
Questo tutorial mostra come esportare un modello Transformer nel formato Open Neural Network Exchange (ONNX), importare il modello ONNX in un set di dati BigQuery e quindi utilizzare il modello per generare incorporamenti da una query SQL.
Questo tutorial utilizza il
modello sentence-transformers/all-MiniLM-L6-v2.
Questo modello di trasformazione delle frasi è noto per le sue prestazioni rapide ed efficaci
nella generazione di incorporamenti di frasi. L'incorporamento di frasi consente attività come
la ricerca semantica, il clustering e la somiglianza di frasi acquisendo il
significato sottostante del testo.
ONNX fornisce un formato uniforme progettato per rappresentare qualsiasi framework di machine learning (ML). Il supporto di BigQuery ML per ONNX ti consente di:
- Addestra un modello utilizzando il tuo framework preferito.
- Converti il modello nel formato ONNX.
- Importa il modello ONNX in BigQuery ed esegui previsioni utilizzando BigQuery ML.
Obiettivi
- Utilizza l'interfaccia a riga di comando Hugging Face Optimum per esportare il modello
sentence-transformers/all-MiniLM-L6-v2in ONNX. - Utilizza l'istruzione
CREATE MODELper importare il modello ONNX in BigQuery. - Utilizza la
funzione
ML.PREDICTper generare embedding con il modello ONNX importato.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per saperne di più, consulta Esegui la pulizia.
Prima di iniziare
- Accedi al tuo account Google Cloud . Se non conosci Google Cloud, crea un account per valutare le prestazioni dei nostri prodotti in scenari reali. I nuovi clienti ricevono anche 300 $di crediti senza costi per l'esecuzione, il test e il deployment dei workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verifica che la fatturazione sia abilitata per il tuo progetto Google Cloud .
Attiva le API BigQuery e Cloud Storage.
Ruoli richiesti per abilitare le API
Per abilitare le API, devi disporre del ruolo IAM Amministratore utilizzo dei servizi (
roles/serviceusage.serviceUsageAdmin), che include l'autorizzazioneserviceusage.services.enable. Scopri come concedere i ruoli.- Assicurati di disporre delle autorizzazioni necessarie per eseguire le attività descritte in questo documento.
Ruoli obbligatori
Se crei un nuovo progetto, sei il proprietario del progetto e ti vengono concesse tutte le autorizzazioni IAM (Identity and Access Management) richieste per completare questo tutorial.
Se utilizzi un progetto esistente, procedi nel seguente modo.
Assicurati di disporre dei seguenti ruoli nel progetto:
- Amministratore BigQuery Studio (
roles/bigquery.studioAdmin) - Creatore oggetti Storage (
roles/storage.objectCreator)
Controlla i ruoli
-
Nella console Google Cloud vai alla pagina IAM.
Vai a IAM - Seleziona il progetto.
-
Nella colonna Entità, trova tutte le righe che identificano te o un gruppo di cui fai parte. Per scoprire a quali gruppi appartieni, contatta il tuo amministratore.
- Per tutte le righe che ti specificano o ti includono, controlla la colonna Ruolo per verificare se l'elenco dei ruoli include i ruoli richiesti.
Concedi i ruoli
-
Nella console Google Cloud vai alla pagina IAM.
Vai a IAM - Seleziona il progetto.
- Fai clic su Concedi l'accesso.
-
Nel campo Nuove entità, inserisci il tuo identificatore dell'utente. In genere si tratta dell'indirizzo email di un Account Google.
- Fai clic su Seleziona un ruolo, quindi cerca il ruolo.
- Per concedere altri ruoli, fai clic su Aggiungi un altro ruolo e aggiungi ogni ruolo successivo.
- Fai clic su Salva.
Per saperne di più sulle autorizzazioni IAM in BigQuery, consulta Autorizzazioni IAM.
Converti i file del modello Transformer in ONNX
Se vuoi, puoi seguire i passaggi descritti in questa sezione per convertire manualmente il modello sentence-transformers/all-MiniLM-L6-v2 e il tokenizer in ONNX.
In alternativa, puoi utilizzare i file di esempio del bucket Cloud Storage pubblico gs://cloud-samples-data
che sono già stati convertiti.
Se scegli di convertire manualmente i file, devi disporre di un ambiente a riga di comando locale con Python installato. Per ulteriori informazioni sull'installazione di Python, consulta la pagina Download di Python.
Esporta il modello Transformer in ONNX
Utilizza la CLI Hugging Face Optimum per esportare il modello sentence-transformers/all-MiniLM-L6-v2 in ONNX.
Per saperne di più sull'esportazione di modelli con Optimum CLI, vedi
Esportare un modello in ONNX con optimum.exporters.onnx.
Per esportare il modello, apri un ambiente a riga di comando e segui questi passaggi:
Installa l'interfaccia a riga di comando Optimum:
pip install optimum[onnx]Esporta il modello. L'argomento
--modelspecifica l'ID modello Hugging Face. L'argomento--opsetspecifica la versione della libreria ONNXRuntime ed è impostato su17per mantenere la compatibilità con la libreria ONNXRuntime supportata da BigQuery.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
Il file del modello viene esportato nella directory all-MiniLM-L6-v2 come model.onnx.
Applica la quantizzazione al modello Transformer
Utilizza la CLI Optimum per applicare la quantizzazione al modello transformer esportato per ridurre le dimensioni del modello e velocizzare l'inferenza. Per ulteriori informazioni, vedi Quantizzazione.
Per applicare la quantizzazione al modello, esegui questo comando sulla riga di comando:
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
Il file del modello quantizzato viene esportato nella directory all-MiniLM-L6-v2_quantized
come model_quantized.onnx.
Converti il tokenizer in ONNX
Per generare incorporamenti utilizzando un modello Transformer in formato ONNX, in genere utilizzi un
tokenizer
per produrre due input per il modello, input_ids e attention_mask.
Per produrre questi input, converti il tokenizer per il modello sentence-transformers/all-MiniLM-L6-v2 in formato ONNX utilizzando la libreria onnxruntime-extensions. Dopo aver convertito il tokenizer, puoi eseguire la tokenizzazione
direttamente sugli input di testo non elaborato per generare previsioni ONNX.
Per convertire il tokenizer, segui questi passaggi dalla riga di comando:
Installa l'interfaccia a riga di comando Optimum:
pip install optimum[onnx]Utilizzando l'editor di testo che preferisci, crea un file denominato
convert-tokenizer.py. L'esempio seguente utilizza l'editor di testo nano:nano convert-tokenizer.pyCopia e incolla il seguente script Python nel file
convert-tokenizer.py:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())Salva il file
convert-tokenizer.py.Esegui lo script Python per convertire il tokenizer:
python convert-tokenizer.py
Il tokenizer convertito viene esportato nella directory all-MiniLM-L6-v2_quantized
come tokenizer.onnx.
Carica i file del modello convertito su Cloud Storage
Dopo aver convertito il modello Transformer e il tokenizer, procedi nel seguente modo:
- Crea un bucket Cloud Storage per archiviare i file convertiti.
- Carica il modello Transformer convertito e i file del tokenizer nel bucket Cloud Storage.
Crea un set di dati
Crea un set di dati BigQuery per archiviare il tuo modello ML.Console
Nella console Google Cloud , vai alla pagina BigQuery.
Nel riquadro Explorer, fai clic sul nome del progetto.
Fai clic su Visualizza azioni > Crea set di dati.
Nella pagina Crea set di dati, segui questi passaggi:
In ID set di dati, inserisci
bqml_tutorial.Per Tipo di località, seleziona Multi-regione e poi Stati Uniti.
Lascia invariate le restanti impostazioni predefinite e fai clic su Crea set di dati.
bq
Per creare un nuovo set di dati, utilizza il
comando bq mk --dataset.
Crea un set di dati denominato
bqml_tutorialcon la località dei dati impostata suUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Verifica che il set di dati sia stato creato:
bq ls
API
Chiama il metodo datasets.insert con una risorsa dataset definita.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery per l'utilizzo di BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura ADC per un ambiente di sviluppo locale.
Importa i modelli ONNX in BigQuery
Importa i modelli di tokenizer e sentence transformer convertiti come modelli BigQuery ML.
Seleziona una delle seguenti opzioni:
Console
Nella console Google Cloud , apri BigQuery Studio.
Nell'editor di query, esegui la seguente istruzione
CREATE MODELper creare il modellotokenizer.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
Sostituisci
TOKENIZER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTOKENIZER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Al termine dell'operazione, viene visualizzato un messaggio simile al seguente:
Successfully created model named tokenizernel riquadro Risultati query.Fai clic su Vai al modello per aprire il riquadro Dettagli.
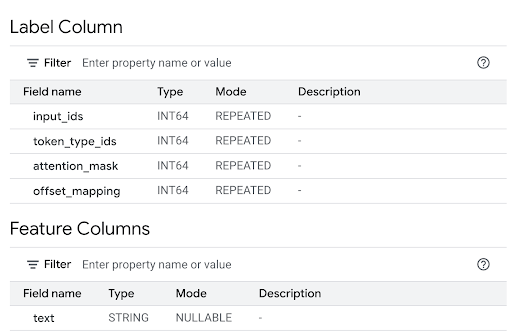
Esamina la sezione Colonne di caratteristiche per visualizzare gli input del modello e la Colonna etichetta per visualizzare gli output del modello.
Nell'editor di query, esegui la seguente istruzione
CREATE MODELper creare il modelloall-MiniLM-L6-v2.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
Sostituisci
TRANSFORMER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTRANSFORMER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Al termine dell'operazione, viene visualizzato un messaggio simile al seguente:
Successfully created model named all-MiniLM-L6-v2nel riquadro Risultati query.Fai clic su Vai al modello per aprire il riquadro Dettagli.
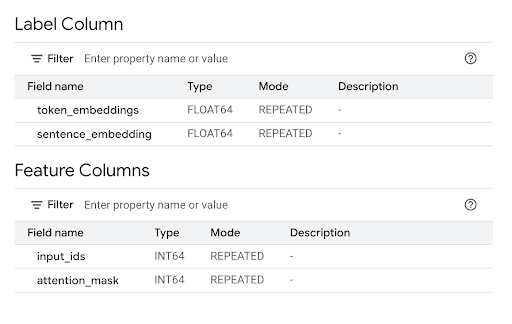
Esamina la sezione Colonne di caratteristiche per visualizzare gli input del modello e la Colonna etichetta per visualizzare gli output del modello.
bq
Utilizza lo strumento a riga di comando bq
comando query
per eseguire l'istruzione CREATE MODEL.
Nella riga di comando, esegui questo comando per creare il modello
tokenizer.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"Sostituisci
TOKENIZER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTOKENIZER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Al termine dell'operazione, viene visualizzato un messaggio simile al seguente:
Successfully created model named tokenizer.Nella riga di comando, esegui questo comando per creare il modello
all-MiniLM-L6-v2.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"Sostituisci
TRANSFORMER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTRANSFORMER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Al termine dell'operazione, viene visualizzato un messaggio simile al seguente:
Successfully created model named all-MiniLM-L6-v2.Dopo aver importato i modelli, verifica che vengano visualizzati nel set di dati.
bq ls -m bqml_tutorial
L'output è simile al seguente:
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
Utilizza il metodo jobs.insert
per importare i modelli. Compila il parametro query della
risorsa QueryRequest
nel corpo della richiesta con l'istruzione CREATE MODEL.
Utilizza il seguente valore parametro
queryper creare il modellotokenizer.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }Sostituisci quanto segue:
PROJECT_IDcon l'ID progetto.TOKENIZER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTOKENIZER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.
Utilizza il seguente valore parametro
queryper creare il modelloall-MiniLM-L6-v2.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }Sostituisci quanto segue:
PROJECT_IDcon l'ID progetto.TRANSFORMER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTRANSFORMER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery per l'utilizzo di BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura ADC per un ambiente di sviluppo locale.
Importa i modelli di tokenizer e sentence transformer utilizzando l'oggetto
ONNXModel.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
Sostituisci quanto segue:
PROJECT_IDcon l'ID progetto.TOKENIZER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTOKENIZER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.TRANSFORMER_BUCKET_PATHcon il percorso del modello che hai caricato su Cloud Storage. Se utilizzi il modello di esempio, sostituisciTRANSFORMER_BUCKET_PATHcon il seguente valore:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
Generare embedding con i modelli ONNX importati
Utilizza i modelli di tokenizer e sentence transformer importati per generare
incorporamenti basati sui dati del set di dati pubblico bigquery-public-data.imdb.reviews.
Seleziona una delle seguenti opzioni:
Console
Utilizza la
funzione ML.PREDICT
per generare embedding con i modelli.
La query utilizza una chiamata ML.PREDICT nidificata per elaborare il testo non elaborato direttamente
tramite il tokenizer e il modello di embedding, come segue:
- Tokenizzazione (query interna): la chiamata
ML.PREDICTinterna utilizza il modellobqml_tutorial.tokenizer. Prende la colonnatitledal set di dati pubblicobigquery-public-data.imdb.reviewscome inputtext. Il modellotokenizerconverte le stringhe di testo non elaborate negli input token numerici richiesti dal modello principale, inclusi gli inputinput_idseattention_mask. - Generazione di incorporamenti (query esterna): la chiamata
ML.PREDICTesterna utilizza il modellobqml_tutorial.all-MiniLM-L6-v2. La query prende le colonneinput_idseattention_maskdall'output della query interna come input.
L'istruzione SELECT recupera la colonna sentence_embedding, che
è un array di valori FLOAT che rappresentano l'incorporamento semantico del testo.
Nella console Google Cloud , apri BigQuery Studio.
Nell'editor di query, esegui la query seguente.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
Il risultato è simile al seguente:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
Utilizza lo strumento a riga di comando bq
comando query
per eseguire una query. La query utilizza la
funzione ML.PREDICT
per generare embedding con i modelli.
La query utilizza una chiamata ML.PREDICT nidificata per elaborare il testo non elaborato direttamente
tramite il tokenizer e il modello di embedding, come segue:
- Tokenizzazione (query interna): la chiamata
ML.PREDICTinterna utilizza il modellobqml_tutorial.tokenizer. Prende la colonnatitledal set di dati pubblicobigquery-public-data.imdb.reviewscome inputtext. Il modellotokenizerconverte le stringhe di testo non elaborate negli input token numerici richiesti dal modello principale, inclusi gli inputinput_idseattention_mask. - Generazione di incorporamenti (query esterna): la chiamata
ML.PREDICTesterna utilizza il modellobqml_tutorial.all-MiniLM-L6-v2. La query prende le colonneinput_idseattention_maskdall'output della query interna come input.
L'istruzione SELECT recupera la colonna sentence_embedding, che
è un array di valori FLOAT che rappresentano l'incorporamento semantico del testo.
Nella riga di comando, esegui questo comando per eseguire la query.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
Il risultato è simile al seguente:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
BigQuery DataFrames
Prima di provare questo esempio, segui le istruzioni di configurazione di BigQuery DataFrames nella guida rapida di BigQuery per l'utilizzo di BigQuery DataFrames. Per ulteriori informazioni, consulta la documentazione di riferimento di BigQuery DataFrames.
Per eseguire l'autenticazione in BigQuery, configura le Credenziali predefinite dell'applicazione. Per saperne di più, consulta Configura ADC per un ambiente di sviluppo locale.
Utilizza il metodo predict
per generare embedding utilizzando i modelli ONNX.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
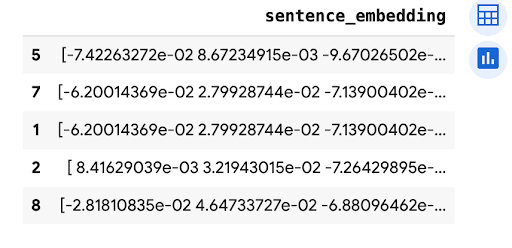
predictions.peek(5)
L'output è simile al seguente:
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
Console
- Nella console Google Cloud , vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona quello che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
gcloud
Elimina un progetto Google Cloud :
gcloud projects delete PROJECT_ID
Elimina singole risorse
In alternativa, per rimuovere le singole risorse utilizzate in questo tutorial:
(Facoltativo) Elimina il set di dati.
Passaggi successivi
- Scopri come utilizzare i text embedding per la ricerca semantica e la Retrieval Augmented Generation (RAG).
- Per saperne di più sulla conversione dei modelli Transformer in ONNX, consulta
Esportare un modello in ONNX con
optimum.exporters.onnx. - Per ulteriori informazioni sull'importazione di modelli ONNX, consulta
L'istruzione
CREATE MODELper i modelli ONNX. - Per saperne di più sull'esecuzione della previsione, consulta
La funzione
ML.PREDICT. - Per una panoramica di BigQuery ML, consulta Introduzione a BigQuery ML.
- Per iniziare a utilizzare BigQuery ML, consulta Creare modelli di machine learning in BigQuery ML.