
הדמיה של גרפים באמצעות BigQuery DataFrames
במאמר הזה מוסבר איך ליצור סוגים שונים של תרשימים באמצעות ספריית ההדמיה של BigQuery DataFrames.
bigframes.pandas API
מספק מערך שלם של כלים ל-Python. ה-API תומך בפעולות סטטיסטיות מתקדמות, ואפשר להציג באופן חזותי את הצבירות שנוצרו מ-BigQuery DataFrames. אפשר גם לעבור מ-BigQuery DataFrames ל-pandas DataFrame עם פעולות דגימה מובנות.
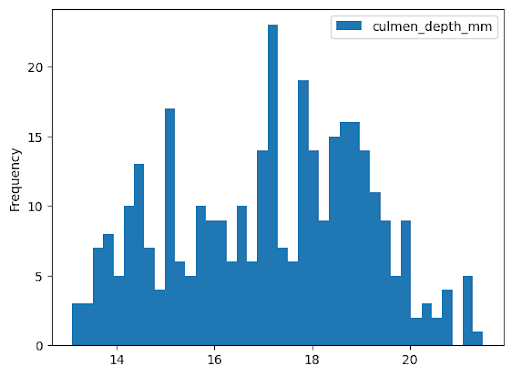
היסטוגרמה
בדוגמה הבאה, הנתונים נקראים מהטבלה bigquery-public-data.ml_datasets.penguins כדי ליצור היסטוגרמה של התפלגות העומקים של מקורי הפינגווינים:
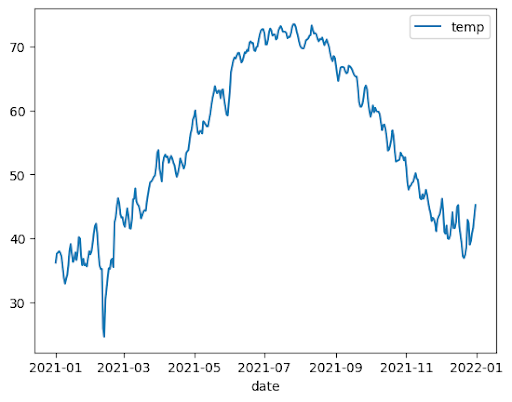
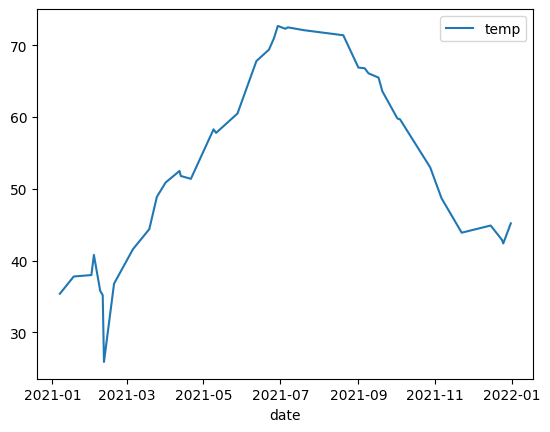
תרשים קו
בדוגמה הבאה נעשה שימוש בנתונים מהטבלה bigquery-public-data.noaa_gsod.gsod2021 כדי ליצור תרשים קו של שינויים בטמפרטורה החציונית במהלך השנה:
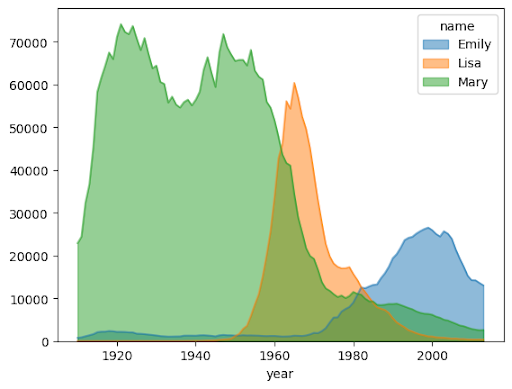
תרשים שטח
בדוגמה הבאה נעשה שימוש בטבלה bigquery-public-data.usa_names.usa_1910_2013 כדי לעקוב אחרי הפופולריות של שמות בהיסטוריה של ארה"ב, והיא מתמקדת בשמות Mary, Emily ו-Lisa:
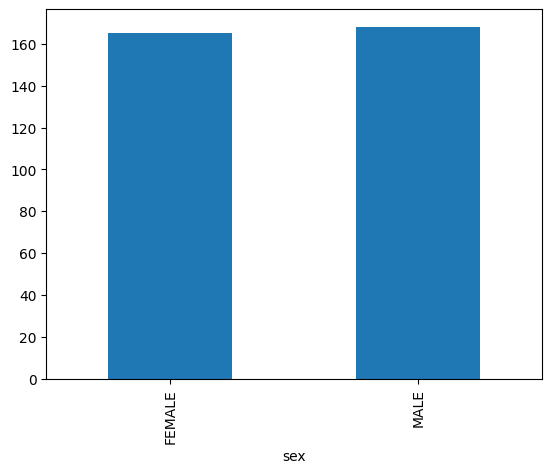
תרשים עמודות
בדוגמה הבאה נעשה שימוש בטבלה bigquery-public-data.ml_datasets.penguins כדי להציג את התפלגות המינים של הפינגווינים:
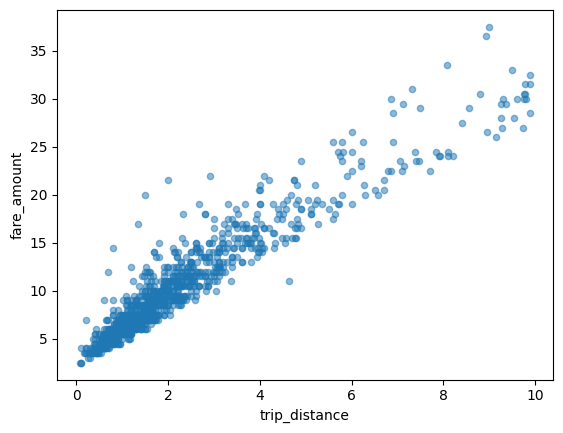
תרשים פיזור
בדוגמה הבאה נעשה שימוש בטבלה bigquery-public-data.new_york_taxi_trips.tlc_yellow_trips_2021 כדי לבדוק את הקשר בין סכומי התשלום על נסיעות במונית לבין מרחקי הנסיעה:
הדמיה של מערך נתונים גדול
BigQuery DataFrames מוריד נתונים למחשב המקומי לצורך ויזואליזציה. מספר נקודות הנתונים שניתן להוריד מוגבל ל-1,000 כברירת מחדל. אם מספר נקודות הנתונים חורג מהמגבלה, BigQuery DataFrames מבצע דגימה אקראית של מספר נקודות הנתונים ששווה למגבלה.
אפשר לשנות את המגבלה הזו על ידי הגדרת הפרמטר sampling_n כשמשרטטים תרשים, כמו בדוגמה הבאה:
יצירת תרשימים מתקדמים באמצעות פרמטרים של pandas ו-Matplotlib
אפשר להעביר עוד פרמטרים כדי לכוונן את הגרף, כמו שאפשר לעשות עם pandas, כי ספריית השרטוט של BigQuery DataFrames מבוססת על pandas ו-Matplotlib. בקטעים הבאים מפורטות דוגמאות.
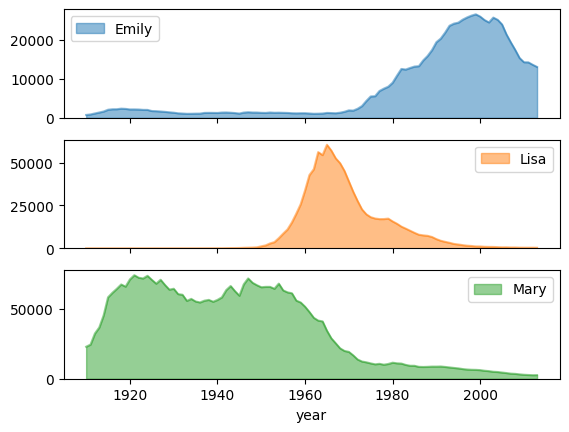
מגמת הפופולריות של השם עם תרשימי משנה
בדוגמה הבאה, נעשה שימוש בנתוני היסטוריית השמות מדוגמת תרשים שטח כדי ליצור גרפים נפרדים לכל שם על ידי הגדרת subplots=True בקריאה לפונקציה plot.area():
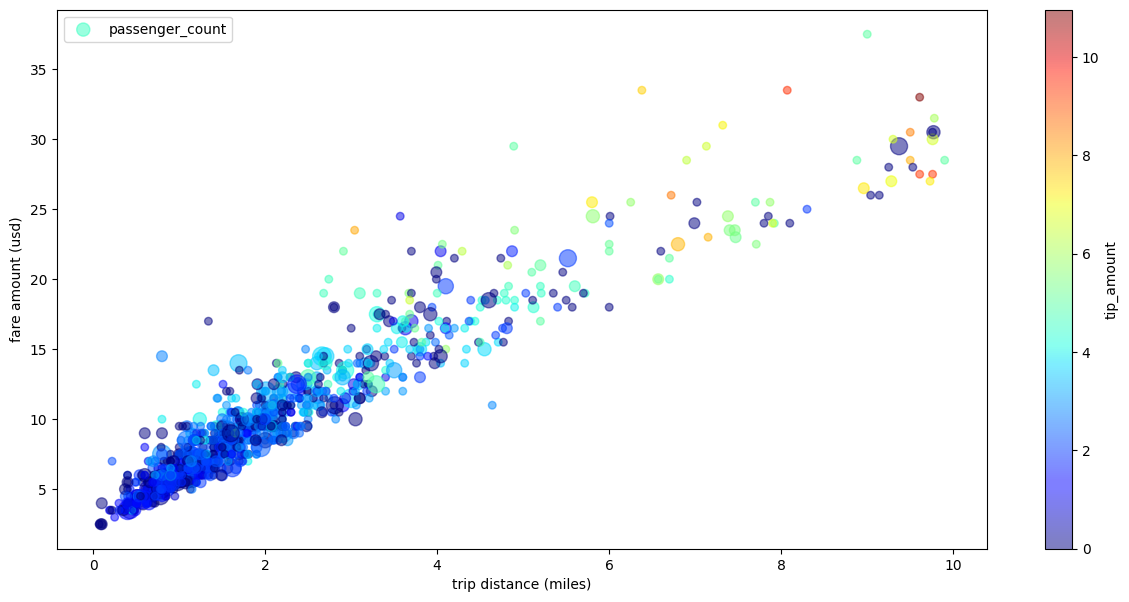
תרשים פיזור של נסיעות במונית עם כמה מאפיינים
בדוגמה הבאה נעשה שימוש בנתונים מדוגמת תרשים הפיזור. התוויות של ציר ה-x וציר ה-y מקבלות שמות חדשים, נעשה שימוש בפרמטר passenger_count לציון גודל הנקודות, נעשה שימוש בנקודות צבעוניות עם הפרמטר tip_amount, והגודל של הדמות משתנה:
המאמרים הבאים
- מידע נוסף על BigQuery DataFrames
- איך משתמשים ב-BigQuery DataFrames ב-dbt
- אפשר לעיין בהפניית API של BigQuery DataFrames.