
Cette page explique comment fonctionne le débit provisionné, comment contrôler les dépassements ou contourner le débit provisionné, et comment surveiller l'utilisation.
Fonctionnement du débit provisionné
Cette section explique le fonctionnement du débit provisionné à l'aide de la vérification des quotas pendant la période d'application des quotas.
Vérification du quota de débit provisionné
Votre quota maximal de débit provisionné est un multiple du nombre d'unités de scaling pour l'IA générative (GSU) achetées et du débit par GSU. Il est vérifié chaque fois que vous effectuez une requête au cours de votre période d'application des quotas, c'est-à-dire la fréquence à laquelle le quota maximal de débit provisionné est appliqué.
À la réception d'une requête, la taille réelle de la réponse est inconnue. Comme nous privilégions la rapidité de réponse pour les applications en temps réel, le débit provisionné estime la taille du jeton de sortie. Si l'estimation initiale dépasse le quota maximal de débit provisionné disponible, la requête est traitée via le modèle de paiement à l'usage. Sinon, elle est traitée comme un débit provisionné. Pour effectuer ce calcul, l'estimation initiale est comparée au quota maximal de débit provisionné.
Lorsque la réponse est générée et que la taille réelle du jeton de sortie est connue, l'utilisation réelle et le quota sont rapprochés en ajoutant la différence entre l'estimation et l'utilisation réelle à votre quota de débit provisionné disponible.
Périodes d'application des quotas de débit provisionné
Vertex AI applique une fenêtre dynamique tout en appliquant le quota de débit provisionné pour les modèles Gemini. Cela permet d'assurer une stabilité optimale pour le trafic susceptible de connaître des pics. Au lieu d'une fenêtre fixe, Vertex AI applique le quota sur une fenêtre flexible qui s'ajuste automatiquement en fonction du type de modèle et du nombre d'UGS que vous avez provisionnées. Cela signifie que, dans certains cas, vous pouvez temporairement constater un trafic prioritaire qui dépasse votre quota par seconde. Toutefois, vous ne devez pas dépasser votre quota pendant la durée de la fenêtre. Ces périodes sont basées sur l'horloge interne de Vertex AI et sont indépendantes du moment où les requêtes sont envoyées.
Fonctionnement de la période d'application des quotas
La fenêtre d'application détermine la marge de dépassement (ou"rafale") de votre limite par seconde avant que vous ne soyez limité. Cette période est appliquée automatiquement. Notez que ces fenêtres sont susceptibles d'être modifiées pour optimiser les performances et la fiabilité.
Petites allocations GSU (3 GSU ou moins) : la fenêtre peut aller de 40 à 120 secondes pour permettre le traitement des demandes individuelles plus importantes sans interruption.
Par exemple, si vous achetez un GSU de
gemini-2.5-flash, vous obtenez en moyenne 2 690 jetons par seconde de débit continu. Votre utilisation totale sur une période de 120 secondes ne peut pas dépasser 322 800 jetons (2 690 jetons par seconde * 120 secondes). Par conséquent, si vous envoyez une requête qui utilise 70 000 jetons par seconde, mais que l'utilisation totale sur 120 secondes reste inférieure à 322 800 jetons, le pic de 70 000 jetons par seconde est toujours considéré comme un débit provisionné, car l'utilisation moyenne ne dépasse pas 2 690 jetons par seconde.Attributions GSU standards (taille moyenne) (plus de trois GSU) : pour les déploiements GSU de taille moyenne (par exemple, moins de 50 GSU), la fenêtre peut aller de 5 à 30 secondes. Les seuils et les fenêtres de contexte de la GSU varient en fonction du modèle.
Par exemple, si vous achetez 25 GSU de
gemini-2.5-flash, vous obtenez un débit continu moyen de 67 250 jetons par seconde (2 690 jetons par seconde x 25). Votre utilisation totale sur une période de 30 secondes ne peut pas dépasser 2 017 500 jetons (67 250 jetons par seconde * 30 secondes). Par conséquent, si vous envoyez une requête qui utilise 1 000 000 de jetons par seconde, mais que l'utilisation totale sur 30 secondes reste inférieure à 2 017 500 jetons, le pic de 1 000 000 de jetons par seconde est toujours considéré comme un débit provisionné, car l'utilisation moyenne ne dépasse pas 67 250 jetons par seconde.Attributions GSU de haute précision (à grande échelle) : pour les déploiements GSU à grande échelle (par exemple, 50 GSU ou plus), la fenêtre peut aller de 1 à 5 secondes afin de garantir que les requêtes à haute fréquence sont traitées avec une précision maximale dans l'ensemble de l'infrastructure.
Par exemple, si vous achetez 250 GSU de
gemini-2.5-flash, vous obtenez un débit continu moyen de 672 500 jetons par seconde (2 690 jetons par seconde * 250). Votre utilisation totale sur une période de cinq secondes ne peut pas dépasser 3 362 500 jetons (672 500 jetons par seconde * 5 secondes). Par conséquent, si vous envoyez une requête qui utilise 5 000 000 de jetons par seconde, elle ne sera pas traitée comme un débit provisionné, car l'utilisation totale de 5 000 000 de jetons dépasse la limite de 3 362 500 jetons sur une période de cinq secondes. En revanche, une requête qui utilise 1 000 000 de jetons par seconde peut être traitée comme un débit provisionné si l'utilisation moyenne au cours de la période de cinq secondes ne dépasse pas 672 500 jetons par seconde.
Contrôler les dépassements ou contourner le débit provisionné
Utilisez l'API pour contrôler les dépassements lorsque vous dépassez le débit souscrit ou pour contourner le débit provisionné pour des requêtes spécifiques.
Lisez chacune des options pour déterminer ce que vous devez faire pour répondre à votre cas d'utilisation.
Comportement par défaut
Si une requête dépasse le quota de débit provisionné restant, elle est traitée par défaut comme une requête à la demande et facturée au tarif de paiement à l'usage. Dans ce cas, le trafic apparaît comme débordement dans les tableaux de bord de surveillance. Pour en savoir plus sur la surveillance de l'utilisation du débit provisionné, consultez Surveiller le débit provisionné.
Une fois que votre commande de débit provisionné est active, le comportement par défaut est automatiquement appliqué. Vous n'avez pas besoin de modifier votre code pour commencer à utiliser votre commande, à condition de l'utiliser dans la région provisionnée.
Utiliser uniquement le débit provisionné
Si vous gérez les coûts de manière à éviter la facturation à la demande, n'utilisez que le débit provisionné. Les requêtes qui dépassent le montant de la commande de débit provisionné renverront une erreur 429.
Lorsque vous envoyez des requêtes à l'API, définissez l'en-tête HTTP X-Vertex-AI-LLM-Request-Type sur dedicated.
Utiliser uniquement le paiement à l'usage
On parle également d'utilisation à la demande. Les requêtes contournent la commande de débit provisionné et sont envoyées directement au paiement à l'usage. Cela peut être utile pour les tests ou les applications en cours de développement.
Lorsque vous envoyez des requêtes à l'API, définissez l'en-tête HTTP X-Vertex-AI-LLM-Request-Type sur shared.
Exemple
Python
Installer
pip install --upgrade google-genai
Pour en savoir plus, consultez la documentation de référence du SDK.
Définissez des variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Découvrez comment installer ou mettre à jour le Go.
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez des variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Installer
npm install @google/genai
Pour en savoir plus, consultez la documentation de référence du SDK.
Définissez des variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Découvrez comment installer ou mettre à jour le Java.
Pour en savoir plus, lisez la documentation de référence du SDK.
Définissez des variables d'environnement pour utiliser le SDK Gen AI avec Vertex AI :
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Une fois que vous avez configuré votre environnement, vous pouvez utiliser REST pour tester un prompt textuel. L'exemple suivant envoie une requête au point de terminaison du modèle de l'éditeur.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Utiliser le débit provisionné avec une clé API
Si vous avez acheté un débit provisionné pour un projet, un modèle Google et une région spécifiques, et que vous souhaitez l'utiliser pour envoyer une requête avec une clé API, vous devez inclure l'ID de projet, le modèle, l'emplacement et la clé API en tant que paramètres dans votre requête.
Pour savoir comment créer une clé API Google Cloud associée à un compte de service, consultez Obtenir une clé API Google Cloud . Pour découvrir comment envoyer des requêtes à l'API Gemini à l'aide d'une clé API, consultez le guide de démarrage rapide de l'API Gemini dans Vertex AI.
Par exemple, l'exemple suivant montre comment envoyer une requête avec une clé API tout en utilisant le débit provisionné :
REST
Une fois que vous avez configuré votre environnement, vous pouvez utiliser REST pour tester un prompt textuel. L'exemple suivant envoie une requête au point de terminaison du modèle de l'éditeur.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Surveiller le débit provisionné
Vous pouvez surveiller vous-même votre utilisation du débit provisionné à l'aide d'un ensemble de métriques mesurées sur le type de ressource aiplatform.googleapis.com/PublisherModel.
La surveillance du trafic de débit provisionné est une fonctionnalité en Preview publique.
Dimensions
Vous pouvez filtrer les métriques à l'aide des dimensions suivantes :
| Dimension | Valeurs |
|---|---|
type |
inputoutput |
request_type |
|
Préfixe de chemin d'accès
Le préfixe de chemin d'accès d'une métrique est aiplatform.googleapis.com/publisher/online_serving.
Par exemple, le chemin d'accès complet de la métrique /consumed_throughput est aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Métriques
Les métriques Cloud Monitoring suivantes sont disponibles sur la ressource aiplatform.googleapis.com/PublisherModel pour les modèles Gemini. Utilisez les types de requêtes dedicated pour filtrer l'utilisation du débit provisionné.
| Métrique | Nom à afficher | Description |
|---|---|---|
/dedicated_gsu_limit |
Limite (GSU) | Limite dédiée dans les GSU. Utilisez cette métrique pour comprendre votre quota maximal de débit provisionné dans les GSU. |
/tokens |
Jetons | Distribution du nombre de jetons d'entrée et de sortie. |
/token_count |
Nombre de jetons | Nombre cumulé de jetons d'entrée et de sortie. |
/consumed_token_throughput |
Débit en jetons | Débit consommé, qui tient compte du taux d'utilisation des jetons et intègre le rapprochement des quotas. Consultez la section Vérification du quota de débit provisionné. Utilisez cette métrique pour comprendre comment votre quota de débit provisionné a été utilisé. |
/dedicated_token_limit |
Limite (jetons par seconde) | Limite dédiée en jetons par seconde. Utilisez cette métrique pour comprendre votre quota maximal de débit provisionné pour les modèles basés sur des jetons. |
/characters |
Caractères | Distribution du nombre de caractères d'entrée et de sortie. |
/character_count |
Nombre de caractères | Nombre cumulé de caractères d'entrée et de sortie. |
/consumed_throughput |
Débit en caractères | Débit consommé, qui tient compte du taux d'utilisation des caractères et intègre le rapprochement des quotas. Consultez la section Vérification du quota de débit provisionné. Cette métrique vous permet de comprendre comment votre quota de débit provisionné a été utilisé. Pour les modèles basés sur des jetons, cette métrique équivaut au débit consommé en jetons multiplié par quatre. |
/dedicated_character_limit |
Limite (caractères par seconde) | Limite dédiée en caractères par seconde. Utilisez cette métrique pour comprendre votre quota maximal de débit provisionné pour les modèles basés sur des caractères. |
/model_invocation_count |
Nombre d'appels du modèle | Nombre d'appels du modèle (requêtes de prédiction). |
/model_invocation_latencies |
Latences d'appel du modèle | Latences d'appel du modèle (latences de prédiction). |
/first_token_latencies |
Latences du premier jeton | Durée entre la réception de la requête et le premier jeton renvoyé. |
Les modèles Anthropic disposent également d'un filtre pour le débit provisionné, mais uniquement pour tokens et token_count.
Tableaux de bord
Les tableaux de bord de surveillance par défaut pour le débit provisionné fournissent des métriques qui vous permettent de mieux comprendre votre utilisation et l'utilisation du débit provisionné. Pour accéder aux tableaux de bord :
Dans la console Google Cloud , accédez à la page Débit provisionné.
Pour afficher l'utilisation du débit provisionné de chaque modèle dans vos commandes, sélectionnez l'onglet Résumé de l'utilisation.
Dans le tableau Utilisation du débit provisionné par modèle, vous pouvez afficher les éléments suivants pour la période sélectionnée :
Nombre total de GSU dont vous disposiez.
Pic d'utilisation du débit en termes de GSU.
Utilisation moyenne des GSU.
Nombre de fois où vous avez atteint votre limite de débit provisionné.
Sélectionnez un modèle dans le tableau Utilisation du débit provisionné par modèle pour afficher d'autres métriques spécifiques au modèle sélectionné.
Interpréter les tableaux de bord de surveillance
Le débit provisionné vérifie le quota disponible en temps réel au niveau de la milliseconde pour les requêtes au fur et à mesure de leur envoi, mais compare ces données à une période d'application du quota glissante, basée sur l'heure de l'horloge interne de Vertex AI. Cette comparaison est indépendante du moment où les requêtes sont envoyées. Les tableaux de bord de surveillance indiquent les métriques d'utilisation une fois le quota rapproché. Toutefois, ces métriques sont agrégées pour fournir des moyennes pour les périodes d'alignement du tableau de bord, en fonction de la période sélectionnée. La précision la plus faible acceptée par les tableaux de bord de surveillance est d'une minute. De plus, le temps écoulé pour les tableaux de bord de surveillance est différent de celui de Vertex AI.
Ces différences de timing peuvent parfois entraîner des écarts entre les données des tableaux de bord de surveillance et les performances en temps réel. Cela peut être dû à l'une des raisons suivantes :
Les quotas sont appliqués en temps réel, mais les graphiques de surveillance agrègent les données dans des périodes d'alignement de tableau de bord d'une minute ou plus, en fonction de la période spécifiée dans les tableaux de bord de surveillance.
Vertex AI et les tableaux de bord de surveillance s'exécutent sur des horloges système différentes.
Si un pic de trafic sur une période d'une seconde dépasse votre quota de débit provisionné, l'intégralité de la requête est traitée comme du trafic excédentaire. Toutefois, l'utilisation globale du débit provisionné peut sembler faible lorsque les données de surveillance pour cette seconde sont moyennées au cours de la période d'alignement d'une minute, car l'utilisation moyenne sur l'ensemble de la période d'alignement peut ne pas dépasser 100 %. Si vous constatez un trafic excédentaire, cela confirme que votre quota de débit provisionné a été entièrement utilisé pendant la période d'application du quota, lorsque ces requêtes spécifiques ont été effectuées. Cela, quelle que soit l'utilisation moyenne affichée dans les tableaux de bord de surveillance.
Exemple d'écart potentiel dans les données de surveillance
Cet exemple illustre certains des écarts résultant d'un décalage des fenêtres. La figure 1 représente l'utilisation du débit sur une période spécifique. Dans cette figure :
Les barres bleues représentent le trafic autorisé en tant que débit provisionné.
La barre orange représente le trafic qui dépasse la limite GSU et qui est traité comme un dépassement.
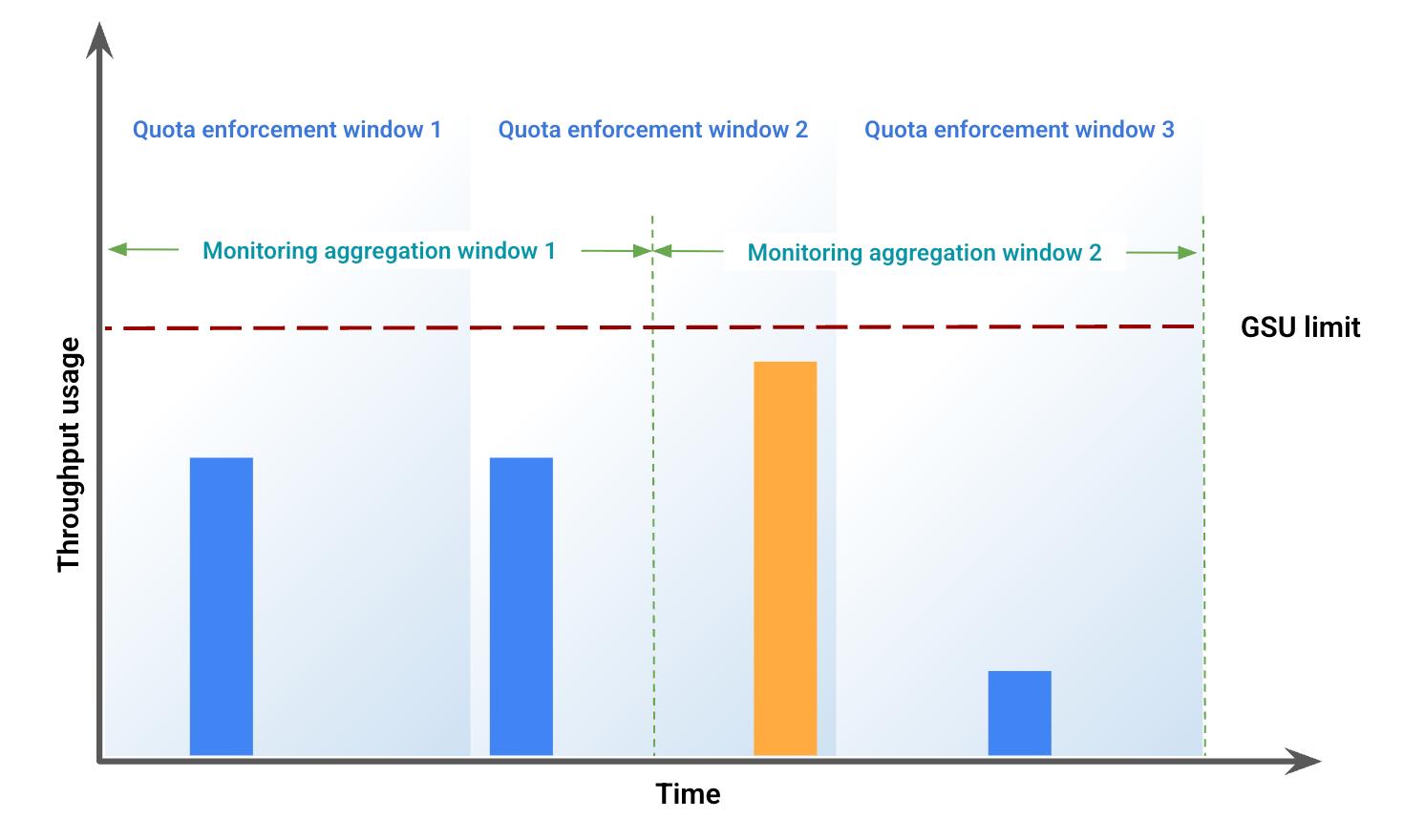
Sur la base de l'utilisation du débit, la figure 2 représente les éventuelles différences visuelles dues à un décalage des fenêtres. Dans cette figure :
La ligne bleue représente le trafic de débit provisionné.
La ligne orange représente le trafic de débordement.
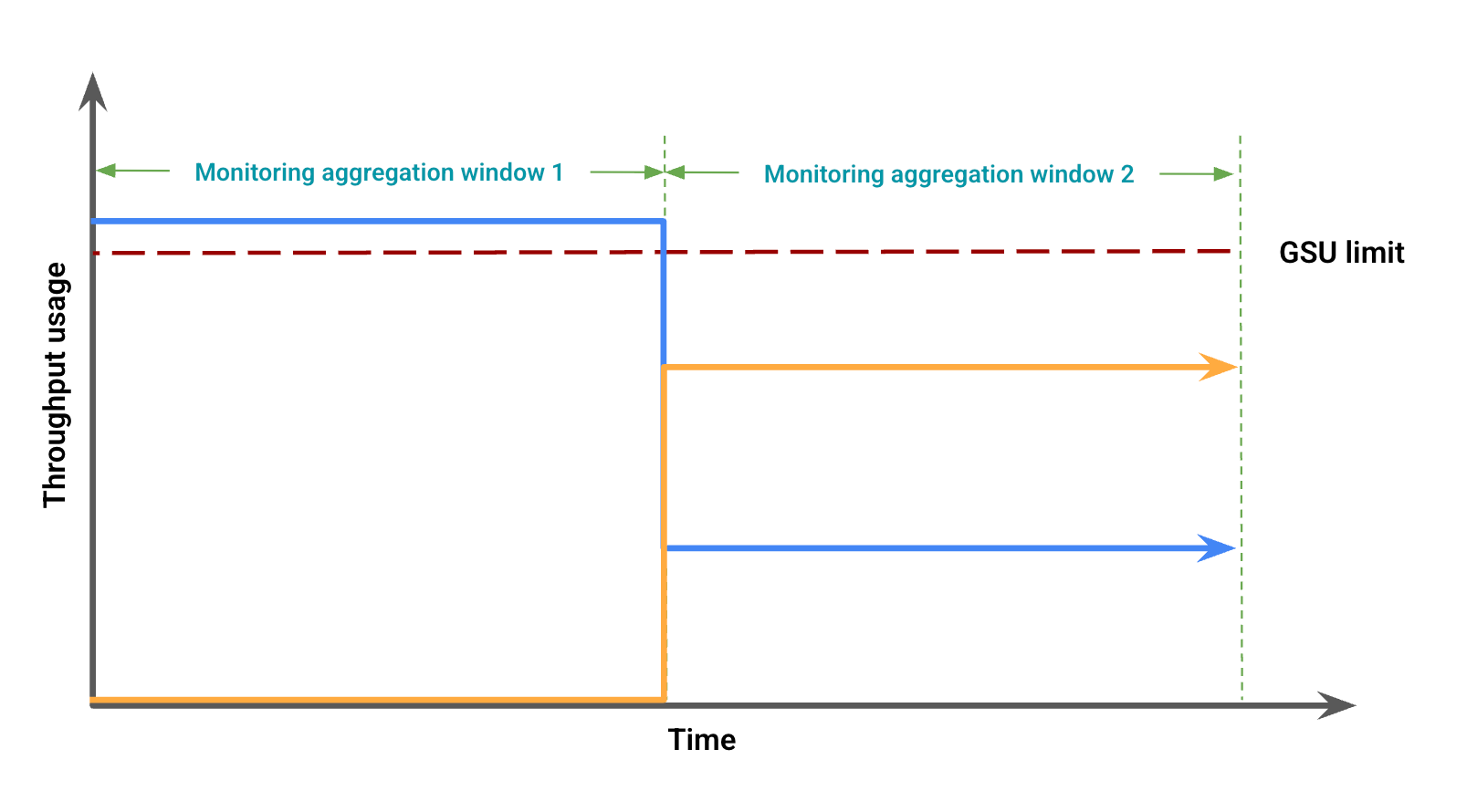
Dans ce cas, les données de surveillance peuvent indiquer une utilisation du débit provisionné sans débordement pour une période d'agrégation de surveillance, tout en observant simultanément une utilisation du débit provisionné inférieure à la limite de l'UGS coïncidant avec un débordement dans une autre période d'agrégation de surveillance.
Résoudre les problèmes liés aux tableaux de bord de surveillance
Pour résoudre les problèmes de débordement inattendu dans vos tableaux de bord ou les erreurs 429, procédez comme suit :
Faire un zoom avant : définissez la période de votre tableau de bord sur 12 heures ou moins pour obtenir la période d'alignement la plus précise (1 minute). Les grandes plages de temps lissent les pics qui entraînent une limitation et augmentent les moyennes des périodes d'alignement.
Vérifiez le trafic total : vos tableaux de bord spécifiques aux modèles affichent le trafic dédié et le trafic excédentaire sur deux lignes distinctes, ce qui peut vous amener à conclure à tort que le quota de débit provisionné n'est pas entièrement utilisé et qu'il est excédentaire prématurément. Si votre trafic dépasse le quota disponible, l'intégralité de la demande est traitée comme un dépassement. Pour obtenir une autre visualisation utile, ajoutez une requête au tableau de bord à l'aide de l'explorateur de métriques et incluez le débit de jetons pour le modèle et la région spécifiques. N'incluez aucune agrégation ni aucun filtre supplémentaires pour afficher le trafic total pour tous les types de trafic (dédié, débordement et partagé).
Surveiller les modèles Genmedia
La surveillance du débit provisionné n'est pas disponible sur les modèles Veo 3 et Imagen.
Alertes
Une fois l'alerte activée, définissez des alertes par défaut pour vous aider à gérer votre utilisation du trafic.
Activer les alertes
Pour activer les alertes dans le tableau de bord, procédez comme suit :
Dans la console Google Cloud , accédez à la page Débit provisionné.
Pour afficher l'utilisation du débit provisionné de chaque modèle dans vos commandes, sélectionnez l'onglet Résumé de l'utilisation.
Sélectionnez Alertes recommandées. Les alertes suivantes s'affichent :
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Vérifiez les alertes qui vous aident à gérer votre trafic.
Afficher plus de détails sur l'alerte
Pour afficher plus d'informations sur les alertes, procédez comme suit :
Accédez à la page Intégrations.
Saisissez vertex dans le champ Filtrer, puis appuyez sur Entrée. Google Vertex AI s'affiche.
Pour afficher plus d'informations, cliquez sur Afficher les détails. Le volet Détails Google Vertex AI s'affiche.
Sélectionnez l'onglet Alertes et choisissez un modèle de règle d'alerte.
Étape suivante
- Résoudre le code d'erreur
429.