
本頁說明預先佈建輸送量的運作方式、如何控管溢出或略過預先佈建輸送量,以及如何監控用量。
佈建輸送量的運作方式
本節說明「佈建輸送量」的運作方式,包括在配額強制執行期間檢查配額。
檢查佈建輸送量配額
佈建處理量配額上限是您購買的生成式 AI 擴充單元 (GSU) 數量,以及每個 GSU 的處理量倍數。系統會在配額強制執行週期內,每次您提出要求時進行檢查。配額強制執行週期是指強制執行最高佈建輸送量配額的頻率。
收到要求時,系統並不知道實際的回應大小。由於我們優先考量即時應用程式的回覆速度,因此「預先佈建輸送量」會估算輸出權杖大小。如果初始預估值超過可用的佈建傳輸量上限配額,系統會以即付即用方式處理要求。否則,系統會以佈建傳輸量方式處理要求。方法是比較初始預估值與佈建處理量的配額上限。
系統產生回應並得知實際輸出權杖大小後,會將預估用量與實際用量之間的差額加到可用的已佈建處理量配額金額,藉此調整實際用量和配額。
佈建輸送量配額強制執行期
對於 Gemini 模型,配額強制執行期最多可能需要 30 秒,且可能會變更。也就是說,在某些情況下,您可能會暫時遇到優先流量,每秒超過配額量,但每 30 秒不應超過配額。這些時間範圍是以 Vertex AI 內部時鐘時間為準,與提出要求的時間無關。
舉例來說,如果您購買 1 個 GSU 的 gemini-2.0-flash-001,則應預期每秒 3,360 個符記的持續輸送量。平均來說,每 30 秒不得超過 100,800 個權杖,計算公式如下:
3,360 tokens per second * 30 seconds = 100,800 tokens
假設您在一天內只提交一個要求,且該要求在一秒內耗用 8,000 個權杖,即使您在提出要求時超過每秒 3,360 個權杖的限制,系統仍可能會將該要求視為佈建輸送量要求。這是因為要求未超過每 30 秒 100,800 個符記的門檻。
控管超額用量或略過佈建的處理量
使用 API 控制超出購買處理量的用量,或以要求為單位略過佈建處理量。
請詳閱每個選項,判斷必須採取哪些行動才能滿足您的用途。
預設行為
如果要求超出剩餘的佈建處理量配額,系統預設會將整個要求視為隨選要求處理,並按即付即用費率計費。發生這種情況時,監控資訊主頁會將流量顯示為「溢出」。如要進一步瞭解如何監控佈建輸送量用量,請參閱「監控佈建輸送量」。
佈建輸送量訂單生效後,系統會自動執行預設行為。只要在佈建區域使用訂單,就不必變更程式碼。
僅使用佈建輸送量
如要避免支付隨選費用來控管成本,請只使用佈建輸送量。如果要求超出佈建輸送量訂單金額,系統會傳回錯誤 429。
向 API 傳送要求時,請將 X-Vertex-AI-LLM-Request-Type HTTP 標頭設為 dedicated。
僅使用即付即用方案
這也稱為使用隨選功能。要求會略過「佈建輸送量」訂單,直接以隨用隨付方式傳送。這可能適用於實驗或開發中的應用程式。
傳送要求至 API 時,請將 X-Vertex-AI-LLM-Request-Type HTTP 標頭設為 shared。
範例
Python
安裝
pip install --upgrade google-genai
詳情請參閱 SDK 參考說明文件。
設定環境變數,透過 Vertex AI 使用 Gen AI SDK:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
瞭解如何安裝或更新 Go。
詳情請參閱 SDK 參考說明文件。
設定環境變數,透過 Vertex AI 使用 Gen AI SDK:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
設定環境後,您可以使用 REST 測試文字提示。下列範例會將要求傳送至發布商模型端點。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
搭配 API 金鑰使用佈建輸送量
如果您已為特定專案、Google 模型和區域購買佈建輸送量,並想使用該輸送量透過 API 金鑰傳送要求,則必須在要求中加入專案 ID、模型、位置和 API 金鑰做為參數。
如要瞭解如何建立 Google Cloud 與服務帳戶繫結的 API 金鑰,請參閱「取得 Google Cloud API 金鑰」。如要瞭解如何使用 API 金鑰將要求傳送至 Gemini API,請參閱 Vertex AI 的 Gemini API 快速入門導覽課程。
舉例來說,下列範例說明如何在使用佈建輸送量時,透過 API 金鑰提交要求:
REST
設定環境後,您可以使用 REST 測試文字提示。下列範例會將要求傳送至發布商模型端點。
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
監控佈建輸送量
您可以透過一組指標自行監控佈建輸送量用量,這些指標是在 aiplatform.googleapis.com/PublisherModel 資源類型上測量。
佈建輸送量流量監控功能為公開預先發布版。
維度
您可以使用下列維度篩選指標:
| 尺寸 | 值 |
|---|---|
type |
inputoutput |
request_type |
|
路徑前置字串
指標的路徑前置字串為 aiplatform.googleapis.com/publisher/online_serving。
舉例來說,/consumed_throughput 指標的完整路徑為 aiplatform.googleapis.com/publisher/online_serving/consumed_throughput。
指標
您可以在 aiplatform.googleapis.com/PublisherModel 資源上查看 Gemini 模型適用的下列 Cloud Monitoring 指標。使用 dedicated 要求類型,篩選出佈建輸送量用量。
| 指標 | 顯示名稱 | 說明 |
|---|---|---|
/dedicated_gsu_limit |
限制 (GSU) | 專屬 GSU 限制。這項指標可協助您瞭解 GSU 中佈建輸送量的配額上限。 |
/tokens |
權杖 | 輸入和輸出詞元數量分布。 |
/token_count |
符記數量 | 累積的輸入和輸出詞元數量。 |
/consumed_token_throughput |
詞元處理量 | 總處理量用量,其中包含權杖的消耗率和配額對帳。請參閱「佈建的處理量配額檢查」。 使用這項指標瞭解佈建的處理量配額用量。 |
/dedicated_token_limit |
上限 (每秒權杖數) | 每秒詞元數的專屬限制。使用這項指標,瞭解以權杖為準的模型佈建處理量配額上限。 |
/characters |
字元 | 輸入和輸出字元數分布情形。 |
/character_count |
字元數 | 累積的輸入和輸出字元數。 |
/consumed_throughput |
字元處理量 | 總處理量用量,其中包含字元消耗率,並納入配額對帳 佈建總處理量配額檢查。 使用這項指標,瞭解已佈建的處理量配額使用情形。 如果是以權杖為準的模型,這項指標相當於以權杖為單位計算的耗用量乘以 4。 |
/dedicated_character_limit |
上限 (每秒字元數) | 每秒字元數的專屬限制。這項指標可協助您瞭解字元型模型的佈建輸送量配額上限。 |
/model_invocation_count |
模型叫用次數 | 模型調用次數 (預測要求)。 |
/model_invocation_latencies |
模型叫用延遲 | 模型叫用延遲時間 (預測延遲時間)。 |
/first_token_latencies |
第一個權杖的延遲時間 | 從收到要求到傳回第一個權杖的時間長度。 |
Anthropic 模型也有佈建處理量的篩選器,但僅適用於 tokens 和 token_count。
資訊主頁
佈建輸送量的預設監控資訊主頁提供指標,可協助您進一步瞭解用量和佈建輸送量使用率。如要存取資訊主頁,請按照下列步驟操作:
前往 Google Cloud 控制台的「佈建輸送量」頁面。
如要查看所有訂單中個別模型的佈建輸送量使用率,請選取「使用率摘要」分頁。
在「各模型的佈建輸送量使用情形」表格中,您可以查看所選時間範圍的下列資訊:
您擁有的 GSU 總數。
以 GSU 為單位的尖峰處理量用量。
平均 GSU 使用率。
達到佈建輸送量上限的次數。
從「Provisioned Throughput utilization by model」(模型提供的處理量使用率) 表格中選取模型,即可查看所選模型的更多指標。
如何解讀監控資訊主頁
系統會以毫秒為單位,在要求提出時即時檢查可用配額,但會根據 Vertex AI 內部時鐘時間,將這項資料與 30 秒的配額強制執行期進行比較。這項比較與提出要求的時間無關。配額對帳完成後,監控資訊主頁就會回報用量指標。不過,系統會根據所選時間範圍,匯總這些指標,提供資訊主頁對齊週期的平均值。監控資訊主頁支援的最低精細度為分鐘層級。此外,監控資訊主頁的時鐘時間與 Vertex AI 不同。
時間差有時會導致監控資訊主頁中的資料與即時成效不一致。可能原因如下:
系統會即時強制執行配額,但監控圖表會將資料匯總為 1 分鐘或更高的平均資訊主頁對齊週期,視監控資訊主頁中指定的時間範圍而定。
Vertex AI 和監控資訊主頁使用不同的系統時鐘。
如果 1 秒內的流量爆增,導致超過佈建處理量配額,系統會將整個要求視為溢出流量處理。不過,如果該秒的監控資料是在 1 分鐘的對齊期間內平均計算,整體佈建的處理量用量可能會偏低,因為整個對齊期間的平均用量可能不會超過 100%。如果看到溢出流量,表示在配額強制執行期間,當這些特定要求提出時,您已充分運用佈建輸送量配額。無論監控資訊主頁顯示的平均使用率為何,都會發生這種情況。
監控資料可能出現差異的範例
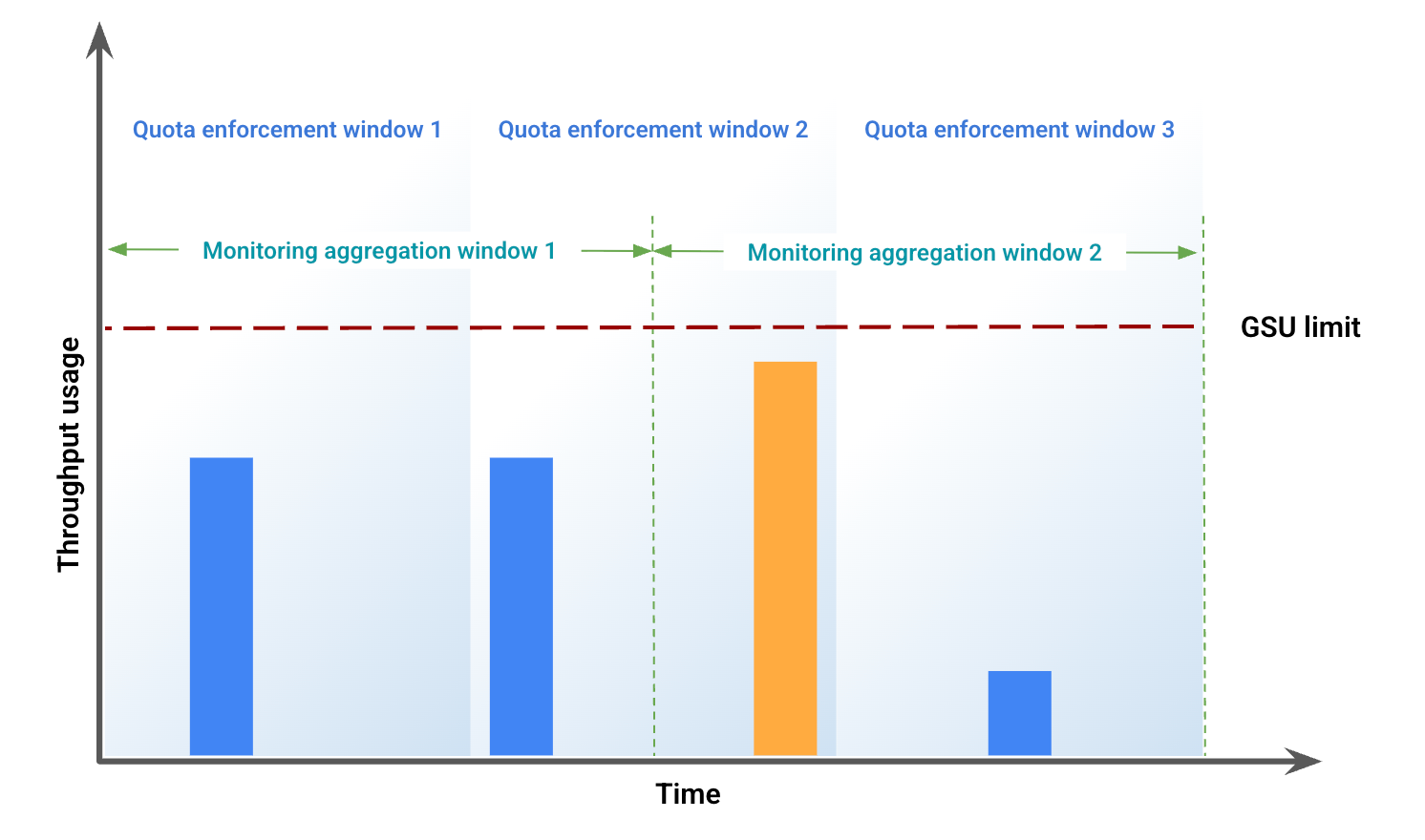
這個範例說明視窗未對齊所導致的部分差異。圖 1 顯示特定時間範圍內的輸送量用量。在這張圖中:
藍色長條代表以佈建輸送量形式接受的流量。
橘色長條代表流量超出 GSU 限制,並以溢出流量處理。
根據輸送量用量,圖 2 顯示可能因視窗未對齊而出現的視覺差異。在這張圖中:
藍線代表佈建處理量流量。
橘色線條代表溢出流量。
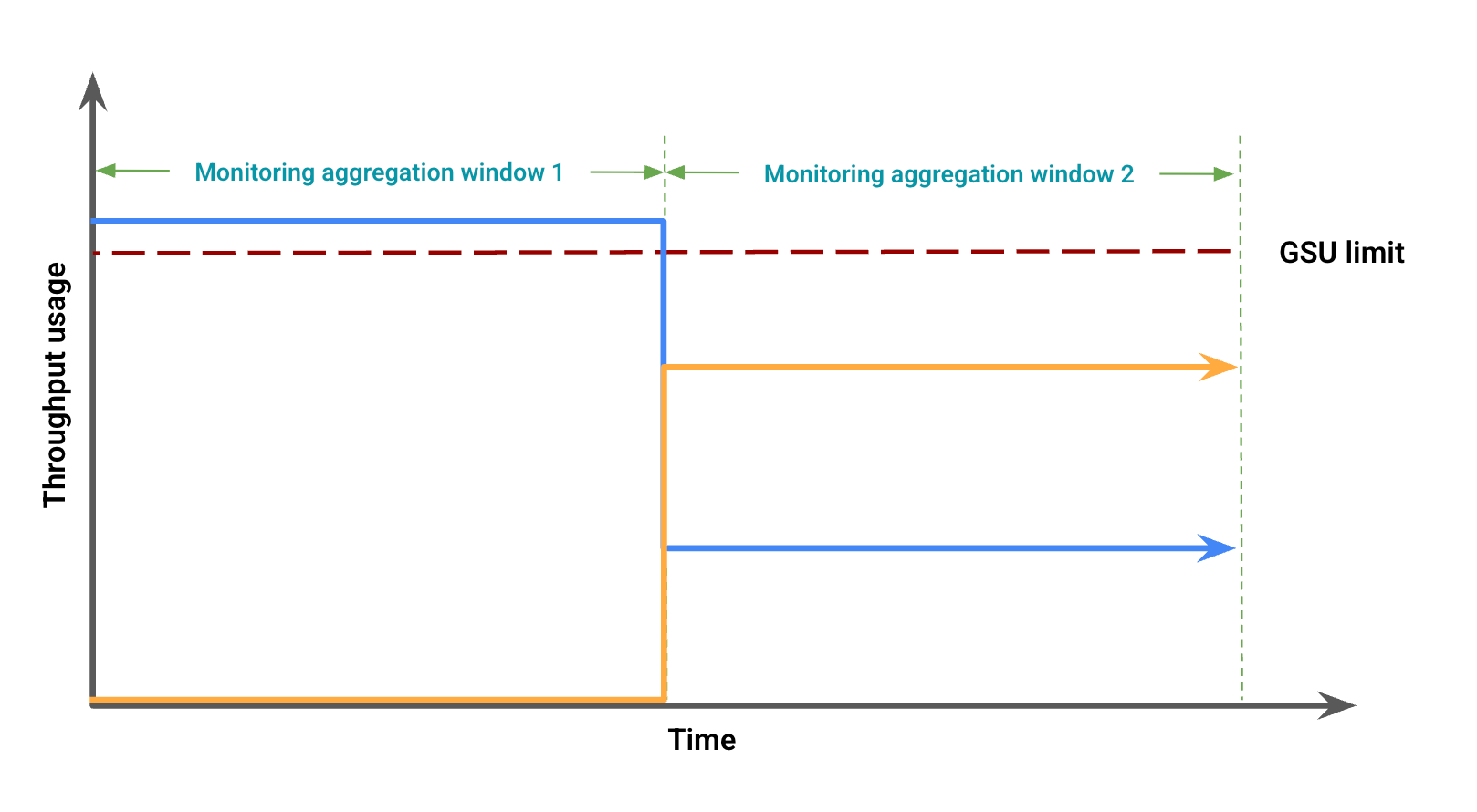
在這種情況下,監控資料可能會顯示在某個監控匯總時間範圍內,佈建輸送量用量沒有溢出,同時在另一個監控匯總時間範圍內,佈建輸送量用量低於 GSU 限制,但有溢出。
排解監控資訊主頁的問題
如要排解資訊主頁中非預期的溢位或 429 錯誤,請按照下列步驟操作:
放大:將資訊主頁的時間範圍設為 12 小時以內,即可提供最精細的 1 分鐘校正間隔。較大的時間範圍可平緩導致節流的尖峰,並提高對齊週期平均值。
檢查總流量:模型專屬資訊主頁會將專用和溢出流量顯示為兩條不同的線,這可能會導致您誤以為佈建輸送量配額未充分運用,且溢出過早。如果流量超過可用配額,系統會將整個要求視為溢出流量來處理。如要取得其他實用視覺化資料,請使用 Metrics Explorer 將查詢新增至資訊主頁,並加入特定模型和區域的權杖輸送量。如要查看所有流量類型 (專用、溢出和共用) 的總流量,請勿加入任何其他匯總或篩選器。
監控 Genmedia 模型
Veo 3 和 Imagen 模型不支援佈建輸送量監控功能。
快訊
啟用快訊功能後,請設定預設快訊,協助您管理流量用量。
啟用警告
如要在資訊主頁中啟用快訊,請按照下列步驟操作:
前往 Google Cloud 控制台的「佈建輸送量」頁面。
如要查看所有訂單中個別模型的佈建輸送量使用率,請選取「使用率摘要」分頁。
選取「建議的快訊」,系統會顯示下列快訊:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
查看有助於管理流量的快訊。
查看更多快訊詳細資料
如要查看快訊的詳細資訊,請按照下列步驟操作:
前往「整合」頁面。
在「Filter」(篩選條件) 欄位中輸入「vertex」,然後按 Enter 鍵。系統會顯示「Google Vertex AI」。
如要查看更多資訊,請按一下「查看詳細資料」。系統會顯示「Google Vertex AI 詳細資料」窗格。
選取「快訊」分頁標籤,然後選取「快訊政策」範本。
後續步驟
- 排解錯誤代碼
429。