
使用巢狀和重複的欄位
BigQuery 可搭配許多不同的資料模型化方法使用,且通常在許多資料模型方法中都能提供高效能。如要進一步調整資料模型以提升效能,可以考慮採用資料去正規化方法,也就是在單一資料表中新增資料欄,藉此減少或移除資料表聯結。
最佳做法:使用巢狀和重複的欄位,對資料儲存空間進行反正規化,並提高查詢效能。
反正規化是提升先前經過正規化的關聯式資料集讀取效能的常見策略。在 BigQuery 中,建議使用巢狀和重複的欄位對資料進行反正規化。如果資料集之間為階層關係且經常同時查詢 (例如上下層關係),最適合使用這項策略。
使用標準化資料以節省儲存空間對現今系統的影響較小。使用去標準化資料雖會提高儲存空間成本,但用來換取效能的提升絕對划算。Join 作業需要資料協調 (通訊頻寬),去標準化作業則可將資料本地化至個別運算單元,因此兩者可平行執行。
如要在將資料去標準化的同時維持資料的關係,您可以使用巢狀和重複的欄位,而非完全整併資料。將關聯資料完全整併後,網路通訊 (重組) 可能會對查詢效能造成負面影響。
舉例來說,如果您在進行訂單結構定義的去標準化作業時未使用巢狀與重複的欄位,就可能須按照 order_id 等的欄位將資料分組 (如果存在一對多關係)。將資料分組涉及重組作業,因此成效不如使用巢狀與重複的欄位將資料去標準化。
在某些情況下,將資料去標準化及使用巢狀與重複的欄位並無法提升效能。舉例來說,星狀結構通常是經過最佳化的分析架構,因此如果您嘗試進一步去正規化,成效可能不會有顯著差異。
使用巢狀和重複的欄位
BigQuery 不需要完全整平的去標準化作業。您可以使用巢狀與重複欄位來保留關聯性。
巢狀資料 (
STRUCT)- 巢狀資料可讓您內嵌表示外部實體。
- 查詢巢狀資料時使用 dot 語法參照 Leaf 欄位,這與使用 Join 的語法類似。
- 巢狀資料在 GoogleSQL 中會表示為
STRUCT類型。
重複資料 (
ARRAY)- 建立類型為
RECORD的欄位並將模式設為REPEATED,即可保留內嵌的一對多關係 (只要關係並非高基數)。 - 如果使用重複資料,資料重組就非必要。
- 重複的資料會表示為
ARRAY。您可以在 GoogleSQL 中使用ARRAY函式查詢重複資料。
- 建立類型為
巢狀和重複的資料 (
STRUCT的ARRAY)。- 巢狀和重複資料彼此互補。
- 例如,在交易記錄資料表中,您可以納入明細項目
STRUCT的陣列。
詳情請參閱「在資料表結構定義中指定巢狀與重複的資料欄」。
如要進一步瞭解如何反正規化資料,請參閱「反正規化」一文。
範例
假設有 Orders 個表格,每列代表售出的委刊項:
| Order_Id | Item_Name |
|---|---|
| 001 | A1 |
| 001 | B1 |
| 002 | A1 |
| 002 | C1 |
如要分析這個資料表的資料,您需要使用類似下列的 GROUP BY 子句:
SELECT COUNT (Item_Name) FROM Orders GROUP BY Order_Id;
GROUP BY 子句會產生額外的運算負荷,但您可以透過巢狀重複資料避免這種情況。您可以建立每個資料列包含一筆訂單的資料表,並將訂單明細項目放在巢狀欄位中,避免使用 GROUP BY 子句:
| Order_Id | Item_Name |
|---|---|
| 001 |
A1 B1 |
| 002 |
A1 C1 |
在 BigQuery 中,您通常會將巢狀結構定義指定為 ARRAY 物件的 STRUCT。您可以使用 UNNEST 運算子將巢狀資料扁平化,如下列查詢所示:
SELECT * FROM UNNEST( [ STRUCT('001' AS Order_Id, ['A1', 'B1'] AS Item_Name), STRUCT('002' AS Order_Id, ['A1', 'C1'] AS Item_Name) ] );
這項查詢會產生類似下列內容的結果:
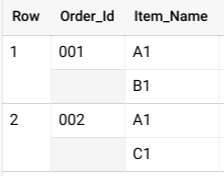
如果這項資料未巢狀化,每個訂單可能會有多個資料列,每個資料列代表該訂單中銷售的一項商品,這會導致表格過大,並產生昂貴的 GROUP BY 作業。
運動
如要比較使用巢狀欄位的查詢與未使用巢狀欄位的查詢,請按照本節的步驟操作。
根據公開資料集建立資料表:
bigquery-public-data.stackoverflow.commentsCREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow` AS ( SELECT user_id, post_id, creation_date FROM `bigquery-public-data.stackoverflow.comments` );
使用
stackoverflow表格,執行下列查詢,查看每位使用者的最早留言:SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date AS earliest_comment) ORDER BY creation_date ASC LIMIT 1)[OFFSET(0)].* FROM `PROJECT.DATASET.stackoverflow` GROUP BY user_id ORDER BY user_id ASC;
這項查詢大約需要 25 秒才能執行完畢,並會處理 1.88 GB 的資料。
建立第二個資料表,其中包含相同的資料,但會使用
STRUCT型別建立comments欄位來儲存post_id和creation_date資料,而不是兩個個別欄位:CREATE OR REPLACE TABLE `PROJECT.DATASET.stackoverflow_nested` AS ( SELECT user_id, ARRAY_AGG(STRUCT(post_id, creation_date) ORDER BY creation_date ASC) AS comments FROM `bigquery-public-data.stackoverflow.comments` GROUP BY user_id );
使用
stackoverflow_nested表格,執行下列查詢,查看每位使用者的最早留言:SELECT user_id, (SELECT AS STRUCT post_id, creation_date as earliest_comment FROM UNNEST(comments) ORDER BY creation_date ASC LIMIT 1).* FROM `PROJECT.DATASET.stackoverflow_nested` ORDER BY user_id ASC;
這項查詢大約需要 10 秒才能執行完畢,並會處理 1.28 GB 的資料。
完成後,請刪除
stackoverflow和stackoverflow_nested資料表。