
Las firmas de pensamiento son representaciones encriptadas del proceso de pensamiento interno del modelo. Las firmas de pensamiento conservan el estado de razonamiento de Gemini durante las conversaciones de varios pasos y turnos, lo que puede ser útil cuando se usa la llamada a funciones. Las respuestas pueden incluir un campo thought_signature dentro de cualquier parte del contenido (p.ej., text, functionCall).
Los modelos de Gemini 3 aplican una validación más estricta en las firmas de pensamiento que las versiones anteriores de Gemini, ya que mejoran el rendimiento del modelo para la llamada a funciones. Para garantizar que el modelo mantenga el contexto completo en varios turnos de una conversación, debes devolver las firmas de pensamiento de las respuestas anteriores en tus solicitudes posteriores, incluso cuando uses niveles de pensamiento de MINIMAL. Si no se devuelve una firma de pensamiento requerida cuando se usan los modelos de Gemini 3, el modelo devolverá un error 400.
Si bien Gemini 3 Pro Image no aplica esta validación, para garantizar que el modelo mantenga el contexto completo en varios turnos de una conversación, debes devolver las firmas de pensamiento de las respuestas anteriores en tus solicitudes posteriores. Gemini 3 Pro Image no devuelve un error 400 si no se devuelve una firma de pensamiento. Para ver muestras de código relacionadas con la edición de imágenes de varios turnos con Gemini 3 Pro Image, consulta Ejemplo de edición de imágenes de varios turnos con firmas de pensamiento.
Si usas el SDK oficial de IA generativa de Google (Python, Node.js, Go o Java) y las funciones estándar del historial de chat, o bien agregas la respuesta completa del modelo al historial, las firmas de pensamiento se controlan automáticamente.
¿Por qué son importantes?
Cuando un modelo de Thinking llama a una herramienta externa, pausa su proceso de razonamiento interno. La firma de pensamiento actúa como un "estado de guardado", lo que permite que el modelo reanude su cadena de pensamiento sin problemas una vez que proporciones el resultado de la función. Sin las firmas de pensamiento, el modelo "olvida" sus pasos de razonamiento específicos durante la fase de ejecución de la herramienta. Pasar la firma de vuelta garantiza lo siguiente:
- Continuidad del contexto: El modelo conserva y puede verificar los pasos de razonamiento que justificaron la llamada a la herramienta.
- Razonamiento complejo: Permite realizar tareas de varios pasos en las que el resultado de una herramienta fundamenta el razonamiento de la siguiente.
Giros y pasos
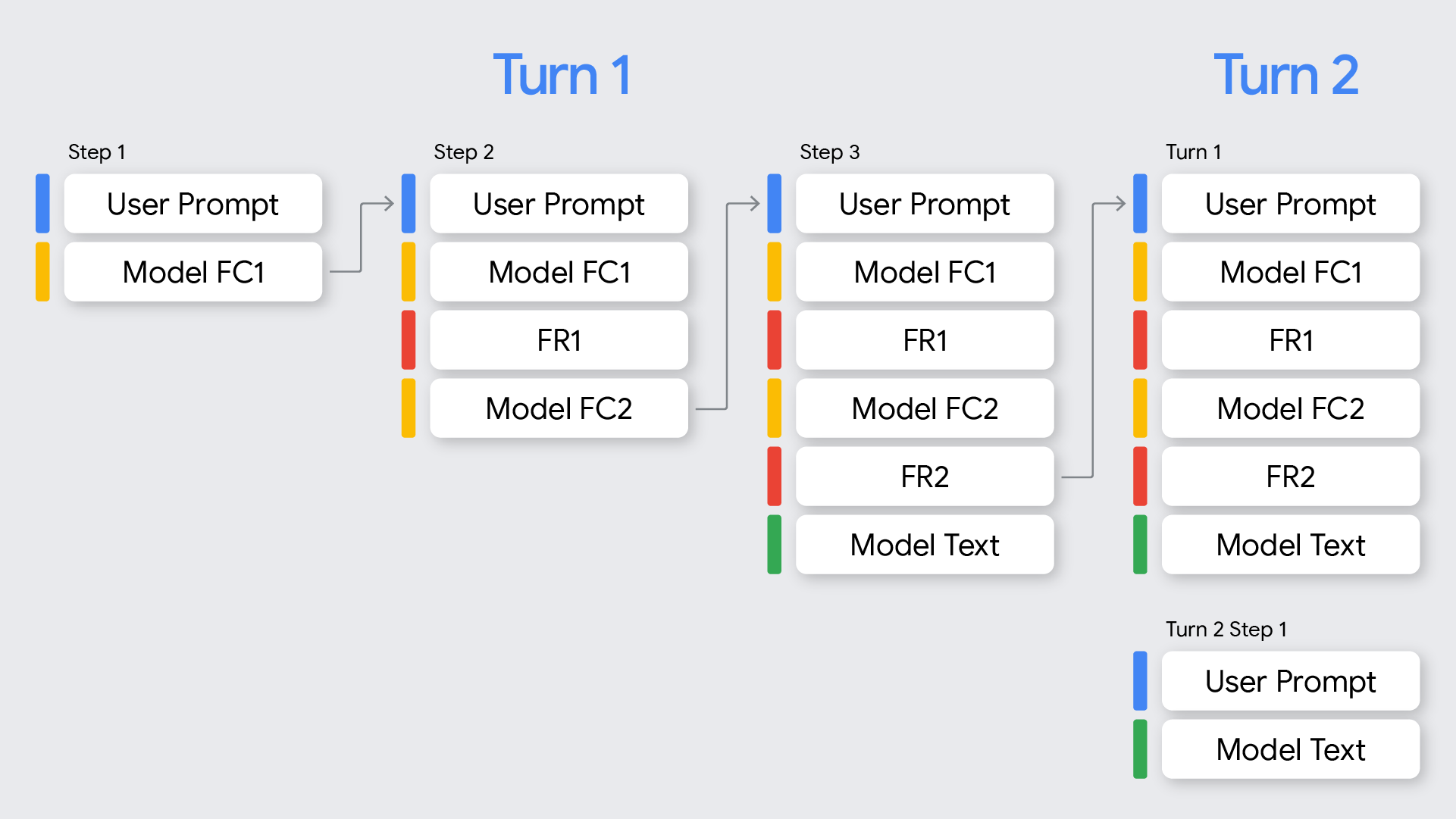
En el contexto de la llamada a funciones, es importante comprender la diferencia entre turnos y pasos:
- Un turno representa un intercambio completo de conversación, que comienza con una instrucción del usuario y finaliza cuando el modelo proporciona una respuesta final que no es una llamada a función a esa instrucción.
- Un paso ocurre dentro de un solo turno cuando el modelo invoca una función y requiere una respuesta de la función para continuar con su proceso de razonamiento. Como se muestra en el diagrama, un solo turno puede implicar varios pasos si el modelo necesita llamar a varias funciones de forma secuencial para satisfacer la solicitud del usuario.
Cómo usar las firmas de pensamiento
La forma más sencilla de controlar las firmas de pensamiento es incluir todos los Part de todos los mensajes anteriores en el historial de conversación cuando se envía una solicitud nueva, exactamente como los devolvió el modelo.
Si no usas uno de los SDKs de IA generativa de Google o necesitas modificar o recortar el historial de conversación, debes asegurarte de que se conserven las firmas de pensamiento y se envíen de vuelta al modelo.
Cuando usas el SDK de IA generativa de Google (recomendado)
Cuando se usan las funciones del historial de chat de los SDKs o se agrega el objeto content del modelo de la respuesta anterior al objeto contents de la siguiente solicitud, las firmas se controlan automáticamente.
En el siguiente ejemplo de Python, se muestra el control automático:
from google import genai
from google.genai.types import Content, FunctionDeclaration, GenerateContentConfig, Part, ThinkingConfig, Tool
client = genai.Client()
# 1. Define your tool
get_weather_declaration = FunctionDeclaration(
name="get_weather",
description="Gets the current weather temperature for a given location.",
parameters={
"type": "object",
"properties": {"location": {"type": "string"}},
"required": ["location"],
},
)
get_weather_tool = Tool(function_declarations=[get_weather_declaration])
# 2. Send a message that triggers the tool
prompt = "What's the weather like in London?"
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=prompt,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 3. Handle the function call
function_call = response.function_calls[0]
location = function_call.args["location"]
print(f"Model wants to call: {function_call.name}")
# Execute your tool (for example, call an API)
# (This is a mock response for the example)
print(f"Calling external tool for: {location}")
function_response_data = {
"location": location,
"temperature": "30C",
}
# 4. Send the tool's result back
# Append this turn's messages to history for a final response.
# The `content` object automatically attaches the required thought_signature behind the scenes.
history = [
Content(role="user", parts=[Part(text=prompt)]),
response.candidates[0].content, # Signature preserved here
Content(
role="tool",
parts=[
Part.from_function_response(
name=function_call.name,
response=function_response_data,
)
],
)
]
response_2 = client.models.generate_content(
model="gemini-2.5-flash",
contents=history,
config=GenerateContentConfig(
tools=[get_weather_tool],
thinking_config=ThinkingConfig(include_thoughts=True)
),
)
# 5. Get the final, natural-language answer
print(f"\nFinal model response: {response_2.text}")
Cuando se usa REST o el control manual
Si interactúas directamente con la API, debes implementar el control de firmas según las siguientes reglas para Gemini 3 Pro:
- Llamar funciones:
- Si la respuesta del modelo contiene una o más partes de
functionCall, se requiere unthought_signaturepara el procesamiento correcto. - En los casos de llamadas a funciones paralelas en una sola respuesta, solo la primera parte de
functionCallcontendrá elthought_signature. - En los casos de llamadas a funciones secuenciales en varios pasos de un turno, cada parte de
functionCallcontendrá unthought_signature. - Regla: Cuando construyas la siguiente solicitud, debes incluir el
partque contiene elfunctionCally suthought_signatureexactamente como los devolvió el modelo. En el caso de las llamadas a funciones secuenciales (de varios pasos), la validación se realiza en todos los pasos del turno actual, y omitir unthought_signatureobligatorio para la primera parte defunctionCallen cualquier paso del turno actual genera un error de400. Un turno comienza con el mensaje del usuario más reciente que no es unfunctionResponse. - Si el modelo devuelve llamadas a funciones paralelas (por ejemplo,
FC1+signature,FC2), tu respuesta debe contener todas las llamadas a funciones seguidas de todas las respuestas a funciones (FC1+signature,FC2,FR1,FR2). Las respuestas intercaladas (FC1+signature,FR1,FC2,FR2) generan un error de400. - Hay casos excepcionales en los que debes proporcionar partes de
functionCallque no generó la API y, por lo tanto, no tienen una firma de pensamiento asociada (por ejemplo, cuando se transfiere el historial de un modelo que no incluye firmas de pensamiento). Puedes establecerthought_signatureenskip_thought_signature_validator, pero esto debería ser un último recurso, ya que afectará negativamente el rendimiento del modelo.
- Si la respuesta del modelo contiene una o más partes de
- Llamada a un elemento que no es una función:
- Si la respuesta del modelo no contiene un
functionCall, es posible que incluya unthought_signatureen el últimopartde la respuesta (por ejemplo, la última parte detext). - Regla: Se recomienda incluir esta firma en la próxima solicitud para obtener el mejor rendimiento, pero omitirla no causará un error. Cuando se transmite, es posible que esta firma se devuelva en una parte con contenido de texto vacío, por lo que debes analizar todas las partes hasta que el modelo devuelva
finish_reason.
- Si la respuesta del modelo no contiene un
Sigue estas reglas para asegurarte de que se conserve el contexto del modelo:
- Siempre envía el
thought_signaturede vuelta al modelo dentro de suPartoriginal. - No combines un
Partque contiene una firma con uno que no la tiene. Esto rompe el contexto posicional del pensamiento. - No combines dos objetos
Partque contengan firmas, ya que las cadenas de firma no se pueden combinar.
Ejemplo de llamada a función secuencial
En el siguiente ejemplo, se muestra una llamada a función de varios pasos en la que el usuario pregunta "Verifica el estado del vuelo AA100 y reserva un taxi si se retrasa", lo que requiere varias tareas.
REST
En el siguiente ejemplo, se muestra cómo controlar las firmas de pensamiento en varios pasos de un flujo de trabajo de llamada a función secuencial con la API de REST.
Turno 1, paso 1 (solicitud del usuario)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check" } }, "required": [ "flight" ] } }, { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } ] } ] }
Turno 1, paso 1 (respuesta del modelo)
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] } }
Turno 1, paso 2 (respuesta del usuario: envío de resultados de herramientas)
Dado que este turno del usuario solo contiene un functionResponse (sin texto nuevo), seguimos en el turno 1. Debes conservar <SIGNATURE_A>.
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }
Turn 1, Step 2 (respuesta del modelo)
Ahora, el modelo decide reservar un taxi según el resultado anterior de la herramienta.
{ "content": { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] } }
Turno 1, paso 3 (respuesta del usuario: envío del resultado de la herramienta)
Para enviar la confirmación de la reserva de taxi, debes incluir firmas para todas las llamadas a funciones en este bucle (<SIGNATURE_A> y <SIGNATURE_B>).
{ "role": "user", "parts": [ { "text": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "check_flight", "args": { "flight": "AA100" } }, "thoughtSignature": "<SIGNATURE_A>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "check_flight", "response": { "status": "delayed", "departure_time": "12 PM" } } } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "book_taxi", "args": { "time": "10 AM" } }, "thoughtSignature": "<SIGNATURE_B>" } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "book_taxi", "response": { "booking_status": "success" } } } ] } }
Completado de chat
En el siguiente ejemplo, se muestra cómo controlar las firmas de pensamiento en varios pasos de un flujo de trabajo secuencial de llamada a función con la API de Chat Completions.
Turno 1, paso 1 (solicitud del usuario)
{ "model": "google/gemini-3-pro-preview", "messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." } ], "tools": [ { "type": "function", "function": { "name": "check_flight", "description": "Gets the current status of a flight", "parameters": { "type": "object", "properties": { "flight": { "type": "string", "description": "The flight number to check." } }, "required": [ "flight" ] } } }, { "type": "function", "function": { "name": "book_taxi", "description": "Book a taxi", "parameters": { "type": "object", "properties": { "time": { "type": "string", "description": "time to book the taxi" } }, "required": [ "time" ] } } } ] }
Turno 1, paso 1 (respuesta del modelo)
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }
Turno 1, paso 2 (respuesta del usuario: envío de resultados de herramientas)
Dado que este turno del usuario solo contiene un functionResponse (sin texto nuevo), seguimos en el turno 1. Debes conservar <SIGNATURE_A>.
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" } ]
Turn 1, Step 2 (respuesta del modelo)
Ahora, el modelo decide reservar un taxi según el resultado anterior de la herramienta.
{ "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-2", "type": "function" } ] }
Turno 1, paso 3 (respuesta del usuario: envío del resultado de la herramienta)
Para enviar la confirmación de la reserva de taxi, debes incluir firmas para todas las llamadas a funciones en este bucle (<SIGNATURE_A> y <SIGNATURE_B>).
"messages": [ { "role": "user", "content": "Check flight status for AA100 and book a taxi 2 hours before if delayed." }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"flight\":\"AA100\"}", "name": "check_flight" }, "id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "type": "function" } ] }, { "role": "tool", "name": "check_flight", "tool_call_id": "function-call-1d6a1a61-6f4f-4029-80ce-61586bd86da5", "content": "{\"status\":\"delayed\",\"departure_time\":\"12 PM\"}" }, { "role": "model", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_B>" } }, "function": { "arguments": "{\"time\":\"10 AM\"}", "name": "book_taxi" }, "id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "type": "function" } ] }, { "role": "tool", "name": "book_taxi", "tool_call_id": "function-call-65b325ba-9b40-4003-9535-8c7137b35634", "content": "{\"booking_status\":\"success\"}" } ]
Ejemplo de llamada a función paralela
En el siguiente ejemplo, se muestra una llamada a función paralela en la que el usuario pregunta "Consulta el clima en París y Londres".
REST
En el siguiente ejemplo, se muestra cómo controlar las firmas de pensamiento en un flujo de trabajo de llamada a función paralelo con la API de REST.
Turno 1, paso 1 (solicitud del usuario)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Turno 1, paso 1 (respuesta del modelo)
{ "content": { "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "location": "Paris" } }, "thoughtSignature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "location": "London" } } } ] } }
Turno 1, paso 2 (respuesta del usuario: envío de resultados de herramientas)
Debes conservar <SIGNATURE_A> en la primera parte exactamente como se recibió.
[ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] }, { "role": "model", "parts": [ { "functionCall": { "name": "get_current_temperature", "args": { "city": "Paris" } }, "thought_signature": "<SIGNATURE_A>" }, { "functionCall": { "name": "get_current_temperature", "args": { "city": "London" } } } ] }, { "role": "user", "parts": [ { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "15C" } } }, { "functionResponse": { "name": "get_current_temperature", "response": { "temp": "12C" } } } ] } ]
Completado de chat
En el siguiente ejemplo, se muestra cómo controlar las firmas de pensamiento en un flujo de trabajo de llamada a función paralela con la API de Chat Completions.
Turno 1, paso 1 (solicitud del usuario)
{ "contents": [ { "role": "user", "parts": [ { "text": "Check the weather in Paris and London." } ] } ], "tools": [ { "functionDeclarations": [ { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco" } }, "required": [ "location" ] } } ] } ] }
Turno 1, paso 1 (respuesta del modelo)
{ "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }
Turno 1, paso 2 (respuesta del usuario: envío de resultados de herramientas)
Debes conservar <SIGNATURE_A> en la primera parte exactamente como se recibió.
"messages": [ { "role": "user", "content": "Check the weather in Paris and London." }, { "role": "assistant", "tool_calls": [ { "extra_content": { "google": { "thought_signature": "<SIGNATURE_A>" } }, "function": { "arguments": "{\"location\":\"Paris\"}", "name": "get_current_temperature" }, "id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "type": "function" }, { "function": { "arguments": "{\"location\":\"London\"}", "name": "get_current_temperature" }, "id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "type": "function" } ] }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-f3b9ecb3-d55f-4076-98c8-b13e9d1c0e01", "content": "{\"temp\":\"15C\"}" }, { "role":"tool", "name": "get_current_temperature", "tool_call_id": "function-call-335673ad-913e-42d1-bbf5-387c8ab80f44", "content": "{\"temp\":\"12C\"}" } ]
Firmas en Parts que no son de functionCall
Gemini también puede devolver un thought_signature en el Part final de una respuesta, incluso si no hay ninguna llamada a función.
- Comportamiento: El contenido final
Part(text,inlineData, etc.) que devuelve el modelo puede contener unthought_signature. - Requisito: Se recomienda devolver esta firma para garantizar que el modelo mantenga un razonamiento de alta calidad, especialmente para el seguimiento de instrucciones complejas o flujos de trabajo de agentes simulados.
- Validación: La API no aplica estrictamente la validación de firmas en las partes que no son de
functionCall. No recibirás un error de bloqueo si los omites, aunque es posible que el rendimiento disminuya.
Ejemplo de respuesta del modelo con firma en la parte de texto:
En los siguientes ejemplos, se muestra una respuesta del modelo en la que se incluye un thought_signature en un Part que no es de functionCall y cómo controlarlo en una solicitud posterior.
Turno 1, paso 1 (respuesta del modelo)
{ "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", "thought_signature": "<SIGNATURE_C>" // OPTIONAL (Recommended) } ] }
Turno 2, paso 1 (usuario)
[ { "role": "user", "parts": [{ "text": "What is the risk?" }] }, { "role": "model", "parts": [ { "text": "I need to calculate the risk. Let me think step-by-step...", // If you omit <SIGNATURE_C> here, no error will occur. } ] }, { "role": "user", "parts": [{ "text": "Summarize it." }] } ]
Ejemplo de edición de imágenes de varios turnos con firmas de pensamiento
En los siguientes ejemplos, se ilustra cómo recuperar y pasar firmas de pensamiento durante la creación y edición de imágenes en varios turnos con Gemini 3 Pro Image.
Turno 1: Obtén la respuesta y guarda los datos que incluyen firmas de pensamiento
chat = client.chats.create( model="gemini-3-pro-image-preview", config=types.GenerateContentConfig( response_modalities=['TEXT', 'IMAGE'] ) ) message = "Create an image of a clear perfume bottle sitting on a vanity." response = chat.send_message(message) data = b'' for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: data = part.inline_data.data display(Image(data=data, width=500))
Turno 2: Pasa los datos que incluyen firmas de pensamiento.
response = chat.send_message( message=[ types.Part.from_bytes( data=data, mime_type="image/png", ), "Make the perfume bottle purple and add a vase of hydrangeas next to the bottle.", ], ) for part in response.candidates[0].content.parts: if part.text: display(Markdown(part.text)) if part.inline_data: display(Image(data=part.inline_data.data, width=500))
¿Qué sigue?
- Obtén más información sobre Thinking.
- Obtén más información sobre las llamadas a funciones.
- Obtén más información para diseñar instrucciones multimodales.