
En este tutorial se explica cómo usar un ARIMA_PLUSmodelo de serie temporal univariante para predecir el valor futuro de una columna determinada en función de los valores históricos de esa columna.
En este tutorial se hacen previsiones de varias series temporales. Los valores previstos se calculan para cada punto temporal y para cada valor de una o varias columnas especificadas. Por ejemplo, si quieres predecir el tiempo y especificas una columna que contenga datos de ciudades, los datos previstos incluirán las predicciones de todos los puntos temporales de la ciudad A, los valores previstos de todos los puntos temporales de la ciudad B, etc.
En este tutorial se usan datos de la tabla pública
bigquery-public-data.new_york.citibike_trips. Esta tabla contiene información sobre los trayectos de Citi Bike en Nueva York.
Antes de leer este tutorial, te recomendamos que leas el artículo Predecir una sola serie temporal con un modelo univariante.
Crear conjunto de datos
Crea un conjunto de datos de BigQuery para almacenar tu modelo de aprendizaje automático.
Consola
En la Google Cloud consola, ve a la página BigQuery.
En el panel Explorador, haz clic en el nombre de tu proyecto.
Haga clic en Ver acciones > Crear conjunto de datos.
En la página Crear conjunto de datos, haz lo siguiente:
En ID del conjunto de datos, introduce
bqml_tutorial.En Tipo de ubicación, selecciona Multirregión y, a continuación, EE. UU. (varias regiones de Estados Unidos).
Deje el resto de los ajustes predeterminados como están y haga clic en Crear conjunto de datos.
bq
Para crear un conjunto de datos, usa el comando
bq mk
con la marca --location. Para ver una lista completa de los parámetros posibles, consulta la referencia del comando bq mk --dataset.
Crea un conjunto de datos llamado
bqml_tutorialcon la ubicación de los datos definida comoUSy la descripciónBigQuery ML tutorial dataset:bq --location=US mk -d \ --description "BigQuery ML tutorial dataset." \ bqml_tutorial
En lugar de usar la marca
--dataset, el comando usa el acceso directo-d. Si omite-dy--dataset, el comando creará un conjunto de datos de forma predeterminada.Confirma que se ha creado el conjunto de datos:
bq ls
API
Llama al método datasets.insert con un recurso de conjunto de datos definido.
{ "datasetReference": { "datasetId": "bqml_tutorial" } }
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Visualizar los datos de entrada
Antes de crear el modelo, puedes visualizar los datos de la serie temporal de entrada para hacerte una idea de la distribución. Para ello, puedes usar Looker Studio.
SQL
La instrucción SELECT de la siguiente consulta usa la función EXTRACT para extraer la información de la fecha de la columna starttime. La consulta usa la cláusula COUNT(*) para obtener el número total diario de viajes de Citi Bike.
Sigue estos pasos para visualizar los datos de la serie temporal:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` GROUP BY date;
Cuando se complete la consulta, haz clic en Explorar datos > Explorar con Looker Studio. Looker Studio se abre en una pestaña nueva. Sigue estos pasos en la nueva pestaña.
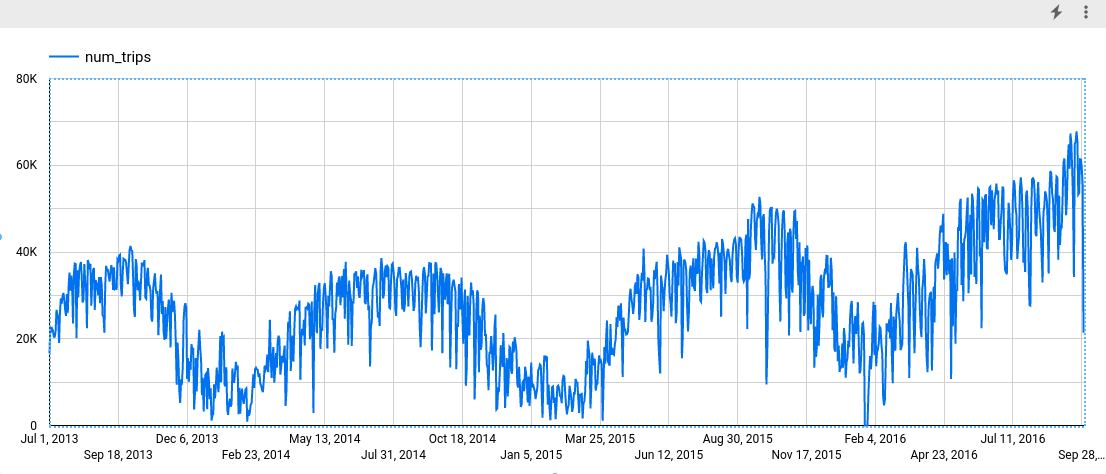
En Looker Studio, haz clic en Insertar > Gráfico de serie temporal.
En el panel Gráfico, selecciona la pestaña Configuración.
En la sección Métrica, añade el campo num_trips y quita la métrica predeterminada Número de registros. El gráfico resultante será similar al siguiente:
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Crear el modelo de serie temporal
Quieres predecir el número de trayectos en bicicleta de cada estación de Citi Bike, lo que requiere muchos modelos de series temporales, uno por cada estación de Citi Bike incluida en los datos de entrada. Puedes crear varios modelos para hacerlo, pero puede ser un proceso tedioso y largo, sobre todo si tienes un gran número de series temporales. En su lugar, puede usar una sola consulta para crear y ajustar un conjunto de modelos de series temporales con el fin de predecir varias series temporales a la vez.
SQL
En la siguiente consulta, la cláusula OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...)
indica que estás creando un modelo de serie temporal basado en ARIMA. Usa la opción time_series_id_col de la instrucción CREATE MODEL para especificar una o varias columnas de los datos de entrada de los que quieras obtener previsiones. En este caso, se trata de la estación de Citi Bike, representada por la columna start_station_name. Usas la cláusula WHERE para
limitar las estaciones de inicio a las que tienen Central Park en sus nombres. La opción auto_arima_max_order de la instrucción CREATE MODEL controla el espacio de búsqueda para el ajuste de hiperparámetros en el algoritmo auto.ARIMA. La opción decompose_time_series de la instrucción CREATE MODEL tiene el valor predeterminado TRUE, por lo que se devuelve información sobre los datos de la serie temporal al evaluar el modelo en el paso siguiente.
Sigue estos pasos para crear el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
CREATE OR REPLACE MODEL `bqml_tutorial.nyc_citibike_arima_model_group` OPTIONS (model_type = 'ARIMA_PLUS', time_series_timestamp_col = 'date', time_series_data_col = 'num_trips', time_series_id_col = 'start_station_name', auto_arima_max_order = 5 ) AS SELECT start_station_name, EXTRACT(DATE from starttime) AS date, COUNT(*) AS num_trips FROM `bigquery-public-data.new_york.citibike_trips` WHERE start_station_name LIKE '%Central Park%' GROUP BY start_station_name, date;
La consulta tarda unos 24 segundos en completarse. Después, puedes acceder al modelo
nyc_citibike_arima_model_group. Como la consulta usa una instrucciónCREATE MODEL, no verás los resultados de la consulta.
Esta consulta crea doce modelos de serie temporal, uno para cada una de las doce estaciones de inicio de Citi Bike de los datos de entrada. El coste temporal, que es de aproximadamente 24 segundos, es solo 1,4 veces mayor que el de crear un modelo de serie temporal único debido al paralelismo. Sin embargo, si quitas la cláusula WHERE ... LIKE ..., habría más de 600 series temporales que predecir y no se predecirían completamente en paralelo debido a las limitaciones de capacidad de las ranuras. En ese caso, la consulta tardaría unos 15 minutos en completarse. Para reducir el tiempo de ejecución de la consulta, aunque esto suponga una ligera disminución de la calidad del modelo, puedes reducir el valor de auto_arima_max_order.
De esta forma, se reduce el espacio de búsqueda del ajuste de hiperparámetros en el algoritmo auto.ARIMA. Para obtener más información, consulta Large-scale time series forecasting best practices.
BigQuery DataFrames
En el siguiente fragmento, se crea un modelo de serie temporal basado en ARIMA.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
De esta forma, se crean doce modelos de series temporales, uno para cada una de las doce estaciones de inicio de Citi Bike de los datos de entrada. El coste temporal, de aproximadamente 24 segundos, es solo 1,4 veces mayor que el de crear un solo modelo de serie temporal debido al paralelismo.
Evaluar el modelo
SQL
Evalúa el modelo de serie temporal con la función ML.ARIMA_EVALUATE. La función ML.ARIMA_EVALUATE muestra las métricas de evaluación que se han generado para el modelo durante el proceso de ajuste automático de hiperparámetros.
Sigue estos pasos para evaluar el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.ARIMA_EVALUATE(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
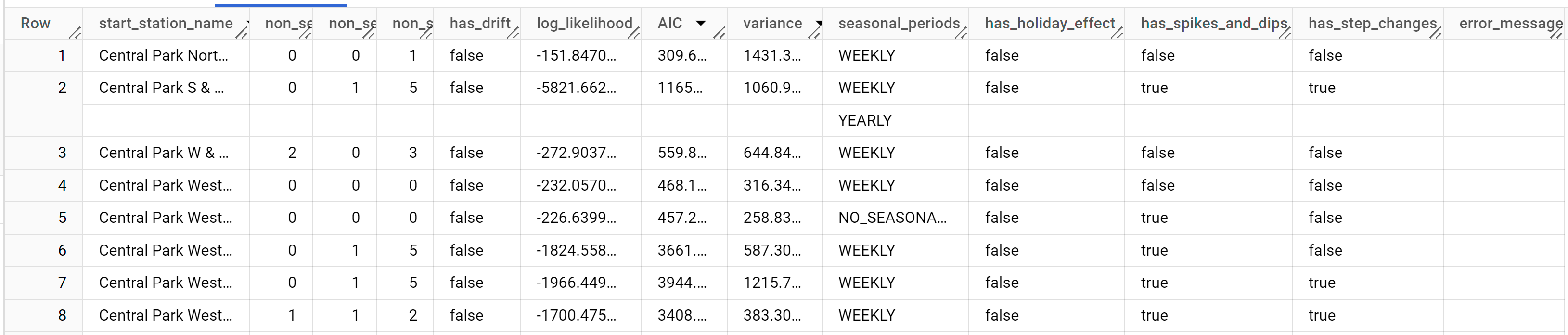
Los resultados deberían tener este aspecto:
Mientras que
auto.ARIMAevalúa decenas de modelos ARIMA candidatos para cada serie temporal,ML.ARIMA_EVALUATEsolo muestra de forma predeterminada la información del mejor modelo para que la tabla de resultados sea compacta. Para ver todos los modelos candidatos, puede asignar el valorTRUEal argumentoshow_all_candidate_modelde la funciónML.ARIMA_EVALUATE.
BigQuery DataFrames
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
La columna start_station_name identifica la columna de datos de entrada para la que se han creado series temporales. Esta es la columna que especificaste con la opción time_series_id_col al crear el modelo.
Las columnas de salida non_seasonal_p, non_seasonal_d, non_seasonal_q y has_drift
definen un modelo ARIMA en el flujo de entrenamiento. Las columnas de salida log_likelihood, AIC y variance son relevantes para el proceso de ajuste del modelo ARIMA.El proceso de ajuste determina el mejor modelo ARIMA mediante el algoritmo auto.ARIMA, uno para cada serie temporal.
El algoritmo auto.ARIMA usa la prueba KPSS para determinar el mejor valor de non_seasonal_d, que en este caso es 1. Si non_seasonal_d es 1, el algoritmo auto.ARIMA entrena 42 modelos ARIMA posibles diferentes en paralelo.
En este ejemplo, los 42 modelos candidatos son válidos, por lo que el resultado contiene 42 filas, una por cada modelo ARIMA candidato. En los casos en los que algunos de los modelos no son válidos, se excluyen del resultado. Estos modelos candidatos se devuelven en orden ascendente por AIC. El modelo de la primera fila tiene el AIC más bajo y se considera el mejor modelo. Este modelo óptimo se guarda como modelo final y se usa cuando pronosticas datos, evalúas el modelo e inspeccionas los coeficientes del modelo, tal como se muestra en los pasos siguientes.
La columna seasonal_periods contiene información sobre el patrón estacional identificado en los datos de serie temporal. Cada serie temporal puede tener patrones estacionales diferentes. Por ejemplo, en la figura se puede ver que una serie temporal tiene un patrón anual, mientras que otras no.
Las columnas has_holiday_effect, has_spikes_and_dips y has_step_changes solo se rellenan cuando decompose_time_series=TRUE. Estas columnas también reflejan información sobre los datos de series temporales de entrada y no están relacionadas con el modelado ARIMA. Estas columnas también tienen los mismos valores en todas las filas de salida.
Inspeccionar los coeficientes del modelo
SQL
Inspecciona los coeficientes del modelo de serie temporal con la función ML.ARIMA_COEFFICIENTS.
Sigue estos pasos para obtener los coeficientes del modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.ARIMA_COEFFICIENTS(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`);
La consulta tarda menos de un segundo en completarse. Los resultados deberían ser similares a los siguientes:
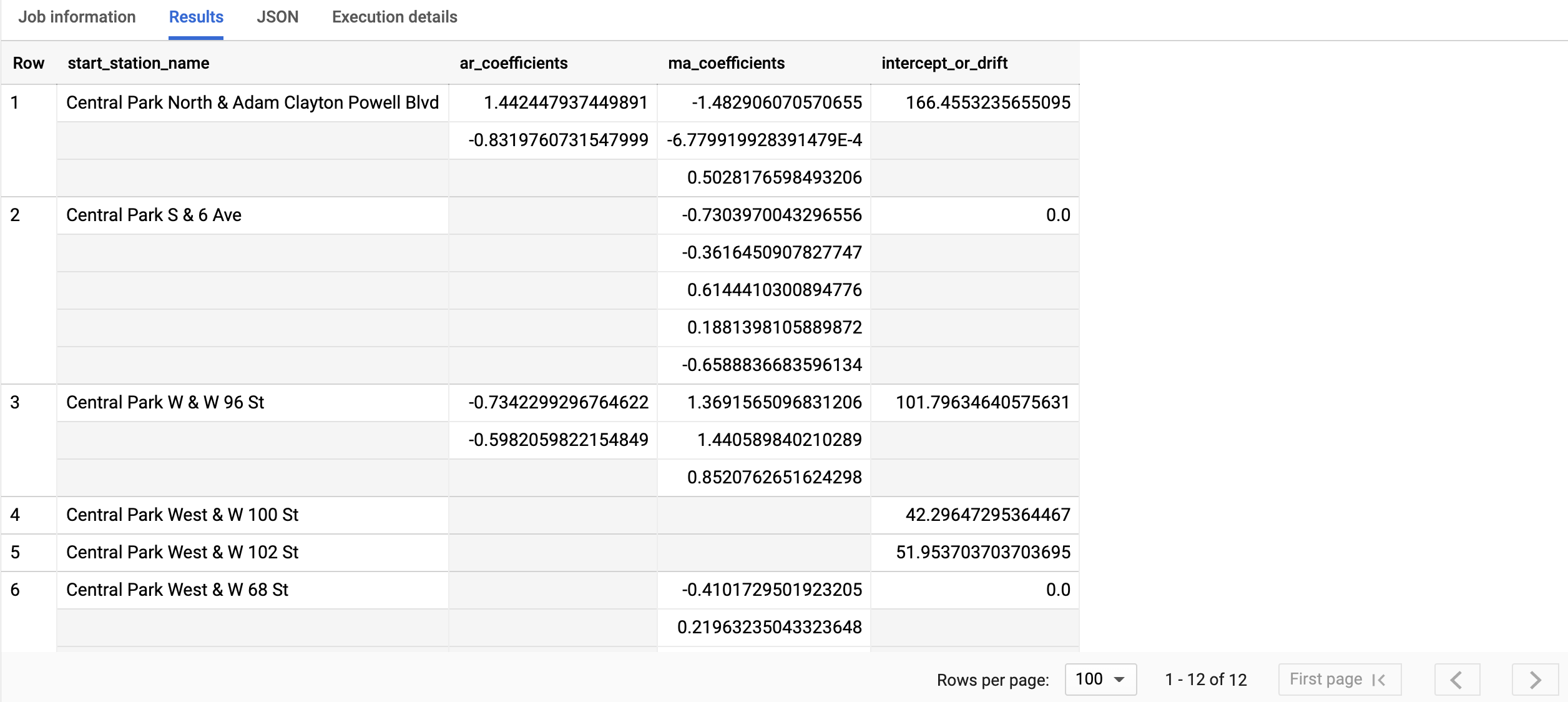
Para obtener más información sobre las columnas de salida, consulta la función
ML.ARIMA_COEFFICIENTS.
BigQuery DataFrames
Inspecciona los coeficientes del modelo de serie temporal con la función coef_.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
La columna start_station_name identifica la columna de datos de entrada para la que se han creado series temporales. Esta es la columna que especificaste en la opción time_series_id_col al crear el modelo.
La columna ar_coefficients muestra los coeficientes del modelo de la parte autorregresiva (AR) del modelo ARIMA. Del mismo modo, la columna ma_coefficients
output muestra los coeficientes del modelo de la parte de media móvil (MA) del
modelo ARIMA. Ambas columnas contienen valores de matriz cuya longitud es igual a non_seasonal_p y non_seasonal_q, respectivamente. El valor de intercept_or_drift es el término constante del modelo ARIMA.
Usar el modelo para predecir datos
SQL
Prevé valores futuros de series temporales con la función ML.FORECAST.
En la siguiente consulta de GoogleSQL, la cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) indica que la consulta prevé 3 puntos temporales futuros y genera un intervalo de predicción con un nivel de confianza del 90 %.
Sigue estos pasos para predecir datos con el modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level))
Haz clic en Ejecutar.
La consulta tarda menos de un segundo en completarse. Los resultados deberían ser similares a los siguientes:
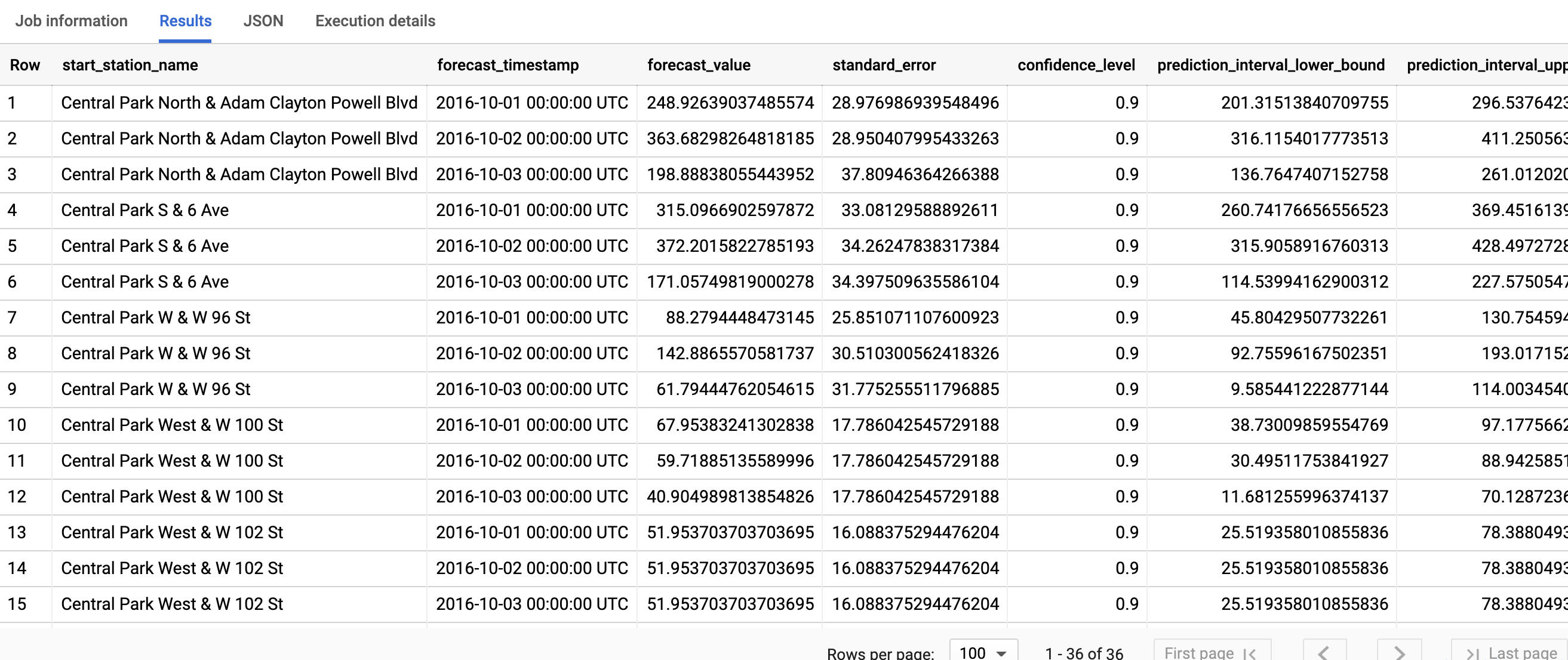
Para obtener más información sobre las columnas de salida, consulta la función ML.FORECAST.
BigQuery DataFrames
Prevé valores futuros de series temporales con la función predict.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
La primera columna, start_station_name, anota la serie temporal con la que se ajusta cada modelo de serie temporal. Cada start_station_name tiene tres filas de resultados previstos, tal como se especifica en el valor horizon.
En cada start_station_name, las filas de salida se ordenan cronológicamente por el valor de la columna forecast_timestamp. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnas prediction_interval_lower_bound y prediction_interval_upper_bound, es tan importante como el valor de la columna forecast_value. El valor forecast_value es el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnas standard_error y confidence_level.
Explicar los resultados de las previsiones
SQL
Puede obtener métricas de interpretabilidad además de datos de previsión mediante la función ML.EXPLAIN_FORECAST. La función ML.EXPLAIN_FORECAST predice los valores de series temporales futuras y también devuelve todos los componentes independientes de la serie temporal. Si solo quieres devolver datos de previsión, usa la función ML.FORECAST
en su lugar, tal como se muestra en Usar el modelo para predecir datos.
La cláusula STRUCT(3 AS horizon, 0.9 AS confidence_level) utilizada en la función ML.EXPLAIN_FORECAST indica que la consulta pronostica 3 puntos temporales futuros y genera un intervalo de predicción con una confianza del 90 %.
Sigue estos pasos para explicar los resultados del modelo:
En la Google Cloud consola, ve a la página BigQuery.
En el editor de consultas, pega la siguiente consulta y haz clic en Ejecutar:
SELECT * FROM ML.EXPLAIN_FORECAST(MODEL `bqml_tutorial.nyc_citibike_arima_model_group`, STRUCT(3 AS horizon, 0.9 AS confidence_level));
La consulta tarda menos de un segundo en completarse. Los resultados deberían ser similares a los siguientes:



Las primeras miles de filas devueltas son datos del historial. Debes desplazarte por los resultados para ver los datos de previsión.
Las filas de salida se ordenan primero por
start_station_namey, después, cronológicamente por el valor de la columnatime_series_timestamp. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnasprediction_interval_lower_boundyprediction_interval_upper_bound, es tan importante como el valor de la columnaforecast_value. El valorforecast_valuees el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnasstandard_erroryconfidence_level.Para obtener más información sobre las columnas de salida, consulta
ML.EXPLAIN_FORECAST.
BigQuery DataFrames
Puede obtener métricas de interpretabilidad además de datos de previsión mediante la función predict_explain. La función predict_explain predice los valores de series temporales futuras y también devuelve todos los componentes independientes de la serie temporal. Si solo quieres devolver datos de previsión, usa la función predict
en su lugar, tal como se muestra en Usar el modelo para predecir datos.
La cláusula horizon=3, confidence_level=0.9 utilizada en la función predict_explain indica que la consulta pronostica 3 puntos temporales futuros y genera un intervalo de predicción con una confianza del 90 %.
Antes de probar este ejemplo, sigue las instrucciones de configuración de BigQuery DataFrames que se indican en la guía de inicio rápido de BigQuery con BigQuery DataFrames. Para obtener más información, consulta la documentación de referencia de los DataFrames de BigQuery.
Para autenticarte en BigQuery, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta Configurar ADC en un entorno de desarrollo local.
Las filas de salida se ordenan primero por time_series_timestamp y, después, cronológicamente por el valor de la columna start_station_name. En la previsión de series temporales, el intervalo de predicción, representado por los valores de las columnas prediction_interval_lower_bound y prediction_interval_upper_bound, es tan importante como el valor de la columna forecast_value. El valor forecast_value es el punto medio del intervalo de predicción. El intervalo de predicción depende de los valores de las columnas standard_error y confidence_level.