
Einführung in BigQuery Omni
Mit BigQuery Omni können Sie BigQuery-Analysen für Daten ausführen, die in Amazon Simple Storage Service (Amazon S3) oder Azure Blob Storage mithilfe von BigLake-Tabellen gespeichert sind.
Viele Organisationen speichern Daten in mehreren öffentlichen Clouds. Oft sind diese Daten isoliert gespeichert, da es schwierig ist, Erkenntnisse über alle Daten zu gewinnen. Sie möchten die Daten mit einem Multi-Cloud-Datentool analysieren können, das kostengünstig und schnell ist und keinen zusätzlichen Overhead für die dezentralisierte Data Governance verursacht. Durch die Verwendung von BigQuery Omni lassen sich diese Probleme mit einer einheitlichen Schnittstelle reduzieren.
Wenn Sie BigQuery-Analysen für Ihre externen Daten ausführen möchten, müssen Sie zuerst eine Verbindung zu Amazon S3 oder Blob Storage herstellen. Wenn Sie externe Daten abfragen möchten, müssen Sie eine BigLake-Tabelle erstellen, die auf Amazon S3- oder Blob Storage-Daten verweist.
BigQuery Omni-Tools
Mit den folgenden BigQuery Omni-Tools können Sie BigQuery-Analysen für Ihre externen Daten ausführen:
- BigQuery Omni-Joins: Führen Sie eine Abfrage direkt aus einer BigQuery-Region aus, mit der Daten aus einer BigQuery Omni-Region verknüpft werden können.
- Materialisierte BigQuery Omni-Ansichten: Verwenden Sie Replikate materialisierter Ansichten, um Daten kontinuierlich aus BigQuery Omni-Regionen zu replizieren. Unterstützt das Filtern von Daten.
- BigQuery Omni-Übertragung mit
SELECT: Führen Sie eine Abfrage mit derCREATE TABLE AS SELECT- oderINSERT INTO SELECT-Anweisung in einer BigQuery Omni-Region aus und verschieben Sie das Ergebnis in eine BigQuery-Region. - BigQuery Omni-Übertragung mit
LOADLOAD DATA-Anweisungen:LOAD DATA-Anweisungen verwenden, um Daten direkt aus Amazon Simple Storage Service (Amazon S3) oder Azure Blob Storage in BigQuery zu laden
In der folgenden Tabelle sind die wichtigsten Funktionen der einzelnen BigQuery Omni-Tools aufgeführt:
| BigQuery Omni-Joins | Materialisierte BigQuery Omni-Ansicht | BigQuery Omni-Übertragung mit SELECT |
BigQuery Omni-Übertragung mit LOAD |
|
|---|---|---|---|---|
| Empfohlene Verwendung | Externe Daten für die einmalige Verwendung abfragen, wobei Sie sie mit lokalen Tabellen zusammenführen oder Daten zwischen zwei verschiedenen BigQuery Omni-Regionen zusammenführen können, z. B. zwischen AWS- und Azure Blob Storage-Regionen. BigQuery Omni-Joins verwenden, wenn die Daten nicht groß sind und das Caching keine wichtige Anforderung ist | Richten Sie wiederholte oder geplante Abfragen ein, um externe Daten kontinuierlich inkrementell zu übertragen. Hier ist das Zwischenspeichern eine wichtige Voraussetzung. Zum Beispiel, um ein Dashboard zu pflegen | Sie möchten externe Daten einmalig abfragen, und zwar aus einer BigQuery Omni-Region in eine BigQuery-Region. Dabei sind manuelle Steuerelemente wie Caching und Abfrageoptimierung eine wichtige Anforderung. Außerdem verwenden Sie komplexe Abfragen, die nicht von BigQuery Omni-Joins oder BigQuery Omni-materialisierten Ansichten unterstützt werden. | Große Datasets unverändert migrieren, ohne dass eine Filterung erforderlich ist. Rohdaten werden mit geplanten Abfragen verschoben. |
| Unterstützt das Filtern vor dem Verschieben von Daten | Ja. Für bestimmte Abfrageoperatoren gelten Limits. Weitere Informationen finden Sie unter BigQuery Omni-Join-Limits. | Ja. Für bestimmte Abfrageoperatoren wie Aggregatfunktionen und den UNION-Operator gelten Limits. |
Ja. Keine Einschränkungen für Abfrageoperatoren | Nein |
| Beschränkungen bei der Übertragungsgröße | 60 GB pro Übertragung (jede Unterabfrage an eine Remote-Region führt zu einer Übertragung) | Kein Limit | 60 GB pro Übertragung (jede Unterabfrage an eine Remote-Region führt zu einer Übertragung) | Kein Limit |
| Kompression bei der Datenübertragung | Kabelkomprimierung | Spaltenbasiert | Kabelkomprimierung | Drahtkompression |
| Caching | Nicht unterstützt | Unterstützt mit Cache-fähigen Tabellen mit materialisierten Ansichten | Nicht unterstützt | Nicht unterstützt |
| Preise für ausgehenden Traffic | Kosten für ausgehenden AWS-Traffic und interkontinentale Kosten | Kosten für ausgehenden AWS-Traffic und interkontinentale Kosten | Kosten für ausgehenden AWS-Traffic und interkontinentale Kosten | Kosten für ausgehenden AWS-Traffic und interkontinentale Kosten |
| Compute-Nutzung für die Datenübertragung | Es werden Slots in der AWS- oder Azure Blob Storage-Quellregion verwendet (Reservierung oder On-Demand). | Nicht verwendet | Es werden Slots in der AWS- oder Azure Blob Storage-Quellregion verwendet (Reservierung oder On-Demand). | Nicht verwendet |
| Compute-Nutzung für die Filterung | Es werden Slots in der AWS- oder Azure Blob Storage-Quellregion verwendet (Reservierung oder On-Demand). | Verwendet Slots in der AWS- oder Azure Blob Storage-Quellregion (Reservierung oder On-Demand) zum Berechnen lokaler materialisierter Ansichten und Metadaten. | Es werden Slots in der AWS- oder Azure Blob Storage-Quellregion verwendet (Reservierung oder On-Demand). | Nicht verwendet |
| Inkrementelle Übertragung | Nicht unterstützt | Unterstützt für nicht aggregierte materialisierte Ansichten | Nicht unterstützt | Nicht unterstützt |
Sie können auch die folgenden Alternativen in Betracht ziehen, um Daten aus Amazon Simple Storage Service (Amazon S3) oder Azure Blob Storage in Google Cloudzu übertragen:
- Storage Transfer Service: Daten zwischen Objekt- und Dateispeicher in Google Cloud und Amazon Simple Storage Service (Amazon S3) oder Azure Blob Storage übertragen.
- BigQuery Data Transfer Service: Richten Sie die automatisierte Datenübertragung nach BigQuery nach einem festgelegten Zeitplan ein. Unterstützt eine Vielzahl von Quellen und eignet sich für die Datenmigration. Der BigQuery Data Transfer Service unterstützt keine Filterung.
Architektur
Bei der Architektur von BigQuery ist die Trennung von Computing und Speicher möglich. Somit kann BigQuery nach Bedarf für die Verarbeitung sehr großer Arbeitslasten horizontal skalieren. BigQuery Omni erweitert diese Architektur durch Ausführung der BigQuery-Abfrage-Engine in anderen Clouds. Daher müssen Sie Daten nicht physisch in den BigQuery-Speicher verschieben. Die Verarbeitung findet dann statt, wenn die Daten bereits vorhanden sind.
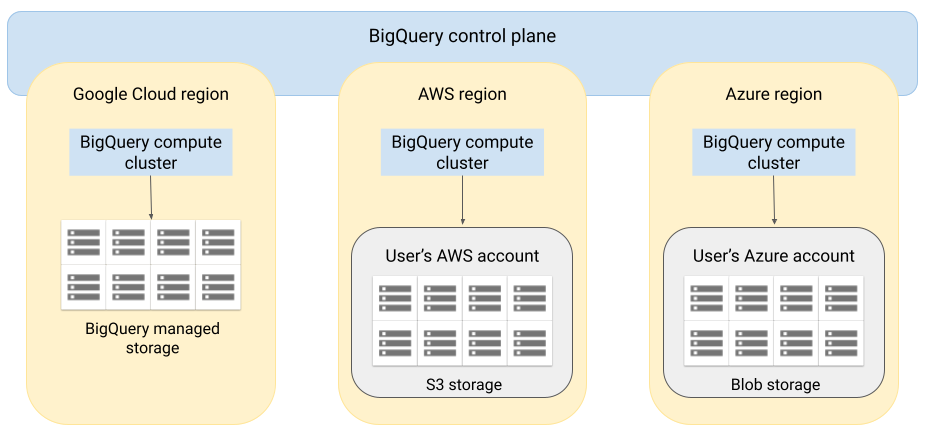
Abfrageergebnisse können über eine sichere Verbindung an Google Cloud zurückgegeben werden, z. B. um in der Google Cloud Console angezeigt zu werden. Alternativ können Sie die Ergebnisse direkt in Amazon S3-Buckets oder Blob Storage schreiben. In diesem Fall gibt es keine cloudübergreifende Verschiebung der Abfrageergebnisse.
BigQuery Omni verwendet die AWS IAM-Standardrollen oder Azure Active Directory-Hauptkonten, um auf die Daten in Ihrem Abo zuzugreifen. Sie delegieren den Lese- oder Schreibzugriff auf BigQuery Omni und können die Zugriffsrechte jederzeit widerrufen.
Datenfluss beim Abfragen von Daten
In der folgenden Abbildung wird gezeigt, wie die Daten für die folgenden Abfragen zwischen Google Cloud und AWS oder Azure verschoben werden:
SELECT-AnweisungCREATE EXTERNAL TABLE-Anweisung

- Die BigQuery-Steuerungsebene empfängt Abfragejobs über dieGoogle Cloud -Konsole, das bq-Befehlszeilentool, eine API-Methode oder eine Clientbibliothek.
- BigQuery-Steuerungsebene sendet Abfragejobs zur Verarbeitung an die BigQuery-Datenebene in AWS oder Azure.
- Die BigQuery-Datenebene empfängt Abfragen über eine VPN-Verbindung von der Steuerungsebene.
- Die BigQuery-Datenebene liest Tabellendaten aus Ihrem Amazon S3-Bucket oder Blob-Speicher.
- Die BigQuery-Datenebene führt den Abfragejob für Tabellendaten aus. Die Tabellendaten werden in der angegebenen AWS- oder Azure-Region verarbeitet.
- Das Abfrageergebnis wird von der Datenebene über die VPN-Verbindung an die Steuerungsebene übertragen.
- Die BigQuery-Steuerungsebene empfängt die Abfrageergebnisse für die Anzeige in Form eines Abfragejobs. Diese Daten werden bis zu 24 Stunden gespeichert.
- Das Abfrageergebnis wird an Sie zurückgegeben.
Weitere Informationen finden Sie unter Amazon S3-Daten abfragen und Blob-Speicherdaten.
Datenfluss beim Exportieren von Daten
In der folgenden Abbildung wird beschrieben, wie Daten während einer EXPORT DATA-Anweisung zwischen Google Cloud und AWS oder Azure verschoben werden.

- Die BigQuery-Steuerungsebene empfängt Exportabfragejobs von Ihnen über die Google Cloud Console, das bq-Befehlszeilentool, eine API-Methode oder eine Clientbibliothek. Die Abfrage enthält den Zielpfad für das Abfrageergebnis in Ihrem Amazon S3-Bucket oder Blob Storage.
- BigQuery-Steuerungsebene sendet Exportabfragejobs zur Verarbeitung an die BigQuery-Datenebene in AWS oder Azure.
- Die BigQuery-Datenebene empfängt die Exportabfragen über eine VPN-Verbindung von der Steuerungsebene
- Die BigQuery-Datenebene liest Tabellendaten aus Ihrem Amazon S3-Bucket oder Blob-Speicher.
- Die BigQuery-Datenebene führt den Abfragejob für Tabellendaten aus. Die Tabellendaten werden in der festgelegten AWS- oder Azure-Region verarbeitet.
- BigQuery schreibt das Abfrageergebnis in den angegebenen Zielpfad in Ihrem Amazon S3-Bucket oder in Blob Storage.
Weitere Informationen finden Sie unter Abfrageergebnisse nach Amazon S3 und Blob Storage exportieren.
Vorteile
Leistung. Sie erhalten schneller Einblicke, da die Daten nicht in andere Clouds kopiert werden und die Abfragen in derselben Region ausgeführt werden, in der sich Ihre Daten befinden.
Kosten. Sie sparen Kosten für ausgehenden Datenübertragungs-Traffic, da die Daten nicht verschoben werden. Für Ihr AWS- oder Azure-Konto im Zusammenhang mit BigQuery Omni-Analysen fallen keine zusätzlichen Gebühren an, da die Abfragen auf von Google verwalteten Clustern ausgeführt werden. Sie bezahlen nur für das Abfragen des BigQuery-Preismodells.
Sicherheit und Data Governance: Sie verwalten die Daten in Ihrem eigenen AWS- oder Azure-Abo. Sie müssen die Rohdaten nicht aus Ihrer öffentlichen Cloud verschieben oder kopieren. Die gesamte Berechnung erfolgt im BigQuery-Dienst mit mehreren Mandanten, der in derselben Region wie Ihre Daten ausgeführt wird.
Serverlose Architektur. Wie der Rest von BigQuery ist auch BigQuery Omni ein serverloses Angebot. Google stellt die Cluster bereit, die BigQuery Omni ausführen, und verwaltet diese. Sie müssen keine Ressourcen bereitstellen oder Cluster verwalten.
Einfache Verwaltung. BigQuery Omni bietet über Google Cloudeine einheitliche Verwaltungsoberfläche. BigQuery Omni kann Ihr vorhandenes Google Cloud -Konto und Ihre BigQuery-Projekte verwenden. Sie können eine GoogleSQL-Abfrage in der Google Cloud Console schreiben, um Daten in AWS oder Azure abzufragen und die Ergebnisse in der Google Cloud Console anzeigen zu lassen.
BigQuery Omni-Übertragung Sie können Daten aus S3-Buckets und Blob-Speicher in Standard-BigQuery-Tabellen laden. Weitere Informationen finden Sie unter Amazon S3-Daten und Blob-Speicherdaten an BigQuery übertragen.
Metadaten-Caching für bessere Leistung
Sie können im Cache gespeicherte Metadaten verwenden, um die Abfrageleistung für BigLake-Tabellen zu verbessern, die auf Amazon S3-Daten verweisen. Dies ist besonders hilfreich, wenn Sie mit einer großen Anzahl von Dateien arbeiten oder die Daten mit Apache Hive partitioniert sind.
BigQuery verwendet CMETA als verteiltes Metadatensystem, um große Tabellen effizient zu verarbeiten. CMETA bietet detaillierte Metadaten auf Spalten- und Blockebene, auf die über Systemtabellen zugegriffen werden kann. Dieses System trägt dazu bei, die Abfrageleistung zu verbessern, indem es den Datenzugriff und die Datenverarbeitung optimiert. Um die Abfrageleistung für große Tabellen weiter zu beschleunigen, verwaltet BigQuery einen Metadatencache. Durch CMETA-Aktualisierungsjobs wird dieser Cache auf dem neuesten Stand gehalten.Die Metadaten enthalten Dateinamen, Partitionierungsinformationen und physische Metadaten aus Dateien wie der Zeilenanzahl. Sie können auswählen, ob das Caching von Metadaten für eine Tabelle aktiviert werden soll. Abfragen mit einer großen Anzahl von Dateien und mit Apache Hive-Partitionsfiltern profitieren am meisten vom Metadaten-Caching.
Wenn Sie das Caching von Metadaten nicht aktivieren, müssen Abfragen in der Tabelle die externe Datenquelle lesen, um Objektmetadaten abzurufen. Durch das Lesen dieser Daten erhöht sich die Abfragelatenz. Das Auflisten von Millionen von Dateien aus der externen Datenquelle kann einige Minuten dauern. Wenn Sie das Metadaten-Caching aktivieren, können Abfragen die Auflistung von Dateien aus der externen Datenquelle vermeiden und Dateien schneller partitionieren und bereinigen.
Das Metadaten-Caching ist auch in die Cloud Storage-Objektversionsverwaltung integriert. Wenn der Cache gefüllt oder aktualisiert wird, werden Metadaten auf Grundlage der Live-Version der Cloud Storage-Objekte zu diesem Zeitpunkt erfasst. Daher werden bei Abfragen mit aktiviertem Metadaten-Caching Daten gelesen, die der jeweiligen im Cache gespeicherten Objektversion entsprechen, auch wenn neuere Versionen in Cloud Storage live geschaltet werden. Wenn Sie auf Daten aus nachfolgend aktualisierten Objektversionen in Cloud Storage zugreifen möchten, müssen Sie den Metadatencache aktualisieren.
Es gibt zwei Attribute, die diese Funktion steuern:
- Die maximale Veralterung gibt an, wann Abfragen im Cache gespeicherte Metadaten verwenden.
- Der Metadaten-Cache-Modus gibt an, wie die Metadaten erhoben werden.
Wenn Sie das Caching von Metadaten aktiviert haben, geben Sie auch das maximale Intervall der Metadatenveralterung an, das für Vorgänge in Bezug auf die Tabelle akzeptabel ist. Wenn Sie beispielsweise ein Intervall von 1 Stunde angeben, verwenden die Vorgänge für die Tabelle im Cache gespeicherte Metadaten, wenn sie innerhalb der letzten Stunde aktualisiert wurden. Sind die im Cache gespeicherten Metadaten älter, werden für den Vorgang stattdessen Metadaten aus Amazon S3 abgerufen. Sie können ein Veralterungsintervall zwischen 30 Minuten und 7 Tagen festlegen.
Wenn Sie das Metadaten-Caching für BigLake- oder Objekttabellen aktivieren, löst BigQuery Aktualisierungsjobs für die Metadatengenerierung aus. Sie können den Cache entweder automatisch oder manuell aktualisieren:
- Bei automatischen Aktualisierungen wird der Cache in einem systemdefinierten Intervall aktualisiert, in der Regel zwischen 30 und 60 Minuten. Das automatische Aktualisieren des Caches ist ein guter Ansatz, wenn die Dateien in Amazon S3 in unregelmäßigen Abständen hinzugefügt, gelöscht oder geändert werden. Wenn Sie den Zeitpunkt der Aktualisierung steuern müssen, z. B. um die Aktualisierung am Ende eines Extract-Transform-Ladejobs auszulösen, verwenden Sie die manuelle Aktualisierung.
Bei manuellen Aktualisierungen führen Sie das Systemverfahren
BQ.REFRESH_EXTERNAL_METADATA_CACHEaus, um den Metadaten-Cache nach einem Zeitplan zu aktualisieren, der Ihren Anforderungen entspricht. Die manuelle Aktualisierung des Caches ist ein guter Ansatz, wenn die Dateien in Amazon S3 in bekannten Abständen hinzugefügt, gelöscht oder geändert werden, z.B. als Ausgabe einer Pipeline.Wenn Sie mehrere manuelle Aktualisierungen gleichzeitig ausführen, ist nur eine erfolgreich.
Der Metadaten-Cache läuft nach 7 Tagen ab, wenn er nicht aktualisiert wird.
Sowohl manuelle als auch automatische Cache-Aktualisierungen werden mit der Abfragepriorität INTERACTIVE ausgeführt.
BACKGROUND-Reservierungen verwenden
Wenn Sie automatische Aktualisierungen verwenden möchten, empfehlen wir, eine Reservierung zu erstellen und dann eine Zuweisung mit dem Jobtyp BACKGROUND für das Projekt zu erstellen, in dem die Metadaten-Cache-Aktualisierungsjobs ausgeführt werden. Bei BACKGROUND-Reservierungen verwenden Aktualisierungsjobs einen dedizierten Ressourcenpool. Dadurch wird verhindert, dass die Aktualisierungsjobs mit Nutzerabfragen um Ressourcen konkurrieren und möglicherweise fehlschlagen, wenn nicht genügend Ressourcen verfügbar sind.
Die Verwendung eines gemeinsam genutzten Slot-Pools verursacht keine zusätzlichen Kosten. Die Verwendung von BACKGROUND-Reservierungen bietet jedoch eine konsistentere Leistung, da ein dedizierter Ressourcenpool zugewiesen wird. Außerdem wird die Zuverlässigkeit von Aktualisierungsjobs und die allgemeine Abfrageeffizienz in BigQuery verbessert.
Sie sollten berücksichtigen, wie die Werte für Veralterung und Metadaten-Caching-Modus interagieren, bevor Sie sie festlegen. Betrachten Sie hierzu folgende Beispiele:
- Wenn Sie den Metadaten-Cache für eine Tabelle manuell aktualisieren und das Veralterungsintervall auf 2 Tage festlegen, müssen Sie das Systemverfahren
BQ.REFRESH_EXTERNAL_METADATA_CACHEalle 2 Tage oder weniger ausführen, wenn Sie Vorgänge wünschen. um die im Cache gespeicherten Metadaten zu verwenden. - Wenn Sie den Metadaten-Cache für eine Tabelle automatisch aktualisieren und das Veralterungsintervall auf 30 Minuten festlegen, ist es möglich, dass einige Vorgänge für die Tabelle aus Amazon S3 gelesen werden, wenn die Metadaten-Cache-Aktualisierung länger als die üblichen 30 bis 60 Minuten dauert.
Fragen Sie die Ansicht INFORMATION_SCHEMA.JOBS ab, um Informationen zu Aktualisierungsjobs für Metadaten zu erhalten, wie im folgenden Beispiel gezeigt:
SELECT * FROM `region-us.INFORMATION_SCHEMA.JOBS_BY_PROJECT` WHERE job_id LIKE '%metadata_cache_refresh%' AND creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 6 HOUR) ORDER BY start_time DESC LIMIT 10;
Weitere Informationen finden Sie unter Caching von Metadaten.
Cache-fähige Tabellen mit materialisierten Ansichten
Sie können materialisierte Ansichten über metadaten-cache-fähigen Amazon Simple Storage Service (Amazon S3)-Tabellen verwenden, um die Leistung und Effizienz beim Abfragen strukturierter Daten zu verbessern, die in Amazon S3 gespeichert sind. Diese materialisierten Ansichten funktionieren wie materialisierte Ansichten über von BigQuery verwalteten Speichertabellen, einschließlich der Vorteile einer automatischen Aktualisierung und intelligenten Abstimmung.
Wenn Sie Amazon S3-Daten in einer materialisierten Ansicht in einer unterstützten BigQuery-Region für Joins bereitstellen wollen, erstellen Sie ein Replikat der materialisierten Ansicht . Sie können Replikate für materialisierte Ansichten nur über autorisierte materialisierte Ansichten erstellen.
Beschränkungen
Zusätzlich zu den Einschränkungen für BigLake-Tabellen gelten für BigQuery Omni die folgenden Einschränkungen, die auf BigLake-Tabellen basieren, die auf Amazon S3- und Blob Storage-Daten basieren:
- Die Arbeit mit Daten in einer der BigQuery Omni-Regionen wird von den Standard- und Enterprise Plus-Versionen nicht unterstützt. Weitere Informationen zu Editionen finden Sie unter Einführung in BigQuery-Editionen.
- Die
INFORMATION_SCHEMAAnsichtenOBJECT_PRIVILEGES,STREAMING_TIMELINE_BY_*,TABLE_SNAPSHOTS,TABLE_STORAGE,TABLE_CONSTRAINTS,KEY_COLUMN_USAGE,CONSTRAINT_COLUMN_USAGEundPARTITIONSsind für BigLake-Tabellen, die auf Amazon S3- und Blob Storage-Daten basieren, nicht verfügbar. - Materialisierte Ansichten werden für Blob Storage nicht unterstützt.
- JavaScript-UDFs werden nicht unterstützt.
Die folgenden SQL-Anweisungen werden nicht unterstützt:
- BigQuery ML-Anweisungen.
- Anweisungen der Datendefinitionssprache (Data Definition Language, DDL), für die in BigQuery verwaltete Daten erforderlich sind. Beispiel:
CREATE EXTERNAL TABLE,CREATE SCHEMAoderCREATE RESERVATIONwerden unterstützt,CREATE TABLEjedoch nicht. - Anweisungen der Datenbearbeitungssprache (DML).
Für das Abfragen und Lesen von temporären Zieltabellen gelten folgende Einschränkungen:
- Das Abfragen von temporären Tabellen mit der
SELECT-Anweisung wird nicht unterstützt.
- Das Abfragen von temporären Tabellen mit der
Geplante Abfragen werden nur über die API- oder die Befehlszeilenmethode unterstützt. Die Option Zieltabelle ist für Abfragen deaktiviert. Nur
EXPORT DATA-Abfragen sind zulässig.BigQuery Storage API ist in BigQuery Omni-Regionen nicht verfügbar.
Wenn die Abfrage die
ORDER BY-Klausel verwendet und eine Ergebnisgröße von mehr als 256 MB hat, schlägt die Abfrage fehl. Zur Behebung dieses Problems reduzieren Sie entweder die Ergebnisgröße oder entfernen dieORDER BY-Klausel aus der Abfrage. Weitere Informationen zu BigQuery Omni-Kontingenten finden Sie unter Kontingente und Limits.Die Verwendung von kundenverwalteten Verschlüsselungsschlüsseln (CMEK) mit Datasets und externen Tabellen wird nicht unterstützt.
Preise
Informationen zu Preisen und zeitlich begrenzten Angeboten in BigQuery Omni finden Sie unter BigQuery Omni-Preise.
Kontingente und Limits
Informationen zu BigQuery Omni-Kontingenten finden Sie unter Kontingente und Limits.
Wenn das Abfrageergebnis größer als 20 GiB ist, sollten Sie die Ergebnisse nach Amazon S3 oder Blob Storage exportieren. Informationen zu Kontingenten für die BigQuery Connection API finden Sie unter BigQuery Connection API.
Standorte
BigQuery Omni verarbeitet Abfragen am selben Standort wie das Dataset, das die Tabellen enthält, die Sie abfragen. Nachdem Sie das Dataset erstellt haben, kann der Standort nicht mehr geändert werden. Ihre Daten befinden sich in Ihrem AWS- oder Azure-Konto. BigQuery Omni-Regionen unterstützen Reservierungen in der Enterprise-Version und Preise für On-Demand-Computing (Analysen). Weitere Informationen zu Editionen finden Sie unter Einführung in BigQuery-Editionen.
| Beschreibung der Region | Name der Region | Externe BigQuery-Region | |
|---|---|---|---|
| AWS | |||
| AWS – US East (N. Virginia) | aws-us-east-1 |
us-east4 |
|
| AWS – US West (Oregon) | aws-us-west-2 |
us-west1 |
|
| AWS – Asiatisch-pazifischer Raum (Seoul) | aws-ap-northeast-2 |
asia-northeast3 |
|
| AWS – Asiatisch-pazifischer Raum (Sydney) | aws-ap-southeast-2 |
australia-southeast1 |
|
| AWS - Europa (Irland) | aws-eu-west-1 |
europe-west1 |
|
| AWS – Europa (Frankfurt) | aws-eu-central-1 |
europe-west3 |
|
| Azure | |||
| Azure – East US 2 | azure-eastus2 |
us-east4 |
|
Nächste Schritte
- Verbindung zu Amazon S3 und Blob-Speicher herstellen.
- BigLake-Tabellen in Amazon S3 und Blob Storage erstellen
- BigLake-Tabellen in Amazon S3 und Blob Storage abfragen
- BigLake-Tabellen in Amazon S3 und Blob Storage mit Google Cloud Tabellen mithilfe von BigQuery Omni-Joins zusammenführen
- Abfrageergebnisse nach Amazon S3 und Blob Storage exportieren
- Weitere Informationen zum Übertragen von Daten aus Amazon S3 und Blob Storage zu BigQuery
- VPC Service Controls-Perimeter einrichten
- Informationen zum Angeben des Standorts