
Dans ce tutoriel, vous allez importer des modèles TensorFlow dans un ensemble de données BigQuery ML. Ensuite, vous utilisez une requête SQL pour générer des prédictions à partir des modèles importés.
Objectifs
- Utilisez l'instruction
CREATE MODELpour importer des modèles TensorFlow dans BigQuery ML. - Utilisez la fonction
ML.PREDICTpour effectuer des prédictions avec les modèles TensorFlow importés.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud .
Vérifiez que l'API BigQuery est activée.
- Assurez-vous de disposer des autorisations nécessaires pour effectuer les tâches décrites dans ce document.
Rôles requis
Si vous créez un projet, vous en êtes le propriétaire et vous disposez de toutes les autorisations IAM (Identity and Access Management) requises pour suivre ce tutoriel.
Si vous utilisez un projet existant, le rôle Administrateur BigQuery Studio (roles/bigquery.studioAdmin) vous accorde toutes les autorisations nécessaires pour suivre ce tutoriel.
Assurez-vous de disposer du ou des rôles suivants sur le projet :
Administrateur BigQuery Studio (roles/bigquery.studioAdmin).
Vérifier les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
-
Dans la colonne Compte principal, recherchez toutes les lignes qui vous identifient ou identifient un groupe dont vous faites partie. Pour savoir à quels groupes vous appartenez, contactez votre administrateur.
- Pour toutes les lignes qui vous spécifient ou vous incluent, consultez la colonne Rôle pour vous assurer que la liste inclut les rôles requis.
Attribuer les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
- Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez votre identifiant utilisateur. Il s'agit généralement de l'adresse e-mail d'un compte Google.
- Cliquez sur Sélectionner un rôle, puis recherchez le rôle.
- Pour attribuer des rôles supplémentaires, cliquez sur Ajouter un autre rôle et ajoutez tous les rôles supplémentaires.
- Cliquez sur Enregistrer.
Pour en savoir plus sur les autorisations IAM dans BigQuery, consultez Autorisations BigQuery.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis États-Unis.
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, utilisez la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialet définissez l'emplacement des données surUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Vérifiez que l'ensemble de données a été créé :
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Importer un modèle TensorFlow
Les étapes suivantes vous expliquent comment importer un modèle depuis Cloud Storage.
Le chemin d'accès au modèle est gs://cloud-training-demos/txtclass/export/exporter/1549825580/*. Le nom du modèle importé est imported_tf_model.
Notez que l'URI Cloud Storage se termine par un caractère générique (*). Ce caractère indique que BigQuery ML doit importer tous les éléments associés au modèle.
Le modèle importé est un modèle de classificateur de texte TensorFlow capable d'identifier le site Web ayant publié un titre d'article donné.
Pour importer le modèle TensorFlow dans votre ensemble de données, procédez comme suit.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Sous Créer, cliquez sur Requête SQL.
Dans l'éditeur de requête, saisissez l'instruction
CREATE MODEL, puis cliquez sur Exécuter.CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
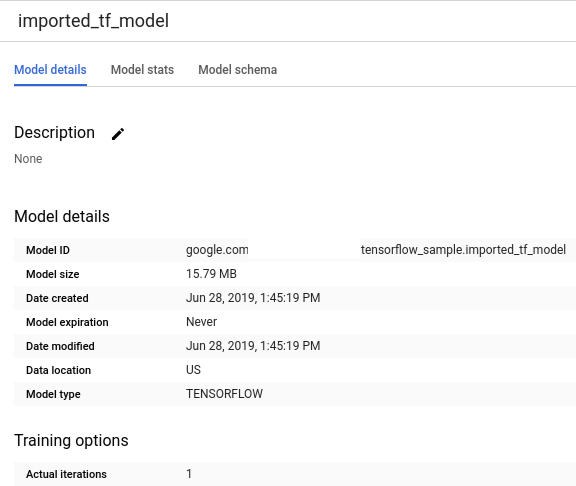
Une fois l'opération terminée, un message tel que
Successfully created model named imported_tf_modeldoit s'afficher.Votre nouveau modèle apparaît dans le panneau Ressources. Les modèles sont indiqués par l'icône
 .
.Si vous sélectionnez le nouveau modèle dans le panneau Ressources, les informations relatives au modèle s'affichent sous l'éditeur de requête.
bq
Importez le modèle TensorFlow depuis Cloud Storage en saisissant l'instruction
CREATE MODELsuivante.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
Une fois le modèle importé, vérifiez qu'il apparaît dans l'ensemble de données.
bq ls -m bqml_tutorial
Le résultat ressemble à ce qui suit :
tableId Type ------------------- ------- imported_tf_model MODEL
API
Insérez une nouvelle tâche et renseignez la propriété jobs#configuration.query dans le corps de la requête.
{ "query": "CREATE MODEL `PROJECT_ID:bqml_tutorial.imported_tf_model` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')" }
Remplacez PROJECT_ID par le nom de votre projet et de votre ensemble de données.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Importez le modèle à l'aide de l'objet TensorFlowModel.
Pour en savoir plus sur l'importation de modèles TensorFlow dans BigQuery ML, y compris sur les exigences de format et de stockage, consultez la section Instruction CREATE MODEL pour l'importation de modèles TensorFlow.
Effectuer des prédictions à l'aide du modèle TensorFlow importé
Après avoir importé le modèle TensorFlow, vous utilisez la fonction ML.PREDICT pour effectuer des prédictions avec le modèle.
La requête suivante utilise imported_tf_model pour effectuer des prédictions à l'aide des données d'entrée de la table full dans l'ensemble de données public hacker_news. Dans la requête, la fonction serving_input_fn du modèle TensorFlow indique que le modèle s'attend à une seule chaîne d'entrée nommée input. La sous-requête attribue l'alias input à la colonne title dans l'instruction SELECT de la sous-requête.
Pour effectuer des prédictions avec le modèle TensorFlow importé, suivez ces étapes.
Console
Dans la console Google Cloud , accédez à la page BigQuery.
Sous Créer, cliquez sur Requête SQL.
Dans l'éditeur de requête, saisissez la requête qui utilise la fonction
ML.PREDICT.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_tf_model`, ( SELECT title AS input FROM bigquery-public-data.hacker_news.full ) )
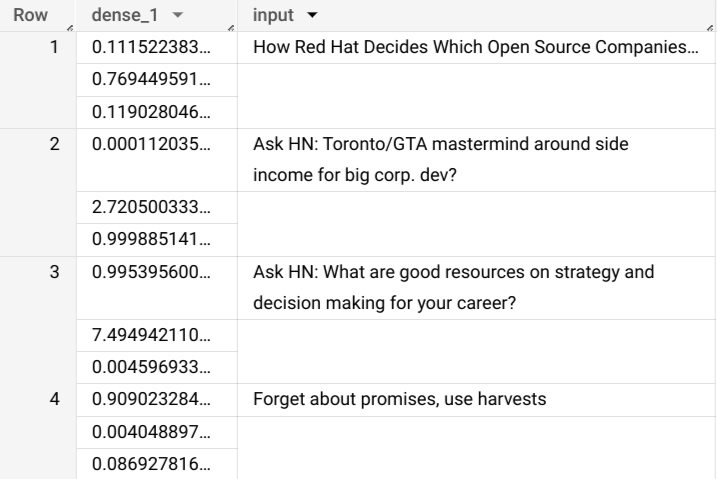
Les résultats de la requête devraient se présenter comme suit :
bq
Saisissez cette commande pour exécuter la requête qui utilise ML.PREDICT.
bq query \ --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `bqml_tutorial.imported_tf_model`, (SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
Les résultats doivent se présenter sous la forme suivante :
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | dense_1 | input | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... | | ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? | | ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? | | ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
Insérez une nouvelle tâche et renseignez la propriété jobs#configuration.query comme dans le corps de la requête. Remplacez project_id par le nom de votre projet.
{ "query": "SELECT * FROM ML.PREDICT(MODEL `project_id.bqml_tutorial.imported_tf_model`, (SELECT * FROM input_data))" }
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Utilisez la fonction predict pour exécuter le modèle TensorFlow :
Les résultats doivent se présenter sous la forme suivante :
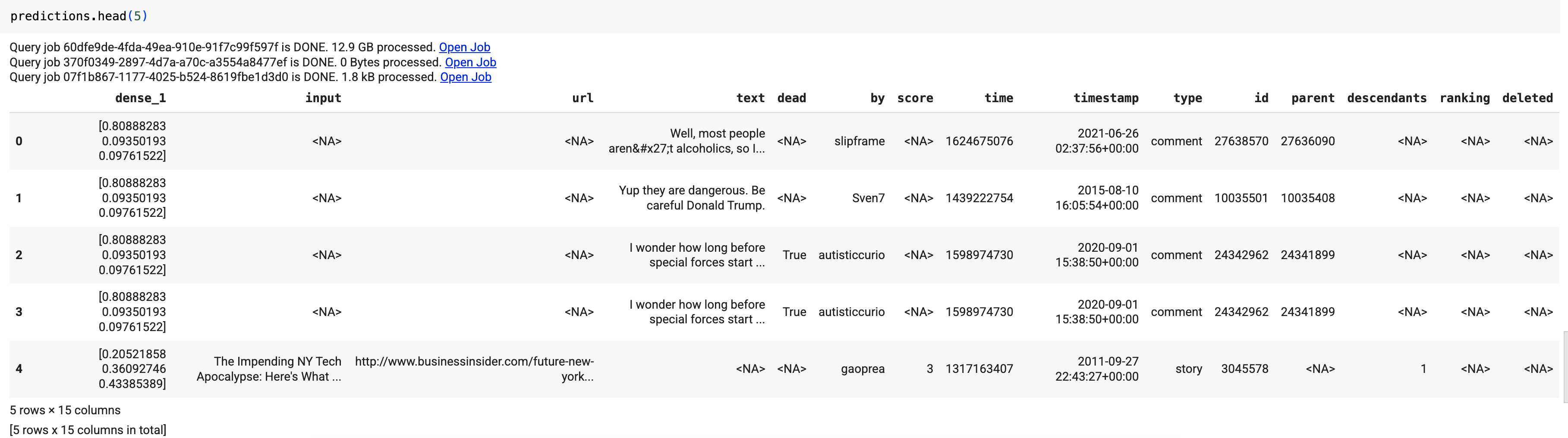
Dans les résultats de la requête, la colonne dense_1 contient un tableau de valeurs de probabilité, et la colonne input contient les valeurs de chaîne correspondantes de la table d'entrée. Chaque valeur d'élément du tableau représente la probabilité que la chaîne d'entrée correspondante soit un titre d'article issu d'une publication spécifique.
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
Console
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
gcloud
Supprimer un projet Google Cloud :
gcloud projects delete PROJECT_ID
Supprimer des ressources individuelles
Vous pouvez également supprimer les ressources individuelles utilisées dans ce tutoriel :
Facultatif : supprimez l'ensemble de données.
Étapes suivantes
- Pour obtenir plus d'informations sur BigQuery ML, consultez la présentation de BigQuery ML.
- Pour commencer à utiliser BigQuery ML, consultez Créer des modèles de machine learning dans BigQuery ML.
- Pour en savoir plus sur l'importation de modèles TensorFlow, consultez la section Instruction
CREATE MODELpour importer des modèles TensorFlow. - Pour en savoir plus sur l'utilisation des modèles, consultez les ressources suivantes :
- Pour en savoir plus sur l'utilisation de l'API BigQuery DataFrames dans un notebook BigQuery, consultez les pages suivantes :