
In dieser Anleitung erfahren Sie, wie Sie ein univariates Zeitachsenmodell ARIMA_PLUS verwenden, um den zukünftigen Wert für eine bestimmte Spalte basierend auf den bisherigen Werten für diese Spalte vorherzusagen.
In dieser Anleitung wird eine einzelne Zeitreihe prognostiziert. Prognostizierte Werte werden einmal für jeden Zeitpunkt in den Eingabedaten berechnet.
In dieser Anleitung werden Daten aus der öffentlichen Beispieltabelle bigquery-public-data.google_analytics_sample.ga_sessions verwendet. Diese Tabelle enthält verschleierte E-Commerce-Daten aus dem Google Merchandise Store.
Ziele
In dieser Anleitung werden Sie durch die folgenden Aufgaben geführt:
- Erstellen eines Zeitreihenmodells zur Prognose des Website-Traffics mit der
CREATE MODEL-Anweisung. - Bewerten der Informationen zum autoregressiven integrierten gleitenden Durchschnitt (ARIMA) im Modell mit der
ML.ARIMA_EVALUATE-Funktion. - Die Modellkoeffizienten mit der Funktion
ML.ARIMA_COEFFICIENTSprüfen. - Abrufen der prognostizierten Website-Traffic-Informationen aus dem Modell mithilfe der Funktion
ML.FORECAST. - Abrufen von Komponenten der Zeitreihe, z. B. Saisonalität und Trend, mit der Funktion
ML.EXPLAIN_FORECAST. Sie können diese Zeitreihenkomponenten untersuchen, um die prognostizierten Werte zu erklären.
Kosten
In dieser Anleitung werden kostenpflichtige Komponenten von Google Cloudverwendet, darunter:
- BigQuery
- BigQuery ML
Weitere Informationen zu den Kosten von BigQuery finden Sie auf der Seite BigQuery-Preise.
Weitere Informationen zu den Kosten für BigQuery ML finden Sie unter BigQuery ML-Preise.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- BigQuery ist in neuen Projekten automatisch aktiviert.
Wenn Sie BigQuery in einem bestehenden Projekt aktivieren möchten, wechseln Sie zu
Aktivieren Sie die BigQuery API.
Rollen, die zum Aktivieren von APIs erforderlich sind
Zum Aktivieren von APIs benötigen Sie die IAM-Rolle „Service Usage-Administrator“ (
roles/serviceusage.serviceUsageAdmin), die die Berechtigungserviceusage.services.enableenthält. Weitere Informationen zum Zuweisen von Rollen
Erforderliche Berechtigungen
Sie benötigen die IAM-Berechtigung
bigquery.datasets.create, um das Dataset zu erstellen.Zum Erstellen des Modells benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateData
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatabigquery.jobs.create
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset zum Speichern Ihres ML-Modells.Console
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Multiregional und dann USA aus.
Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
bq
Wenn Sie ein neues Dataset erstellen möchten, verwenden Sie den Befehl bq mk --dataset.
Erstellen Sie ein Dataset mit dem Namen
bqml_tutorialund legen Sie den Datenspeicherort aufUSfest.bq mk --dataset \ --location=US \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
Prüfen Sie, ob das Dataset erstellt wurde:
bq ls
API
Rufen Sie die Methode datasets.insert mit einer definierten Dataset-Ressource auf.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Eingabedaten visualisieren
Bevor Sie das Modell erstellen, können Sie optional Ihre Eingabezeitachsendaten visualisieren, um einen Eindruck von der Verteilung zu erhalten. Verwenden Sie dazu Data Studio.
So visualisieren Sie die Zeitreihendaten:
SQL
In der folgenden GoogleSQL-Abfrage parst die SELECT-Anweisung die Spalte date aus der Eingabetabelle in den Typ TIMESTAMP und benennt sie in parsed_date um. Außerdem wird mit der SUM(...)-Klausel und der GROUP BY date-Klausel ein täglicher totals.visits-Wert erstellt.
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
Klicken Sie nach Abschluss der Abfrage auf Öffnen in > Data Studio. Data Studio wird in einem neuen Tab geöffnet. Führen Sie die folgenden Schritte in dem neuen Tab aus.
Klicken Sie in Data Studio auf Einfügen > Zeitreihendiagramm.
Wählen Sie im Bereich Diagramm den Tab Einrichtung aus.
Fügen Sie im Bereich Messwert das Feld total_visits hinzu und entfernen Sie den Standardmesswert Anzahl der Datensätze. Das resultierende Diagramm sieht etwa so aus:
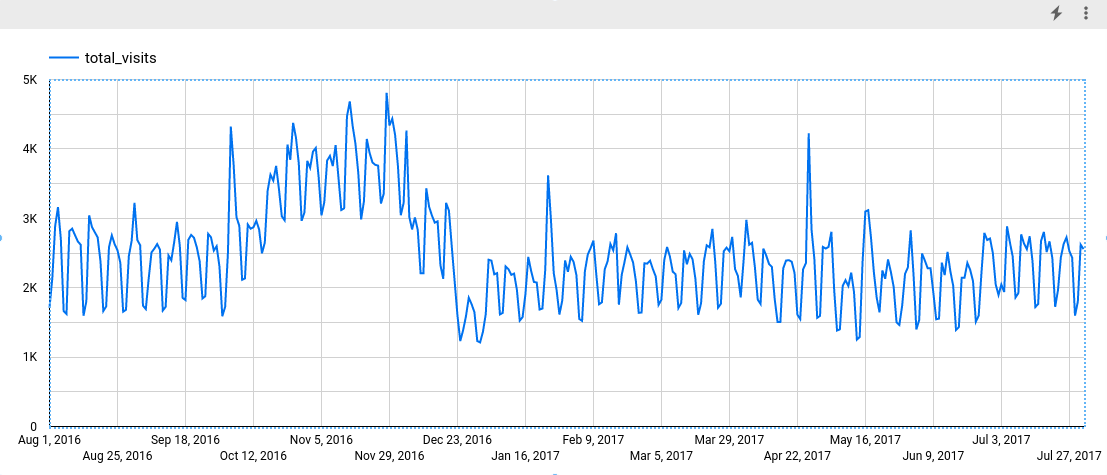
Dem Diagramm können Sie entnehmen, dass die Eingabezeitachse ein wöchentliches saisonales Muster aufweist.
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Das Ergebnis sieht etwa so aus:

Zeitachsenmodell erstellen
Erstellen Sie ein Zeitachsenmodell, um die Gesamtzahl der Websitebesuche zu prognostizieren, die durch die Spalte totals.visits dargestellt werden, und trainieren Sie es mit den Google Analytics 360-Daten.
SQL
In der folgenden Abfrage gibt die OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)-Anweisung an, dass Sie ein ARIMA-basiertes Zeitachsenmodell erstellen. Die auto_arima-Option der CREATE MODEL-Anweisung hat standardmäßig den Wert TRUE. Der auto.ARIMA-Algorithmus stimmt die Hyperparameter im Modell also automatisch ab. Der Algorithmus passt Dutzende von Kandidatenmodellen an und wählt das beste Modell aus, also das Modell mit dem niedrigsten Akaike-Informationskriterium (AIC).
Die data_frequency-Option der CREATE MODEL-Anweisungen hat standardmäßig den Wert AUTO_FREQUENCY. Der Trainingsprozess leitet also automatisch die Datenhäufigkeit der Eingabezeitachse ab. Die Option decompose_time_series der Anweisung CREATE MODELTRUE ist standardmäßig auf TRUE festgelegt. Wenn Sie das Modell im nächsten Schritt auswerten, werden also Informationen zu den Zeitreihendaten zurückgegeben.
So erstellen Sie das Modell:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
CREATE OR REPLACE MODEL `bqml_tutorial.ga_arima_model` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'parsed_date', time_series_data_col = 'total_visits', auto_arima = TRUE, data_frequency = 'AUTO_FREQUENCY', decompose_time_series = TRUE ) AS SELECT PARSE_TIMESTAMP("%Y%m%d", date) AS parsed_date, SUM(totals.visits) AS total_visits FROM `bigquery-public-data.google_analytics_sample.ga_sessions_*` GROUP BY date;
Die Abfrage dauert etwa 4 Sekunden. Anschließend können Sie auf das Modell
ga_arima_modelzugreifen. Da die Abfrage eineCREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, werden keine Abfrageergebnisse angezeigt.
BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Kandidatenmodelle bewerten
SQL
Bewerten Sie die Zeitreihenmodelle mit der Funktion ML.ARIMA_EVALUATE. Die ML.ARIMA_EVALUATE-Funktion zeigt die Bewertungsmesswerte aller infrage kommenden Modelle an, die während der automatischen Hyperparameter-Abstimmung bewertet wurden.
So bewerten Sie das Modell:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.ga_arima_model`);
Die Antwort sollte in etwa so aussehen:

BigQuery DataFrames
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Die Ausgabespalten non_seasonal_p, non_seasonal_d, non_seasonal_q und has_drift definieren ein ARIMA-Modell in der Trainingspipeline. Die Ausgabespalten log_likelihood, AIC und variance sind für den ARIMA-Modellanpassungsprozess relevant.
Der auto.ARIMA-Algorithmus verwendet den KPSS-Test, um den besten Wert für non_seasonal_d zu ermitteln. In diesem Fall ist das 1. Wenn non_seasonal_d gleich 1 ist, trainiert der auto.ARIMA-Algorithmus 42 verschiedene ARIMA-Kandidatenmodelle parallel.
In diesem Beispiel sind alle 42 Kandidatenmodelle gültig. Die Ausgabe enthält also 42 Zeilen, eine für jedes ARIMA-Kandidatenmodell. Wenn einige der Modelle ungültig sind, werden sie aus der Ausgabe ausgeschlossen. Diese Kandidatenmodelle werden in aufsteigender Reihenfolge nach AIC zurückgegeben. Das Modell in der ersten Zeile hat den niedrigsten AIC und gilt als bestes Modell. Das beste Modell wird als endgültiges Modell gespeichert und verwendet, wenn Sie Funktionen wie ML.FORECAST für das Modell aufrufen.
Die Spalte seasonal_periods enthält Informationen zum saisonalen Muster, das in den Zeitachsendaten ermittelt wurde. Es hat nichts mit der ARIMA-Modellierung zu tun und hat daher in allen Ausgabezeilen denselben Wert. Es wird ein wöchentliches Muster gemeldet, das mit den Ergebnissen übereinstimmt, die Sie gesehen haben, wenn Sie die Eingabedaten visualisiert haben.
Die Spalten has_holiday_effect, has_spikes_and_dips und has_step_changes werden nur ausgefüllt, wenn decompose_time_series=TRUE. Diese Spalten enthalten auch Informationen zu den Eingabezeitachsendaten und stehen nicht im Zusammenhang mit der ARIMA-Modellierung. Diese Spalten haben auch in allen Ausgabezeilen dieselben Werte.
In der Spalte error_message werden alle Fehler angezeigt, die während der auto.ARIMA-Anpassung aufgetreten sind. Ein möglicher Grund für Fehler ist, dass die ausgewählten Spalten non_seasonal_p, non_seasonal_d, non_seasonal_q und has_drift die Zeitachse nicht stabilisieren können. Legen Sie beim Erstellen des Modells die Option show_all_candidate_models auf TRUE fest, um die Fehlermeldung aller Kandidatenmodelle abzurufen.
Weitere Informationen zu den Ausgabespalten finden Sie unter ML.ARIMA_EVALUATE-Funktion.
Koeffizienten des Modells prüfen
SQL
Prüfen Sie die Koeffizienten des Zeitachsenmodells mit der Funktion ML.ARIMA_COEFFICIENTS.
So rufen Sie die Koeffizienten des Modells ab:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.ga_arima_model`);
In der Ausgabespalte ar_coefficients werden die Modellkoeffizienten des autoregressiven (AR) Teils des ARIMA-Modells angezeigt. Entsprechend zeigt die Ausgabespalte ma_coefficients die Modellkoeffizienten des gleitenden Durchschnitts (Moving Average, MA) des ARIMA-Modells an. Beide Spalten enthalten Array-Werte, deren Länge non_seasonal_p bzw. non_seasonal_q entspricht. In der Ausgabe der Funktion ML.ARIMA_EVALUATE haben Sie gesehen, dass das beste Modell einen non_seasonal_p-Wert von 2 und einen non_seasonal_q-Wert von 3 hat. Daher ist im ML.ARIMA_COEFFICIENTS-Ergebnis der ar_coefficients-Wert ein Array mit zwei Elementen und der ma_coefficients-Wert ein Array mit drei Elementen. Der Wert für intercept_or_drift ist der konstante Begriff im ARIMA-Modell.
Weitere Informationen zu den Ausgabespalten finden Sie unter ML.ARIMA_COEFFICIENTS-Funktion.
BigQuery DataFrames
Prüfen Sie die Koeffizienten des Zeitachsenmodells mit der Funktion coef_.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
In der Ausgabespalte ar_coefficients werden die Modellkoeffizienten des autoregressiven (AR) Teils des ARIMA-Modells angezeigt. Entsprechend zeigt die Ausgabespalte ma_coefficients die Modellkoeffizienten des gleitenden Durchschnitts (Moving Average, MA) des ARIMA-Modells an. Beide Spalten enthalten Array-Werte, deren Länge non_seasonal_p bzw. non_seasonal_q entspricht.
Modell zum Vorhersagen von Daten verwenden
SQL
Mit der Funktion ML.FORECAST können Sie zukünftige Zeitachsenwerte prognostizieren.
In der folgenden GoogleSQL-Abfrage gibt die STRUCT(30 AS horizon, 0.8 AS confidence_level)-Klausel an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einem Konfidenzniveau von 80% generiert.
So prognostizieren Sie Daten mit dem Modell:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
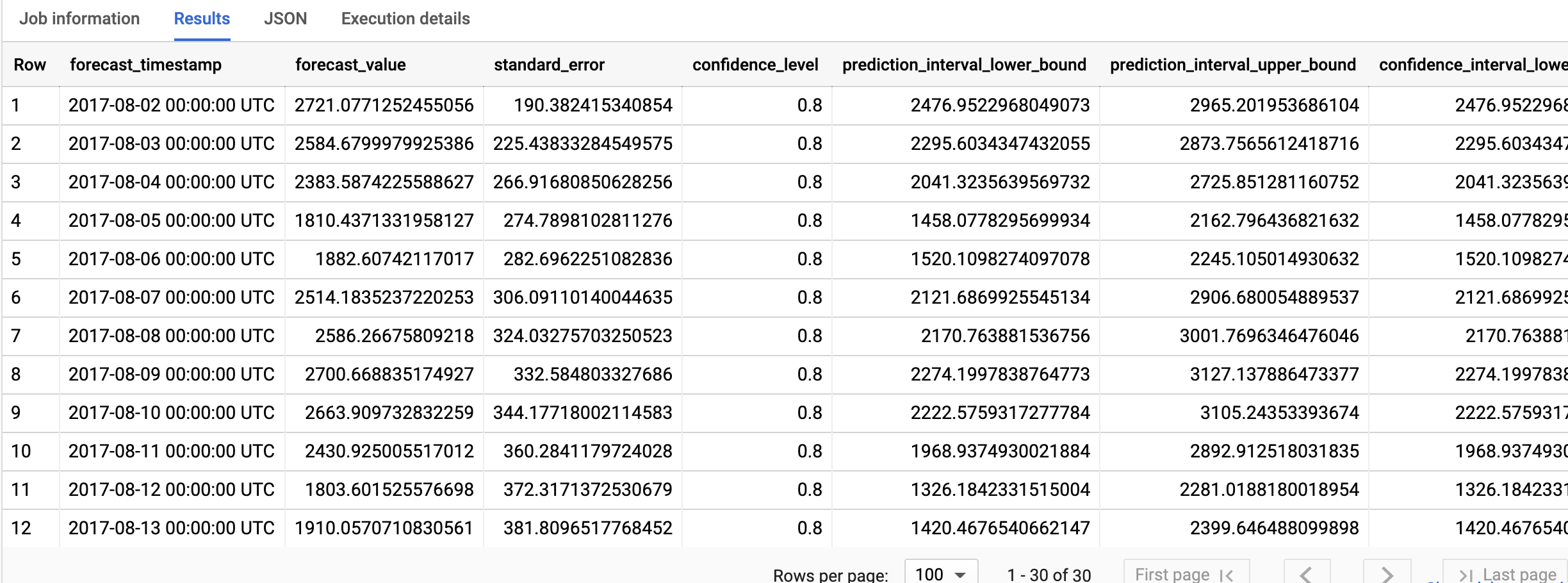
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
Die Antwort sollte in etwa so aussehen:
BigQuery DataFrames
Mit der Funktion predict zukünftige Zeitachsenwerte vorhersagen.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Die Ausgabezeilen sind in chronologischer Reihenfolge nach dem Wert der Spalte forecast_timestamp sortiert. In der Zeitachsenprognose ist das Vorhersageintervall, das durch die Spaltenwerte prediction_interval_lower_bound und prediction_interval_upper_bound dargestellt wird, genauso wichtig wie der Spaltenwert forecast_value. Der forecast_value-Wert ist der Mittelpunkt des Vorhersageintervalls. Das Vorhersageintervall hängt von den Spaltenwerten standard_error und confidence_level ab.
Weitere Informationen zu den Ausgabespalten finden Sie unter ML.FORECAST-Funktion.
Prognoseergebnisse erklären
SQL
Mit der Funktion ML.EXPLAIN_FORECAST können Sie neben Prognosedaten auch Messwerte zur Erklärbarkeit abrufen. Die Funktion ML.EXPLAIN_FORECAST prognostiziert zukünftige Zeitreihenwerte und gibt auch alle separaten Komponenten der Zeitreihe zurück.
Ähnlich wie bei der Funktion ML.FORECAST gibt die in der Funktion ML.EXPLAIN_FORECAST verwendete Klausel STRUCT(30 AS horizon, 0.8 AS confidence_level) an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einer Konfidenz von 80% generiert.
So erklären Sie die Ergebnisse des Modells:
Rufen Sie in der Google Cloud Console die Seite BigQuery auf.
Fügen Sie die folgende Abfrage in den Abfrageeditor ein und klicken Sie auf Ausführen:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.ga_arima_model`, STRUCT(30 AS horizon, 0.8 AS confidence_level));
Die Antwort sollte in etwa so aussehen:
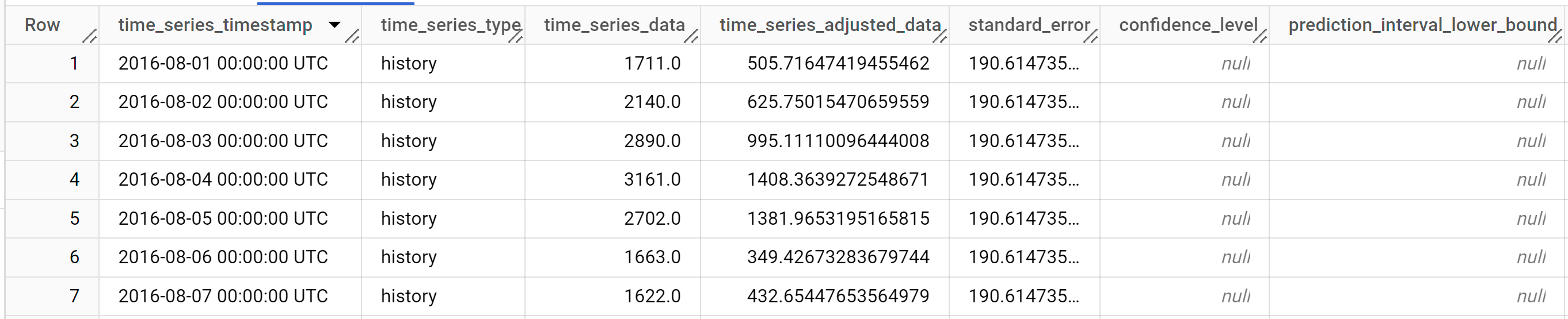
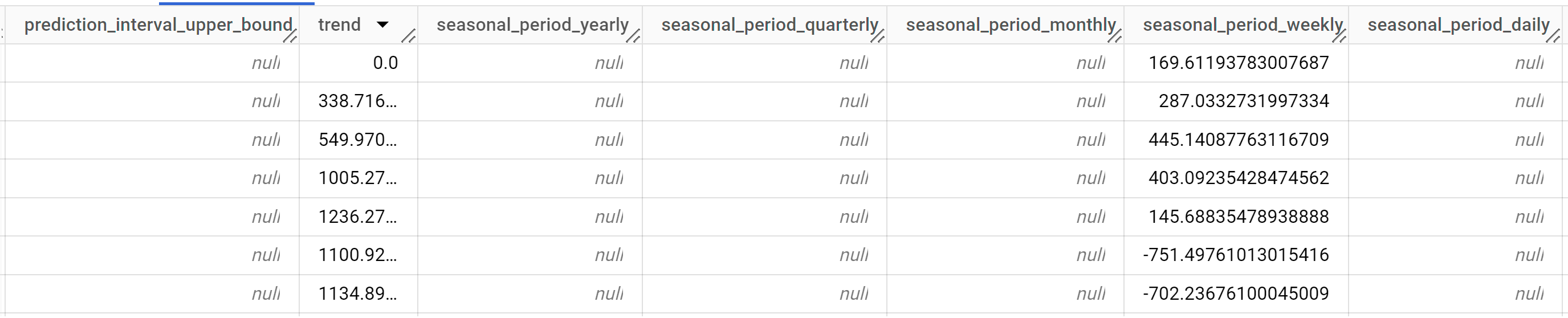
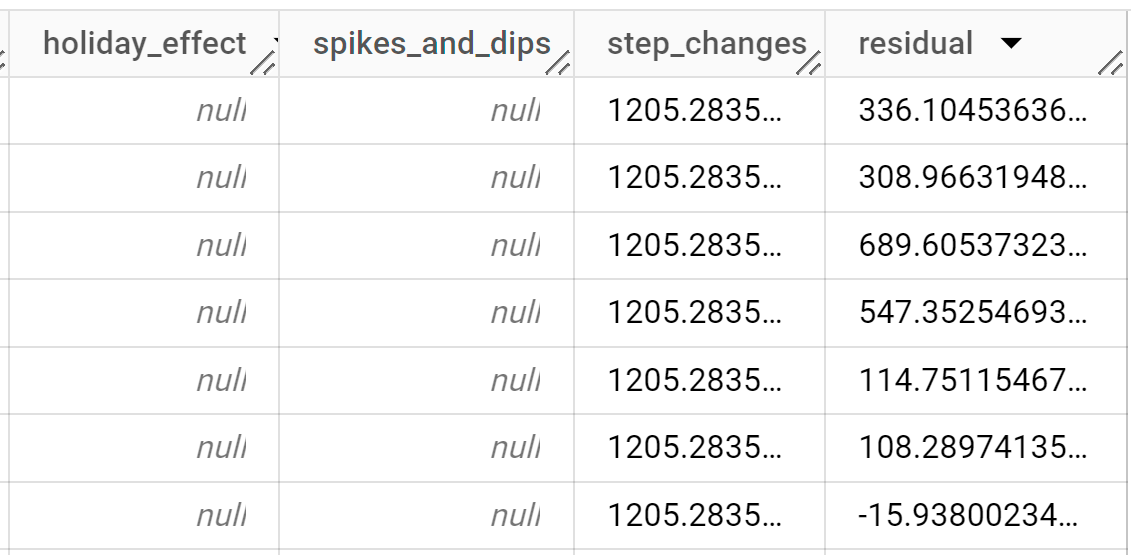
Die Ausgabezeilen werden chronologisch nach dem Spaltenwert
time_series_timestampsortiert.Weitere Informationen zu den Ausgabespalten finden Sie unter
ML.EXPLAIN_FORECAST-Funktion.
BigQuery DataFrames
Mit der Funktion predict_explain können Sie neben Prognosedaten auch Messwerte zur Erklärbarkeit abrufen. Die Funktion predict_explain prognostiziert zukünftige Zeitreihenwerte und gibt auch alle einzelnen Komponenten der Zeitreihe zurück.
Ähnlich wie bei der Funktion predict gibt die in der Funktion predict_explain verwendete Klausel horizon=30, confidence_level=0.8 an, dass die Abfrage 30 zukünftige Zeitpunkte prognostiziert und ein Vorhersageintervall mit einer Konfidenz von 80% generiert.
Bevor Sie dieses Beispiel ausprobieren, folgen Sie den Schritten zur Einrichtung von BigQuery DataFrames in der BigQuery-Kurzanleitung: BigQuery DataFrames verwenden. Weitere Informationen finden Sie in der Referenzdokumentation zu BigQuery DataFrames.
Richten Sie zur Authentifizierung bei BigQuery die Standardanmeldedaten für Anwendungen ein. Weitere Informationen finden Sie unter ADC für eine lokale Entwicklungsumgebung einrichten.
Wenn Sie die Ergebnisse visualisieren möchten, können Sie Data Studio verwenden. Gehen Sie dazu so vor, wie im Abschnitt Eingabedaten visualisieren beschrieben. Verwenden Sie die folgenden Spalten als Messwerte, um ein Diagramm zu erstellen:
time_series_dataprediction_interval_lower_boundprediction_interval_upper_boundtrendseasonal_period_weeklystep_changes
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
- Sie können das von Ihnen erstellte Projekt löschen.
- Sie können das Projekt aber auch behalten und das Dataset löschen.
Dataset löschen
Wenn Sie Ihr Projekt löschen, werden alle Datasets und Tabellen entfernt. Wenn Sie das Projekt wieder verwenden möchten, können Sie das in dieser Anleitung erstellte Dataset löschen:
Rufen Sie, falls erforderlich, die Seite „BigQuery“ in derGoogle Cloud Console auf.
Wählen Sie im Navigationsbereich das Dataset bqml_tutorial aus, das Sie erstellt haben.
Klicken Sie rechts im Fenster auf Delete dataset (Dataset löschen). Dadurch werden das Dataset, die Tabelle und alle Daten gelöscht.
Bestätigen Sie im Dialogfeld Delete dataset (Dataset löschen) den Löschbefehl. Geben Sie dazu den Namen des Datasets (
bqml_tutorial) ein und klicken Sie auf Delete (Löschen).
Projekt löschen
So löschen Sie das Projekt:
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Nächste Schritte
- Weitere Informationen zum Prognostizieren einer einzelnen Zeitreihe mit einem multivariaten Modell
- Mehrere Zeitreihen mit einem univariaten Modell prognostizieren
- Informationen zum Skalieren eines univariaten Modells bei der Prognose mehrerer Zeitreihen über viele Zeilen hinweg
- Hierarchische Prognosen für mehrere Zeitachsen mit einem univariaten Modell erstellen
- Eine Übersicht über BigQuery ML finden Sie unter Einführung in KI und ML in BigQuery.