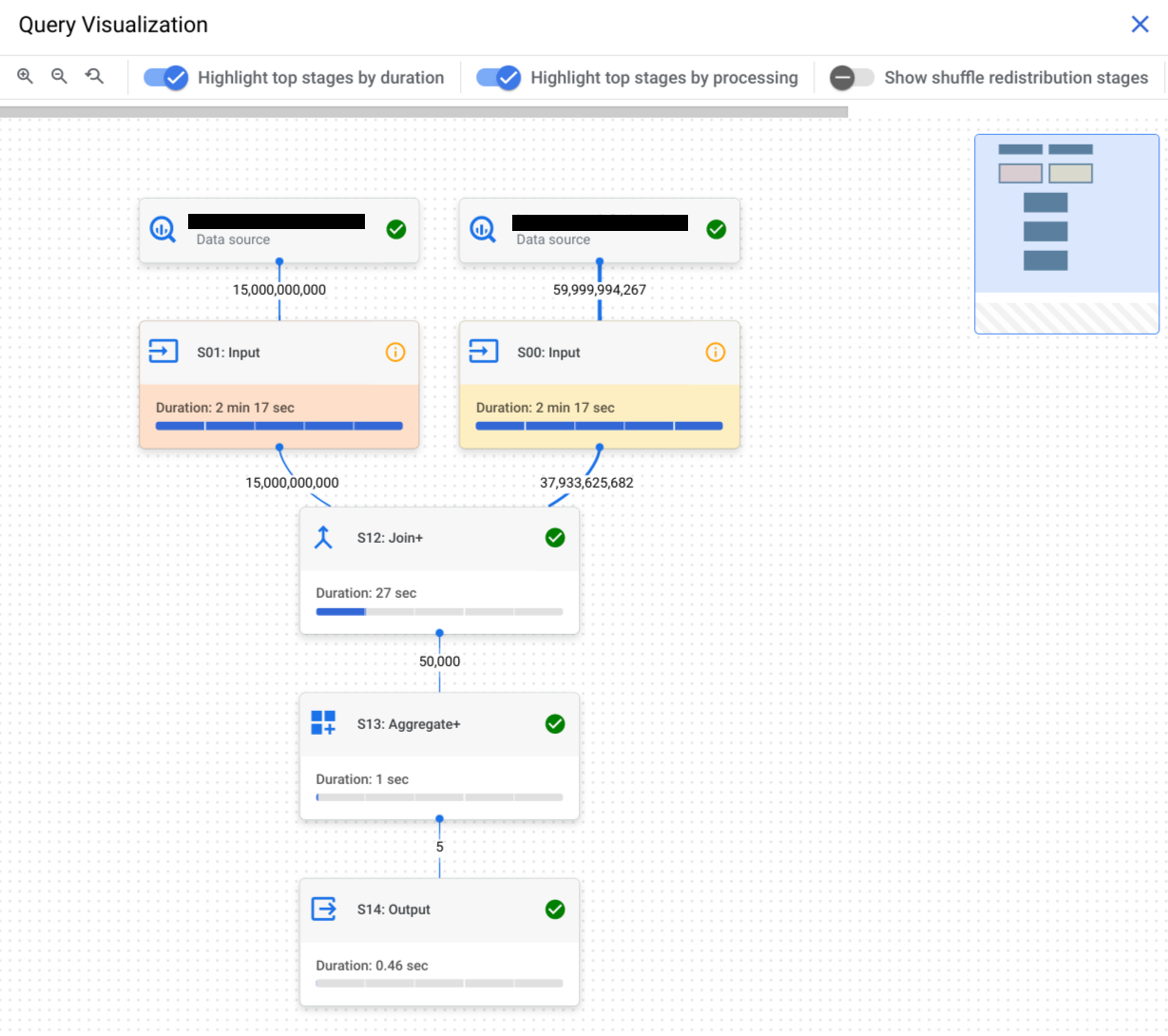
Para determinar si una etapa de la consulta tiene estadísticas de rendimiento, observa el ícono que muestra. Las etapas que tienen un ícono de información tienen estadísticas de rendimiento. Las etapas que tienen un ícono de verificación no lo hacen.
Haz clic en una etapa para abrir el panel de detalles de la etapa, en el que podrás ver la siguiente información:
- Información del plan de consulta para la etapa.
- Los pasos que se ejecutan en la etapa.
- Todas las estadísticas de rendimiento aplicables.
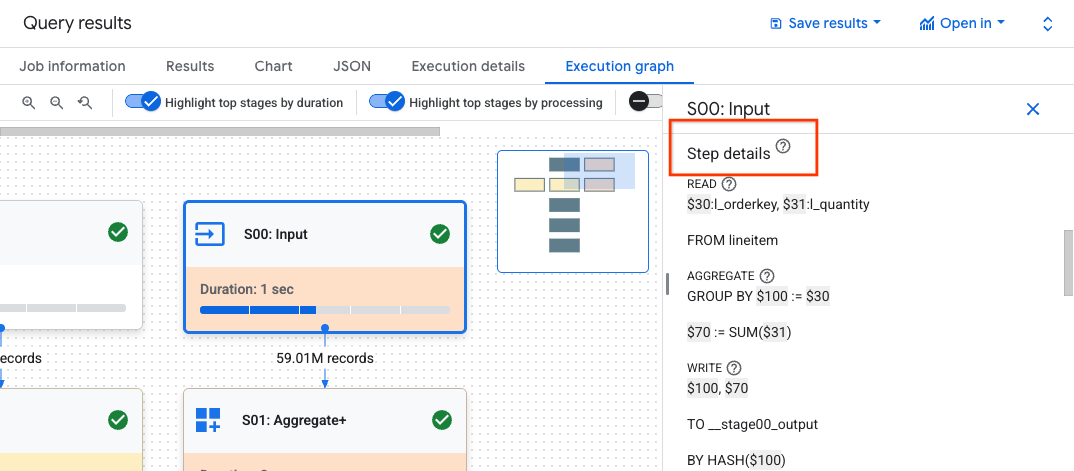
Opcional: Si inspeccionas una consulta en ejecución, haz clic en Sincronizar para actualizar el gráfico de ejecución a fin de que refleje el estado actual de la consulta.

Opcional: Para destacar las etapas principales por duración de la etapa en el gráfico, haz clic en Destacar etapas principales por duración.

Opcional: Para destacar las etapas principales por tiempo de ranura que se usa en el gráfico, haz clic en Destacar etapas principales por procesamiento.

Opcional: Para incluir etapas de redistribución aleatoria en el grafo, haz clic en Mostrar etapas de redistribución aleatoria.

Usa esta opción para mostrar las etapas de repartición y la función COALESCE que están ocultas en el grafo de ejecución predeterminado.
Las etapas de repartición y función COALESCE se ingresan mientras se ejecuta la consulta y se usan para mejorar la distribución de datos entre los trabajadores que procesan la consulta. Debido a que estas etapas no se relacionan con el texto de tu consulta, están ocultas para simplificar el plan de consulta que se muestra.
En el caso de cualquier consulta que tenga problemas de regresión de rendimiento, las estadísticas de rendimiento también se muestran en la pestaña Información del trabajo de la consulta:
SQL
En la Google Cloud consola de, ve a la página BigQuery.
En el editor de consultas, escribe la siguiente sentencia:
SELECT `bigquery-public-data`.persistent_udfs.job_url( project_id || ':us.' || job_id) AS job_url, query_info.performance_insights FROM `region-REGION_NAME`.INFORMATION_SCHEMA.JOBS_BY_PROJECT WHERE DATE(creation_time) >= CURRENT_DATE - 30 -- scan 30 days of query history AND job_type = 'QUERY' AND state = 'DONE' AND error_result IS NULL AND statement_type != 'SCRIPT' AND EXISTS ( -- Only include queries which had performance insights SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_standalone_insights ) WHERE slot_contention OR insufficient_shuffle_quota OR bi_engine_reasons IS NOT NULL OR high_cardinality_joins IS NOT NULL OR partition_skew IS NOT NULL UNION ALL SELECT 1 FROM UNNEST( query_info.performance_insights.stage_performance_change_insights ) WHERE input_data_change.records_read_diff_percentage IS NOT NULL );
Haz clic en Ejecutar.
Para obtener más información sobre cómo ejecutar consultas, visita Ejecuta una consulta interactiva.
API
Puedes obtener estadísticas de rendimiento de las consultas en un formato no gráfico si llamas al método de la API jobs.list y, luego, inspeccionas la información de JobStatistics2 que se muestra.
Interpreta las estadísticas de rendimiento de las consultas
Usa esta sección para obtener más información sobre el significado de las estadísticas de rendimiento y cómo abordarlas.
Las estadísticas de rendimiento están destinadas a dos públicos:
Analistas: Ejecutas consultas en un proyecto. Te interesa descubrir por qué una consulta que ejecutaste antes se ejecuta de forma inesperada y obtener sugerencias para mejorar el rendimiento de una consulta. Tienes los permisos descritos en Permisos necesarios.
Administradores de data lakes o almacenes de datos: Administras los recursos y as reservas de BigQuery de tu organización. Tienes los permisos asociados con el rol de administrador de BigQuery.
En cada una de las siguientes secciones, se proporciona orientación sobre lo que puedes hacer para abordar las estadísticas de rendimiento que recibes, según los roles que ocupes.
Contención de ranuras
Cuando ejecutas una consulta, BigQuery intenta dividir el trabajo que necesita tu consulta en tareas. Una tarea es una porción única de datos que ingresa y sale de una etapa. Una sola ranura toma una tarea y ejecuta esa porción de datos para la etapa. Lo ideal es que las ranuras de BigQuery ejecuten estas tareas en paralelo para lograr un alto rendimiento. La contención de ranuras ocurre cuando tu consulta tiene muchas tareas listas para comenzar a ejecutarse, pero BigQuery no puede obtener suficientes ranuras disponibles para ejecutarlas.
Qué hacer si eres analista
Sigue los pasos que se indican en Reduce los datos procesados en las consultas para reducir los datos que procesas en la consulta.
Qué hacer si eres administrador
Realiza las siguientes acciones para aumentar la disponibilidad de las ranuras o disminuir su uso:
- Si usas los precios según demanda de BigQuery, tus consultas usan un grupo compartido de ranuras. Considera cambiar a precios de análisis basados en la capacidad mediante la compra de reservas. Las reservas te permiten reservar ranuras dedicadas para las consultas de tu organización.
Si usas reservas de BigQuery, asegúrate de que hayan suficientes ranuras en la reserva que se asignaron al proyecto que ejecutaba la consulta. Es posible que la reserva no tenga suficientes ranuras en estas situaciones:
- Existen otros trabajos que consumen ranuras de reserva. Puedes usar los gráficos de recursos del administrador para ver cómo tu organización usa la reserva.
- La reserva no tiene suficientes ranuras asignadas para ejecutar consultas con la suficiente rapidez. Puedes usar el estimador de ranuras para obtener una estimación del tamaño que deben tener tus reservas y procesar de manera eficiente las tareas de tus consultas.
Para abordar esto, puedes probar una de las siguientes soluciones:
- Agrega más ranuras (ya sean ranuras del modelo de referencia o ranuras máximas de reserva) a esa reserva.
- Crea una reserva adicional y asígnala al proyecto que ejecuta la consulta.
- Distribuye las consultas que requieren muchos recursos, ya sea a lo largo del tiempo dentro de una reserva o en diferentes reservas.
Asegúrate de que las tablas que consultas estén agrupadas en clústeres. El agrupamiento en clústeres ayuda a garantizar que BigQuery pueda leer con rapidez las columnas con datos correlacionados.
Asegúrate de que las tablas que consultas estén particionadas. Para las tablas no particionadas, BigQuery lee la tabla completa. Particionar tus tablas ayuda a garantizar que consultes solo el subconjunto de las tablas que te interesan.
Cuota de Shuffle insuficiente
Antes de ejecutar la consulta, BigQuery divide la lógica de tu consulta en etapas. Las ranuras de BigQuery ejecutan las tareas para cada etapa. Cuando una ranura completa la ejecución de las tareas de una etapa, almacena los resultados intermedios en Shuffle. Las etapas posteriores de tu consulta leen datos desde Shuffle para continuar con la ejecución de tu consulta. La cuota de Shuffle es insuficiente cuando tienes más datos que se deben escribir en Shuffle que la capacidad de Shuffle que tienes.
Qué hacer si eres analista
De manera similar a la contención de ranuras, reducir la cantidad de datos que procesa la consulta puede reducir el uso aleatorio. Para ello, sigue las instrucciones en Reduce los datos procesados en las consultas.
Ciertas operaciones en SQL tienden a hacer un uso más extenso de la redistribución,
en particular las
operaciones JOIN
y las cláusulas GROUP BY.
Siempre que sea posible, reducir la cantidad de datos en estas operaciones puede reducir el uso aleatorio.
Qué hacer si eres administrador
Realiza las siguientes acciones para reducir la contención de cuota aleatoria:
- Al igual que la contención de ranuras, si usas los precios según demanda de BigQuery, tus consultas usan un grupo compartido de ranuras. Considera cambiar a precios de análisis basados en la capacidad mediante la compra de reservas. Las reservas te brindan ranuras dedicadas y capacidad de redistribución para las consultas de tus proyectos.
Si usas reservas de BigQuery, las ranuras tienen capacidad Shuffle exclusiva. Si tu reserva ejecuta algunas consultas que hacen un uso extensivo de Shuffle, esto puede provocar que otras consultas que se ejecutan en paralelo no tengan suficiente capacidad de Shuffle. Puedes identificar qué trabajos usan la capacidad de redistribución ampliamente si consultas la columna
period_shuffle_ram_usage_ratioen la vistaINFORMATION_SCHEMA.JOBS_TIMELINE.Para abordar esto, puedes probar una o más de las siguientes soluciones:
- Agrega más ranuras a esa reserva.
- Crea una reserva adicional y asígnala al proyecto que ejecuta la consulta.
- Distribuye las consultas intensivas de redistribución, ya sea a lo largo del tiempo dentro de una reserva o en diferentes reservas.
Para obtener información adicional sobre la solución de problemas, consulta Errores de límite de tamaño de redistribución en la página Solución de problemas de BigQuery.
Cambio en el ajuste de la entrada de datos
La obtención de esta estadística de rendimiento indica que tu consulta lee al menos un 50% más de datos en una tabla de entrada determinada que la última vez que ejecutaste la consulta. Puedes usar el historial de cambios de tabla para ver si el tamaño de cualquiera de las tablas usadas en la consulta aumentó recientemente.
Qué hacer si eres analista
Sigue los pasos que se indican en Reduce los datos procesados en las consultas para reducir los datos que procesas en la consulta.
Unión de alta cardinalidad
Cuando una consulta contiene una unión con claves no únicas en ambos lados de la unión, el tamaño de la tabla de salida puede ser considerablemente mayor que el tamaño de cualquiera de las tablas de entrada. Esta estadística indica que la proporción de filas de salida con filas de entrada es alta y ofrece información sobre estos recuentos de filas.
Qué hacer si eres analista
Verifica las condiciones de unión para confirmar que se espera el aumento del tamaño de la tabla de salida. Evita usar uniones cruzadas.
Si debes usar una unión cruzada, intenta usar una cláusula GROUP BY para agregar previamente los resultados o usar una función analítica. Para obtener más información, consulta Reduce los datos antes de usar una JOIN.
Sesgo de partición
Para enviar comentarios o solicitar asistencia con esta función, envía un correo electrónico a
bq-query-inspector-feedback@google.com.
La distribución de datos sesgada puede hacer que las consultas se ejecuten con lentitud. Cuando se ejecuta una consulta, BigQuery divide los datos en particiones pequeñas para el procesamiento en paralelo. El sesgo ocurre cuando los datos se distribuyen de manera desigual en estas particiones, a menudo debido a valores que ocurren con frecuencia en las claves de unión o agrupamiento, lo que hace que algunas particiones sean significativamente más grandes que otras. Dado que una sola ranura procesa una partición completa y no puede compartir el trabajo, una partición de gran tamaño puede ralentizar el procesamiento, provocar errores de "recurso excedido" y, en casos extremos, bloquear la ranura.
Mientras ejecutas una operación JOIN, BigQuery particiona los datos en los lados izquierdo y derecho de la unión según las claves de unión. Si una partición es demasiado grande, BigQuery intenta volver a balancear los datos. Si el sesgo es demasiado grave para volver a balancearse por completo, se agrega una estadística de sesgo de partición a la etapa JOIN en el gráfico de ejecución.
Identifica el sesgo de partición
Usa la pestaña Gráfico de ejecución en BigQuery Studio para encontrar qué etapa de la consulta experimenta el sesgo de partición. La estadística se marca en la etapa. En los detalles de la etapa, puedes determinar la parte relevante del texto de la consulta y las tablas que se procesan. Para obtener más información, consulta Comprende los pasos con el texto de la consulta.
Ejemplo
La siguiente consulta une la información del repositorio con la información del archivo. El sesgo puede ocurrir si algunos repositorios tienen muchos más archivos que otros.
SELECT r.repo_name, COUNT(f.path) AS file_count
FROM `bigquery-public-data.github_repos.sample_repos` AS r
JOIN `bigquery-public-data.github_repos.sample_files` AS f
ON r.repo_name = f.repo_name
WHERE r.watch_count > 10
GROUP BY r.repo_name
La clave de unión es repo_name. En la tabla sample_repos, se espera que repo_name sea único. Sin embargo, en la tabla sample_files, repo_name puede aparecer muchas veces. Si algunos valores de repo_name aparecen con una frecuencia desproporcionada en sample_files, se crea un sesgo de datos.
Para confirmar si existe un sesgo de datos, analiza la distribución de la clave de unión en la tabla más grande (sample_files en este caso). Ejecuta la siguiente consulta para evaluar la distribución de repo_name:
SELECT repo_name, COUNT(*) AS occurrences
FROM `bigquery-public-data.github_repos.sample_files`
GROUP BY repo_name
ORDER BY occurrences DESC
Para tablas muy grandes, usa la APPROX_TOP_COUNT
función para estimar de manera eficiente los valores más frecuentes.
SELECT APPROX_TOP_COUNT(repo_name, 100)
FROM `bigquery-public-data.github_repos.sample_files`
Si los recuentos de los valores principales son órdenes de magnitud más grandes que otros, existe un sesgo de datos.
Mitiga el sesgo de partición
Puedes usar las siguientes estrategias para abordar el sesgo de partición:
- Filtra tus datos con anticipación. Aplica filtros lo antes posible en tu consulta para reducir la cantidad de datos que se procesan. Esto puede disminuir la cantidad de filas asociadas con claves sesgadas antes de que lleguen a operaciones como
JOINoGROUP BY. Divide la consulta para aislar las claves sesgadas. Si el sesgo es causado por algunos valores de clave específicos, similares al campo
repo_nameen el ejemplo anterior, considera dividir la consulta. Procesa los datos de las claves sesgadas por separado del resto de los datos y, luego, combina los resultados conUNION ALL.Ejemplo: Aislamiento de una clave de uso frecuente
-- Query for the skewed key SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name = 'popular_repo' GROUP BY r.repo_name UNION ALL -- Query for all other keys SELECT r.repo_name, COUNT(f.path) AS file_count FROM `bigquery-public-data.github_repos.sample_repos` AS r JOIN `bigquery-public-data.github_repos.sample_files` AS f ON r.repo_name = f.repo_name WHERE r.watch_count > 10 AND r.repo_name != 'popular_repo' GROUP BY r.repo_nameControla los valores
NULLy predeterminados: Una causa común de sesgo es una gran cantidad de filas conNULLo valores de cadena vacía en las columnas clave. Si no necesitas estas filas para el análisis, fíltralas con una cláusulaWHEREantes deJOINoGROUP BY.Reordena las operaciones: En las consultas con varias uniones, el orden puede ser importante. Si es posible, realiza uniones que reduzcan significativamente los recuentos de filas antes en la consulta.
Usa funciones aproximadas: Para las agregaciones en datos sesgados, considera si un resultado aproximado es aceptable. Las funciones como
APPROX_COUNT_DISTINCTson más tolerantes al sesgo de datos que las funciones exactas comoCOUNT(DISTINCT).
Interpreta la información de la etapa de consulta
Además de usar las estadísticas de rendimiento de las consultas, también puedes usar los siguientes lineamientos cuando revises los detalles de la etapa de consulta para determinar si hay un problema con una consulta:
- Si el valor Esperar ms de una o más etapas es alto en comparación con las ejecuciones anteriores de la consulta:
- Verifica si tienes suficientes ranuras disponibles para adaptar tu carga de trabajo. De lo contrario, balancea las cargas cuando ejecutes consultas que requieren muchos recursos para que no compitan entre sí.
- Si el valor Esperar ms es superior al de solo una etapa, observa la etapa antes de esta para ver si se ingresó un cuello de botella. Los cambios sustanciales en los datos o el esquema de las tablas involucradas en la consulta pueden afectar el rendimiento de la consulta.
- Si el valor de Bytes de salida de Shuffle para una etapa es alto en comparación con ejecuciones anteriores de la consulta o en comparación con una etapa anterior, evalúa los pasos procesados en esa etapa para ver si alguna. crean grandes cantidades de datos inesperadas. Una causa común es cuando un paso procesa un
INNER JOINen el que hay claves duplicadas en ambos lados de la unión. Esto puede mostrar una gran cantidad de datos. - Usa el gráfico de ejecución para ver las etapas principales por duración y procesamiento. Considera la cantidad de datos que producen y si son proporcionales al tamaño de las tablas a las que se hace referencia en la consulta. Si no es así, revisa los pasos en esas etapas para ver si alguno de ellos puede producir una cantidad inesperada de datos provisionales.
¿Qué sigue?
- Revisa los lineamientos de optimización de consultas para obtener sugerencias sobre cómo mejorar el rendimiento de las consultas.