
Esta página explica como funciona o débito processado, como controlar os excessos ou ignorar o débito processado e como monitorizar a utilização.
Como funciona o débito aprovisionado
Esta secção explica como o débito processado funciona através da verificação de quotas durante o período de aplicação de quotas.
Verificação da quota de débito aprovisionado
A sua quota máxima de débito aprovisionado é um múltiplo do número de unidades de escalabilidade de IA generativa (GSUs) compradas e do débito por GSU. É verificado sempre que faz um pedido no seu período de aplicação de quotas, que é a frequência com que a quota de débito processado máxima é aplicada.
No momento em que é recebido um pedido, o tamanho real da resposta é desconhecido. Uma vez que damos prioridade à velocidade de resposta para aplicações em tempo real, o débito aprovisionado estima o tamanho dos tokens de saída. Se a estimativa inicial exceder a quota máxima de débito processado disponível, o pedido é processado como pagamento conforme o uso. Caso contrário, é processado como débito processado. Isto é feito comparando a estimativa inicial com a quota máxima de débito processado.
Quando a resposta é gerada e o tamanho real do token de saída é conhecido, a utilização e a quota reais são reconciliadas adicionando a diferença entre a estimativa e a utilização real ao valor da quota de débito processado disponível.
Janelas de aplicação da quota de débito aprovisionado
A Vertex AI aplica uma janela dinâmica ao aplicar a quota de débito aprovisionado para os modelos Gemini. Isto oferece uma estabilidade ideal para o tráfego propenso a picos. Em vez de uma janela fixa, a Vertex AI aplica a quota numa janela flexível que se ajusta automaticamente, consoante o tipo de modelo e o número de GSUs que aprovisionou. Como resultado, pode ter temporariamente tráfego prioritário que excede o valor da sua quota por segundo em alguns casos. No entanto, não pode exceder a sua quota durante a duração da janela. Estes períodos baseiam-se na hora do relógio interno do Vertex AI e são independentes do momento em que os pedidos são feitos.
Como funciona o período de aplicação de quotas
O período de aplicação determina o quanto pode exceder, ou "disparar", acima do limite por segundo antes de a velocidade ser limitada. Esta janela é aplicada automaticamente. Tenha em atenção que estes períodos estão sujeitos a alterações para otimizar o desempenho e a fiabilidade.
Atribuições de GSU pequenas (3 GSUs ou menos): o período pode variar entre 40 e 120 segundos para permitir o processamento de pedidos individuais maiores sem interrupções.
Por exemplo, se comprar 1 GSU de
gemini-2.5-flash, recebe uma média de 2690 tokens por segundo de débito contínuo. A sua utilização total num período de 120 segundos não pode exceder 322 800 tokens (2690 tokens por segundo * 120 segundos). Por conseguinte, se enviar um pedido que use 70 000 tokens por segundo, mas a utilização total ao longo de 120 segundos permanecer abaixo dos 322 800 tokens, o pico de 70 000 tokens por segundo continua a ser contabilizado como débito processado, uma vez que a utilização média não excede os 2690 tokens por segundo.Alocações de GSU padrão (tamanho médio) (mais de 3 GSUs): para implementações de GSU de tamanho médio (por exemplo, menos de 50 GSUs), o intervalo pode variar entre 5 e 30 segundos. Os limites e os períodos de contexto da GSU variam consoante o modelo.
Por exemplo, se comprar 25 GSUs de
gemini-2.5-flash, recebe uma média de 67 250 tokens por segundo (2690 tokens por segundo * 25) de débito contínuo. A sua utilização total num período de 30 segundos não pode exceder 2 017 500 tokens (67 250 tokens por segundo * 30 segundos). Por conseguinte, se enviar um pedido que use 1 000 000 de tokens por segundo, mas a utilização total ao longo de 30 segundos permanecer dentro de 2 017 500 tokens, o pico de 1 000 000 de tokens por segundo continua a contar como débito processado, uma vez que a utilização média não excede 67 250 tokens por segundo.Atribuições de GSU de alta precisão (em grande escala): para implementações de GSU em grande escala (por exemplo, 50 GSUs ou mais), o período pode variar entre 1 e 5 segundos para garantir que os pedidos de alta frequência são processados com a máxima precisão na infraestrutura.
Por exemplo, se comprar 250 GSUs de
gemini-2.5-flash, recebe uma média de 672 500 tokens por segundo (2690 tokens por segundo * 250) de débito contínuo. A sua utilização total num período de 5 segundos não pode exceder 3 362 500 tokens (672 500 tokens por segundo * 5 segundos). Por conseguinte, se enviar um pedido que use 5 000 000 de tokens por segundo, não será processado como débito processado, porque a utilização total de 5 000 000 de tokens excede o limite de 3 362 500 tokens num período de 5 segundos. Por outro lado, um pedido que usa 1 000 000 tokens por segundo pode ser processado como débito processado, se a utilização média durante o período de 5 segundos não exceder os 672 500 tokens por segundo.
Controle os excessos ou ignore o débito aprovisionado
Use a API para controlar os excessos quando excede o débito adquirido ou para ignorar o débito aprovisionado por pedido.
Leia cada opção para determinar o que tem de fazer para satisfazer o seu exemplo de utilização.
Comportamento predefinido
Se um pedido exceder a quota de débito processado provisionado restante, o pedido inteiro é processado como um pedido a pedido por predefinição e é faturado à taxa de pagamento conforme a utilização. Quando isto acontece, o tráfego aparece como transbordo nos painéis de controlo de monitorização. Para mais informações sobre a monitorização da utilização do débito aprovisionado, consulte o artigo Monitorizar o débito aprovisionado.
Depois de a sua encomenda de débito processado provisionado estar ativa, o comportamento predefinido ocorre automaticamente. Não tem de alterar o código para começar a usar a sua encomenda, desde que a esteja a usar na região aprovisionada.
Use apenas o débito aprovisionado
Se estiver a gerir os custos evitando encargos a pedido, use apenas o débito processado. Os pedidos que excedem o valor do pedido de débito processado devolvem um erro 429.
Quando enviar pedidos para a API, defina o cabeçalho HTTP X-Vertex-AI-LLM-Request-Type como dedicated.
Use apenas o pagamento mediante utilização
Isto também é conhecido como usar a pedido. Os pedidos ignoram a ordem de débito de capacidade de processamento provisionada e são enviados diretamente para o pagamento por utilização. Isto pode ser útil para experiências ou aplicações em desenvolvimento.
Quando enviar pedidos para a API, defina o cabeçalho HTTP X-Vertex-AI-LLM-Request-Type como shared.
Exemplo
Python
Instalação
pip install --upgrade google-genai
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA gen com o Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Saiba como instalar ou atualizar o Go.
Para saber mais, consulte a documentação de referência do SDK.
Defina variáveis de ambiente para usar o SDK de IA gen com o Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Depois de configurar o seu ambiente, pode usar a API REST para testar um comando de texto. O exemplo seguinte envia um pedido para o ponto final do modelo do publicador.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Use o débito processado com uma chave da API
Se comprou débito processado para um projeto, um modelo e uma região específicos da Google, e quer usá-lo para enviar um pedido com uma chave API, tem de incluir o ID do projeto, o modelo, a localização e a chave API como parâmetros no seu pedido.
Para obter informações sobre como criar uma Google Cloud chave da API associada a uma conta de serviço, consulte o artigo Obtenha uma Google Cloud chave da API. Para saber como enviar pedidos para a API Gemini através de uma chave da API, consulte o início rápido da API Gemini no Vertex AI.
Por exemplo, o exemplo seguinte mostra como enviar um pedido com uma chave da API enquanto usa o débito processado:
REST
Depois de configurar o seu ambiente, pode usar a API REST para testar um comando de texto. O exemplo seguinte envia um pedido para o ponto final do modelo do publicador.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Monitorize o débito aprovisionado
Pode monitorizar autonomamente a utilização do débito processado através de um conjunto de métricas que são medidas no tipo de recurso aiplatform.googleapis.com/PublisherModel.
A monitorização do tráfego de débito aprovisionado é uma funcionalidade de pré-visualização pública.
Dimensões
Pode filtrar por métricas através das seguintes dimensões:
| Dimensão | Valores |
|---|---|
type |
inputoutput |
request_type |
|
Prefixo do caminho
O prefixo do caminho de uma métrica é
aiplatform.googleapis.com/publisher/online_serving.
Por exemplo, o caminho completo para a métrica /consumed_throughput é
aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Métrica
As seguintes métricas do Cloud Monitoring estão disponíveis no recurso aiplatform.googleapis.com/PublisherModel para os modelos Gemini. Use os dedicated tipos de pedidos para filtrar a utilização do débito processado.
| Métrica | Nome a apresentar | Descrição |
|---|---|---|
/dedicated_gsu_limit |
Limite (GSU) | Limite dedicado em GSUs. Use esta métrica para compreender a sua quota máxima de débito aprovisionado em GSUs. |
/tokens |
Tokens | Distribuição da contagem de tokens de entrada e saída. |
/token_count |
Contagem de tokens | Contagem de tokens de entrada e saída acumulados. |
/consumed_token_throughput |
Débito de tokens | Utilização da taxa de transferência, que tem em conta a taxa de redução em tokens e incorpora a conciliação de quotas. Consulte a secção Verificação da quota de débito processado. Use esta métrica para compreender como foi usada a sua quota de débito processado. |
/dedicated_token_limit |
Limite (tokens por segundo) | Limite dedicado em tokens por segundo. Use esta métrica para compreender a sua quota máxima de débito aprovisionado para modelos baseados em tokens. |
/characters |
Carateres | Distribuição da contagem de carateres de entrada e saída. |
/character_count |
Número de carateres | Número de carateres de entrada e saída acumulados. |
/consumed_throughput |
Débito de carateres | Utilização do débito, que representa a taxa de redução em carateres e incorpora a conciliação de quotas Verificação de quotas de débito aprovisionado. Use esta métrica para compreender como foi usada a sua quota de débito processado. Para modelos baseados em tokens, esta métrica é equivalente ao débito consumido em tokens multiplicado por 4. |
/dedicated_character_limit |
Limite (carateres por segundo) | Limite dedicado em carateres por segundo. Use esta métrica para compreender a sua quota máxima de débito processado para modelos baseados em carateres. |
/model_invocation_count |
Número de invocações do modelo | Número de invocações de modelos (pedidos de previsão). |
/model_invocation_latencies |
Latências de invocação de modelos | Latências de invocação de modelos (latências de previsão). |
/first_token_latencies |
Latências do primeiro token | Duração desde o pedido recebido até à devolução do primeiro token. |
Os modelos da Anthropic também têm um filtro para o débito processado, mas apenas para tokens e token_count.
Painéis de controlo
Os painéis de controlo de monitorização predefinidos para o débito aprovisionado fornecem métricas que lhe permitem compreender melhor a sua utilização e a utilização do débito aprovisionado. Para aceder aos painéis de controlo, faça o seguinte:
Na Google Cloud consola, aceda à página Débito processado.
Para ver a utilização do débito processado de cada modelo em todas as suas encomendas, selecione o separador Resumo da utilização.
Na tabela Utilização do débito aprovisionado por modelo, pode ver o seguinte para o intervalo de tempo selecionado:
Número total de GSUs que tinha.
Utilização do débito de pico em termos de GSUs.
A utilização média da GSU.
O número de vezes que atingiu o limite de débito processado provisionado.
Selecione um modelo na tabela Utilização do débito aprovisionado por modelo para ver mais métricas específicas do modelo selecionado.
Como interpretar os painéis de controlo de monitorização
A capacidade de débito aprovisionada verifica a quota disponível em tempo real ao nível do milissegundo para os pedidos à medida que são feitos, mas compara estes dados com um período de aplicação de quotas, com base na hora do relógio interno do Vertex AI. Esta comparação é independente da hora em que os pedidos são feitos. Os painéis de controlo de monitorização comunicam métricas de utilização após a conciliação das quotas. No entanto, estas métricas são agregadas para fornecer médias para os períodos de alinhamento do painel de controlo, com base no intervalo de tempo selecionado. O nível de detalhe mais baixo possível suportado pelos painéis de controlo de monitorização é o nível de minutos. Além disso, a hora do relógio dos painéis de controlo de monitorização é diferente da do Vertex AI.
Estas diferenças nos horários podem, ocasionalmente, resultar em discrepâncias entre os dados nos painéis de controlo de monitorização e o desempenho em tempo real. Estas podem resultar de qualquer um dos seguintes motivos:
A quota é aplicada em tempo real, mas os gráficos de monitorização agregam dados em períodos de alinhamento do painel de controlo de 1 minuto ou mais, consoante o intervalo de tempo especificado nos painéis de controlo de monitorização.
O Vertex AI e os painéis de controlo de monitorização são executados em diferentes relógios do sistema.
Se um pico de tráfego durante um período de 1 segundo exceder a sua quota de débito aprovisionado, todo o pedido é processado como tráfego de transbordo. No entanto, a utilização geral do débito processado pode parecer baixa quando os dados de monitorização desse segundo são calculados na média no período de alinhamento de 1 minuto, porque a utilização média durante todo o período de alinhamento pode não exceder 100%. Se vir tráfego de transbordo, confirma que a sua quota de débito processado aprovisionado foi totalmente utilizada durante o período de aplicação da quota quando esses pedidos específicos foram feitos. Isto é independentemente da utilização média apresentada nos painéis de controlo de monitorização.
Exemplo de potencial discrepância nos dados de monitorização
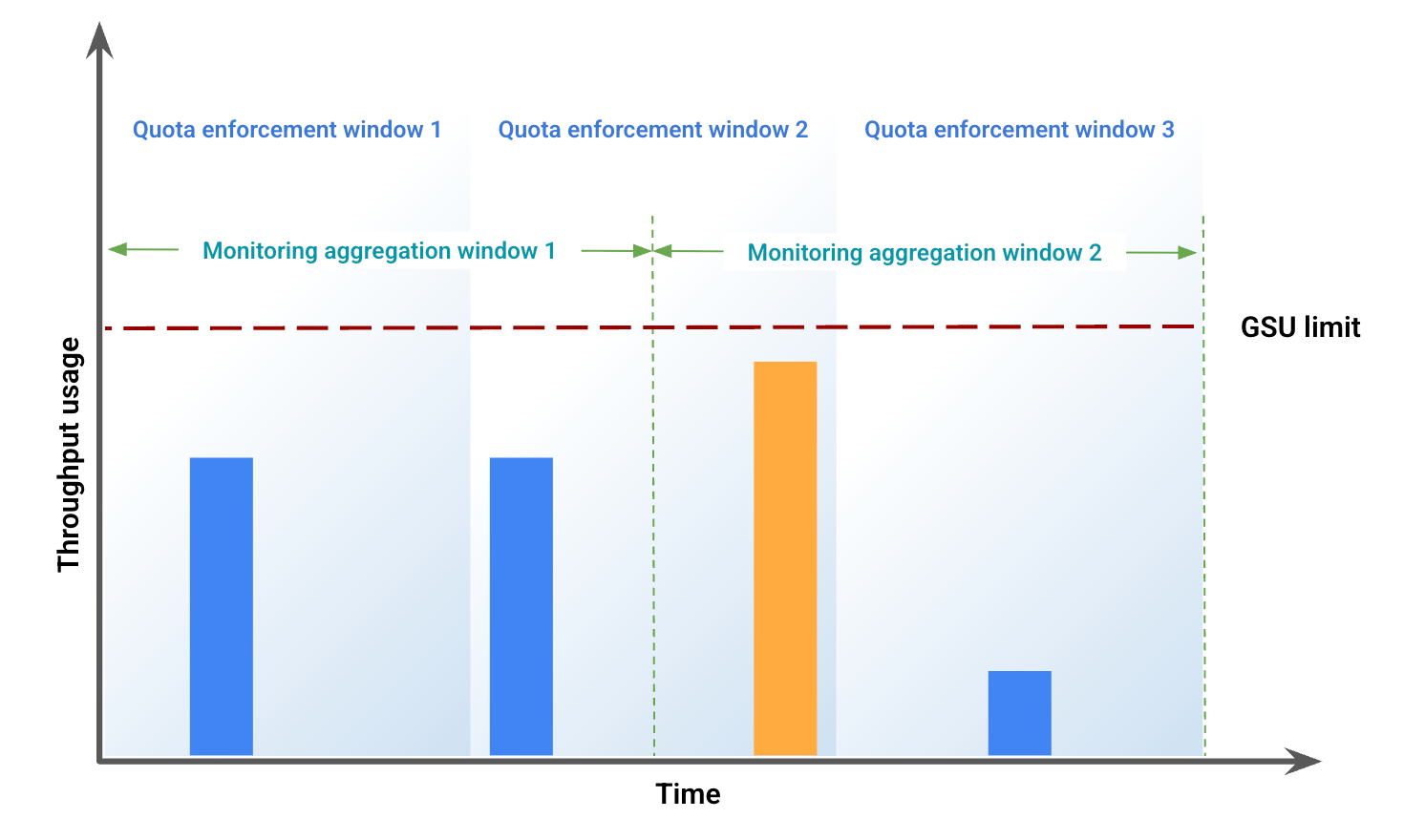
Este exemplo ilustra algumas das discrepâncias resultantes do desalinhamento das janelas. A Figura 1 representa a utilização do débito durante um período específico. Nesta figura:
As barras azuis representam o tráfego admitido como débito aprovisionado.
A barra laranja representa o tráfego que ultrapassa o limite da GSU e é processado como transbordo.
Com base na utilização da taxa de transferência, a figura 2 representa possíveis discrepâncias visuais devido ao desalinhamento das janelas. Nesta figura:
A linha azul representa o tráfego de débito aprovisionado.
A linha laranja representa o tráfego de transbordo.
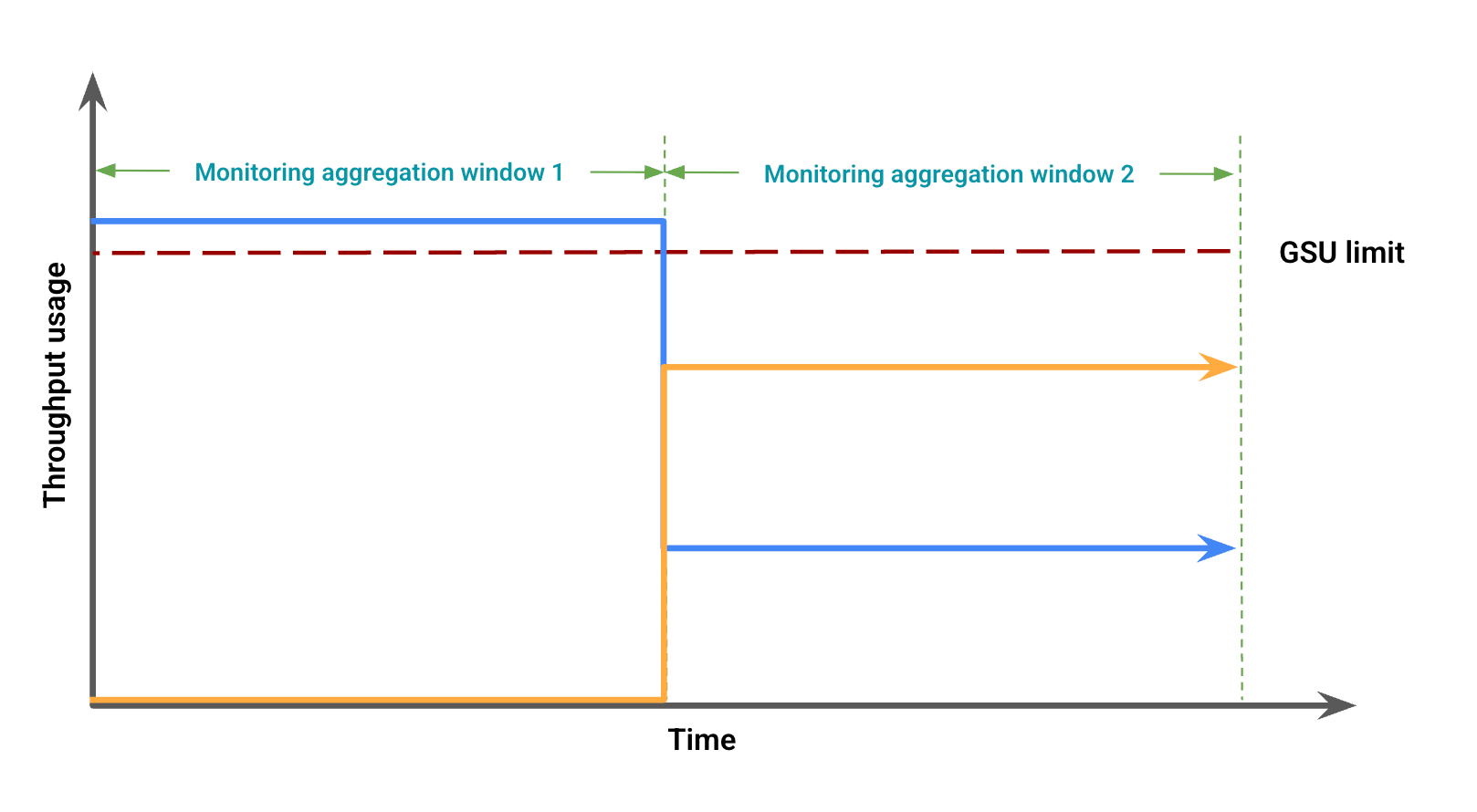
Neste caso, os dados de monitorização podem mostrar a utilização do débito processado sem transbordo para um período de agregação de monitorização, enquanto observam simultaneamente a utilização do débito processado abaixo do limite da GSU coincidente com um transbordo noutro período de agregação de monitorização.
Resolva problemas de painéis de controlo de monitorização
Pode resolver problemas de transbordo inesperado nos painéis de controlo ou erros 429 seguindo estes passos:
Aumentar zoom: defina o intervalo de tempo do painel de controlo para 12 horas ou menos para fornecer o período de alinhamento mais detalhado de 1 minuto. Os grandes intervalos de tempo suavizam os picos que causam a limitação e aumentam as médias do período de alinhamento.
Verifique o tráfego total: os painéis de controlo específicos do modelo mostram o tráfego dedicado e de transbordo como duas linhas separadas, o que pode levar à conclusão incorreta de que a quota de débito aprovisionado não está totalmente utilizada e está a transbordar prematuramente. Se o seu tráfego exceder a quota disponível, todo o pedido é processado como transbordo. Para outra visualização útil, adicione uma consulta ao painel de controlo através do explorador de métricas e inclua o débito de tokens para o modelo e a região específicos. Não inclua agregações nem filtros adicionais para ver o tráfego total em todos os tipos de tráfego (dedicado, transbordo e partilhado).
Monitorize modelos Genmedia
A monitorização do débito aprovisionado não está disponível nos modelos Veo 3 e Imagen.
Alertas
Depois de ativar os alertas, defina alertas predefinidos para ajudar a gerir a sua utilização de tráfego.
Ative os alertas
Para ativar os alertas no painel de controlo, faça o seguinte:
Na Google Cloud consola, aceda à página Débito processado.
Para ver a utilização do débito processado de cada modelo em todas as suas encomendas, selecione o separador Resumo da utilização.
Selecione Alertas recomendados. São apresentados os seguintes alertas:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Verifique os alertas que ajudam a gerir o seu tráfego.
Veja mais detalhes do alerta
Para ver mais informações sobre os alertas, faça o seguinte:
Aceda à página Integrações.
Introduza vertex no campo Filtro e prima Enter. É apresentado o Google Vertex AI.
Para ver mais informações, clique em Ver detalhes. É apresentado o painel Detalhes do Google Vertex AI.
Selecione o separador Alertas e pode selecionar um modelo de Política de alertas.
O que se segue?
- Resolva problemas do código de erro
429.