
In dieser Anleitung erfahren Sie, wie Sie ein k-means-Modell in BigQuery ML verwenden, um Cluster in einem Datensatz zu identifizieren.
Der k-means-Algorithmus, mit dem Ihre Daten in Clustern gruppiert werden, ist eine Form des unüberwachten maschinellen Lernens. Anders als bei überwachtem maschinellem Lernen, bei dem es um vorhersagende Analysen geht, beschäftigt sich das unüberwachte Lernen mit beschreibenden Analysen. Mit unüberwachtem maschinellem Lernen können Sie Ihre Daten besser verstehen und datengestützte Entscheidungen treffen.
Die Abfragen in dieser Anleitung verwenden geografische Funktionen, die für die raumbezogene Analyse verfügbar sind. Weitere Informationen finden Sie unter Einführung in raumbezogene Analysen.
In dieser Anleitung wird das öffentliche Dataset zum Fahrradverleih in London verwendet. Außerdem enthalten die Daten Zeitstempel zu Leihbeginn und -ende, Namen von Verleihstationen und Fahrtdauer.
Ziele
In dieser Anleitung werden Sie durch die folgenden Aufgaben geführt:- Prüfen Sie die Daten, die zum Trainieren des Modells verwendet wurden.
- Ein k-Means-Clustering-Modell erstellen
- Interpretieren Sie die erstellten Datencluster anhand der Clustervisualisierung in BigQuery ML.
- Führen Sie die
ML.PREDICT-Funktion für das k-Means-Modell aus, um den wahrscheinlichen Cluster für eine Reihe von Fahrradverleihstationen vorherzusagen.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Informationen zu den Kosten für BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Wenn Sie BigQuery in einem bestehenden Projekt aktivieren möchten, wechseln Sie zu
Aktivieren Sie die BigQuery API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Weitere Informationen zum Zuweisen von Rollen
Erforderliche Berechtigungen
Sie benötigen die IAM-Berechtigung
bigquery.datasets.create, um das Dataset zu erstellen.Zum Erstellen des Modells benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatabigquery.jobs.create
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres K-Means-Modells:
Rufen Sie in der Google Cloud Console die Seite "BigQuery" auf.
Klicken Sie im linken Bereich auf Explorer:

Wenn Sie den linken Bereich nicht sehen, klicken Sie auf Linken Bereich maximieren, um ihn zu öffnen.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.

Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Multiregional und dann EU (mehrere Regionen in der Europäischen Union) aus.
Das öffentliche Dataset zum Fahrradverleih in London wird in der Multiregion
EUgespeichert. Ihr Dataset muss sich am selben Standort befinden.Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.

Trainingsdaten prüfen
Prüfen Sie die Daten, die Sie zum Trainieren des k-means-Modells verwenden möchten. In dieser Anleitung clustern Sie Radstationen anhand der folgenden Attribute:
- Dauer des Verleihs
- Anzahl der Fahrten pro Tag
- Entfernung zum Stadtzentrum
SQL
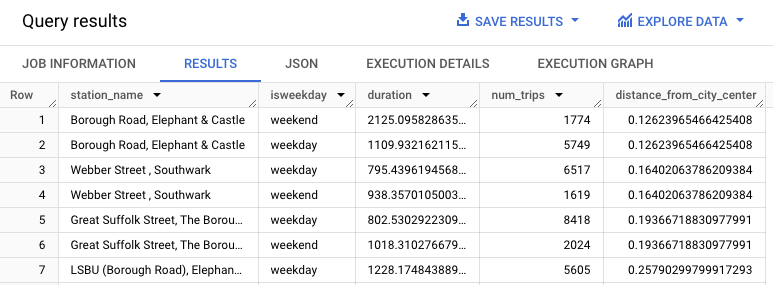
Diese Abfrage extrahiert Daten zum Fahrradverleih, einschließlich der Spalten start_station_name und duration, und verknüpft diese Daten mit Informationen zu Radstationen. Dazu gehört das Erstellen einer berechneten Spalte, die die Entfernung der Station vom Stadtzentrum enthält. Anschließend werden Attribute der Station, einschließlich der durchschnittlichen Fahrtzeit und der Anzahl der Fahrten, in einer stationstats-Spalte berechnet und die berechnete distance_from_city_center-Spalte wird durchlaufen.
So untersuchen Sie die Trainingsdaten:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * FROM stationstats ORDER BY distance_from_city_center ASC;
Die Antwort sollte in etwa so aussehen:
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
k-means-Modell erstellen
Erstellen Sie ein k-means-Modell mit den Trainingsdaten zum Fahrradverleih in London.
SQL
In der folgenden Abfrage gibt die Anweisung CREATE MODEL die Anzahl der Cluster an, die verwendet werden sollen, nämlich vier. In der SELECT-Anweisung schließt die Klausel EXCEPT die Spalte station_name aus, da diese Spalte kein Feature enthält. Mit der Abfrage wird pro „station_name“ eine eindeutige Zeile erstellt und in der SELECT-Anweisung werden nur die Features genannt.
So erstellen Sie ein k-Means-Modell:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.london_station_clusters` OPTIONS ( model_type = 'kmeans', num_clusters = 4) AS WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (station_name, isweekday) FROM stationstats;
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Datencluster interpretieren
Die Informationen auf dem Tab Bewertung des Modells können Ihnen helfen, die vom Modell erstellten Cluster zu interpretieren.
So rufen Sie die Bewertungsinformationen des Modells auf:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im linken Bereich auf Explorer:
Maximieren Sie im Bereich Explorer Ihr Projekt und klicken Sie auf Datasets.
Klicken Sie auf das Dataset
bqml_tutorialund rufen Sie dann den Tab Modelle auf.Wählen Sie das
london_station_clusters-Modell aus.Wählen Sie den Tab Bewertung aus. In diesem Tab werden Visualisierungen der durch das k-Means-Modell identifizierten Cluster angezeigt. Im Bereich Numerische Features werden in Balkendiagrammen die wichtigsten numerischen Featurewerte für jeden Schwerpunkt (Centroid) angezeigt. Jeder Schwerpunkt repräsentiert einen bestimmten Datencluster. Im Drop-down-Menü können Sie auswählen, welche Features angezeigt werden sollen.
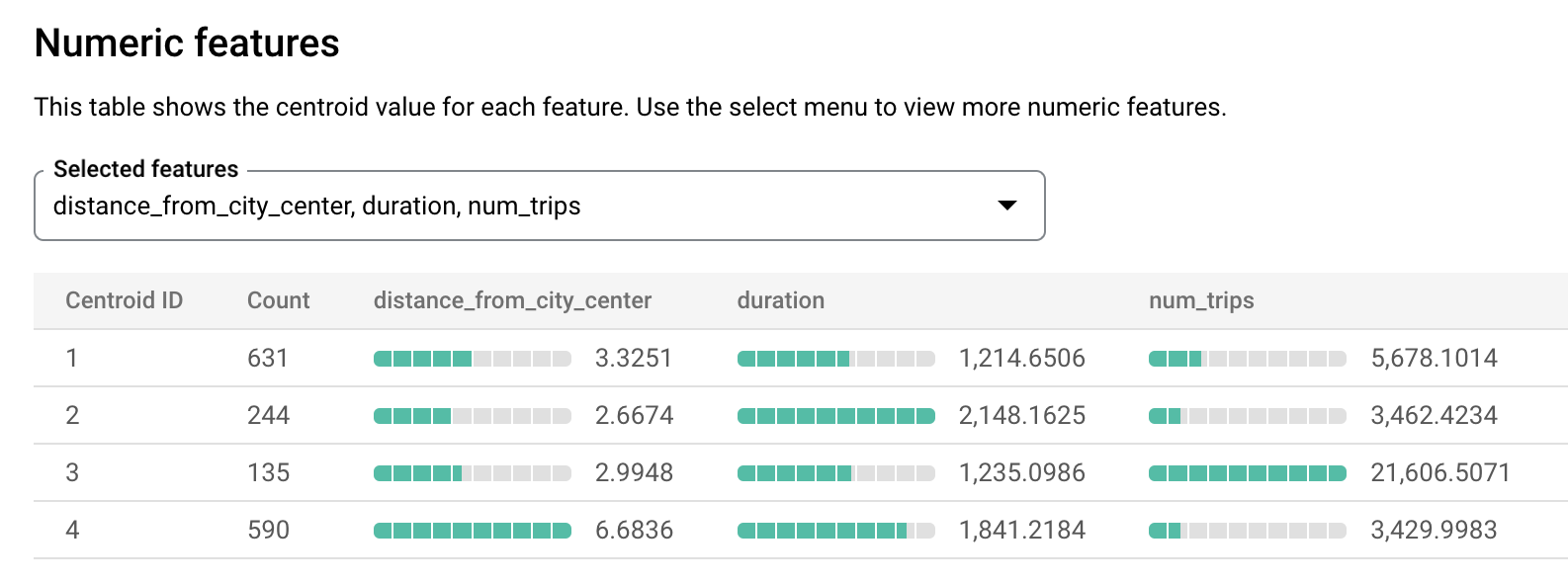
Mit diesem Modell werden die folgenden Schwerpunkte erstellt:
- Schwerpunkt 1 ist die weniger ausgelastete Station in der Stadt, mit kürzerer Mietdauer.
- Centerid 2 zeigt die zweite Station, die weniger ausgelastet ist und für längere Mietzeiten genutzt wird.
- Centroid 3 zeigt eine belebte Radstation in der Nähe des Stadtzentrums.
- Centerid 4 zeigt eine Vorstadtstation, deren Fahrten länger sind.
Wenn Sie ein Fahrradverleihunternehmen betreiben, können Sie diese Informationen für Geschäftsentscheidungen nutzen. Beispiel:
Angenommen, Sie müssen eine neue Art Schloss ausprobieren. Welchen Radstations-Cluster sollten Sie für dieses Experiment wählen? Die Stationen in Centroid 1, Centroid 2 oder Centroid 4 scheinen die logische Wahl zu sein, weil sie nicht die am stärksten frequentierten Stationen sind.
In einer weiteren Annahme möchten Sie in einigen Radstationen Rennräder bereitstellen. Welche Stationen wären hierfür die richtige Wahl? Centroid 4 ist die Station, die weit vom Stadtzentrum entfernt ist und an der die längsten Fahrten verzeichnet werden. Hier haben Sie Ihre Kandidaten für Rennräder.
Mit der Funktion ML.PREDICT den Cluster einer Radstation vorhersagen
Mit der SQL-Funktion ML.PREDICT oder der BigQuery DataFrames-Funktion predict können Sie den Cluster ermitteln, zu dem eine bestimmte Station gehört.
SQL
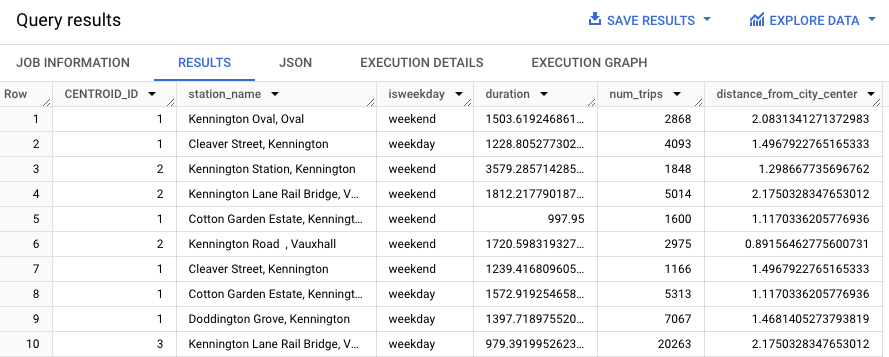
In der folgenden Abfrage wird die Funktion REGEXP_CONTAINS verwendet, um in der Spalte station_name alle Einträge zu finden, die den String Kennington enthalten. Anhand dieser Werte prognostiziert die Funktion ML.PREDICT, welche Cluster diese Stationen enthalten könnten.
So sagen Sie den Cluster jeder Radstation vorher, deren Name den String Kennington enthält:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
WITH hs AS ( SELECT h.start_station_name AS station_name, IF( EXTRACT(DAYOFWEEK FROM h.start_date) = 1 OR EXTRACT(DAYOFWEEK FROM h.start_date) = 7, 'weekend', 'weekday') AS isweekday, h.duration, ST_DISTANCE(ST_GEOGPOINT(s.longitude, s.latitude), ST_GEOGPOINT(-0.1, 51.5)) / 1000 AS distance_from_city_center FROM `bigquery-public-data.london_bicycles.cycle_hire` AS h JOIN `bigquery-public-data.london_bicycles.cycle_stations` AS s ON h.start_station_id = s.id WHERE h.start_date BETWEEN CAST('2015-01-01 00:00:00' AS TIMESTAMP) AND CAST('2016-01-01 00:00:00' AS TIMESTAMP) ), stationstats AS ( SELECT station_name, isweekday, AVG(duration) AS duration, COUNT(duration) AS num_trips, MAX(distance_from_city_center) AS distance_from_city_center FROM hs GROUP BY station_name, isweekday ) SELECT * EXCEPT (nearest_centroids_distance) FROM ML.PREDICT( MODEL `bqml_tutorial.london_station_clusters`, ( SELECT * FROM stationstats WHERE REGEXP_CONTAINS(station_name, 'Kennington') ));
Die Ergebnisse sollten in etwa so aussehen:
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset und das Modell gelöscht.
Bestätigen Sie im Dialogfeld Dataset löschen den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Löschen.
Projekt löschen
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Einführung in BigQuery ML
- Weitere Informationen zum Erstellen von Modellen finden Sie auf der Seite zur
CREATE MODEL-Syntax