
Tutorial ini menunjukkan cara mengekspor model transformer ke format Open Neural Network Exchange (ONNX), mengimpor model ONNX ke set data BigQuery, lalu menggunakan model tersebut untuk membuat embedding dari kueri SQL.
Tutorial ini menggunakan
model sentence-transformers/all-MiniLM-L6-v2.
Model transformer kalimat ini dikenal karena performanya yang cepat dan efektif dalam membuat embedding kalimat. Embedding kalimat memungkinkan tugas seperti penelusuran semantik, pengelompokan, dan kemiripan kalimat dengan menangkap makna teks yang mendasarinya.
ONNX menyediakan format seragam yang dirancang untuk merepresentasikan framework machine learning (ML) apa pun. Dengan dukungan ML BigQuery untuk ONNX, Anda dapat melakukan hal berikut:
- Melatih model menggunakan framework favorit Anda.
- Mengonversi model ke format model ONNX.
- Impor model ONNX ke BigQuery dan buat prediksi menggunakan BigQuery ML.
Tujuan
- Gunakan
Hugging Face Optimum CLI
untuk mengekspor model
sentence-transformers/all-MiniLM-L6-v2ke ONNX. - Gunakan
pernyataan
CREATE MODELuntuk mengimpor model ONNX ke BigQuery. - Gunakan
fungsi
ML.PREDICTuntuk membuat embedding dengan model ONNX yang diimpor.
Biaya
Dalam dokumen ini, Anda akan menggunakan komponen Google Cloudyang dapat ditagih berikut:
Untuk membuat perkiraan biaya berdasarkan proyeksi penggunaan Anda,
gunakan kalkulator harga.
Setelah menyelesaikan tugas yang dijelaskan dalam dokumen ini, Anda dapat menghindari penagihan berkelanjutan dengan menghapus resource yang Anda buat. Untuk mengetahui informasi selengkapnya, baca bagian Pembersihan.
Sebelum memulai
- Login ke akun Google Cloud Anda. Jika Anda baru menggunakan Google Cloud, buat akun untuk mengevaluasi performa produk kami dalam skenario dunia nyata. Pelanggan baru juga mendapatkan kredit gratis senilai $300 untuk menjalankan, menguji, dan men-deploy workload.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verifikasi bahwa penagihan diaktifkan untuk project Google Cloud Anda.
Aktifkan BigQuery dan Cloud Storage API.
Peran yang diperlukan untuk mengaktifkan API
Untuk mengaktifkan API, Anda memerlukan peran IAM Service Usage Admin (
roles/serviceusage.serviceUsageAdmin), yang berisi izinserviceusage.services.enable. Pelajari cara memberikan peran.- Pastikan Anda memiliki izin yang diperlukan untuk melakukan tugas dalam dokumen ini.
Peran yang diperlukan
Jika membuat project baru, Anda adalah pemilik project, dan Anda diberi semua izin Identity and Access Management (IAM) yang diperlukan untuk menyelesaikan tutorial ini.
Jika Anda menggunakan project yang sudah ada, lakukan hal berikut.
Pastikan Anda memiliki peran berikut di project:
- Admin BigQuery Studio (
roles/bigquery.studioAdmin) - Storage Object Creator (
roles/storage.objectCreator)
Memeriksa peran
-
Di konsol Google Cloud , buka halaman IAM.
Buka IAM - Pilih project.
-
Di kolom Principal, temukan semua baris yang mengidentifikasi Anda atau grup yang Anda termasuk di dalamnya. Untuk mengetahui grup mana saja yang Anda ikuti, hubungi administrator Anda.
- Untuk semua baris yang menentukan atau menyertakan Anda, periksa kolom Peran untuk melihat apakah daftar peran menyertakan peran yang diperlukan.
Memberikan peran
-
Di konsol Google Cloud , buka halaman IAM.
Buka IAM - Pilih project.
- Klik Grant access.
-
Di kolom New principals, masukkan ID pengguna Anda. Biasanya, ini adalah alamat email untuk Akun Google.
- Klik Pilih peran, lalu telusuri peran.
- Untuk memberikan peran tambahan, klik Add another role, lalu tambahkan tiap peran tambahan.
- Klik Simpan.
Untuk mengetahui informasi selengkapnya tentang izin IAM di BigQuery, lihat Izin IAM.
Mengonversi file model transformer ke ONNX
Jika ingin, Anda dapat mengikuti langkah-langkah di bagian ini untuk mengonversi model dan tokenizer sentence-transformers/all-MiniLM-L6-v2 ke ONNX secara manual.
Atau, Anda dapat menggunakan contoh file dari bucket Cloud Storage gs://cloud-samples-data publik yang telah dikonversi.
Jika memilih untuk mengonversi file secara manual, Anda harus memiliki lingkungan command line lokal yang telah menginstal Python. Untuk mengetahui informasi selengkapnya tentang cara menginstal Python, lihat download Python.
Mengekspor model transformer ke ONNX
Gunakan Hugging Face Optimum CLI untuk mengekspor model sentence-transformers/all-MiniLM-L6-v2 ke ONNX.
Untuk mengetahui informasi selengkapnya tentang cara mengekspor model dengan Optimum CLI, lihat
Mengekspor model ke ONNX dengan optimum.exporters.onnx.
Untuk mengekspor model, buka lingkungan command line dan ikuti langkah-langkah berikut:
Instal Optimum CLI:
pip install optimum[onnx]Mengekspor model. Argumen
--modelmenentukan ID model Hugging Face. Argumen--opsetmenentukan versi library ONNXRuntime, dan ditetapkan ke17untuk mempertahankan kompatibilitas dengan library ONNXRuntime yang didukung oleh BigQuery.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
File model diekspor ke direktori all-MiniLM-L6-v2 sebagai model.onnx.
Menerapkan kuantisasi pada model transformer
Gunakan Optimum CLI untuk menerapkan kuantisasi pada model transformer yang diekspor guna mengurangi ukuran model dan mempercepat inferensi. Untuk mengetahui informasi selengkapnya, lihat Kuantisasi.
Untuk menerapkan kuantisasi ke model, jalankan perintah berikut di command line:
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
File model yang dikuantisasi diekspor ke direktori all-MiniLM-L6-v2_quantized
sebagai model_quantized.onnx.
Mengonversi tokenizer ke ONNX
Untuk membuat embedding menggunakan model transformer dalam format ONNX, Anda biasanya menggunakan tokenizer untuk menghasilkan dua input ke model, input_ids dan attention_mask.
Untuk menghasilkan input ini, konversi tokenizer untuk model
sentence-transformers/all-MiniLM-L6-v2 ke format ONNX menggunakan
library onnxruntime-extensions. Setelah mengonversi tokenizer, Anda dapat melakukan tokenisasi
langsung pada input teks mentah untuk menghasilkan prediksi ONNX.
Untuk mengonversi tokenizer, ikuti langkah-langkah berikut di command line:
Instal Optimum CLI:
pip install optimum[onnx]Dengan menggunakan editor teks pilihan Anda, buat file bernama
convert-tokenizer.py. Contoh berikut menggunakan editor teks nano:nano convert-tokenizer.pySalin dan tempel skrip Python berikut ke dalam file
convert-tokenizer.py:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())Simpan file
convert-tokenizer.py.Jalankan skrip Python untuk mengonversi tokenizer:
python convert-tokenizer.py
Tokenizer yang dikonversi diekspor ke direktori all-MiniLM-L6-v2_quantized
sebagai tokenizer.onnx.
Mengupload file model yang dikonversi ke Cloud Storage
Setelah Anda mengonversi model transformer dan tokenizer, lakukan langkah-langkah berikut:
- Buat bucket Cloud Storage untuk menyimpan file yang dikonversi.
- Upload file model transformer dan tokenizer yang telah dikonversi ke bucket Cloud Storage Anda.
Membuat set data
Buat set data BigQuery untuk menyimpan model ML Anda.Konsol
Di konsol Google Cloud , buka halaman BigQuery.
Di panel Explorer, klik nama project Anda.
Klik View actions > Create dataset.
Di halaman Create dataset, lakukan hal berikut:
Untuk Dataset ID, masukkan
bqml_tutorial.Untuk Location type, pilih Multi-region, lalu pilih US.
Jangan ubah setelan default yang tersisa, lalu klik Create dataset.
bq
Untuk membuat set data baru, gunakan
perintah bq mk --dataset.
Buat set data bernama
bqml_tutorialdengan lokasi data ditetapkan keUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Pastikan set data telah dibuat:
bq ls
API
Panggil metode datasets.insert dengan resource set data yang ditentukan.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Mengimpor model ONNX ke BigQuery
Impor model tokenizer yang dikonversi dan model sentence transformer sebagai model BigQuery ML.
Pilih salah satu opsi berikut:
Konsol
Di konsol Google Cloud , buka BigQuery Studio.
Di editor kueri, jalankan pernyataan
CREATE MODELberikut untuk membuat modeltokenizer.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
Ganti
TOKENIZER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTOKENIZER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Setelah operasi selesai, Anda akan melihat pesan yang mirip dengan berikut:
Successfully created model named tokenizerdi panel Query results.Klik Go to model untuk membuka panel Details.
Tinjau bagian Kolom Fitur untuk melihat input model dan Kolom Label untuk melihat output model.
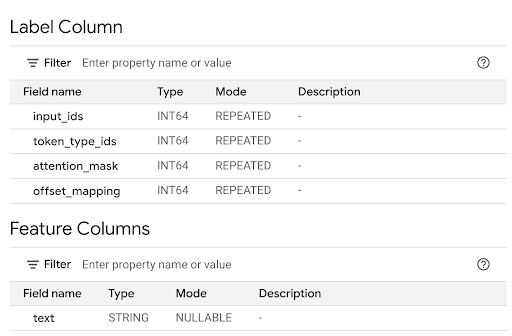
Di editor kueri, jalankan pernyataan
CREATE MODELberikut untuk membuat modelall-MiniLM-L6-v2.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
Ganti
TRANSFORMER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTRANSFORMER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Setelah operasi selesai, Anda akan melihat pesan yang mirip dengan berikut:
Successfully created model named all-MiniLM-L6-v2di panel Query results.Klik Go to model untuk membuka panel Details.
Tinjau bagian Kolom Fitur untuk melihat input model dan Kolom Label untuk melihat output model.
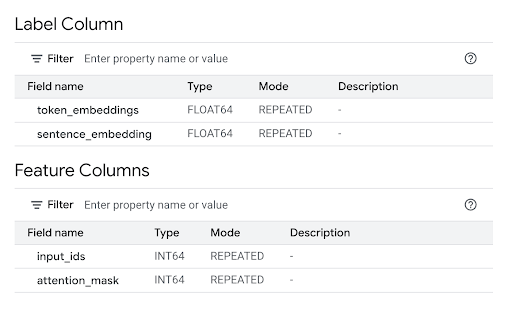
bq
Gunakan perintah query alat command line bq
untuk menjalankan pernyataan CREATE MODEL.
Pada command line, jalankan perintah berikut untuk membuat model
tokenizer.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"Ganti
TOKENIZER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTOKENIZER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Setelah operasi selesai, Anda akan melihat pesan yang mirip dengan berikut:
Successfully created model named tokenizer.Pada command line, jalankan perintah berikut untuk membuat model
all-MiniLM-L6-v2.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"Ganti
TRANSFORMER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTRANSFORMER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Setelah operasi selesai, Anda akan melihat pesan yang mirip dengan berikut:
Successfully created model named all-MiniLM-L6-v2.Setelah mengimpor model, verifikasi bahwa model muncul di set data.
bq ls -m bqml_tutorial
Outputnya mirip dengan hal berikut ini:
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
Gunakan metode jobs.insert
untuk mengimpor model. Isi parameter query dari
resource QueryRequest
dalam isi permintaan dengan pernyataan CREATE MODEL.
Gunakan nilai parameter
queryberikut untuk membuat modeltokenizer.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }Ganti kode berikut:
PROJECT_IDdengan ID project Anda.TOKENIZER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTOKENIZER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.
Gunakan nilai parameter
queryberikut untuk membuat modelall-MiniLM-L6-v2.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }Ganti kode berikut:
PROJECT_IDdengan ID project Anda.TRANSFORMER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTRANSFORMER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
BigQuery DataFrames
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Impor model tokenizer dan sentence transformer menggunakan objek
ONNXModel.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
Ganti kode berikut:
PROJECT_IDdengan ID project Anda.TOKENIZER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTOKENIZER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.TRANSFORMER_BUCKET_PATHdengan jalur ke model yang Anda upload ke Cloud Storage. Jika Anda menggunakan model sampel, gantiTRANSFORMER_BUCKET_PATHdengan nilai berikut:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
Membuat embedding dengan model ONNX yang diimpor
Gunakan model tokenizer dan sentence transformer yang diimpor untuk membuat embedding berdasarkan data dari set data publik.bigquery-public-data.imdb.reviews
Pilih salah satu opsi berikut:
Konsol
Gunakan
fungsi ML.PREDICT
untuk membuat embedding dengan model.
Kueri menggunakan panggilan ML.PREDICT bertingkat, untuk memproses teks mentah secara langsung
melalui tokenizer dan model embedding, sebagai berikut:
- Tokenisasi (kueri dalam): panggilan
ML.PREDICTdalam menggunakan modelbqml_tutorial.tokenizer. Kueri ini mengambil kolomtitledari set data publikbigquery-public-data.imdb.reviewssebagai inputtext-nya. Modeltokenizermengonversi string teks mentah menjadi input token numerik yang diperlukan model utama, termasuk inputinput_idsdanattention_mask. - Pembuatan embedding (kueri luar): panggilan
ML.PREDICTluar menggunakan modelbqml_tutorial.all-MiniLM-L6-v2. Kueri mengambil kolominput_idsdanattention_maskdari output kueri dalam sebagai inputnya.
Pernyataan SELECT mengambil kolom sentence_embedding, yang merupakan array nilai FLOAT yang merepresentasikan sematan semantik teks.
Di konsol Google Cloud , buka BigQuery Studio.
Di editor kueri, jalankan kueri berikut.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
Hasilnya mirip dengan berikut ini:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
Gunakan perintah query alat command line bq
untuk menjalankan kueri. Kueri menggunakan
fungsi ML.PREDICT
untuk membuat embedding dengan model.
Kueri menggunakan panggilan ML.PREDICT bertingkat, untuk memproses teks mentah secara langsung
melalui tokenizer dan model embedding, sebagai berikut:
- Tokenisasi (kueri dalam): panggilan
ML.PREDICTdalam menggunakan modelbqml_tutorial.tokenizer. Kueri ini mengambil kolomtitledari set data publikbigquery-public-data.imdb.reviewssebagai inputtext-nya. Modeltokenizermengonversi string teks mentah menjadi input token numerik yang diperlukan model utama, termasuk inputinput_idsdanattention_mask. - Pembuatan embedding (kueri luar): panggilan
ML.PREDICTluar menggunakan modelbqml_tutorial.all-MiniLM-L6-v2. Kueri mengambil kolominput_idsdanattention_maskdari output kueri dalam sebagai inputnya.
Pernyataan SELECT mengambil kolom sentence_embedding, yang merupakan array nilai FLOAT yang merepresentasikan sematan semantik teks.
Di command line, jalankan perintah berikut untuk menjalankan kueri.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
Hasilnya mirip dengan berikut ini:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
BigQuery DataFrames
Sebelum mencoba contoh ini, ikuti petunjuk penyiapan BigQuery DataFrames di Panduan memulai BigQuery menggunakan BigQuery DataFrames. Untuk mengetahui informasi selengkapnya, lihat dokumentasi referensi BigQuery DataFrames.
Untuk melakukan autentikasi ke BigQuery, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan ADC untuk lingkungan pengembangan lokal.
Gunakan metode predict
untuk membuat embedding menggunakan model ONNX.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
predictions.peek(5)
Outputnya mirip dengan hal berikut ini:
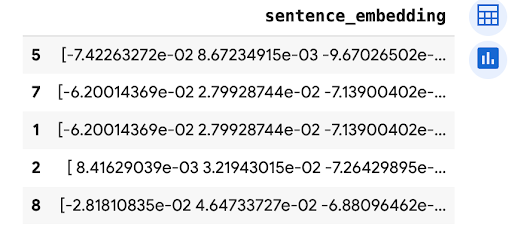
Pembersihan
Agar tidak perlu membayar biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam tutorial ini, hapus project yang berisi resource tersebut, atau simpan project dan hapus setiap resource.
Menghapus project
Konsol
- Di Konsol Google Cloud , buka halaman Manage resources.
- Pada daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
gcloud
Menghapus Google Cloud project:
gcloud projects delete PROJECT_ID
Menghapus resource satu per satu
Atau, untuk menghapus setiap resource yang digunakan dalam tutorial ini, lakukan langkah-langkah berikut:
Opsional: Hapus set data.
Langkah berikutnya
- Pelajari cara menggunakan embedding teks untuk penelusuran semantik dan retrieval-augmented generation (RAG).
- Untuk mengetahui informasi selengkapnya tentang cara mengonversi model transformer ke ONNX, lihat Mengekspor model ke ONNX dengan
optimum.exporters.onnx. - Untuk mengetahui informasi selengkapnya tentang cara mengimpor model ONNX, lihat
Pernyataan
CREATE MODELuntuk model ONNX. - Untuk mengetahui informasi selengkapnya tentang cara melakukan prediksi, lihat
Fungsi
ML.PREDICT. - Untuk ringkasan BigQuery ML, lihat Pengantar BigQuery ML.
- Untuk mulai menggunakan BigQuery ML, lihat Membuat model machine learning di BigQuery ML.