
En este instructivo, se muestra cómo exportar un modelo de Transformer al formato Open Neural Network Exchange (ONNX), importar el modelo ONNX a un conjunto de datos de BigQuery y, luego, usar el modelo para generar embeddings a partir de una consulta en SQL.
En este instructivo, se usa el modelo sentence-transformers/all-MiniLM-L6-v2.
Este modelo de transformador de oraciones es conocido por su rendimiento rápido y eficaz en la generación de incorporaciones de oraciones. La incorporación de oraciones permite realizar tareas como la búsqueda semántica, la agrupación en clústeres y la similitud de oraciones, ya que captura el significado subyacente del texto.
ONNX proporciona un formato uniforme diseñado para representar cualquier framework de aprendizaje automático (AA). La compatibilidad de BigQuery ML con ONNX te permite hacer lo siguiente:
- Entrenar un modelo con tu framework favorito.
- Convierte el modelo al formato de modelo ONNX.
- Importar el modelo ONNX a BigQuery y hacer predicciones con BigQuery ML.
Objetivos
- Usa la CLI de Hugging Face Optimum para exportar el modelo
sentence-transformers/all-MiniLM-L6-v2a ONNX. - Usa la sentencia
CREATE MODELpara importar el modelo ONNX a BigQuery. - Usa la función
ML.PREDICTpara generar embeddings con el modelo ONNX importado.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto,
usa la calculadora de precios.
Cuando completes las tareas que se describen en este documento, podrás borrar los recursos que creaste para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Antes de comenzar
- Accede a tu cuenta de Google Cloud . Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verifica que la facturación esté habilitada para tu proyecto de Google Cloud .
Habilita las APIs de BigQuery y Cloud Storage.
Roles necesarios para habilitar las APIs
Para habilitar APIs, necesitas el permiso
serviceusage.services.enable. Si creaste el proyecto, es probable que ya tengas este permiso a través del rol de propietario (roles/owner). De lo contrario, puedes obtener este permiso a través del rol de administrador de Service Usage (roles/serviceusage.serviceUsageAdmin). Obtén más información para otorgar roles.- Asegúrate de tener los permisos necesarios para realizar las tareas de este documento.
Roles obligatorios
Si creas un proyecto nuevo, serás el propietario y se te otorgarán todos los permisos de Identity and Access Management (IAM) necesarios para completar este instructivo.
Si usas un proyecto existente, haz lo siguiente.
Asegúrate de tener los siguientes roles en el proyecto:
- Administrador de BigQuery Studio (
roles/bigquery.studioAdmin) - Creador de objetos de almacenamiento (
roles/storage.objectCreator)
Verifica los roles
-
En la consola de Google Cloud , dirígete a la página IAM.
Ir a IAM - Selecciona el proyecto.
-
En la columna Principal, busca todas las filas que te identifiquen a ti o a un grupo en el que se te incluya. Para saber en qué grupos estás incluido, comunícate con tu administrador.
- Para todas las filas en las que se te especifique o se te incluya, verifica la columna Rol para ver si la lista de roles incluye los roles necesarios.
Otorga los roles
-
En la consola de Google Cloud , dirígete a la página IAM.
Ir a IAM - Selecciona el proyecto.
- Haz clic en Otorgar acceso.
-
En el campo Principales nuevas, ingresa tu identificador de usuario. Esta suele ser la dirección de correo electrónico de una Cuenta de Google.
- Haz clic en Seleccionar un rol y, luego, busca el rol.
- Para otorgar roles adicionales, haz clic en Agregar otro rol y agrega uno más.
- Haz clic en Guardar.
Para obtener más información sobre los permisos de IAM en BigQuery, consulta Permisos de IAM.
Convierte los archivos del modelo Transformer a ONNX
De manera opcional, puedes seguir los pasos de esta sección para convertir manualmente el modelo sentence-transformers/all-MiniLM-L6-v2 y el tokenizador a ONNX.
De lo contrario, puedes usar archivos de muestra del bucket público de Cloud Storage gs://cloud-samples-data que ya se convirtieron.
Si eliges convertir los archivos de forma manual, debes tener un entorno de línea de comandos local que tenga instalado Python. Para obtener más información sobre la instalación de Python, consulta Descargas de Python.
Exporta el modelo de Transformer a ONNX
Usa la CLI de Hugging Face Optimum para exportar el modelo sentence-transformers/all-MiniLM-L6-v2 a ONNX.
Para obtener más información sobre la exportación de modelos con la CLI de Optimum, consulta Exporta un modelo a ONNX con optimum.exporters.onnx.
Para exportar el modelo, abre un entorno de línea de comandos y sigue estos pasos:
Instala la CLI de Optimum:
pip install optimum[onnx]Exportación del modelo El argumento
--modelespecifica el ID del modelo de Hugging Face. El argumento--opsetespecifica la versión de la biblioteca de ONNX Runtime y se establece en17para mantener la compatibilidad con la biblioteca de ONNX Runtime que admite BigQuery.optimum-cli export onnx \ --model sentence-transformers/all-MiniLM-L6-v2 \ --task sentence-similarity \ --opset 17 all-MiniLM-L6-v2/
El archivo del modelo se exporta al directorio all-MiniLM-L6-v2 como model.onnx.
Aplica la cuantización al modelo Transformer
Usa la CLI de Optimum para aplicar la cuantización al modelo Transformer exportado y, así, reducir el tamaño del modelo y acelerar la inferencia. Para obtener más información, consulta Cuantización.
Para aplicar la cuantificación al modelo, ejecuta el siguiente comando en la línea de comandos:
optimum-cli onnxruntime quantize \
--onnx_model all-MiniLM-L6-v2/ \
--avx512_vnni -o all-MiniLM-L6-v2_quantized
El archivo del modelo cuantificado se exporta al directorio all-MiniLM-L6-v2_quantized como model_quantized.onnx.
Convierte el tokenizador a ONNX
Para generar embeddings con un modelo de transformador en formato ONNX, por lo general, se usa un tokenizador para producir dos entradas para el modelo, input_ids y attention_mask.
Para generar estas entradas, convierte el tokenizador del modelo sentence-transformers/all-MiniLM-L6-v2 al formato ONNX con la biblioteca onnxruntime-extensions. Después de convertir el tokenizador, puedes realizar la tokenización directamente en las entradas de texto sin procesar para generar predicciones de ONNX.
Para convertir el tokenizador, sigue estos pasos en la línea de comandos:
Instala la CLI de Optimum:
pip install optimum[onnx]Con el editor de texto que prefieras, crea un archivo llamado
convert-tokenizer.py. En el siguiente ejemplo, se usa el editor de texto nano:nano convert-tokenizer.pyCopia y pega la siguiente secuencia de comandos de Python en el archivo
convert-tokenizer.py:from onnxruntime_extensions import gen_processing_models # Load the Huggingface tokenizer tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") # Export the tokenizer to ONNX using gen_processing_models onnx_tokenizer_path = "tokenizer.onnx" # Generate the tokenizer ONNX model, and set the maximum token length. # Ensure 'max_length' is set to a value less than the model's maximum sequence length, failing to do so will result in error during inference. tokenizer_onnx_model = gen_processing_models(tokenizer, pre_kwargs={'max_length': 256})[0] # Modify the tokenizer ONNX model signature. # This is because certain tokenizers don't support batch inference. tokenizer_onnx_model.graph.input[0].type.tensor_type.shape.dim[0].dim_value = 1 # Save the tokenizer ONNX model with open(onnx_tokenizer_path, "wb") as f: f.write(tokenizer_onnx_model.SerializeToString())Guarda el archivo
convert-tokenizer.py.Ejecuta la secuencia de comandos de Python para convertir el tokenizador:
python convert-tokenizer.py
El tokenizador convertido se exporta al directorio all-MiniLM-L6-v2_quantized como tokenizer.onnx.
Sube los archivos del modelo convertido a Cloud Storage
Después de convertir el modelo Transformer y el tokenizador, haz lo siguiente:
- Crea un bucket de Cloud Storage para almacenar los archivos convertidos.
- Sube los archivos del modelo Transformer convertido y del tokenizador a tu bucket de Cloud Storage.
Crea un conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de AA.Console
En la consola de Google Cloud , ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haz clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, ingresa
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, luego, EE.UU..
Deja la configuración predeterminada restante como está y haz clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos nuevo, usa el comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos establecida enUS.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Confirma que se haya creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Importa los modelos de ONNX a BigQuery
Importa el tokenizador convertido y los modelos de transformador de oraciones como modelos de BigQuery ML.
Selecciona una de las siguientes opciones:
Console
En la consola de Google Cloud , abre BigQuery Studio.
En el editor de consultas, ejecuta la siguiente declaración de
CREATE MODELpara crear el modelotokenizer.CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')
Reemplaza
TOKENIZER_BUCKET_PATHpor la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTOKENIZER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Cuando se complete la operación, verás un mensaje similar al siguiente:
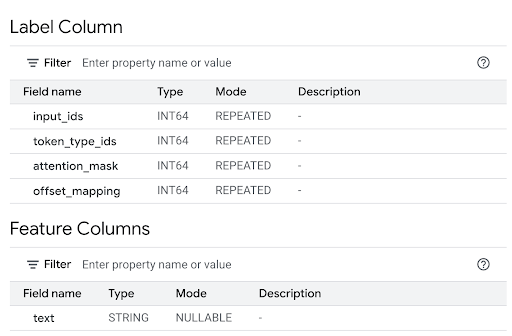
Successfully created model named tokenizeren el panel Resultados de la búsqueda.Haz clic en Ir al modelo para abrir el panel Detalles.
Revisa la sección Feature Columns para ver las entradas del modelo y la Label Column para ver los resultados del modelo.
En el editor de consultas, ejecuta la siguiente instrucción
CREATE MODELpara crear el modeloall-MiniLM-L6-v2.CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')
Reemplaza
TRANSFORMER_BUCKET_PATHpor la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTRANSFORMER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Cuando se complete la operación, verás un mensaje similar al siguiente:
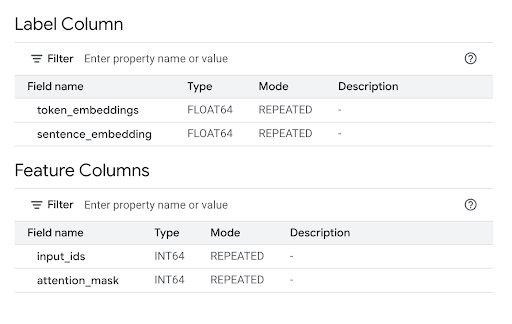
Successfully created model named all-MiniLM-L6-v2en el panel Resultados de la búsqueda.Haz clic en Ir al modelo para abrir el panel Detalles.
Revisa la sección Feature Columns para ver las entradas del modelo y la Label Column para ver los resultados del modelo.
bq
Usa el comando query de la herramienta de línea de comandos de bq para ejecutar la instrucción CREATE MODEL.
En la línea de comandos, ejecuta el siguiente comando para crear el modelo
tokenizer.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.tokenizer` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TOKENIZER_BUCKET_PATH')"Reemplaza
TOKENIZER_BUCKET_PATHpor la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTOKENIZER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.Cuando se complete la operación, verás un mensaje similar al siguiente:
Successfully created model named tokenizer.En la línea de comandos, ejecuta el siguiente comando para crear el modelo
all-MiniLM-L6-v2.bq query --use_legacy_sql=false \ "CREATE OR REPLACE MODEL `bqml_tutorial.all-MiniLM-L6-v2` OPTIONS (MODEL_TYPE='ONNX', MODEL_PATH='TRANSFORMER_BUCKET_PATH')"Reemplaza
TRANSFORMER_BUCKET_PATHpor la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTRANSFORMER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.Cuando se complete la operación, verás un mensaje similar al siguiente:
Successfully created model named all-MiniLM-L6-v2.Después de importar los modelos, verifica que aparezcan en el conjunto de datos.
bq ls -m bqml_tutorial
El resultado es similar a lo siguiente:
tableId Type ------------------------ tokenizer MODEL all-MiniLM-L6-v2 MODEL
API
Usa el método jobs.insert para importar los modelos. Propaga el parámetro query del recurso QueryRequest en el cuerpo de la solicitud con la instrucción CREATE MODEL.
Usa el siguiente valor del parámetro
querypara crear el modelotokenizer.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.tokenizer` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TOKENIZER_BUCKET_PATH')" }Reemplaza lo siguiente:
PROJECT_IDpor el ID del proyectoTOKENIZER_BUCKET_PATHcon la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTOKENIZER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.
Usa el siguiente valor del parámetro
querypara crear el modeloall-MiniLM-L6-v2.{ "query": "CREATE MODEL `PROJECT_ID :bqml_tutorial.all-MiniLM-L6-v2` OPTIONS(MODEL_TYPE='ONNX' MODEL_PATH='TRANSFORMER_BUCKET_PATH')" }Reemplaza lo siguiente:
PROJECT_IDpor el ID del proyectoTRANSFORMER_BUCKET_PATHcon la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTRANSFORMER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Importa los modelos de tokenizador y de transformación de oraciones con el objeto ONNXModel.
import bigframes from bigframes.ml.imported import ONNXModel bigframes.options.bigquery.project = PROJECT_ID bigframes.options.bigquery.location = "US" tokenizer = ONNXModel( model_path= "TOKENIZER_BUCKET_PATH" ) imported_onnx_model = ONNXModel( model_path="TRANSFORMER_BUCKET_PATH" )
Reemplaza lo siguiente:
PROJECT_IDpor el ID del proyectoTOKENIZER_BUCKET_PATHcon la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTOKENIZER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/tokenizer.onnx.TRANSFORMER_BUCKET_PATHcon la ruta de acceso al modelo que subiste a Cloud Storage. Si usas el modelo de muestra, reemplazaTRANSFORMER_BUCKET_PATHpor el siguiente valor:gs://cloud-samples-data/bigquery/ml/onnx/all-MiniLM-L6-v2/model_quantized.onnx.
Genera embeddings con los modelos ONNX importados
Usa el tokenizador importado y los modelos de Sentence Transformer para generar incorporaciones basadas en los datos del conjunto de datos públicos bigquery-public-data.imdb.reviews.
Selecciona una de las siguientes opciones:
Console
Usa la función ML.PREDICT para generar incorporaciones con los modelos.
La consulta usa una llamada ML.PREDICT anidada para procesar texto sin procesar directamente a través del tokenizador y el modelo de incorporación, de la siguiente manera:
- Tokenización (consulta interna): La llamada interna a
ML.PREDICTusa el modelobqml_tutorial.tokenizer. Toma la columnatitledel conjunto de datos públicosbigquery-public-data.imdb.reviewscomo su entradatext. El modelotokenizerconvierte las cadenas de texto sin procesar en las entradas de tokens numéricos que requiere el modelo principal, incluidas las entradasinput_idsyattention_mask. - Generación de embeddings (consulta externa): La llamada externa a
ML.PREDICTusa el modelobqml_tutorial.all-MiniLM-L6-v2. La consulta toma las columnasinput_idsyattention_maskdel resultado de la consulta interna como entrada.
La sentencia SELECT recupera la columna sentence_embedding, que es un array de valores FLOAT que representan la incorporación semántica del texto.
En la consola de Google Cloud , abre BigQuery Studio.
En el editor de consultas, ejecuta la siguiente consulta.
SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))
El resultado es similar al siguiente:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
bq
Usa el comando query de la herramienta de línea de comandos de bq para ejecutar una consulta. La consulta usa la función ML.PREDICT para generar incorporaciones con los modelos.
La consulta usa una llamada ML.PREDICT anidada para procesar texto sin procesar directamente a través del tokenizador y el modelo de incorporación, de la siguiente manera:
- Tokenización (consulta interna): La llamada interna a
ML.PREDICTusa el modelobqml_tutorial.tokenizer. Toma la columnatitledel conjunto de datos públicosbigquery-public-data.imdb.reviewscomo su entradatext. El modelotokenizerconvierte las cadenas de texto sin procesar en las entradas de tokens numéricos que requiere el modelo principal, incluidas las entradasinput_idsyattention_mask. - Generación de embeddings (consulta externa): La llamada externa a
ML.PREDICTusa el modelobqml_tutorial.all-MiniLM-L6-v2. La consulta toma las columnasinput_idsyattention_maskdel resultado de la consulta interna como entrada.
La sentencia SELECT recupera la columna sentence_embedding, que es un array de valores FLOAT que representan la incorporación semántica del texto.
En la línea de comandos, ejecuta el siguiente comando para ejecutar la consulta.
bq query --use_legacy_sql=false \ 'SELECT sentence_embedding FROM ML.PREDICT (MODEL `bqml_tutorial.all-MiniLM-L6-v2`, ( SELECT input_ids, attention_mask FROM ML.PREDICT(MODEL `bqml_tutorial.tokenizer`, ( SELECT title AS text FROM `bigquery-public-data.imdb.reviews` limit 10))))'
El resultado es similar al siguiente:
+-----------------------+ | sentence_embedding | +-----------------------+ | -0.02361682802438736 | | 0.02025664784014225 | | 0.005168713629245758 | | -0.026361213997006416 | | 0.0655381828546524 | | ... | +-----------------------+
Permite trabajar con BigQuery DataFrames.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de BigQuery DataFrames.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura ADC para un entorno de desarrollo local.
Usa el método predict para generar embeddings con los modelos ONNX.
import bigframes.pandas as bpd
df = bpd.read_gbq("bigquery-public-data.imdb.reviews", max_results=10)
df_pred = df.rename(columns={"title": "text"})
tokens = tokenizer.predict(df_pred)
predictions = imported_onnx_model.predict(tokens)
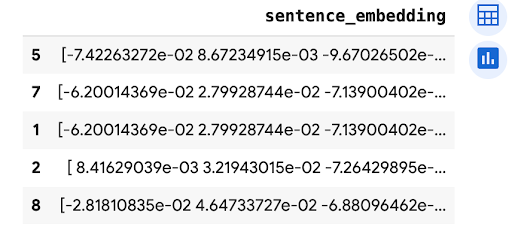
predictions.peek(5)
El resultado es similar a lo siguiente:
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
Console
- En la Google Cloud consola, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
gcloud
Borra un Google Cloud proyecto:
gcloud projects delete PROJECT_ID
Borra los recursos individuales
Como alternativa, para quitar los recursos individuales que se usan en este instructivo, haz lo siguiente:
¿Qué sigue?
- Aprende a usar embeddings de texto para la búsqueda semántica y la generación mejorada por recuperación (RAG).
- Para obtener más información sobre la conversión de modelos de transformadores a ONNX, consulta Exporta un modelo a ONNX con
optimum.exporters.onnx. - Para obtener más información sobre la importación de modelos ONNX, consulta la declaración
CREATE MODELpara modelos ONNX. - Para obtener más información sobre cómo realizar predicciones, consulta La función
ML.PREDICT. - Para obtener una descripción general de BigQuery ML, consulta Introducción a BigQuery ML.
- Para comenzar a usar BigQuery ML, consulta Crea modelos de aprendizaje automático en BigQuery ML.