
En este instructivo, importarás modelos de TensorFlow a un conjunto de datos de BigQuery ML. Luego, usas una consulta en SQL para generar predicciones a partir de los modelos importados.
Objetivos
- Usa la sentencia
CREATE MODELpara importar modelos de TensorFlow en BigQuery ML. - Usa la función
ML.PREDICTpara hacer predicciones con los modelos de TensorFlow importados.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto,
usa la calculadora de precios.
Cuando completes las tareas que se describen en este documento, podrás borrar los recursos que creaste para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Antes de comenzar
- Accede a tu cuenta de Google Cloud . Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verifica que la facturación esté habilitada para tu proyecto de Google Cloud .
Asegúrate de que la API de BigQuery esté habilitada.
- Asegúrate de tener los permisos necesarios para realizar las tareas de este documento.
Roles obligatorios
Si creas un proyecto nuevo, serás el propietario y se te otorgarán todos los permisos de Identity and Access Management (IAM) necesarios para completar este instructivo.
Si usas un proyecto existente, el rol de Administrador de BigQuery Studio (roles/bigquery.studioAdmin) otorga todos los permisos necesarios para completar este instructivo.
Asegúrate de tener los siguientes roles en el proyecto:
Administrador de BigQuery Studio (roles/bigquery.studioAdmin).
Verifica los roles
-
En la consola de Google Cloud , dirígete a la página IAM.
Ir a IAM - Selecciona el proyecto.
-
En la columna Principal, busca todas las filas que te identifiquen a ti o a un grupo en el que se te incluya. Para saber en qué grupos estás incluido, comunícate con tu administrador.
- Para todas las filas en las que se te especifique o se te incluya, verifica la columna Rol para ver si la lista de roles incluye los roles necesarios.
Otorga los roles
-
En la consola de Google Cloud , dirígete a la página IAM.
Ir a IAM - Selecciona el proyecto.
- Haz clic en Otorgar acceso.
-
En el campo Principales nuevas, ingresa tu identificador de usuario. Esta suele ser la dirección de correo electrónico de una Cuenta de Google.
- Haz clic en Seleccionar un rol y, luego, busca el rol.
- Para otorgar roles adicionales, haz clic en Agregar otro rol y agrega uno más.
- Haz clic en Guardar.
Para obtener más información sobre los permisos de IAM en BigQuery, consulta Permisos de BigQuery.
Crea un conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU..
Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos nuevo, usa el comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos establecida enUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Confirma que se haya creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Importa un modelo de TensorFlow
En los siguientes pasos, se muestra cómo importar un modelo desde Cloud Storage.
La ruta de acceso al modelo es gs://cloud-training-demos/txtclass/export/exporter/1549825580/*. El nombre del modelo importado es imported_tf_model.
Ten en cuenta que el URI de Cloud Storage termina en un carácter comodín (*), que indica que BigQuery ML debe importar los recursos asociados con el modelo.
El modelo importado es un modelo clasificador de texto de TensorFlow que predice qué sitio web publicó el título de un artículo determinado.
Para importar el modelo de TensorFlow a tu conjunto de datos, sigue estos pasos.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En Crear nuevo, haz clic en Consulta en SQL.
En el editor de consultas, ingresa esta sentencia
CREATE MODELy, luego, haz clic en Ejecutar.CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')
Cuando se complete la operación, deberías ver un mensaje como
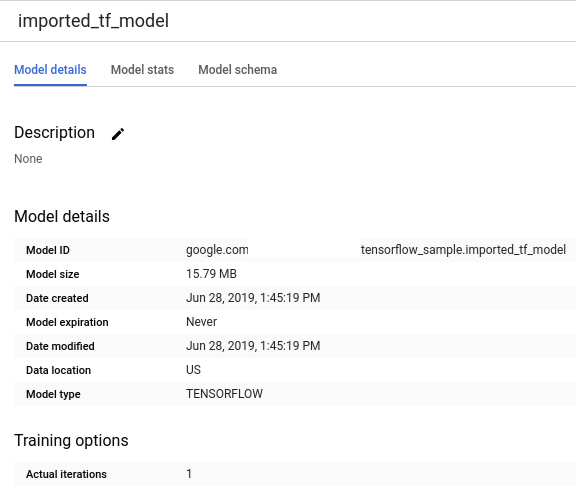
Successfully created model named imported_tf_model.Tu nuevo modelo aparece en el panel Recursos. Los modelos se indican con el ícono de modelo:
 .
.Si seleccionas el modelo nuevo en el panel Recursos, la información sobre el modelo aparece debajo del Editor de consultas.
bq
Para importar el modelo de TensorFlow desde Cloud Storage, ingresa la siguiente instrucción
CREATE MODEL.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.imported_tf_model` OPTIONS (MODEL_TYPE='TENSORFLOW', MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')"
Después de importar el modelo, verifica que aparezca en el conjunto de datos.
bq ls -m bqml_tutorial
El resultado es similar a lo siguiente:
tableId Type ------------------- ------- imported_tf_model MODEL
API
Inserta un nuevo trabajo y propaga la propiedad jobs#configuration.query en el cuerpo de la solicitud.
{ "query": "CREATE MODEL `PROJECT_ID:bqml_tutorial.imported_tf_model` OPTIONS(MODEL_TYPE='TENSORFLOW' MODEL_PATH='gs://cloud-training-demos/txtclass/export/exporter/1549825580/*')" }
Reemplaza PROJECT_ID por el nombre de tu proyecto y conjunto de datos.
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Importa el modelo con el objeto TensorFlowModel.
Para obtener más información sobre cómo importar modelos de TensorFlow a BigQuery ML, incluidos los requisitos de formato y almacenamiento, consulta la declaración CREATE MODEL para importar modelos de TensorFlow.
Realiza predicciones con el modelo de TensorFlow importado
Después de importar el modelo de TensorFlow, usas la función ML.PREDICT para hacer predicciones con el modelo.
La siguiente consulta usa imported_tf_model para realizar predicciones con datos de entrada de la tabla full en el conjunto de datos públicos hacker_news. En la consulta, la función serving_input_fn del modelo de TensorFlow especifica que el modelo espera una sola cadena de entrada llamada input. La subconsulta asigna el alias input a la columna title en la declaración SELECT de la subconsulta.
Para realizar predicciones con el modelo importado de TensorFlow, sigue estos pasos.
Console
En la consola de Google Cloud , ve a la página BigQuery.
En Crear nuevo, haz clic en Consulta en SQL.
En el editor de consultas, ingresa esta consulta que usa la función
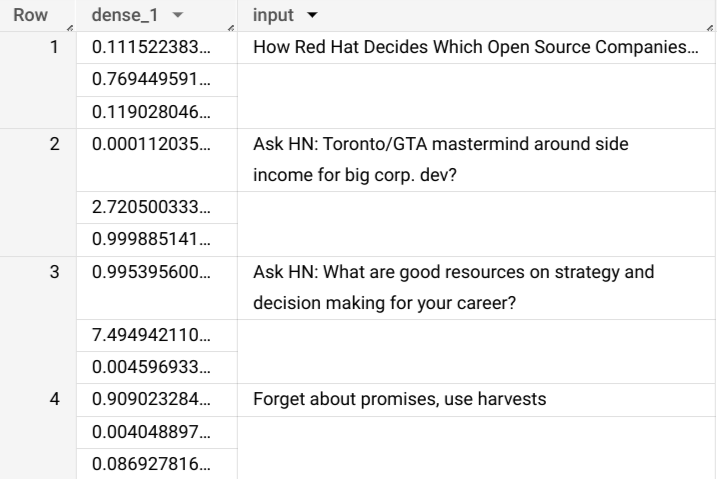
ML.PREDICT.SELECT * FROM ML.PREDICT(MODEL `bqml_tutorial.imported_tf_model`, ( SELECT title AS input FROM bigquery-public-data.hacker_news.full ) )
Los resultados de la búsqueda deberían verse así:
bq
Ingresa este comando para ejecutar la consulta que usa ML.PREDICT.
bq query \ --use_legacy_sql=false \ 'SELECT * FROM ML.PREDICT( MODEL `bqml_tutorial.imported_tf_model`, (SELECT title AS input FROM `bigquery-public-data.hacker_news.full`))'
Los resultados deberían verse así:
+------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | dense_1 | input | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+ | ["0.6251608729362488","0.2989124357700348","0.07592673599720001"] | How Red Hat Decides Which Open Source Companies t... | | ["0.014276246540248394","0.972910463809967","0.01281337533146143"] | Ask HN: Toronto/GTA mastermind around side income for big corp. dev? | | ["0.9821603298187256","1.8601855117594823E-5","0.01782100833952427"] | Ask HN: What are good resources on strategy and decision making for your career? | | ["0.8611106276512146","0.06648492068052292","0.07240450382232666"] | Forget about promises, use harvests | +------------------------------------------------------------------------+----------------------------------------------------------------------------------+
API
Inserta un nuevo trabajo y propaga la propiedad jobs#configuration.query como en el cuerpo de la solicitud. Reemplaza project_id por el nombre de tu proyecto.
{ "query": "SELECT * FROM ML.PREDICT(MODEL `project_id.bqml_tutorial.imported_tf_model`, (SELECT * FROM input_data))" }
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Usa la función predict para ejecutar el modelo de TensorFlow:
Los resultados deberían verse así:
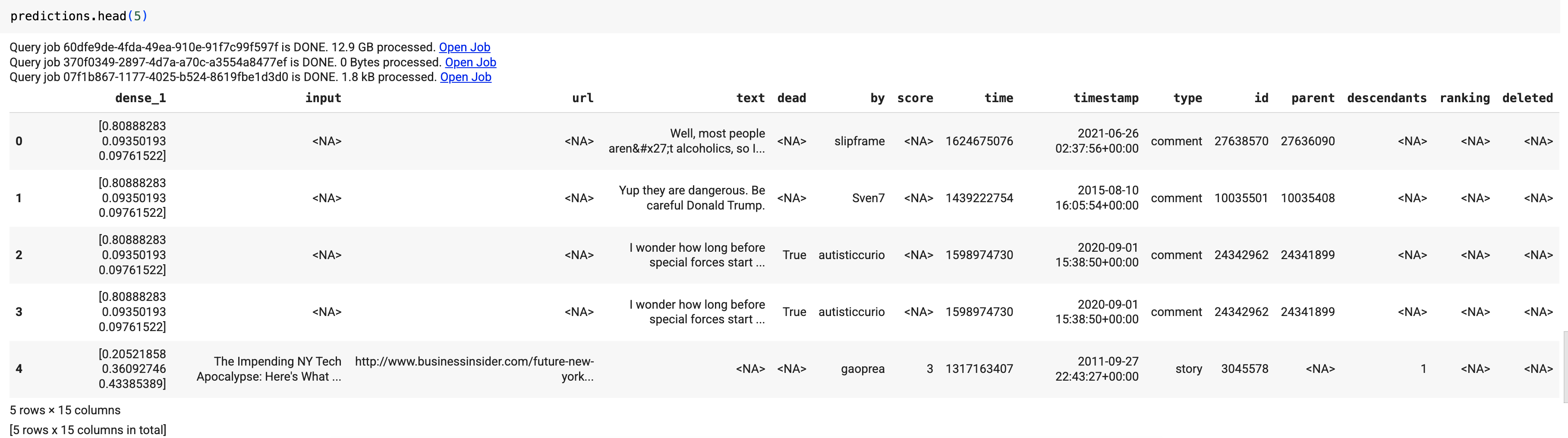
En los resultados de la consulta, la columna dense_1 contiene un array de valores de probabilidad, y la columna input contiene los valores de cadena correspondientes de la tabla de entrada. Cada valor del elemento del array representa la probabilidad de que la cadena de entrada correspondiente sea el título de un artículo de una publicación en particular.
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
Console
- En la Google Cloud consola, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
gcloud
Borra un Google Cloud proyecto:
gcloud projects delete PROJECT_ID
Borra los recursos individuales
Como alternativa, quita los recursos individuales que se usan en este instructivo:
Opcional: Borra el conjunto de datos.
¿Qué sigue?
- Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para comenzar a usar BigQuery ML, consulta Crea modelos de aprendizaje automático en BigQuery ML.
- Para obtener más información sobre la importación de modelos de TensorFlow, consulta la declaración
CREATE MODELpara importar modelos de TensorFlow. - Para obtener más información sobre cómo trabajar con modelos, consulta estos recursos:
- Para obtener más información sobre el uso de la API de BigQuery DataFrames en un notebook de BigQuery, consulta lo siguiente: