
ציון עמודות בתוך עמודות ועמודות חוזרות בסכימות של טבלאות
בדף הזה מוסבר איך להגדיר סכימת טבלה עם עמודות מקוננות וחוזרות ב-BigQuery. סקירה כללית של סכימות טבלאות זמינה במאמר בנושא הגדרת סכימה.
הגדרת עמודות בתוך עמודות ועמודות חוזרות
כדי ליצור עמודה עם נתונים בתוך נתונים, מגדירים את סוג הנתונים של העמודה ל-RECORD בסכימה. אפשר לגשת אל RECORD כאל סוג STRUCT ב-GoogleSQL. STRUCT הוא מאגר של שדות מסודרים.
כדי ליצור עמודה עם נתונים שחוזרים על עצמם, מגדירים את המאפיין mode של העמודה לערך REPEATED בסכימה.
אפשר לגשת לשדה חוזר כסוג ARRAY ב-GoogleSQL.
עמודה מסוג RECORD יכולה להיות במצב REPEATED, שמיוצג כמערך של סוגי STRUCT. בנוסף, שדה בתוך רשומה יכול לחזור על עצמו, והוא מיוצג כ-STRUCT שמכיל ARRAY. מערך לא יכול להכיל מערך אחר באופן ישיר. מידע נוסף זמין במאמר בנושא הצהרה על סוג ARRAY.
מגבלות
סכימות מקוננות וחוזרות כפופות למגבלות הבאות:
- סכימה לא יכולה להכיל יותר מ-15 רמות של סוגי
RECORDמוטמעים. - עמודות מסוג
RECORDיכולות להכיל סוגים מוטמעים שלRECORD, שנקראים גם רשומות צאצא. המגבלה המקסימלית של עומק הקינון היא 15 רמות. המגבלה הזו לא תלויה בשאלה אםRECORDהם סקלריים או מבוססי מערך (חוזרים).
הסוג RECORD לא תואם ל-UNION, INTERSECT, EXCEPT DISTINCT ו-SELECT DISTINCT.
סכימה לדוגמה
בדוגמה הבאה מוצגים נתונים לדוגמה שחוזרים על עצמם ונתונים מקוננים. הטבלה הזו מכילה מידע על אנשים. הוא מורכב מהשדות הבאים:
idfirst_namelast_namedob(תאריך לידה)-
addresses(שדה בתוך שדה ושדה חוזר)addresses.status(נוכחי או קודם)addresses.addressaddresses.cityaddresses.stateaddresses.zip-
addresses.numberOfYears(מספר השנים בכתובת)
קובץ נתוני ה-JSON ייראה כך. שימו לב שהעמודה addresses מכילה מערך של ערכים (מסומן על ידי [ ]). הכתובות הרבות במערך הן הנתונים שחוזרים על עצמם. השדות הרבים בכל כתובת הם הנתונים המקוננים.
{"id":"1","first_name":"John","last_name":"Doe","dob":"1968-01-22","addresses":[{"status":"current","address":"123 First Avenue","city":"Seattle","state":"WA","zip":"11111","numberOfYears":"1"},{"status":"previous","address":"456 Main Street","city":"Portland","state":"OR","zip":"22222","numberOfYears":"5"}]}
{"id":"2","first_name":"Jane","last_name":"Doe","dob":"1980-10-16","addresses":[{"status":"current","address":"789 Any Avenue","city":"New York","state":"NY","zip":"33333","numberOfYears":"2"},{"status":"previous","address":"321 Main Street","city":"Hoboken","state":"NJ","zip":"44444","numberOfYears":"3"}]}
הסכימה של הטבלה הזו נראית כך:
[ { "name": "id", "type": "STRING", "mode": "NULLABLE" }, { "name": "first_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "last_name", "type": "STRING", "mode": "NULLABLE" }, { "name": "dob", "type": "DATE", "mode": "NULLABLE" }, { "name": "addresses", "type": "RECORD", "mode": "REPEATED", "fields": [ { "name": "status", "type": "STRING", "mode": "NULLABLE" }, { "name": "address", "type": "STRING", "mode": "NULLABLE" }, { "name": "city", "type": "STRING", "mode": "NULLABLE" }, { "name": "state", "type": "STRING", "mode": "NULLABLE" }, { "name": "zip", "type": "STRING", "mode": "NULLABLE" }, { "name": "numberOfYears", "type": "STRING", "mode": "NULLABLE" } ] } ]
ציון העמודות המקוננות והחוזרות בדוגמה
כדי ליצור טבלה חדשה עם העמודות הקודמות שכוללות נתונים מקוננים וחוזרים, בוחרים באחת מהאפשרויות הבאות:
המסוף
מציינים את העמודה addresses עם השדות בתוך שדות והשדות החוזרים:
נכנסים לדף BigQuery במסוף Google Cloud .
בחלונית הימנית, לוחצים על כלי הניתוחים:

אם החלונית הימנית לא מוצגת, לוחצים על הרחבת החלונית הימנית כדי לפתוח אותה.
בחלונית Explorer, מרחיבים את הפרויקט, לוחצים על Datasets ובוחרים מערך נתונים.
בחלונית הפרטים, לוחצים על יצירת טבלה.
בדף Create table, מציינים את הפרטים הבאים:
- בקטע מקור, בשדה יצירת טבלה מ, בוחרים באפשרות טבלה ריקה.
בקטע Destination (יעד), מציינים את השדות הבאים:
- בקטע Dataset (מערך נתונים), בוחרים את מערך הנתונים שבו רוצים ליצור את הטבלה.
- בשדה Table (טבלה), מזינים את השם של הטבלה שרוצים ליצור.
בקטע סכימה, לוחצים על הוספת שדה ומזינים את סכימת הטבלה הבאה:
- בשם השדה, מזינים
addresses. - בשדה Type, בוחרים באפשרות RECORD.
- בקטע Mode (מצב), בוחרים באפשרות REPEATED (חוזר).
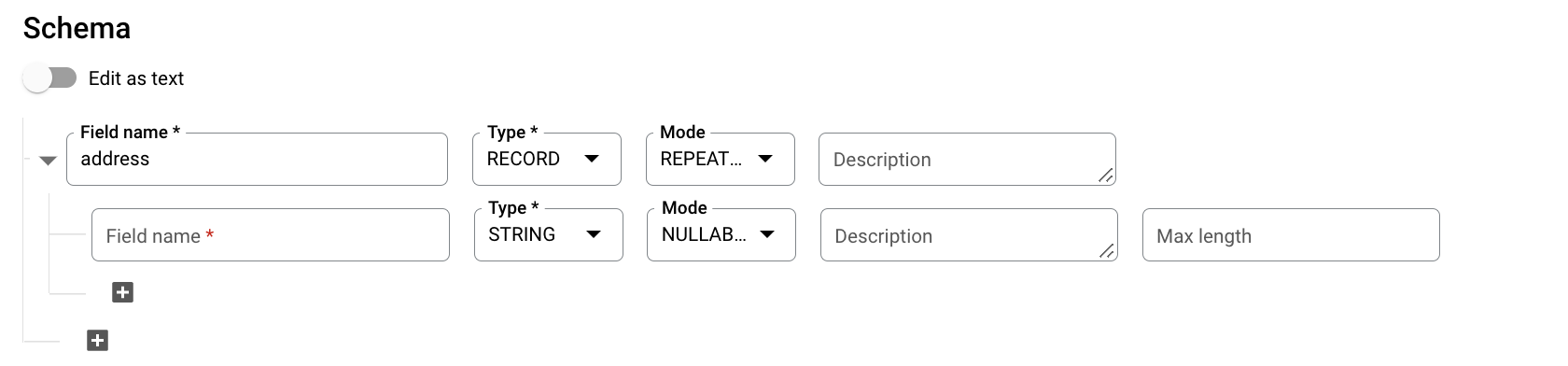
מציינים את השדות הבאים לשדה מקונן:
- בשדה שם השדה מזינים
status. - בשדה Type (סוג), בוחרים באפשרות STRING (מחרוזת).
- בשדה Mode (מצב), משאירים את הערך NULLABLE (ניתן לאיפוס).
לוחצים על הוספת שדה כדי להוסיף את השדות הבאים:
שם השדה סוג מצב addressSTRINGNULLABLEcitySTRINGNULLABLEstateSTRINGNULLABLEzipSTRINGNULLABLEnumberOfYearsSTRINGNULLABLE
לחלופין, לוחצים על Edit as text ומציינים את הסכימה כמערך JSON.
- בשדה שם השדה מזינים
- בשם השדה, מזינים
SQL
משתמשים בהצהרה CREATE TABLE.
מציינים את הסכימה באמצעות האפשרות column:
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
CREATE TABLE IF NOT EXISTS mydataset.mytable ( id STRING, first_name STRING, last_name STRING, dob DATE, addresses ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> ) OPTIONS ( description = 'Example name and addresses table');
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
BQ
כדי לציין את העמודה addresses המקוננת והחוזרת בקובץ סכימת JSON, צריך ליצור קובץ חדש באמצעות עורך טקסט. מדביקים את ההגדרה של סכימת הדוגמה שמוצגת למעלה.
אחרי שיוצרים את קובץ סכימת ה-JSON, אפשר לספק אותו באמצעות כלי שורת הפקודה של BigQuery. מידע נוסף זמין במאמר בנושא שימוש בקובץ סכימת JSON.
המשך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Goהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Go API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
הוספת נתונים בעמודות מקוננות בדוגמה
אפשר להשתמש בשאילתות הבאות כדי להוסיף רשומות נתונים מקוננות לטבלאות שיש בהן עמודות עם סוג הנתונים RECORD.
דוגמה 1
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22", ARRAY< STRUCT< status STRING, address STRING, city STRING, state STRING, zip STRING, numberOfYears STRING>> [("current","123 First Avenue","Seattle","WA","11111","1")])
דוגמה 2
INSERT INTO mydataset.mytable (id, first_name, last_name, dob, addresses) values ("1","Johnny","Dawn","1969-01-22",[("current","123 First Avenue","Seattle","WA","11111","1")])
שאילתה של עמודות בתוך עמודות ועמודות חוזרות
כדי לבחור את הערך של ARRAY במיקום ספציפי, משתמשים באופרטור של אינדקס במערך.
כדי לגשת לאלמנטים ב-STRUCT, משתמשים באופרטור הנקודה.
בדוגמה הבאה נבחרו השם הפרטי, שם המשפחה והכתובת הראשונה שמופיעים בשדה addresses:
SELECT first_name, last_name, addresses[offset(0)].address FROM mydataset.mytable;
התוצאה היא:
+------------+-----------+------------------+ | first_name | last_name | address | +------------+-----------+------------------+ | John | Doe | 123 First Avenue | | Jane | Doe | 789 Any Avenue | +------------+-----------+------------------+
כדי לחלץ את כל הרכיבים של ARRAY, משתמשים באופרטור UNNEST עם CROSS JOIN.
בדוגמה הבאה נבחרים השם הפרטי, שם המשפחה, הכתובת והמדינה של כל הכתובות שלא נמצאות בניו יורק:
SELECT first_name, last_name, a.address, a.state FROM mydataset.mytable CROSS JOIN UNNEST(addresses) AS a WHERE a.state != 'NY';
התוצאה היא:
+------------+-----------+------------------+-------+ | first_name | last_name | address | state | +------------+-----------+------------------+-------+ | John | Doe | 123 First Avenue | WA | | John | Doe | 456 Main Street | OR | | Jane | Doe | 321 Main Street | NJ | +------------+-----------+------------------+-------+
שינוי עמודות בתוך עמודות ועמודות חוזרות
אחרי שמוסיפים עמודה מקוננת או עמודה מקוננת וחוזרת על עצמה להגדרת הסכימה של טבלה, אפשר לשנות את העמודה כמו כל סוג אחר של עמודה. יש כמה שינויים בסכימה שנתמכים באופן טבעי ב-BigQuery, כמו הוספה של שדה חדש עם נתונים מקוננים לרשומה או שינוי המצב של שדה עם נתונים מקוננים. מידע נוסף זמין במאמר בנושא שינוי סכימות של טבלאות.
מתי כדאי להשתמש בעמודות מקוננות ובעמודות חוזרות
הביצועים של BigQuery הכי טובים כשהנתונים לא מנורמלים. במקום לשמור על סכימה יחסית כמו סכימת כוכב או סכימת פתית שלג, כדאי לבצע דה-נורמליזציה של הנתונים ולהשתמש בעמודות מקוננות וחוזרות. עמודות מקוננות וחוזרות יכולות לשמור על קשרים בלי להשפיע על הביצועים, בניגוד לשמירה של סכימה יחסית (מנורמלת).
לדוגמה, במסד נתונים רלציוני שמשמש למעקב אחרי ספרים בספרייה, סביר להניח שכל פרטי המחבר יישמרו בטבלה נפרדת. מפתח כמו author_id ישמש לקישור הספר למחברים.
ב-BigQuery, אפשר לשמור על הקשר בין הספר לבין המחבר בלי ליצור טבלת מחברים נפרדת. במקום זאת, יוצרים עמוד של מחבר ומקננים בו שדות כמו שם פרטי, שם משפחה, תאריך לידה וכו'. אם לספר יש כמה מחברים, אפשר לחזור על עמודת המחבר המקוננת.
נניח שיש לכם את הטבלה הבאה mydataset.books:
+------------------+------------+-----------+ | title | author_ids | num_pages | +------------------+------------+-----------+ | Example Book One | [123, 789] | 487 | | Example Book Two | [456] | 89 | +------------------+------------+-----------+
בנוסף, יש לכם את הטבלה הבאה, mydataset.authors, עם מידע מלא על כל מזהה מחבר:
+-----------+-------------+---------------+ | author_id | author_name | date_of_birth | +-----------+-------------+---------------+ | 123 | Alex | 01-01-1960 | | 456 | Rosario | 01-01-1970 | | 789 | Kim | 01-01-1980 | +-----------+-------------+---------------+
אם הטבלאות גדולות, יכול להיות שיידרשו הרבה משאבים כדי לבצע את הפעולה הזו באופן קבוע. בהתאם למצב שלכם, יכול להיות שכדאי ליצור טבלה אחת שתכיל את כל המידע:
CREATE TABLE mydataset.denormalized_books( title STRING, authors ARRAY<STRUCT<id INT64, name STRING, date_of_birth STRING>>, num_pages INT64) AS ( SELECT title, ARRAY_AGG(STRUCT(author_id, author_name, date_of_birth)) AS authors, ANY_VALUE(num_pages) FROM mydataset.books, UNNEST(author_ids) id JOIN mydataset.authors ON id = author_id GROUP BY title );
הטבלה שמתקבלת נראית כך:
+------------------+-------------------------------+-----------+
| title | authors | num_pages |
+------------------+-------------------------------+-----------+
| Example Book One | [{123, Alex, 01-01-1960}, | 487 |
| | {789, Kim, 01-01-1980}] | |
| Example Book Two | [{456, Rosario, 01-01-1970}] | 89 |
+------------------+-------------------------------+-----------+
BigQuery תומך בטעינת נתונים מקוננים וחוזרים מפורמטים של מקורות שתומכים בסכימות מבוססות-אובייקטים, כמו קובצי JSON, קובצי Avro, קובצי ייצוא של Firestore וקובצי ייצוא של Datastore.
ביטול כפילויות ברשומות כפולות בטבלה
השאילתה הבאה משתמשת בפונקציה row_number()
כדי לזהות רשומות כפולות עם אותם ערכים עבור
last_name ו-first_name בדוגמאות שבהן נעשה שימוש, וממיינת אותן לפי dob:
CREATE OR REPLACE TABLE mydataset.mytable AS ( SELECT * except(row_num) FROM ( SELECT *, row_number() over (partition by last_name, first_name order by dob) row_num FROM mydataset.mytable) temp_table WHERE row_num=1 )
אבטחת טבלאות
כדי לשלוט בגישה לטבלאות ב-BigQuery, אפשר לעיין במאמר בנושא שליטה בגישה למשאבים באמצעות IAM.
המאמרים הבאים
- כדי להוסיף ולעדכן שורות עם עמודות מקוננות וחוזרות, אפשר לעיין בתחביר של שפת טיפול בנתונים (DML).