
Halaman ini menjelaskan cara kerja Throughput yang Disediakan, cara mengontrol penggunaan berlebih atau melewati Throughput yang Disediakan, dan cara memantau penggunaan.
Cara kerja Throughput yang Disediakan
Bagian ini menjelaskan cara kerja Throughput yang Disediakan dengan menggunakan pemeriksaan kuota selama periode penerapan kuota.
Pemeriksaan kuota Throughput yang Disediakan
Kuota maksimum Throughput yang Disediakan adalah kelipatan dari jumlah unit penskalaan AI generatif (GSU) yang dibeli dan throughput per GSU. Hal ini diperiksa setiap kali Anda membuat permintaan dalam periode penerapan kuota, yang merupakan frekuensi penerapan kuota Throughput yang Disediakan maksimum.
Pada saat permintaan diterima, ukuran respons sebenarnya tidak diketahui. Karena kami memprioritaskan kecepatan respons untuk aplikasi real-time, Throughput yang Disediakan memperkirakan ukuran token output. Jika estimasi awal melebihi kuota maksimum Throughput yang Disediakan yang tersedia, permintaan akan diproses sebagai bayar sesuai penggunaan. Jika tidak, permintaan akan diproses sebagai Throughput yang Disediakan. Hal ini dilakukan dengan membandingkan estimasi awal dengan kuota maksimum Throughput yang Disediakan.
Saat respons dibuat dan ukuran token output sebenarnya diketahui, penggunaan dan kuota sebenarnya disesuaikan dengan menambahkan perbedaan antara perkiraan dan penggunaan sebenarnya ke jumlah kuota Throughput yang Disediakan yang tersedia.
Periode penegakan kuota Throughput yang Disediakan
Untuk model Gemini, periode penerapan kuota dapat berlangsung hingga 30 detik dan dapat berubah. Artinya, Anda mungkin mengalami traffic yang diprioritaskan untuk sementara yang melebihi jumlah kuota Anda per detik dalam beberapa kasus, tetapi Anda tidak boleh melebihi kuota Anda per 30 detik. Periode ini didasarkan pada waktu clock internal Vertex AI dan tidak bergantung pada waktu permintaan dibuat.
Misalnya, jika Anda membeli satu GSU gemini-2.0-flash-001, maka Anda
dapat mengharapkan throughput selalu aktif sebesar 3.360 token per detik. Rata-rata, Anda tidak dapat melebihi 100.800 token dalam jangka waktu 30 detik, yang dihitung menggunakan formula berikut:
3,360 tokens per second * 30 seconds = 100,800 tokens
Jika dalam sehari Anda hanya mengirimkan satu permintaan yang menggunakan 8.000 token dalam satu detik, permintaan tersebut mungkin masih diproses sebagai permintaan Throughput yang Disediakan, meskipun Anda melampaui batas 3.360 token per detik pada saat permintaan tersebut. Hal ini karena permintaan tidak melebihi batas 100.800 token per 30 detik.
Mengontrol kelebihan penggunaan atau melewati Throughput yang Disediakan
Gunakan API untuk mengontrol kelebihan penggunaan saat Anda melampaui throughput yang dibeli atau untuk melewati Throughput yang Disediakan berdasarkan per permintaan.
Baca setiap opsi untuk menentukan apa yang harus Anda lakukan untuk memenuhi kasus penggunaan Anda.
Perilaku default
Jika permintaan melebihi kuota Throughput yang Disediakan yang tersisa, seluruh permintaan akan diproses sebagai permintaan on-demand secara default dan ditagih dengan tarif bayar sesuai penggunaan. Jika hal ini terjadi, traffic akan muncul sebagai spillover di dasbor pemantauan. Untuk mengetahui informasi selengkapnya tentang pemantauan penggunaan Throughput yang Disediakan, lihat Memantau Throughput yang Disediakan.
Setelah pesanan Throughput yang Disediakan aktif, perilaku default akan terjadi secara otomatis. Anda tidak perlu mengubah kode untuk mulai menggunakan pesanan selama Anda menggunakannya di wilayah yang disediakan.
Hanya menggunakan Throughput yang Disediakan
Jika Anda mengelola biaya dengan menghindari biaya sesuai permintaan, gunakan hanya
Throughput yang Disediakan. Permintaan yang melebihi jumlah pesanan Throughput yang Disediakan akan menampilkan error 429.
Saat mengirim permintaan ke API, tetapkan header HTTP X-Vertex-AI-LLM-Request-Type ke dedicated.
Hanya menggunakan bayar sesuai penggunaan
Hal ini juga disebut sebagai penggunaan sesuai permintaan. Permintaan melewati urutan Throughput yang Disediakan dan dikirim langsung ke bayar sesuai penggunaan. Hal ini mungkin berguna untuk eksperimen atau aplikasi yang sedang dalam pengembangan.
Saat mengirim permintaan ke API, tetapkan header HTTP X-Vertex-AI-LLM-Request-Type ke shared.
Contoh
Python
Instal
pip install --upgrade google-genai
Untuk mempelajari lebih lanjut, lihat dokumentasi referensi SDK.
Tetapkan variabel lingkungan untuk menggunakan Gen AI SDK dengan Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Pelajari cara menginstal atau mengupdate Go.
Untuk mempelajari lebih lanjut, lihat dokumentasi referensi SDK.
Tetapkan variabel lingkungan untuk menggunakan Gen AI SDK dengan Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Setelah menyiapkan lingkungan, Anda dapat menggunakan REST untuk menguji perintah teks. Contoh berikut mengirim permintaan ke endpoint model penayang.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Menggunakan Throughput yang Disediakan dengan Kunci API
Jika Anda telah membeli Throughput yang Disediakan untuk project, model Google, dan region tertentu, serta ingin menggunakannya untuk mengirim permintaan dengan kunci API, Anda harus menyertakan project ID, model, lokasi, dan kunci API sebagai parameter dalam permintaan Anda.
Untuk mengetahui informasi tentang cara membuat Google Cloud kunci API yang terikat ke akun layanan, lihat Mendapatkan Google Cloud kunci API. Untuk mempelajari cara mengirim permintaan ke Gemini API menggunakan kunci API, lihat panduan memulai Gemini API di Vertex AI.
Misalnya, contoh berikut menunjukkan cara mengirim permintaan dengan kunci API saat menggunakan Throughput yang Disediakan:
REST
Setelah menyiapkan lingkungan, Anda dapat menggunakan REST untuk menguji perintah teks. Contoh berikut mengirim permintaan ke endpoint model penayang.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Memantau Throughput yang Disediakan
Anda dapat memantau sendiri penggunaan Throughput yang Disediakan menggunakan serangkaian metrik yang diukur pada jenis resource aiplatform.googleapis.com/PublisherModel.
Pemantauan traffic Throughput yang Disediakan adalah fitur Pratinjau publik.
Dimensi
Anda dapat memfilter metrik menggunakan dimensi berikut:
| Dimensi | Nilai |
|---|---|
type |
inputoutput |
request_type |
|
Awalan jalur
Awalan jalur untuk metrik adalah
aiplatform.googleapis.com/publisher/online_serving.
Misalnya, jalur lengkap untuk metrik /consumed_throughput adalah
aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Metrik
Metrik Cloud Monitoring berikut tersedia di resource aiplatform.googleapis.com/PublisherModel untuk model Gemini. Gunakan jenis permintaan dedicated untuk memfilter penggunaan Throughput yang Disediakan.
| Metrik | Nama tampilan | Deskripsi |
|---|---|---|
/dedicated_gsu_limit |
Batas (GSU) | Batas khusus di GSU. Gunakan metrik ini untuk memahami kuota maksimum Throughput yang Disediakan dalam GSU. |
/tokens |
Token | Distribusi jumlah token input dan output. |
/token_count |
Jumlah token | Jumlah token input dan output yang terakumulasi. |
/consumed_token_throughput |
Throughput token | Penggunaan throughput, yang memperhitungkan laju penyelesaian dalam token dan menggabungkan rekonsiliasi kuota. Lihat Pemeriksaan kuota Throughput yang Disediakan. Gunakan metrik ini untuk memahami cara penggunaan kuota Throughput yang Disediakan. |
/dedicated_token_limit |
Batas (token per detik) | Batas khusus dalam token per detik. Gunakan metrik ini untuk memahami kuota maksimum Throughput yang Disediakan untuk model berbasis token. |
/characters |
Karakter | Distribusi jumlah karakter input dan output. |
/character_count |
Jumlah karakter | Jumlah karakter input dan output yang terakumulasi. |
/consumed_throughput |
Throughput karakter | Penggunaan throughput, yang memperhitungkan laju penurunan dalam karakter dan menggabungkan rekonsiliasi kuota pemeriksaan kuota Throughput yang Disediakan. Gunakan metrik ini untuk memahami cara penggunaan kuota Throughput yang Disediakan. Untuk model berbasis token, metrik ini setara dengan throughput yang digunakan dalam token dikalikan dengan 4. |
/dedicated_character_limit |
Batas (karakter per detik) | Batas khusus dalam karakter per detik. Gunakan metrik ini untuk memahami kuota maksimum Throughput yang Disediakan untuk model berbasis karakter. |
/model_invocation_count |
Jumlah pemanggilan model | Jumlah pemanggilan model (permintaan prediksi). |
/model_invocation_latencies |
Latensi pemanggilan model | Latensi pemanggilan model (latensi prediksi). |
/first_token_latencies |
Latensi token pertama | Durasi dari permintaan diterima hingga token pertama ditampilkan. |
Model Anthropic juga memiliki filter untuk Throughput yang Disediakan, tetapi hanya untuk tokens dan token_count.
Dasbor
Dasbor pemantauan default untuk Throughput yang Disediakan menyediakan metrik yang memungkinkan Anda lebih memahami penggunaan dan pemanfaatan Throughput yang Disediakan. Untuk mengakses dasbor, lakukan hal berikut:
Di konsol Google Cloud , buka halaman Throughput yang Disediakan.
Untuk melihat pemanfaatan Throughput yang Disediakan dari setiap model di seluruh pesanan Anda, pilih tab Ringkasan pemanfaatan.
Di tabel Penggunaan throughput yang disediakan menurut model, Anda dapat melihat hal berikut untuk rentang waktu yang dipilih:
Jumlah total GSU yang Anda miliki.
Penggunaan throughput puncak dalam hal GSU.
Penggunaan GSU rata-rata.
Jumlah berapa kali Anda mencapai batas Throughput yang Disediakan.
Pilih model dari tabel Pemanfaatan Throughput yang Disediakan menurut model untuk melihat metrik lainnya yang khusus untuk model yang dipilih.
Cara menafsirkan dasbor pemantauan
Throughput yang Disediakan memeriksa kuota yang tersedia secara real time di tingkat milidetik untuk permintaan saat dibuat, tetapi membandingkan data ini dengan periode penerapan kuota 30 detik bergulir, berdasarkan waktu jam internal Vertex AI. Perbandingan ini tidak bergantung pada waktu saat permintaan dibuat. Dasbor pemantauan melaporkan metrik penggunaan setelah rekonsiliasi kuota dilakukan. Namun, metrik ini diagregasi untuk memberikan rata-rata untuk periode penyesuaian dasbor, berdasarkan rentang waktu yang dipilih. Perincian terendah yang didukung dasbor pemantauan adalah di tingkat menit. Selain itu, waktu jam untuk dasbor pemantauan berbeda dengan waktu jam Vertex AI.
Perbedaan waktu ini terkadang dapat menyebabkan perbedaan antara data di dasbor pemantauan dan performa real-time. Hal ini dapat terjadi karena salah satu alasan berikut:
Kouta diterapkan secara real time, tetapi diagram pemantauan menggabungkan data ke dalam periode penyelarasan dasbor rata-rata 1 menit atau lebih tinggi, bergantung pada rentang waktu yang ditentukan di dasbor pemantauan.
Vertex AI dan dasbor pemantauan berjalan di clock sistem yang berbeda.
Jika lonjakan traffic selama periode 1 detik melebihi kuota Throughput yang Disediakan, seluruh permintaan akan diproses sebagai traffic pelimpahan. Namun, pemanfaatan Throughput yang Disediakan secara keseluruhan mungkin tampak rendah saat data pemantauan untuk detik tersebut dirata-ratakan dalam periode penyesuaian 1 menit, karena pemanfaatan rata-rata di seluruh periode penyesuaian mungkin tidak melebihi 100%. Jika Anda melihat traffic pelimpahan, hal ini mengonfirmasi bahwa kuota Throughput yang Disediakan Anda telah digunakan sepenuhnya selama periode penegakan kuota saat permintaan tertentu tersebut dibuat. Hal ini terlepas dari penggunaan rata-rata yang ditampilkan di dasbor pemantauan.
Contoh potensi perbedaan dalam data pemantauan
Contoh ini menggambarkan beberapa perbedaan yang disebabkan oleh ketidakselarasan jendela. Gambar 1 menunjukkan penggunaan throughput selama jangka waktu tertentu. Dalam gambar ini:
Batang biru mewakili traffic yang diizinkan sebagai Throughput yang Disediakan.
Batang oranye mewakili traffic yang mendorong penggunaan melampaui batas GSU dan diproses sebagai pelimpahan.
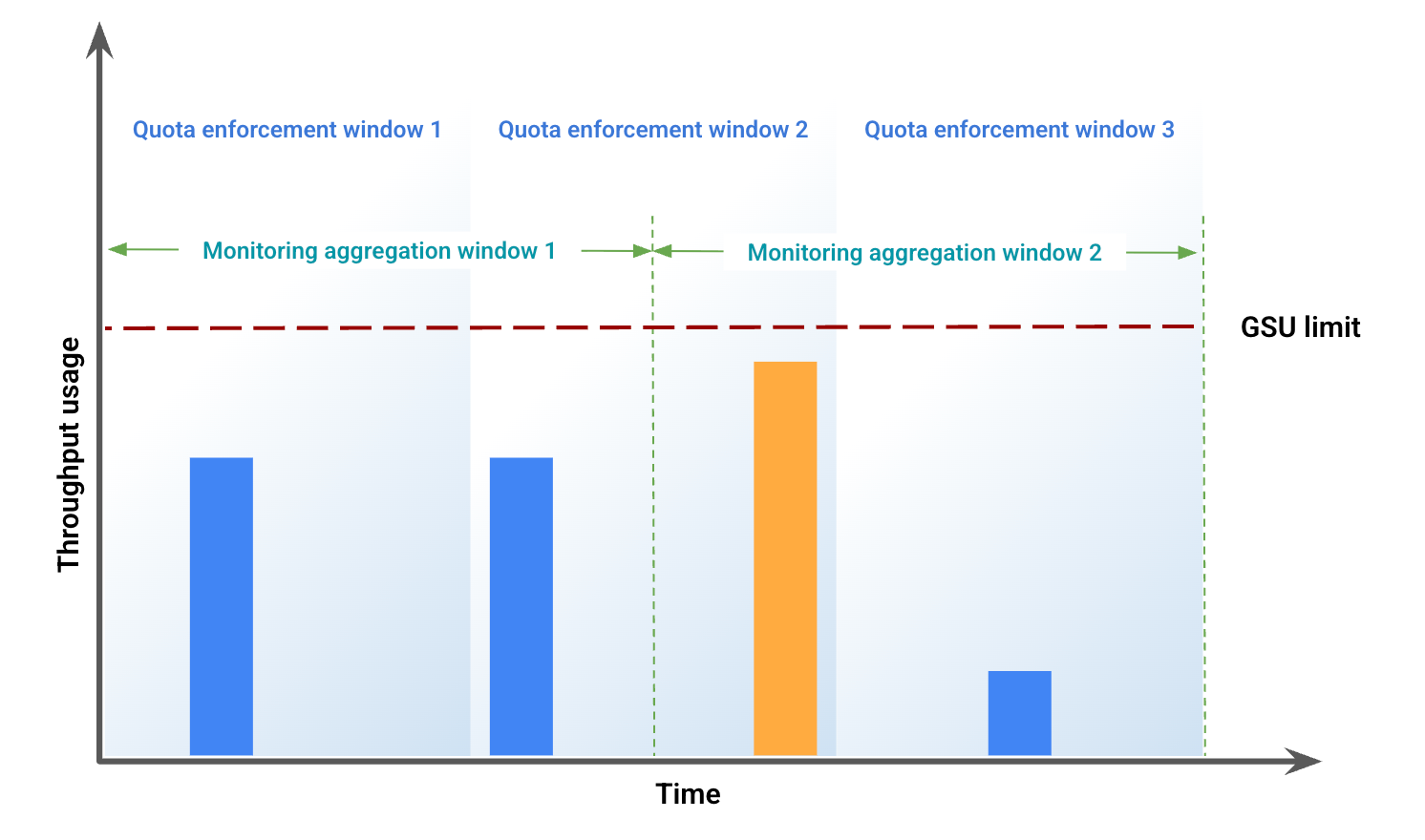
Berdasarkan penggunaan throughput, gambar 2 menunjukkan kemungkinan perbedaan visual, karena ketidakselarasan windowing. Dalam gambar ini:
Garis biru menunjukkan traffic Throughput yang Disediakan.
Garis oranye mewakili traffic peluberan.
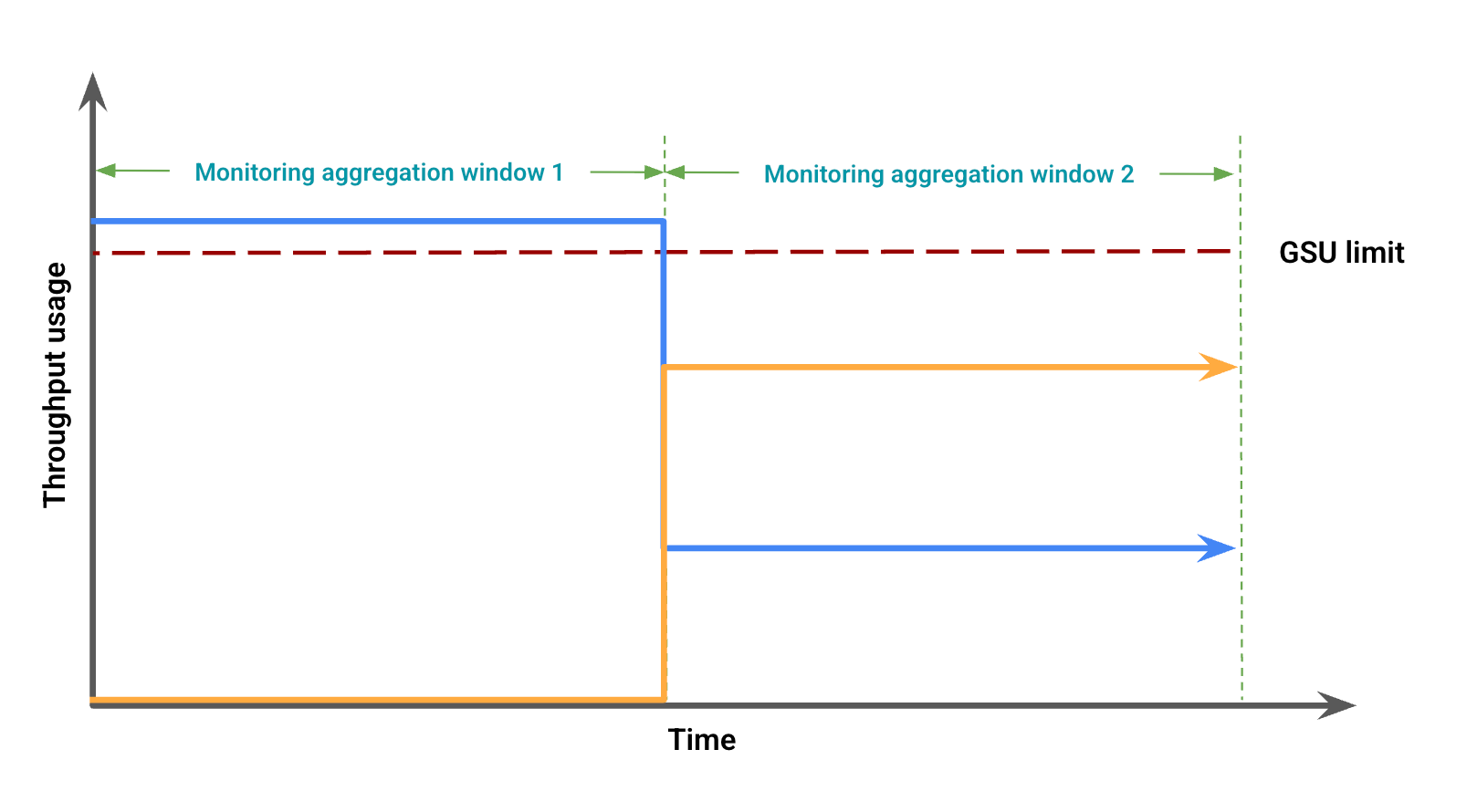
Dalam hal ini, data pemantauan mungkin menunjukkan penggunaan Throughput yang Disediakan tanpa peluapan untuk jangka waktu agregasi pemantauan, sekaligus mengamati penggunaan Throughput yang Disediakan di bawah batas GSU yang bertepatan dengan peluapan dalam jangka waktu agregasi pemantauan lainnya.
Memecahkan masalah dasbor pemantauan
Anda dapat memecahkan masalah peluapan yang tidak terduga di dasbor atau error 429 dengan melakukan langkah-langkah berikut:
Perbesar: Tetapkan rentang waktu dasbor Anda ke 12 jam atau kurang untuk memberikan periode penyelarasan paling terperinci, yaitu 1 menit. Rentang waktu yang besar akan meratakan lonjakan yang menyebabkan pembatasan dan meningkatkan rata-rata periode penyelarasan.
Periksa Total Traffic: Dasbor khusus model Anda menampilkan traffic khusus dan pelimpahan sebagai dua baris terpisah, yang dapat menyebabkan kesimpulan yang salah bahwa kuota Throughput yang Disediakan tidak sepenuhnya digunakan dan melimpah sebelum waktunya. Jika traffic Anda melebihi kuota yang tersedia, seluruh permintaan akan diproses sebagai pelimpahan. Untuk visualisasi lain yang berguna, tambahkan kueri ke dasbor menggunakan Metrics Explorer dan sertakan throughput token untuk model dan region tertentu. Jangan sertakan agregasi atau filter tambahan untuk melihat total traffic di semua jenis traffic (khusus, sisa, dan bersama).
Memantau model Genmedia
Pemantauan Throughput yang Disediakan tidak tersedia di model Veo 3 dan Imagen.
Pemberitahuan
Setelah peringatan diaktifkan, tetapkan peringatan default untuk membantu Anda mengelola penggunaan traffic.
Aktifkan notifikasi
Untuk mengaktifkan pemberitahuan di dasbor, lakukan tindakan berikut:
Di konsol Google Cloud , buka halaman Throughput yang Disediakan.
Untuk melihat pemanfaatan Throughput yang Disediakan dari setiap model di seluruh pesanan Anda, pilih tab Ringkasan pemanfaatan.
Pilih Notifikasi yang direkomendasikan, dan notifikasi berikut akan ditampilkan:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Periksa peringatan yang membantu Anda mengelola traffic.
Melihat detail notifikasi lainnya
Untuk melihat informasi selengkapnya tentang pemberitahuan, lakukan tindakan berikut:
Buka halaman Integrasi.
Masukkan vertex ke kolom Filter, lalu tekan Enter. Google Vertex AI akan muncul.
Untuk melihat informasi selengkapnya, klik Lihat detail. Panel Detail Google Vertex AI akan ditampilkan.
Pilih tab Pemberitahuan, lalu Anda dapat memilih template Kebijakan Pemberitahuan.
Langkah berikutnya
- Memecahkan masalah Kode error
429.