
Esta página explica como a capacidade de processamento provisionada funciona, como controlar excedentes ou ignorar a capacidade de processamento provisionada e como monitorar o uso.
Como funciona a capacidade de processamento provisionada
Esta seção explica como a capacidade de processamento provisionada funciona usando a verificação de cota durante o período de aplicação da cota.
Verificação da cota de capacidade de processamento provisionada
Sua cota máxima de capacidade de processamento provisionada é um múltiplo do número de unidades de escalonamento de IA generativa (GSUs) compradas e da capacidade de processamento por GSU. Ele é verificado sempre que você faz uma solicitação no seu período de aplicação de cota, que é a frequência com que a cota máxima de capacidade de transferência provisionada é aplicada.
Quando uma solicitação é recebida, o tamanho real da resposta é desconhecido. Como priorizamos a velocidade de resposta para aplicativos em tempo real, a capacidade de processamento provisionada estima o tamanho do token de saída. Se a estimativa inicial exceder a cota máxima disponível de capacidade de processamento provisionada, a solicitação será processada como pagamento por uso. Caso contrário, ela será processada como capacidade de processamento provisionada. Isso é feito comparando a estimativa inicial com a cota máxima de capacidade de processamento provisionada.
Quando a resposta é gerada e o tamanho real do token de saída é conhecido, o uso e a cota reais são reconciliados adicionando a diferença entre a estimativa e o uso real ao valor da cota de capacidade de transmissão provisionada disponível.
Janelas de aplicação da cota de capacidade de processamento provisionada
A Vertex AI aplica uma janela dinâmica ao aplicar a cota de capacidade de transmissão provisionada para modelos do Gemini. Isso oferece estabilidade ideal para tráfego propenso a picos. Em vez de uma janela fixa, a Vertex AI aplica a cota em uma janela flexível que se ajusta automaticamente, dependendo do tipo de modelo e do número de GSUs que você provisionou. Como resultado, talvez você tenha temporariamente um tráfego prioritário que exceda o valor da sua cota por segundo em alguns casos. No entanto, não é permitido exceder a cota durante o período. Esses períodos são baseados no tempo do relógio interno da Vertex AI e são independentes de quando as solicitações são feitas.
Como funciona a janela de aplicação de cotas
A janela de aplicação determina o quanto você pode exceder, ou "aumentar", acima do limite por segundo antes de ser limitado. Essa janela é aplicada automaticamente. Essas janelas estão sujeitas a mudanças para otimizar a performance e a confiabilidade.
Alocações pequenas de GSU (3 GSUs ou menos): a janela pode variar de 40 a 120 segundos para permitir que solicitações individuais maiores sejam processadas sem interrupção.
Por exemplo, se você comprar uma GSU do
gemini-2.5-flash, vai receber uma média de 2.690 tokens por segundo de capacidade de processamento contínua. O uso total em qualquer janela de 120 segundos não pode exceder 322.800 tokens (2.690 tokens por segundo * 120 segundos). Portanto, se você enviar uma solicitação que usa 70.000 tokens por segundo, mas o uso total em 120 segundos permanecer abaixo de 322.800 tokens, a taxa de 70.000 tokens por segundo ainda será considerada capacidade de processamento provisionada, já que o uso médio não excede 2.690 tokens por segundo.Alocações padrão (tamanho médio) de GSU (mais de 3 GSUs): para implantações de GSU de tamanho médio (por exemplo, menos de 50 GSUs), a janela pode variar de 5 a 30 segundos. Os limites da GSU e as janelas de contexto variam de acordo com o modelo.
Por exemplo, se você comprar 25 GSUs de
gemini-2.5-flash, vai receber uma média de 67.250 tokens por segundo (2.690 tokens por segundo * 25) de capacidade de processamento contínua. O uso total em qualquer janela de 30 segundos não pode exceder 2.017.500 tokens (67.250 tokens por segundo * 30 segundos). Portanto, se você enviar uma solicitação que usa 1.000.000 de tokens por segundo, mas o uso total em 30 segundos permanecer dentro de 2.017.500 tokens, a explosão de 1.000.000 de tokens por segundo ainda será considerada capacidade de processamento provisionada, já que o uso médio não excede 67.250 tokens por segundo.Alocações de GSU de alta precisão (em grande escala): para implantações de GSU em grande escala (por exemplo, 50 GSUs ou mais), a janela pode variar de 1 a 5 segundos para garantir que as solicitações de alta frequência sejam processadas com a máxima precisão em toda a infraestrutura.
Por exemplo, se você comprar 250 GSUs de
gemini-2.5-flash, vai receber uma média de 672.500 tokens por segundo (2.690 tokens por segundo * 250) de capacidade de processamento contínua. O uso total em qualquer janela de 5 segundos não pode exceder 3.362.500 tokens (672.500 tokens por segundo * 5 segundos). Portanto, se você enviar uma solicitação que usa 5.000.000 de tokens por segundo, ela não será processada como capacidade de processamento provisionada, porque o uso total de 5.000.000 de tokens excede o limite de 3.362.500 tokens em uma janela de 5 segundos. Por outro lado, uma solicitação que usa 1.000.000 de tokens por segundo pode ser processada como capacidade de processamento provisionada se o uso médio na janela de 5 segundos não exceder 672.500 tokens por segundo.
Controlar excedentes ou ignorar a capacidade de processamento provisionada
Use a API para controlar excedentes quando você exceder a capacidade de processamento comprada ou para ignorar a capacidade de processamento provisionada por solicitação.
Leia cada opção para determinar o que você precisa fazer para atender ao seu caso de uso.
Comportamento padrão
Se uma solicitação exceder a cota restante de capacidade de processamento provisionada, ela será processada como uma solicitação sob demanda por padrão e será cobrada de acordo com a taxa de pagamento por uso. Quando isso acontece, o tráfego aparece como transbordamento nos painéis de monitoramento. Para mais informações sobre como monitorar o uso da capacidade de processamento provisionada, consulte Monitorar a capacidade de processamento provisionada.
Depois que o pedido de capacidade de processamento provisionada estiver ativo, o comportamento padrão vai ocorrer automaticamente. Não é preciso mudar o código para começar a consumir seu pedido, desde que ele seja consumido na região provisionada.
Usar apenas a capacidade de processamento provisionada
Se você estiver gerenciando custos evitando cobranças sob demanda, use apenas a capacidade de processamento provisionada. Solicitações que excedem o valor do pedido de capacidade de processamento provisionada retornam um erro 429.
Ao enviar solicitações para a API, defina o cabeçalho HTTP X-Vertex-AI-LLM-Request-Type como dedicated.
Usar apenas o pagamento por uso
Isso também é chamado de uso sob demanda. As solicitações ignoram o pedido de capacidade de processamento provisionada e são enviadas diretamente para o pagamento por uso. Isso pode ser útil para experimentos ou aplicativos que estão em desenvolvimento.
Ao enviar solicitações para a API, defina o cabeçalho HTTP X-Vertex-AI-LLM-Request-Type como shared.
Exemplo
Python
Instalar
pip install --upgrade google-genai
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Saiba como instalar ou atualizar o Go.
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Instalar
npm install @google/genai
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Saiba como instalar ou atualizar o Java.
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA generativa com a Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Depois de configurou seu ambiente use REST para testar uma solicitação de texto. O exemplo a seguir envia uma solicitação ao publisher endpoint do modelo.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Usar a capacidade de processamento provisionada com uma chave de API
Se você comprou a taxa de transferência provisionada para um projeto, modelo do Google e região específicos e quer usá-la para enviar uma solicitação com uma chave de API, inclua o ID do projeto, o modelo, o local e a chave de API como parâmetros na solicitação.
Para informações sobre como criar uma Google Cloud chave de API vinculada a uma conta de serviço, consulte Receber uma Google Cloud chave de API. Para saber como enviar solicitações à API Gemini usando uma chave de API, consulte o Guia de início rápido da API Gemini na Vertex AI.
Por exemplo, a amostra a seguir mostra como enviar uma solicitação com uma chave de API ao usar a capacidade de transferência provisionada:
REST
Depois de configurou seu ambiente use REST para testar uma solicitação de texto. O exemplo a seguir envia uma solicitação ao publisher endpoint do modelo.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Monitorar a capacidade de processamento provisionada
É possível monitorar o uso da capacidade de processamento provisionada usando um conjunto
de métricas medidas no tipo de recurso aiplatform.googleapis.com/PublisherModel.
O monitoramento de tráfego de capacidade de processamento provisionada é um recurso de pré-lançamento público.
Dimensões
É possível filtrar as métricas usando as seguintes dimensões:
| Dimensão | Valores |
|---|---|
type |
inputoutput |
request_type |
|
Prefixo do caminho
O prefixo do caminho de uma métrica é
aiplatform.googleapis.com/publisher/online_serving.
Por exemplo, o caminho completo da métrica /consumed_throughput é
aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Métricas
As seguintes métricas do Cloud Monitoring estão disponíveis no recurso aiplatform.googleapis.com/PublisherModel para os modelos do Gemini. Use os tipos de solicitação dedicated para filtrar o uso da capacidade de processamento provisionada.
| Métrica | Nome de exibição | Descrição |
|---|---|---|
/dedicated_gsu_limit |
Limite (GSU) | Limite dedicado em GSUs. Use essa métrica para entender sua cota máxima de capacidade de processamento provisionada em GSUs. |
/tokens |
Tokens | Distribuição da contagem de tokens de entrada e saída. |
/token_count |
Contagem de tokens | Contagem acumulada de tokens de entrada e saída. |
/consumed_token_throughput |
Capacidade de processamento de tokens | Uso da capacidade de processamento, que considera a taxa de burndown em tokens e incorpora a conciliação de cotas. Consulte Verificação da cota de capacidade de processamento provisionada. Use essa métrica para entender como sua cota de capacidade de processamento provisionada foi usada. |
/dedicated_token_limit |
Limite (tokens por segundo) | Limite dedicado em tokens por segundo. Use essa métrica para entender sua cota máxima de capacidade de processamento provisionada para modelos baseados em tokens. |
/characters |
Caracteres | Distribuição de contagem de caracteres de entrada e saída. |
/character_count |
Contagem de caracteres | Contagem de caracteres de entrada e saída acumulados. |
/consumed_throughput |
Capacidade de processamento de caracteres | Uso da capacidade de processamento, que considera a taxa de burndown em caracteres e incorpora a reconciliação de cota Verificação de cota de capacidade de processamento provisionada. Use essa métrica para entender como sua cota de capacidade de processamento provisionada foi usada. Para modelos baseados em tokens, essa métrica é equivalente à taxa de transferência consumida em tokens multiplicada por 4. |
/dedicated_character_limit |
Limite (caracteres por segundo) | Limite dedicado em caracteres por segundo. Use essa métrica para entender sua cota máxima de capacidade de processamento provisionada para modelos baseados em caracteres. |
/model_invocation_count |
Contagem de invocações de modelo | Número de invocações de modelo (solicitações de previsão). |
/model_invocation_latencies |
Latências de invocação de modelo | Latências de invocação de modelo (latências de previsão). |
/first_token_latencies |
Latências do primeiro token | Duração da solicitação recebida até o primeiro token retornado. |
Os modelos da Anthropic também têm um filtro para capacidade de processamento provisionada, mas apenas para tokens e token_count.
Painéis
Os painéis de monitoramento padrão para capacidade de processamento provisionada fornecem métricas que ajudam a entender melhor o uso e a utilização da capacidade de processamento provisionada. Para acessar os painéis, faça o seguinte:
No console Google Cloud , acesse a página Capacidade de processamento provisionada.
Para conferir o uso da capacidade de processamento provisionada de cada modelo em todos os seus pedidos, selecione a guia Resumo de uso.
Na tabela Utilização da capacidade de processamento provisionada por modelo, é possível conferir o seguinte para o período selecionado:
Número total de GSUs que você tinha.
Pico de uso da capacidade de processamento em termos de GSUs.
O uso médio da GSU.
O número de vezes que você atingiu o limite de capacidade de transferência provisionada.
Selecione um modelo na tabela Utilização da capacidade de processamento provisionada por modelo para conferir mais métricas específicas dele.
Como interpretar painéis de monitoramento
O throughput provisionado verifica a cota disponível em tempo real no nível de milissegundos para solicitações conforme elas são feitas, mas compara esses dados com um período de aplicação de cota contínuo, com base no tempo do relógio interno da Vertex AI. Essa comparação é independente do momento em que as solicitações são feitas. Os painéis de monitoramento informam métricas de uso após a reconciliação de cotas. No entanto, elas são agregadas para fornecer médias de períodos de alinhamento do painel com base no intervalo de tempo selecionado. A menor granularidade possível compatível com os painéis de monitoramento é no nível de minutos. Além disso, o tempo real dos painéis de monitoramento é diferente do da Vertex AI.
Essas diferenças de tempo podem resultar em discrepâncias entre os dados nos painéis de monitoramento e a performance em tempo real. Isso pode acontecer por um dos seguintes motivos:
A cota é aplicada em tempo real, mas os gráficos de monitoramento agregam dados em períodos de alinhamento do painel de 1 minuto ou mais, dependendo do período especificado nos painéis de monitoramento.
A Vertex AI e os painéis de monitoramento são executados em relógios de sistema diferentes.
Em um período de um segundo, se um pico de tráfego exceder sua cota de capacidade de processamento provisionada com base na janela de aplicação, toda a solicitação será processada como tráfego excedente. No entanto, a utilização geral da capacidade de processamento provisionada pode parecer baixa quando os dados de monitoramento desse segundo são calculados na média dentro do período de alinhamento de um minuto, porque a utilização média em todo o período de alinhamento pode não exceder 100%. Se você notar um aumento no tráfego, isso confirma que sua cota de capacidade de processamento provisionada foi totalmente utilizada durante o período de aplicação da cota em que essas solicitações específicas foram feitas. Isso independe do uso médio mostrado nos painéis de monitoramento.
Exemplo de possível discrepância nos dados de monitoramento
Este exemplo ilustra algumas das discrepâncias resultantes do desalinhamento de janelas. A Figura 1 representa o uso da capacidade de processamento em um período específico. Nesta figura:
As barras azuis representam o tráfego admitido como taxa de transferência provisionada.
A barra laranja representa o tráfego que ultrapassa o limite da GSU e é processado como transbordamento.
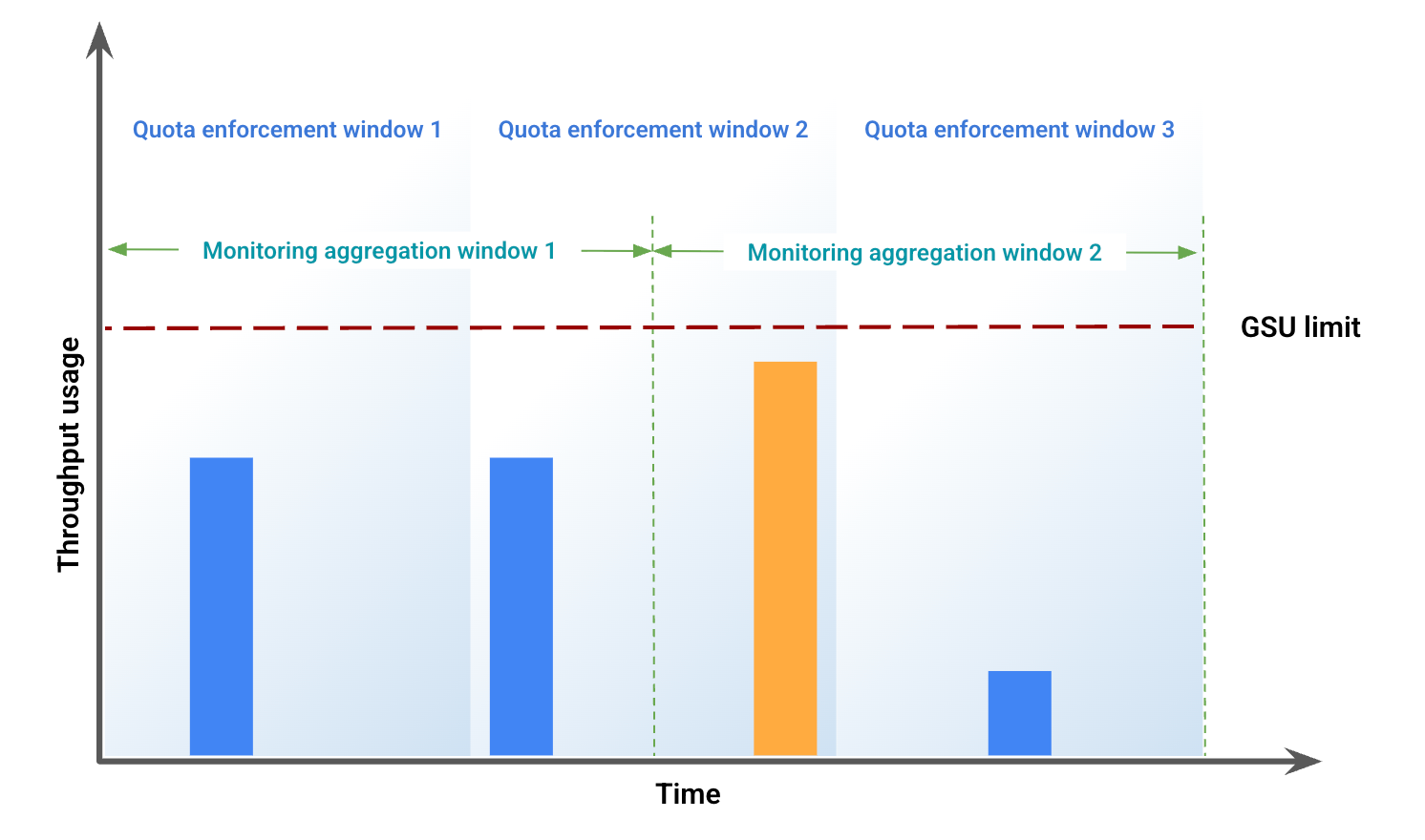
Com base no uso da taxa de transferência, a Figura 2 representa possíveis discrepâncias visuais devido ao desalinhamento de janelas. Nesta figura:
A linha azul representa o tráfego de capacidade de processamento provisionada.
A linha laranja representa o tráfego de transbordamento.

Nesse caso, os dados de monitoramento podem mostrar o uso da capacidade de transmissão provisionada sem estouro em um período de agregação de monitoramento, enquanto observam simultaneamente o uso da capacidade de transmissão provisionada abaixo do limite da GSU, coincidindo com um estouro em outro período de agregação de monitoramento.
Resolver problemas em painéis de monitoramento
Para resolver problemas de transbordamento inesperado nos seus painéis ou erros 429, siga estas etapas:
Ampliar: defina o período do painel como 12 horas ou menos para fornecer o período de alinhamento mais granular de 1 minuto. Intervalos de tempo grandes suavizam picos que causam limitação e aumentam as médias do período de alinhamento.
Verifique o tráfego total: os painéis específicos do modelo mostram o tráfego dedicado e de transbordamento como duas linhas separadas, o que pode levar à conclusão incorreta de que a cota de capacidade de processamento provisionada não está sendo totalmente utilizada e está transbordando prematuramente. Se o tráfego exceder a cota disponível, toda a solicitação será processada como transbordamento. Para outra visualização útil, adicione uma consulta ao painel usando o Metrics Explorer e inclua a taxa de transferência de tokens para o modelo e a região específicos. Não inclua outras agregações ou filtros para ver o tráfego total em todos os tipos de tráfego (dedicado, transbordamento e compartilhado).
Monitorar modelos de Genmedia
O monitoramento da capacidade de processamento provisionada não está disponível nos modelos Veo 3 e Imagen.
Alertas
Depois de ativar os alertas, defina os padrões para ajudar a gerenciar o uso do tráfego.
Ativar alertas
Para ativar os alertas no painel, faça o seguinte:
No console Google Cloud , acesse a página Capacidade de processamento provisionada.
Para conferir o uso da capacidade de processamento provisionada de cada modelo em todos os seus pedidos, selecione a guia Resumo de uso.
Selecione Alertas recomendados. Os seguintes alertas vão aparecer:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Confira os alertas que ajudam você a gerenciar seu tráfego.
Ver mais detalhes do alerta
Para mais informações sobre os alertas, faça o seguinte:
Acesse a página Integrações.
Digite vertex no campo Filtro e pressione Enter. A opção Google Vertex AI aparece.
Para mais informações, clique em Ver detalhes. O painel Detalhes da Vertex AI do Google é exibido.
Selecione a guia Alertas e escolha um modelo de Política de alertas.
A seguir
- Resolva problemas do código de erro
429.