
Ce tutoriel vous explique comment exporter un modèle Transformer au format Open Neural Network Exchange (ONNX), importer le modèle ONNX dans un ensemble de données BigQuery, puis l'utiliser pour générer des embeddings à partir d'une requête SQL.
Ce tutoriel utilise le modèle sentence-transformers/all-MiniLM-L6-v2.
Ce modèle de transformateur de phrases est connu pour ses performances rapides et efficaces en matière de génération d'embeddings de phrases. L'embedding de phrases permet d'effectuer des tâches telles que la recherche sémantique, le clustering et la similarité de phrases en capturant la signification sous-jacente du texte.
ONNX fournit un format uniforme conçu pour représenter tous les frameworks de machine learning (ML). La compatibilité de BigQuery ML avec ONNX vous permet d'effectuer les opérations suivantes :
- Entraîner un modèle à l'aide du framework de votre choix
- Convertir le modèle au format ONNX
- Importer le modèle ONNX dans BigQuery et effectuer des prédictions à l'aide de BigQuery ML
Objectifs
- Utilisez l'interface de ligne de commande Hugging Face Optimum pour exporter le modèle
sentence-transformers/all-MiniLM-L6-v2vers ONNX. - Utilisez l'instruction
CREATE MODELpour importer le modèle ONNX dans BigQuery. - Utilisez la fonction
ML.PREDICTpour générer des embeddings avec le modèle ONNX importé.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
Pour obtenir une estimation des coûts en fonction de votre utilisation prévue, utilisez le simulateur de coût.
Une fois que vous avez terminé les tâches décrites dans ce document, supprimez les ressources que vous avez créées pour éviter que des frais vous soient facturés. Pour en savoir plus, consultez la section Effectuer un nettoyage.
Avant de commencer
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud .
Activez les API BigQuery et Cloud Storage.
Rôles requis pour activer les API
Pour activer les API, vous avez besoin du rôle IAM Administrateur Service Usage (
roles/serviceusage.serviceUsageAdmin), qui contient l'autorisationserviceusage.services.enable. Découvrez comment attribuer des rôles.- Assurez-vous de disposer des autorisations nécessaires pour effectuer les tâches décrites dans ce document.
Rôles requis
Si vous créez un projet, vous en êtes le propriétaire et vous disposez de toutes les autorisations IAM (Identity and Access Management) requises pour suivre ce tutoriel.
Si vous utilisez un projet existant, procédez comme suit.
Assurez-vous de disposer du ou des rôles suivants sur le projet :
- Administrateur BigQuery Studio (
roles/bigquery.studioAdmin) - Créateur d'objets Storage (
roles/storage.objectCreator)
Vérifier les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
-
Dans la colonne Compte principal, recherchez toutes les lignes qui vous identifient ou identifient un groupe dont vous faites partie. Pour savoir à quels groupes vous appartenez, contactez votre administrateur.
- Pour toutes les lignes qui vous spécifient ou vous incluent, consultez la colonne Rôle pour vous assurer que la liste inclut les rôles requis.
Attribuer les rôles
-
Dans la console Google Cloud , accédez à la page IAM.
Accéder à IAM - Sélectionnez le projet.
- Cliquez sur Accorder l'accès.
-
Dans le champ Nouveaux comptes principaux, saisissez votre identifiant utilisateur. Il s'agit généralement de l'adresse e-mail d'un compte Google.
- Cliquez sur Sélectionner un rôle, puis recherchez le rôle.
- Pour attribuer des rôles supplémentaires, cliquez sur Ajouter un autre rôle et ajoutez tous les rôles supplémentaires.
- Cliquez sur Enregistrer.
Pour en savoir plus sur les autorisations IAM dans BigQuery, consultez Autorisations IAM.
Convertir les fichiers de modèle Transformer au format ONNX
Vous pouvez également suivre les étapes de cette section pour convertir manuellement le modèle sentence-transformers/all-MiniLM-L6-v2 et le tokenizer au format ONNX.
Sinon, vous pouvez utiliser des exemples de fichiers déjà convertis à partir du bucket Cloud Storage public gs://cloud-samples-data.
Si vous choisissez de convertir manuellement les fichiers, vous devez disposer d'un environnement de ligne de commande local sur lequel Python est installé. Pour en savoir plus sur l'installation de Python, consultez Téléchargements Python.
Exporter le modèle Transformer vers ONNX
Utilisez l'interface de ligne de commande Hugging Face Optimum pour exporter le modèle sentence-transformers/all-MiniLM-L6-v2 vers ONNX.
Pour en savoir plus sur l'exportation de modèles avec la CLI Optimum, consultez Exporter un modèle au format ONNX avec optimum.exporters.onnx.
Pour exporter le modèle, ouvrez un environnement de ligne de commande et procédez comme suit :
Installez la CLI Optimum :
pip install optimum[onnx]Exporter le modèle L'argument
--modelspécifie l'ID du modèle Hugging Face. L'argument--opsetspécifie la version de la bibliothèque ONNXRuntime et est défini sur17pour maintenir la compatibilité avec la bibliothèque ONNXRuntime compatible avec BigQuery.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
Le fichier de modèle est exporté vers le répertoire all-MiniLM-L6-v2 sous le nom model.onnx.
Appliquer la quantification au modèle Transformer
Utilisez la CLI Optimum pour appliquer la quantification au modèle Transformer exporté afin de réduire la taille du modèle et d'accélérer l'inférence. Pour en savoir plus, consultez Quantification.
Pour appliquer la quantification au modèle, exécutez la commande suivante sur la ligne de commande :
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
Le fichier de modèle quantifié est exporté dans le répertoire all-MiniLM-L6-v2_quantized sous le nom model_quantized.onnx.
Convertir le tokenizer au format ONNX
Pour générer des embeddings à l'aide d'un modèle Transformer au format ONNX, vous utilisez généralement un tokeniseur pour produire deux entrées pour le modèle, input_ids et attention_mask.
Pour générer ces entrées, convertissez le tokenizer du modèle sentence-transformers/all-MiniLM-L6-v2 au format ONNX à l'aide de la bibliothèque onnxruntime-extensions. Une fois le tokenizer converti, vous pouvez effectuer la tokenisation directement sur les entrées de texte brut pour générer des prédictions ONNX.
Pour convertir le tokenizer, procédez comme suit sur la ligne de commande :
Installez la CLI Optimum :
pip install optimum[onnx]À l'aide de l'éditeur de texte de votre choix, créez un fichier nommé
convert-tokenizer.py. L'exemple suivant utilise l'éditeur de texte nano :nano convert-tokenizer.pyCopiez et collez le script Python suivant dans le fichier
convert-tokenizer.py:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())Enregistrez le fichier
convert-tokenizer.py.Exécutez le script Python pour convertir le tokenizer :
python convert-tokenizer.py
Le tokenizer converti est exporté vers le répertoire all-MiniLM-L6-v2_quantized sous le nom tokenizer.onnx.
Importer les fichiers de modèle convertis dans Cloud Storage
Une fois le modèle Transformer et le tokenizer convertis, procédez comme suit :
- Créez un bucket Cloud Storage pour stocker les fichiers convertis.
- Importez les fichiers du modèle Transformer converti et du tokenizer dans votre bucket Cloud Storage.
Créer un ensemble de données
Créez un ensemble de données BigQuery pour stocker votre modèle de ML.Console
Dans la console Google Cloud , accédez à la page BigQuery.
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis États-Unis.
Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
bq
Pour créer un ensemble de données, utilisez la commande bq mk --dataset.
Créez un ensemble de données nommé
bqml_tutorialet définissez l'emplacement des données surUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Vérifiez que l'ensemble de données a été créé :
bq ls
API
Appelez la méthode datasets.insert avec une ressource d'ensemble de données définie.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Importer les modèles ONNX dans BigQuery
Importez les modèles de tokenizer et de sentence transformer convertis en tant que modèles BigQuery ML.
Sélectionnez l'une des options suivantes :
Console
Dans la console Google Cloud , ouvrez BigQuery Studio.
Dans l'éditeur de requête, exécutez l'instruction
CREATE MODELsuivante pour créer le modèletokenizer.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
Remplacez
TOKENIZER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezTOKENIZER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Une fois l'opération terminée, un message semblable à celui-ci s'affiche :
Successfully created model named tokenizerdans le volet Résultats de la requête.Cliquez sur Accéder au modèle pour ouvrir le volet Détails.
Consultez la section Colonnes de caractéristiques pour afficher les entrées du modèle et la colonne "Libellé" pour afficher les sorties du modèle.
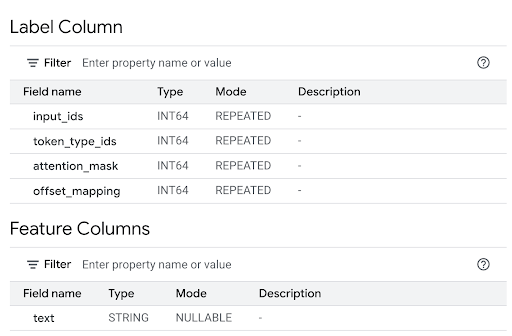
Dans l'éditeur de requête, exécutez l'instruction
CREATE MODELsuivante pour créer le modèleall-MiniLM-L6-v2.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
Remplacez
TRANSFORMER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezTRANSFORMER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Une fois l'opération terminée, un message semblable à celui-ci s'affiche :
Successfully created model named all-MiniLM-L6-v2dans le volet Résultats de la requête.Cliquez sur Accéder au modèle pour ouvrir le volet Détails.
Consultez la section Colonnes de caractéristiques pour afficher les entrées du modèle et la colonne "Libellé" pour afficher les sorties du modèle.
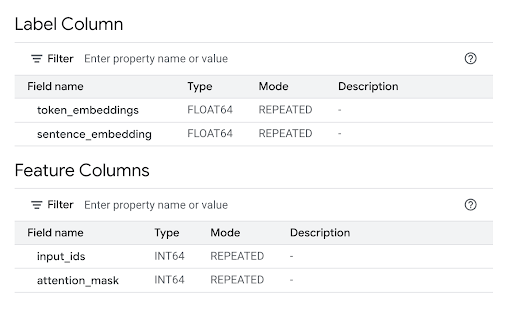
bq
Utilisez la commande query de l'outil de ligne de commande bq pour exécuter l'instruction CREATE MODEL.
Dans la ligne de commande, exécutez la commande suivante pour créer le modèle
tokenizer.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"Remplacez
TOKENIZER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezTOKENIZER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Une fois l'opération terminée, un message semblable à celui-ci s'affiche :
Successfully created model named tokenizer.Dans la ligne de commande, exécutez la commande suivante pour créer le modèle
all-MiniLM-L6-v2.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"Remplacez
TRANSFORMER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezTRANSFORMER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Une fois l'opération terminée, un message semblable à celui-ci s'affiche :
Successfully created model named all-MiniLM-L6-v2.Une fois les modèles importés, vérifiez qu'ils apparaissent dans l'ensemble de données.
bq ls -m bqml_tutorial
Le résultat ressemble à ce qui suit :
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
Utilisez la méthode jobs.insert pour importer les modèles. Renseignez le paramètre query de la ressource QueryRequest dans le corps de la requête avec l'instruction CREATE MODEL.
Utilisez la valeur de paramètre
querysuivante pour créer le modèletokenizer.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }Remplacez les éléments suivants :
PROJECT_IDpar l'ID de votre projet.TOKENIZER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez l'exemple de modèle, remplacezTOKENIZER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.
Utilisez la valeur de paramètre
querysuivante pour créer le modèleall-MiniLM-L6-v2.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }Remplacez les éléments suivants :
PROJECT_IDpar l'ID de votre projet.TRANSFORMER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezTRANSFORMER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Importez les modèles de tokenizer et de sentence transformer à l'aide de l'objet ONNXModel.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
Remplacez les éléments suivants :
PROJECT_IDpar l'ID de votre projet.TOKENIZER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez l'exemple de modèle, remplacezTOKENIZER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.TRANSFORMER_BUCKET_PATHpar le chemin d'accès au modèle que vous avez importé dans Cloud Storage. Si vous utilisez le modèle d'exemple, remplacezTRANSFORMER_BUCKET_PATHpar la valeur suivante :gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
Générer des embeddings avec les modèles ONNX importés
Utilisez le tokenizer importé et les modèles de sentence transformer pour générer des embeddings basés sur les données de l'ensemble de données public bigquery-public-data.imdb.reviews.
Sélectionnez l'une des options suivantes :
Console
Utilisez la fonction ML.PREDICT pour générer des embeddings avec les modèles.
La requête utilise un appel ML.PREDICT imbriqué pour traiter le texte brut directement via le tokenizer et le modèle d'embedding, comme suit :
- Tokenization (requête intérieure) : l'appel
ML.PREDICTintérieur utilise le modèlebqml_tutorial.tokenizer. Il utilise la colonnetitlede l'ensemble de données publicbigquery-public-data.imdb.reviewscomme entréetext. Le modèletokenizerconvertit les chaînes de texte brut en entrées de jetons numériques requises par le modèle principal, y compris les entréesinput_idsetattention_mask. - Génération d'embeddings (requête externe) : l'appel
ML.PREDICTexterne utilise le modèlebqml_tutorial.all-MiniLM-L6-v2. La requête utilise les colonnesinput_idsetattention_maskde la sortie de la requête interne comme entrée.
L'instruction SELECT récupère la colonne sentence_embedding, qui est un tableau de valeurs FLOAT représentant l'intégration sémantique du texte.
Dans la console Google Cloud , ouvrez BigQuery Studio.
Dans l'éditeur de requête, exécutez la requête suivante.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
Le résultat ressemble à ce qui suit :
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
Utilisez la commande query de l'outil de ligne de commande bq pour exécuter une requête. La requête utilise la fonction ML.PREDICT pour générer des embeddings avec les modèles.
La requête utilise un appel ML.PREDICT imbriqué pour traiter le texte brut directement via le tokenizer et le modèle d'embedding, comme suit :
- Tokenization (requête intérieure) : l'appel
ML.PREDICTintérieur utilise le modèlebqml_tutorial.tokenizer. Il utilise la colonnetitlede l'ensemble de données publicbigquery-public-data.imdb.reviewscomme entréetext. Le modèletokenizerconvertit les chaînes de texte brut en entrées de jetons numériques requises par le modèle principal, y compris les entréesinput_idsetattention_mask. - Génération d'embeddings (requête externe) : l'appel
ML.PREDICTexterne utilise le modèlebqml_tutorial.all-MiniLM-L6-v2. La requête utilise les colonnesinput_idsetattention_maskde la sortie de la requête interne comme entrée.
L'instruction SELECT récupère la colonne sentence_embedding, qui est un tableau de valeurs FLOAT représentant l'intégration sémantique du texte.
Dans la ligne de commande, exécutez la commande suivante pour exécuter la requête.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
Le résultat ressemble à ce qui suit :
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
BigQuery DataFrames
Avant d'essayer cet exemple, suivez les instructions de configuration pour BigQuery DataFrames du guide de démarrage rapide de BigQuery DataFrames. Pour en savoir plus, consultez la documentation de référence sur BigQuery DataFrames.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer les ADC pour un environnement de développement local.
Utilisez la méthode predict pour générer des embeddings à l'aide des modèles ONNX.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
predictions.peek(5)
Le résultat ressemble à ce qui suit :
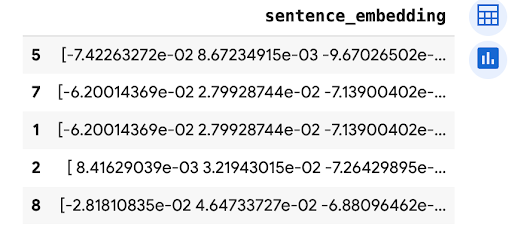
Effectuer un nettoyage
Pour éviter que les ressources utilisées lors de ce tutoriel soient facturées sur votre compte Google Cloud, supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
Console
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
gcloud
Supprimer un projet Google Cloud :
gcloud projects delete PROJECT_ID
Supprimer des ressources individuelles
Vous pouvez également supprimer les ressources individuelles utilisées dans ce tutoriel :
Étapes suivantes
- Découvrez comment utiliser les embeddings textuels pour la recherche sémantique et la génération augmentée par récupération (RAG).
- Pour en savoir plus sur la conversion de modèles Transformers au format ONNX, consultez Exporter un modèle au format ONNX avec
optimum.exporters.onnx. - Pour en savoir plus sur l'importation de modèles ONNX, consultez la page Instruction
CREATE MODELpour les modèles ONNX. - Pour en savoir plus sur l'exécution de prédictions, consultez la section Fonction
ML.PREDICT. - Pour obtenir plus d'informations sur BigQuery ML, consultez la page Présentation de BigQuery ML.
- Pour commencer à utiliser BigQuery ML, consultez la page Créer des modèles de machine learning dans BigQuery ML.