
יצירת מערכי נתונים
במאמר הזה מוסבר איך ליצור מערכי נתונים שמאחסנים נתונים ב-BigQuery. מערכי נתונים הם קונטיינרים ברמה העליונה שמאפשרים לארגן ולשלוט בגישה לטבלאות ולתצוגות.
כדי ללמוד איך לעבוד עם סוגים אחרים של מערכי נתונים, אפשר לעיין במקורות המידע הבאים:
- לגבי מערכי נתונים חיצוניים של Spanner, אפשר לעיין במאמר בנושא יצירת מערכי נתונים חיצוניים של Spanner.
- לגבי מערכי נתונים מאוחדים של AWS Glue, אפשר לעיין במאמר בנושא יצירת מערכי נתונים מאוחדים של AWS Glue.
במאמר הרצת שאילתות על קבוצת נתונים ציבורית באמצעות מסוף Google Cloud יש הסבר איך להריץ שאילתות על טבלאות בקבוצת נתונים ציבורית.
מגבלות על מערכי נתונים
מערכי נתונים ב-BigQuery כפופים למגבלות הבאות:
- אפשר להגדיר את המיקום של מערך הנתונים רק בזמן היצירה. אחרי שיוצרים את מערך הנתונים, אי אפשר לשנות את המיקום שלו.
- כל הטבלאות שאליהן מתבצעת הפניה בשאילתה צריכות להיות מאוחסנות במערכי נתונים באותו מיקום.
מערכי נתונים חיצוניים לא תומכים בתפוגה של טבלאות, בעותקים משוכפלים, בשינוי נתונים לאורך זמן, בהשוואה (collation) של ברירת מחדל, במצב עיגול של ברירת מחדל או באפשרות להפעיל או להשבית שמות טבלאות שלא תלויים באותיות רישיות.
כשמעתיקים טבלה, מערכי הנתונים שמכילים את טבלת המקור ואת טבלת היעד צריכים להיות באותו מיקום.
שמות מערכי הנתונים צריכים להיות ייחודיים לכל פרויקט.
אם משנים את מודל החיוב על האחסון של מערך נתונים, צריך לחכות 14 ימים לפני שאפשר לשנות שוב את מודל החיוב על האחסון.
אי אפשר לרשום מערך נתונים לחיוב על אחסון פיזי אם יש לכם התחייבויות קיימות לשימוש במשבצות זמן בתשלום קבוע מדור קודם שנמצאות באותו אזור כמו מערך הנתונים.
לפני שמתחילים
להקצות תפקידים של ניהול זהויות והרשאות גישה (IAM) שנותנים למשתמשים את ההרשאות הדרושות לביצוע כל משימה במסמך הזה.
ההרשאות הנדרשות
כדי ליצור מערך נתונים, צריך את הרשאת bigquery.datasets.create ב-IAM.
כל אחד מהתפקידים המוגדרים מראש הבאים ב-IAM כולל את ההרשאות שדרושות ליצירת מערך נתונים:
roles/bigquery.dataEditorroles/bigquery.dataOwnerroles/bigquery.userroles/bigquery.admin
במאמר תפקידים והרשאות מוגדרים מראש יש מידע נוסף על תפקידי IAM ב-BigQuery.
יצירת מערכי נתונים
כשיוצרים מערך נתונים, בדרך כלל מציינים מיקום שבו הנתונים מאוחסנים. אם לא מציינים מיקום, המערכת משתמשת במיקום שמוגדר כברירת מחדל. מידע נוסף זמין במאמר בנושא ציון מיקומים.
כדי ליצור מערך נתונים:
המסוף
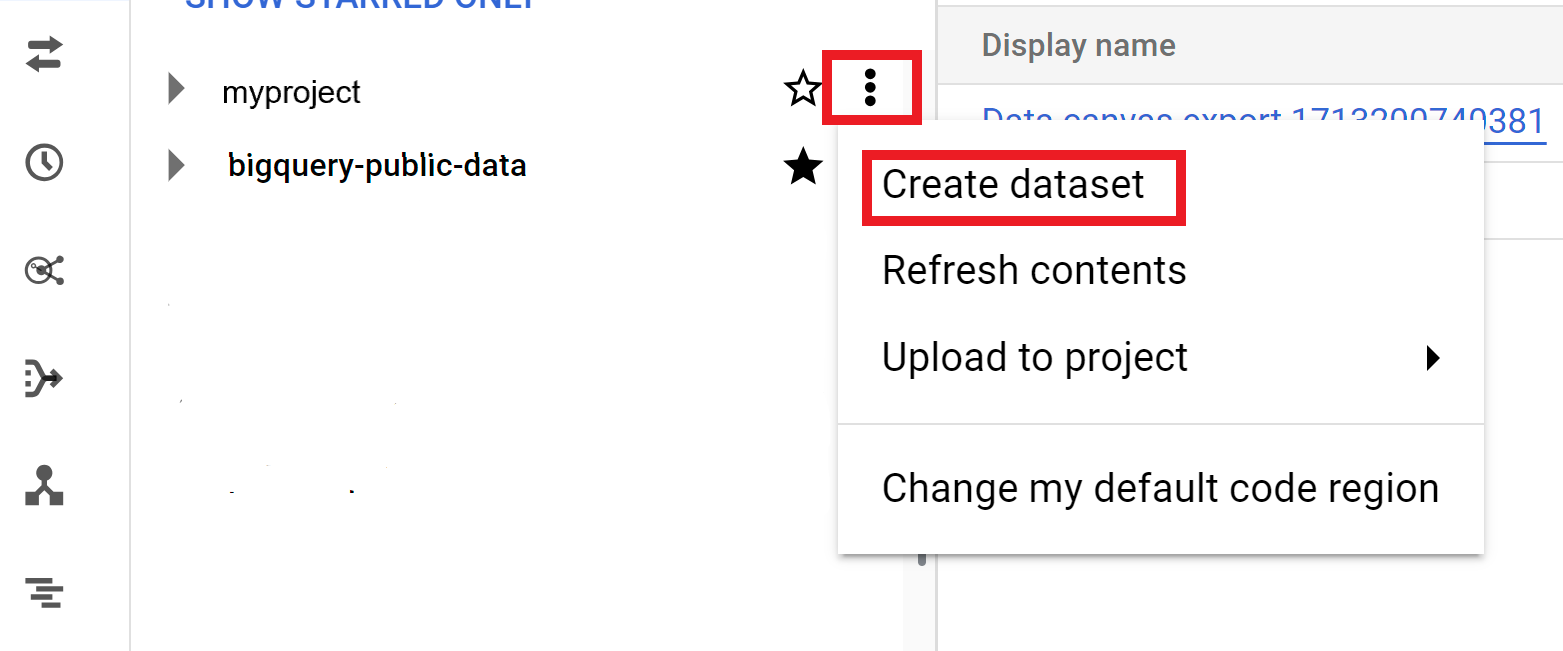
- פותחים את הדף BigQuery במסוף Google Cloud . לדף BigQuery
- בחלונית הימנית, לוחצים על כלי הניתוחים.
- בוחרים את הפרויקט שבו רוצים ליצור את מערך הנתונים.
- לוחצים על View actions (הצגת פעולות) ואז על Create dataset (יצירת מערך נתונים).
- בדף Create dataset:
- בשדה Dataset ID, מזינים שם ייחודי למערך הנתונים.
- בשדה Location type, בוחרים מיקום גיאוגרפי לקבוצת הנתונים. אחרי שיוצרים את מערך הנתונים, אי אפשר לשנות את המיקום.
- אופציונלי: בוחרים באפשרות קישור למערך נתונים חיצוני אם יוצרים מערך נתונים חיצוני.
- אם לא צריך להגדיר אפשרויות נוספות כמו תגים ותאריכי תפוגה של טבלאות, לוחצים על יצירת מערך נתונים. אחרת, מרחיבים את הקטע הבא כדי להגדיר את האפשרויות הנוספות של מערך הנתונים.
- אופציונלי: מרחיבים את הקטע תגים כדי להוסיף תגים למערך הנתונים.
- כדי להחיל תג קיים:
- לוחצים על החץ לתפריט הנפתח לצד Select scope (בחירת היקף) ובוחרים באפשרות Current scope (היקף נוכחי) – Select current organization (בחירת הארגון הנוכחי) או Select current project (בחירת הפרויקט הנוכחי).
- בשדות Key 1 ו-Value 1, בוחרים את הערכים המתאימים מהרשימות.
- כדי להזין תג חדש באופן ידני:
- לוחצים על החץ של התפריט הנפתח לצד בחירת היקף ובוחרים באפשרות הזנת מזהים באופן ידני > ארגון, פרויקט או תגים.
- אם יוצרים תג לפרויקט או לארגון, מזינים את
PROJECT_IDאו אתORGANIZATION_IDבתיבת הדו-שיח ולוחצים על שמירה. - בשדות Key 1 ו-Value 1, בוחרים את הערכים המתאימים מתוך הרשימות.
- כדי להוסיף עוד תגים לטבלה, לוחצים על הוספת תג ופועלים לפי השלבים הקודמים.
- אופציונלי: מרחיבים את הקטע אפשרויות מתקדמות כדי להגדיר אחת או יותר מהאפשרויות הבאות.
- כדי לשנות את האפשרות הצפנה לשימוש במפתח קריפטוגרפי משלכם באמצעות Cloud Key Management Service, בוחרים באפשרות מפתח Cloud KMS.
- כדי להשתמש בשמות טבלאות לא תלויי-רישיות, בוחרים באפשרות הפעלת שמות טבלאות לא תלויי-רישיות.
- כדי לשנות את הגדרת ברירת המחדל של אוסף הכללים (collation), בוחרים את סוג אוסף הכללים (collation) מהרשימה.
- כדי להגדיר תפוגה לטבלאות במערך הנתונים, בוחרים באפשרות הפעלת תפוגה של טבלאות ומציינים את גיל הטבלה המקסימלי כברירת מחדל בימים.
- כדי להגדיר מצב ברירת מחדל לעיגול, בוחרים את מצב העיגול מהרשימה.
- כדי להפעיל את מודל החיוב על אחסון, בוחרים את מודל החיוב מהרשימה.
- כדי להגדיר את חלון הזמן של נסיעה אחורה בזמן של מערך הנתונים, בוחרים את גודל החלון מהרשימה.
- לוחצים על יצירת מערך נתונים.
אפשרויות נוספות למערכי נתונים
אפשר גם ללחוץ על בחירת היקף כדי לחפש משאב או כדי לראות רשימה של המשאבים הנוכחיים.
כשמשנים את מודל החיוב של מערך נתונים, חולפות 24 שעות עד שהשינוי נכנס לתוקף.
אחרי שמשנים את מודל החיוב של אחסון נתונים, צריך לחכות 14 ימים לפני שאפשר לשנות אותו שוב.
SQL
משתמשים בהצהרה CREATE SCHEMA.
כדי ליצור מערך נתונים בפרויקט שאינו פרויקט ברירת המחדל, מוסיפים את מזהה הפרויקט למזהה מערך הנתונים בפורמט הבא:
PROJECT_ID.DATASET_ID.
במסוף Google Cloud , עוברים לדף BigQuery.
מזינים את ההצהרה הבאה בעורך השאילתות:
CREATE SCHEMA PROJECT_ID.DATASET_ID OPTIONS ( default_kms_key_name = 'KMS_KEY_NAME', default_partition_expiration_days = PARTITION_EXPIRATION, default_table_expiration_days = TABLE_EXPIRATION, description = 'DESCRIPTION', labels = [('KEY_1','VALUE_1'),('KEY_2','VALUE_2')], location = 'LOCATION', max_time_travel_hours = HOURS, storage_billing_model = BILLING_MODEL);
מחליפים את מה שכתוב בשדות הבאים:
-
PROJECT_ID: מזהה הפרויקט -
DATASET_ID: המזהה של מערך הנתונים שאתם יוצרים -
KMS_KEY_NAME: השם של מפתח ברירת המחדל של Cloud Key Management Service שמשמש להגנה על טבלאות חדשות שנוצרות במערך הנתונים הזה, אלא אם מסופק מפתח אחר בזמן היצירה. אי אפשר ליצור טבלה מוצפנת ב-Google במערך נתונים עם הפרמטר הזה. -
PARTITION_EXPIRATION: משך החיים שמוגדר כברירת מחדל למחיצות בטבלאות מחולקות חדשות (בימים). למועד התפוגה של המחיצה שמוגדר כברירת מחדל אין ערך מינימלי. מועד התפוגה מחושב לפי התאריך של המחיצה בתוספת הערך המספרי. כל מחיצה שנוצרת בטבלה מחולקת במערך הנתונים נמחקת אחריPARTITION_EXPIRATIONימים מתאריך המחיצה. אם מציינים את האפשרותtime_partitioning_expirationכשיוצרים או מעדכנים טבלה מחולקת, מועד התפוגה של המחיצה ברמת הטבלה קודם למועד התפוגה של המחיצה שמוגדר כברירת מחדל ברמת מערך הנתונים. -
TABLE_EXPIRATION: משך החיים שמוגדר כברירת מחדל (בימים) לטבלאות שנוצרות. הערך המינימלי הוא 0.042 ימים (שעה אחת). זמן התפוגה הוא הזמן הנוכחי בתוספת הערך השלם. כל טבלה שנוצרת במערך הנתונים נמחקת אחריTABLE_EXPIRATIONימים ממועד היצירה שלה. הערך הזה חל אם לא מגדירים זמן תפוגה לטבלה כשיוצרים את הטבלה. -
DESCRIPTION: תיאור של מערך הנתונים -
KEY_1:VALUE_1: זוג מפתח/ערך שרוצים להגדיר כתווית הראשונה במערך הנתונים הזה -
KEY_2:VALUE_2: זוג מפתח/ערך שרוצים להגדיר כתווית השנייה -
LOCATION: המיקום של מערך הנתונים. אחרי שיוצרים את מערך הנתונים, אי אפשר לשנות את המיקום שלו. -
HOURS: משך חלון הזמן של הנסיעה במערך הנתונים החדש, בשעות. הערך שלHOURSחייב להיות מספר שלם שהוא כפולה של 24 (48, 72, 96, 120, 144, 168) בין 48 (יומיים) ל-168 (7 ימים). אם לא מציינים את האפשרות הזו, ברירת המחדל היא 168 שעות. -
BILLING_MODEL: מגדיר את מודל החיוב של נפח האחסון של מערך הנתונים. מגדירים את הערך שלBILLING_MODELל-PHYSICALכדי להשתמש בבייטים פיזיים כשמחשבים את חיובים על נפח האחסון, או ל-LOGICALכדי להשתמש בבייטים לוגיים.LOGICALהוא ברירת המחדל.כשמשנים את מודל החיוב של מערך נתונים, חולפות 24 שעות עד שהשינוי נכנס לתוקף.
אחרי שמשנים את מודל החיוב של האחסון של מערך נתונים, צריך לחכות 14 ימים לפני שאפשר לשנות שוב את מודל החיוב של האחסון.
-
לוחצים על הפעלה.
מידע נוסף על הרצת שאילתות זמין במאמר הרצת שאילתה אינטראקטיבית.
BQ
כדי ליצור מערך נתונים חדש, משתמשים בפקודה bq mk עם הדגל --location. רשימה מלאה של הפרמטרים האפשריים זמינה במאמר בנושא הפקודה bq mk --dataset.
כדי ליצור מערך נתונים בפרויקט שאינו פרויקט ברירת המחדל, מוסיפים את מזהה הפרויקט לשם מערך הנתונים בפורמט הבא:
PROJECT_ID:DATASET_ID.
bq --location=LOCATION mk \ --dataset \ --default_kms_key=KMS_KEY_NAME \ --default_partition_expiration=PARTITION_EXPIRATION \ --default_table_expiration=TABLE_EXPIRATION \ --description="DESCRIPTION" \ --label=KEY_1:VALUE_1 \ --label=KEY_2:VALUE_2 \ --add_tags=KEY_3:VALUE_3[,...] \ --max_time_travel_hours=HOURS \ --storage_billing_model=BILLING_MODEL \ PROJECT_ID:DATASET_ID
מחליפים את מה שכתוב בשדות הבאים:
-
LOCATION: המיקום של מערך הנתונים. אחרי שיוצרים את מערך הנתונים, אי אפשר לשנות את המיקום. אפשר להגדיר ערך ברירת מחדל למיקום באמצעות הקובץ.bigqueryrc. -
KMS_KEY_NAME: השם של מפתח ברירת המחדל של Cloud Key Management Service שמשמש להגנה על טבלאות שנוצרו לאחרונה במערך הנתונים הזה, אלא אם סופק מפתח אחר בזמן היצירה. אי אפשר ליצור טבלה מוצפנת על ידי Google במערך נתונים עם הפרמטר הזה. -
PARTITION_EXPIRATION: משך החיים שמוגדר כברירת מחדל (בשניות) למחיצות בטבלאות מחולקות שנוצרו לאחרונה. לפג תוקף של מחיצת ברירת המחדל אין ערך מינימלי. זמן התפוגה מחושב לפי התאריך של המחיצה בתוספת הערך המספרי. כל מחיצה שנוצרה בטבלה מחולקת במערך הנתונים נמחקתPARTITION_EXPIRATIONשניות אחרי התאריך של המחיצה. אם מספקים את הדגל--time_partitioning_expirationכשיוצרים או מעדכנים טבלה מחולקת למחיצות, תאריך התפוגה של המחיצות ברמת הטבלה מקבל עדיפות על פני תאריך התפוגה של המחיצות שמוגדר כברירת מחדל ברמת מערך הנתונים. -
TABLE_EXPIRATION: משך החיים שמוגדר כברירת מחדל (בשניות) לטבלאות שנוצרו לאחרונה. הערך המינימלי הוא 3,600 שניות (שעה אחת). מועד התפוגה הוא השעה הנוכחית בתוספת הערך השלם. כל טבלה שנוצרת במערך הנתונים נמחקתTABLE_EXPIRATIONשניות אחרי שנוצרה. הערך הזה יחול אם לא תגדירו תאריך תפוגה לטבלה כשתצרו את הטבלה. -
DESCRIPTION: תיאור של מערך הנתונים -
KEY_1:VALUE_1: צמד מפתח/ערך שרוצים להגדיר כתווית הראשונה במערך הנתונים הזה, ו-KEY_2:VALUE_2הוא צמד מפתח/ערך שרוצים להגדיר כתווית השנייה. -
KEY_3:VALUE_3: צמד מפתח/ערך שרוצים להגדיר כתג במערך הנתונים. מוסיפים כמה תגים מתחת לאותו דגל, עם פסיקים בין צמדי מפתח:ערך. -
HOURS: משך הזמן בשעות של חלון הנסיעה בזמן למערך הנתונים החדש. הערךHOURSצריך להיות מספר שלם שהוא כפולה של 24 (48, 72, 96, 120, 144, 168) בין 48 (יומיים) ל-168 (7 ימים). ברירת המחדל היא 168 שעות אם האפשרות הזו לא מצוינת.
BILLING_MODEL: מגדיר את מודל החיוב על אחסון של מערך הנתונים. כדי להשתמש בבייטים פיזיים כשמחשבים את עלויות האחסון, צריך להגדיר את הערך שלBILLING_MODELל-PHYSICAL. כדי להשתמש בבייטים לוגיים, צריך להגדיר את הערך ל-LOGICAL. ברירת המחדל היאLOGICAL.כשמשנים את מודל החיוב של מערך נתונים, חולפות 24 שעות עד שהשינוי נכנס לתוקף.
אחרי שמשנים את מודל החיוב של האחסון של מערך נתונים, צריך לחכות 14 ימים לפני שאפשר לשנות שוב את מודל החיוב של האחסון.
PROJECT_ID: מזהה הפרויקט.
DATASET_IDהוא המזהה של מערך הנתונים שאתם יוצרים.
לדוגמה, הפקודה הבאה יוצרת מערך נתונים בשם mydataset עם מיקום נתונים שמוגדר ל-US, תפוגה של טבלה שמוגדרת כברירת מחדל ל-3,600 שניות (שעה אחת) ותיאור של This is my dataset. במקום להשתמש בדגל --dataset, הפקודה משתמשת בקיצור הדרך -d. אם לא מציינים את -d ואת --dataset, הפקודה
יוצרת מערך נתונים כברירת מחדל.
bq --location=US mk -d \ --default_table_expiration 3600 \ --description "This is my dataset." \ mydataset
כדי לוודא שמערך הנתונים נוצר, מזינים את הפקודה bq ls. בנוסף, אפשר ליצור טבלה כשיוצרים מערך נתונים חדש באמצעות הפורמט הבא: bq mk -t dataset.table.
מידע נוסף על יצירת טבלאות זמין במאמר יצירת טבלה.
Terraform
משתמשים במשאב google_bigquery_dataset.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
יצירת מערך נתונים
בדוגמה הבאה נוצר מערך נתונים בשם mydataset:
כשיוצרים מערך נתונים באמצעות google_bigquery_dataset resource, המערכת מעניקה אוטומטית גישה למערך הנתונים לכל החשבונות שמשתייכים לתפקידים בסיסיים ברמת הפרויקט. אם מריצים את terraform show command אחרי שיוצרים את מערך הנתונים, access block של מערך הנתונים ייראה בערך כך:
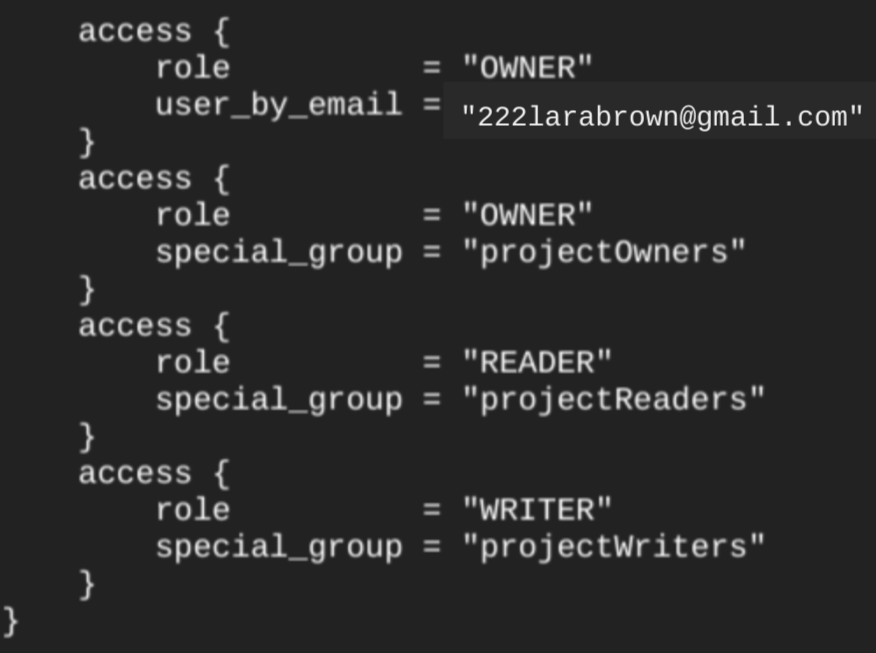
כדי להעניק גישה למערך הנתונים, מומלץ להשתמש באחד מgoogle_bigquery_iamמשאבי BigQuery, כמו בדוגמה הבאה, אלא אם אתם מתכננים ליצור אובייקטים מורשים, כמו תצוגות מורשות, בתוך מערך הנתונים. במקרה כזה, צריך להשתמש במשאב google_bigquery_dataset_access. בדוגמה הזו מוסבר איך עושים את זה.
יצירת מערך נתונים והענקת גישה אליו
בדוגמה הבאה נוצר מערך נתונים בשם mydataset, ואז נעשה שימוש במשאב google_bigquery_dataset_iam_policy כדי להעניק גישה אליו.
יצירת מערך נתונים עם מפתח הצפנה בניהול הלקוח
בדוגמה הבאה נוצר מערך נתונים בשם mydataset, ונעשה שימוש במשאבים google_kms_crypto_key ו-google_kms_key_ring כדי לציין מפתח של Cloud Key Management Service למערך הנתונים. לפני שמריצים את הדוגמה הזו, צריך להפעיל את Cloud Key Management Service API.
כדי להחיל את הגדרות Terraform בפרויקט ב- Google Cloud , מבצעים את השלבים בקטעים הבאים.
הכנת Cloud Shell
- מפעילים את Cloud Shell.
-
מגדירים את פרויקט ברירת המחדל שבו רוצים להחיל את ההגדרות של Terraform. Google Cloud
תצטרכו להריץ את הפקודה הזו רק פעם אחת לכל פרויקט, ותוכלו לעשות זאת בכל ספרייה.
export GOOGLE_CLOUD_PROJECT=PROJECT_ID
אם תגדירו ערכים ספציפיים בקובץ התצורה של Terraform, הם יבטלו את ערכי ברירת המחדל של משתני הסביבה.
הכנת הספרייה
לכל קובץ תצורה של Terraform צריכה להיות ספרייה משלו (שנקראת גם מודול ברמה הבסיסית).
-
יוצרים ספרייה חדשה ב-Cloud Shell ובה יוצרים קובץ חדש. שם הקובץ חייב לכלול את הסיומת
.tf, למשלmain.tf. במדריך הזה, הקובץ נקראmain.tf.mkdir DIRECTORY && cd DIRECTORY && touch main.tf
-
אם אתם עוקבים אחרי המדריך, תוכלו להעתיק את הקוד לדוגמה בכל קטע או שלב.
מעתיקים את הקוד לדוגמה בקובץ
main.tfהחדש שיצרתם.לחלופין, אפשר גם להעתיק את הקוד מ-GitHub. כדאי לעשות את זה כשקטע הקוד של Terraform הוא חלק מפתרון מקצה לקצה.
- בודקים את הפרמטרים לדוגמה ומשנים אותם בהתאם לסביבה שלכם.
- שומרים את השינויים.
-
מפעילים את Terraform. צריך לעשות זאת רק פעם אחת לכל ספרייה.
terraform init
אופציונלי: תוכלו לכלול את האפשרות
-upgrade, כדי להשתמש בגרסה העדכנית ביותר של הספק של Google:terraform init -upgrade
החלה של השינויים
-
בודקים את ההגדרות ומוודאים שהמשאבים שמערכת Terraform תיצור או תעדכן תואמים לציפיות שלכם:
terraform plan
מתקנים את ההגדרות לפי הצורך.
-
מריצים את הפקודה הבאה ומזינים
yesבהודעה שמופיעה, כדי להחיל את הגדרות Terraform:terraform apply
ממתינים עד שב-Terraform תוצג ההודעה "Apply complete!".
- פותחים את Google Cloud הפרויקט כדי לראות את התוצאות. במסוף Google Cloud , נכנסים למשאבים בממשק המשתמש כדי לוודא שהם נוצרו או עודכנו ב-Terraform.
API
מבצעים קריאה לשיטה datasets.insert
עם משאב מוגדר של מערך נתונים.
C#
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי C#הוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery C# API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
המשך
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Goהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Go API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Java
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Javaהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Java API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Node.js
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Node.jsהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Node.js API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
PHP
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי PHPהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery PHP API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Python
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Pythonהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Python API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
Ruby
לפני שמנסים את הדוגמה הזו, צריך לפעול לפי Rubyהוראות ההגדרה שבמדריך למתחילים של BigQuery באמצעות ספריות לקוח. מידע נוסף מופיע במאמרי העזרה של BigQuery Ruby API.
כדי לבצע אימות ב-BigQuery, צריך להגדיר את Application Default Credentials. מידע נוסף זמין במאמר הגדרת אימות לספריות לקוח.
מתן שמות למערכי נתונים
כשיוצרים מערך נתונים ב-BigQuery, השם שלו צריך להיות ייחודי לכל פרויקט. שם מערך הנתונים יכול להכיל את התווים הבאים:
- עד 1,024 תווים.
- אותיות (רישיות או קטנות), מספרים וקווים תחתונים.
כברירת מחדל, שמות של קבוצות נתונים הם תלויי אותיות רישיות. mydataset ו-MyDataset יכולים להתקיים יחד באותו פרויקט, אלא אם אחד מהם לא מבחין בין אותיות רישיות לאותיות קטנות. דוגמאות אפשר למצוא במאמרים יצירת מערך נתונים שלא מבחין בין אותיות רישיות לאותיות קטנות ומשאב: מערך נתונים.
שמות של מערכי נתונים לא יכולים להכיל רווחים או תווים מיוחדים כמו -, &, @ או %.
מערכי נתונים מוסתרים
קבוצת נתונים מוסתרת היא קבוצת נתונים שהשם שלה מתחיל בקו תחתון. אפשר לשלוח שאילתות לטבלאות ולתצוגות במערכי נתונים מוסתרים באותו אופן שבו שולחים שאילתות למערכי נתונים אחרים. יש הגבלות על מערכי נתונים מוסתרים:
- הם מוסתרים בחלונית Explorer במסוף Google Cloud .
- הם לא מופיעים באף
INFORMATION_SCHEMAתצוגה. - אי אפשר להשתמש בהם עם קבוצות נתונים מקושרות.
- אי אפשר להשתמש בהם כמערך נתונים של מקור עם המשאבים המורשים הבאים:
- הם לא מופיעים בקטלוג הנתונים (שיצא משימוש) או ב-Knowledge Catalog.
- אי אפשר להשתמש בהם כמערך נתונים מקור ליצירת העתק של מערך נתונים
אבטחת מערך נתונים
מידע על שליטה בגישה למערכי נתונים ב-BigQuery זמין במאמר בנושא שליטה בגישה למערכי נתונים. מידע על הצפנת נתונים זמין במאמר הצפנה במנוחה.
המאמרים הבאים
- מידע נוסף על הצגת רשימה של מערכי נתונים בפרויקט זמין במאמר הצגת רשימה של מערכי נתונים.
- למידע נוסף על מטא-נתונים של מערכי נתונים, אפשר לעיין במאמר קבלת מידע על מערכי נתונים.
- מידע נוסף על שינוי מאפיינים של מערכי נתונים זמין במאמר בנושא עדכון מערכי נתונים.
- איך יוצרים תוויות ומנהלים אותן?
נסו בעצמכם
אנחנו ממליצים למשתמשים חדשים ב-Google Cloud ליצור חשבון כדי שיוכלו להעריך את הביצועים של BigQuery בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300 $להרצה, לבדיקה ולפריסה של עומסי העבודה.
מתנסים ב-BigQuery בחינם