
Auf dieser Seite wird erläutert, wie Provisioned Throughput funktioniert, wie Sie Überschreitungen steuern oder Provisioned Throughput umgehen und wie Sie die Nutzung überwachen.
Funktionsweise von Provisioned Throughput
In diesem Abschnitt wird erläutert, wie Provisioned Throughput funktioniert. Dazu wird die Kontingentprüfung während des Kontingentdurchsetzungszeitraums beschrieben.
Kontingentprüfung für bereitgestellten Durchsatz
Ihr maximales Kontingent für Provisioned Throughput ist ein Vielfaches der Anzahl der gekauften Skalierungseinheiten der generativen KI (GSUs) und des Durchsatzes pro GSU. Sie wird jedes Mal geprüft, wenn Sie eine Anfrage innerhalb Ihres Zeitraums für die Kontingentdurchsetzung stellen. Das ist die Häufigkeit, mit der das maximale Kontingent für den bereitgestellten Durchsatz durchgesetzt wird.
Wenn eine Anfrage eingeht, ist die tatsächliche Antwortgröße unbekannt. Da wir die Reaktionsgeschwindigkeit für Echtzeitanwendungen priorisieren, wird die Ausgabetoken-Größe durch den bereitgestellten Durchsatz geschätzt. Wenn die erste Schätzung das verfügbare maximale Kontingent für Provisioned Throughput überschreitet, wird die Anfrage als „Pay-as-you-go“ verarbeitet. Andernfalls wird sie als Provisioned Throughput verarbeitet. Dazu wird die erste Schätzung mit Ihrem maximalen Kontingent für den bereitgestellten Durchsatz verglichen.
Wenn die Antwort generiert wird und die tatsächliche Größe des Ausgabetokens bekannt ist, werden die tatsächliche Nutzung und das Kontingent abgeglichen, indem die Differenz zwischen der Schätzung und der tatsächlichen Nutzung zu Ihrem verfügbaren Kontingent für den bereitgestellten Durchsatz hinzugefügt wird.
Zeitraum für die Durchsetzung des Kontingents für den bereitgestellten Durchsatz
Bei Gemini-Modellen kann es bis zu 30 Sekunden dauern, bis das Kontingent durchgesetzt wird. Dieser Zeitraum kann sich ändern. Das bedeutet, dass Sie in einigen Fällen vorübergehend priorisierten Traffic haben, der Ihr Kontingent pro Sekunde überschreitet. Ihr Kontingent sollte jedoch nicht auf 30-Sekunden-Basis überschritten werden. Diese Zeiträume basieren auf der internen Uhrzeit von Vertex AI und sind unabhängig davon, wann Anfragen gestellt werden.
Wenn Sie beispielsweise eine GSU von gemini-2.0-flash-001 kaufen, können Sie mit einem Always-on-Durchsatz von 3.360 Tokens pro Sekunde rechnen. Im Durchschnitt dürfen Sie 100.800 Tokens pro 30 Sekunden nicht überschreiten. Das wird mit der folgenden Formel berechnet:
3,360 tokens per second * 30 seconds = 100,800 tokens
Wenn Sie an einem Tag nur eine Anfrage gesendet haben, für die 8.000 Tokens in einer Sekunde verbraucht wurden, wird sie möglicherweise trotzdem als Anfrage mit bereitgestelltem Durchsatz verarbeitet, obwohl Sie zum Zeitpunkt der Anfrage Ihr Limit von 3.360 Tokens pro Sekunde überschritten haben. Das liegt daran,dass die Anfrage den Grenzwert von 100.800 Tokens pro 30 Sekunden nicht überschritten hat.
Überschreitungen steuern oder Provisioned Throughput umgehen
Mit der API können Sie Überschreitungen steuern, wenn Sie den gekauften Durchsatz überschreiten, oder Provisioned Throughput pro Anfrage umgehen.
Lesen Sie sich die einzelnen Optionen durch, um herauszufinden, was Sie tun müssen, um Ihren Anwendungsfall zu erfüllen.
Standardverhalten
Wenn eine Anfrage das verbleibende Kontingent für Provisioned Throughput überschreitet, wird die gesamte Anfrage standardmäßig als On-Demand-Anfrage verarbeitet und zum Pay-as-you-go-Tarif abgerechnet. In diesem Fall wird der Traffic in den Monitoring-Dashboards als Spillover angezeigt. Weitere Informationen zum Monitoring der Nutzung von Provisioned Throughput finden Sie unter Provisioned Throughput überwachen.
Sobald Ihre Bestellung für Provisioned Throughput aktiv ist, wird das Standardverhalten automatisch angewendet. Sie müssen Ihren Code nicht ändern, um Ihre Bestellung zu nutzen, solange Sie sie in der bereitgestellten Region nutzen.
Nur Provisioned Throughput verwenden
Wenn Sie Kosten verwalten, indem Sie On-Demand-Gebühren vermeiden, verwenden Sie nur Provisioned Throughput. Bei Anfragen, die den Bestellbetrag für Provisioned Throughput überschreiten, wird der Fehler 429 zurückgegeben.
Wenn Sie Anfragen an die API senden, legen Sie den HTTP-Header X-Vertex-AI-LLM-Request-Type auf dedicated fest.
Nur „Pay as you go“ verwenden
Dies wird auch als „On-Demand-Nutzung“ bezeichnet. Anfragen umgehen die Bestellung von Provisioned Throughput und werden direkt an Pay-as-you-go gesendet. Das kann für Tests oder Anwendungen in der Entwicklungsphase nützlich sein.
Wenn Sie Anfragen an die API senden, legen Sie den HTTP-Header X-Vertex-AI-LLM-Request-Type auf shared fest.
Beispiel
Python
Installieren
pip install --upgrade google-genai
Weitere Informationen finden Sie in der SDK-Referenzdokumentation.
Umgebungsvariablen für die Verwendung des Gen AI SDK mit Vertex AI festlegen:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Informationen zum Installieren oder Aktualisieren von Go
Weitere Informationen finden Sie in der SDK-Referenzdokumentation.
Umgebungsvariablen für die Verwendung des Gen AI SDK mit Vertex AI festlegen:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Nachdem Sie Ihre Umgebung eingerichtet haben, können Sie mit REST einen Text-Prompt testen. Im folgenden Beispiel wird eine Anfrage an den Publisher gesendet Modellendpunkt zu erstellen.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Provisioned Throughput mit einem API-Schlüssel verwenden
Wenn Sie Provisioned Throughput für ein bestimmtes Projekt, ein bestimmtes Google-Modell und eine bestimmte Region erworben haben und es verwenden möchten, um eine Anfrage mit einem API-Schlüssel zu senden, müssen Sie die Projekt-ID, das Modell, den Standort und den API-Schlüssel als Parameter in Ihre Anfrage aufnehmen.
Informationen zum Erstellen eines Google Cloud API-Schlüssels, der an ein Dienstkonto gebunden ist, finden Sie unter Google Cloud API-Schlüssel abrufen. Informationen zum Senden von Anfragen an die Gemini API mit einem API-Schlüssel finden Sie in der Kurzanleitung zur Gemini API in Vertex AI.
Im folgenden Beispiel wird gezeigt, wie Sie eine Anfrage mit einem API-Schlüssel senden, wenn Sie Provisioned Throughput verwenden:
REST
Nachdem Sie Ihre Umgebung eingerichtet haben, können Sie mit REST einen Text-Prompt testen. Im folgenden Beispiel wird eine Anfrage an den Publisher gesendet Modellendpunkt zu erstellen.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Provisioned Throughput überwachen
Sie können die Nutzung von Provisioned Throughput selbst überwachen. Dazu verwenden Sie eine Reihe von Messwerten, die für den Ressourcentyp aiplatform.googleapis.com/PublisherModel erfasst werden.
Die Traffic-Überwachung für Provisioned Throughput ist eine Funktion in der öffentlichen Vorschau.
Dimensionen
Sie können Messwerte mit den folgenden Dimensionen filtern:
| Dimension | Werte |
|---|---|
type |
inputoutput |
request_type |
|
Pfadpräfix
Das Pfadpräfix für einen Messwert ist aiplatform.googleapis.com/publisher/online_serving.
Der vollständige Pfad für den Messwert /consumed_throughput ist beispielsweise aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Messwerte
Die folgenden Cloud Monitoring-Messwerte sind für die Ressource aiplatform.googleapis.com/PublisherModel für die Gemini-Modelle verfügbar. Verwenden Sie die Anfragetypen dedicated, um nach der Nutzung von Provisioned Throughput zu filtern.
| Messwert | Anzeigename | Beschreibung |
|---|---|---|
/dedicated_gsu_limit |
Limit (GSU) | Dediziertes Limit in GSUs. Mit diesem Messwert können Sie das maximale Kontingent für Provisioned Throughput in GSUs ermitteln. |
/tokens |
Tokens | Verteilung der Anzahl der Eingabe- und Ausgabetokens. |
/token_count |
Tokenanzahl | Anzahl der kumulierten Eingabe- und Ausgabetokens. |
/consumed_token_throughput |
Token-Durchsatz | Durchsatznutzung, die die Abnahmerate in Tokens berücksichtigt und den Kontingentabgleich einbezieht. Weitere Informationen finden Sie unter Kontingentprüfung für Provisioned Throughput. Mit diesem Messwert können Sie nachvollziehen, wie Ihr Kontingent für Provisioned Throughput genutzt wurde. |
/dedicated_token_limit |
Limit (Tokens pro Sekunde) | Dediziertes Limit in Tokens pro Sekunde. Mit diesem Messwert können Sie das maximale Kontingent für bereitgestellten Durchsatz für tokenbasierte Modelle ermitteln. |
/characters |
Zeichen | Verteilung der Anzahl der Eingabe- und Ausgabezeichen. |
/character_count |
Anzahl der Zeichen | Anzahl der insgesamt eingegebenen und ausgegebenen Zeichen. |
/consumed_throughput |
Zeichendurchsatz | Die Nutzung des Durchsatzes, die die Abnahmerate in Zeichen berücksichtigt und die Kontingentabstimmung Kontingentprüfung für Provisioned Throughput umfasst. Mit diesem Messwert können Sie nachvollziehen, wie Ihr Kontingent für Provisioned Throughput genutzt wurde. Bei tokenbasierten Modellen entspricht dieser Messwert dem in Tokens verbrauchten Durchsatz multipliziert mit 4. |
/dedicated_character_limit |
Limit (Zeichen pro Sekunde) | Ein dediziertes Limit in Zeichen pro Sekunde. Mit diesem Messwert können Sie das maximale Kontingent für bereitgestellten Durchsatz für zeichenbasierte Modelle ermitteln. |
/model_invocation_count |
Anzahl der Modellaufrufe | Anzahl der Modellaufrufe (Vorhersageanfragen). |
/model_invocation_latencies |
Latenzen beim Modellaufruf | Latenz beim Modellaufruf (Vorhersagelatenz). |
/first_token_latencies |
Latenzen für das erste Token | Dauer vom Empfang der Anfrage bis zur Rückgabe des ersten Tokens. |
Anthropic-Modelle haben auch einen Filter für den bereitgestellten Durchsatz, aber nur für tokens und token_count.
Dashboards
Standard-Monitoring-Dashboards für Provisioned Throughput bieten Messwerte, mit denen Sie Ihre Nutzung und die Nutzung von Provisioned Throughput besser nachvollziehen können. So greifen Sie auf die Dashboards zu:
Rufen Sie in der Google Cloud Console die Seite Bereitgestellter Durchsatz auf.
Wenn Sie die Auslastung des bereitgestellten Durchsatzes jedes Modells in Ihren Bestellungen aufrufen möchten, wählen Sie den Tab Zusammenfassung der Auslastung aus.
In der Tabelle Auslastung des bereitgestellten Durchsatzes nach Modell sehen Sie für den ausgewählten Zeitraum Folgendes:
Gesamtzahl der GSUs, die Sie hatten.
Spitzendurchsatznutzung in GSUs.
Die durchschnittliche GSU-Nutzung.
Die Anzahl der Fälle, in denen Sie das Limit für den bereitgestellten Durchsatz erreicht haben.
Wählen Sie in der Tabelle Provisioned Throughput utilization by model (Auslastung des bereitgestellten Durchsatzes nach Modell) ein Modell aus, um weitere messwertspezifische Informationen zum ausgewählten Modell zu sehen.
Monitoring-Dashboards interpretieren
Der bereitgestellte Durchsatz prüft das verfügbare Kontingent in Echtzeit auf Millisekundenebene für Anfragen, die gestellt werden. Die Daten werden jedoch mit einem gleitenden 30-Sekunden-Zeitraum für die Kontingenterzwingung verglichen, der auf der internen Uhrzeit von Vertex AI basiert. Dieser Vergleich ist unabhängig davon, wann die Anfragen gestellt werden. In den Monitoring-Dashboards werden Nutzungsmesswerte nach dem Abgleich des Kontingents angezeigt. Diese Messwerte werden jedoch zusammengefasst, um auf Grundlage des ausgewählten Zeitraums Durchschnittswerte für die Dashboard-Abstimmungszeiträume zu erhalten. Die geringste mögliche Granularität, die von den Monitoring-Dashboards unterstützt wird, ist die Minutenebene. Außerdem unterscheidet sich die Uhrzeit für die Monitoring-Dashboards von der in Vertex AI.
Diese Zeitunterschiede können gelegentlich zu Abweichungen zwischen den Daten in den Monitoring-Dashboards und der Echtzeitleistung führen. Das kann folgende Gründe haben:
Das Kontingent wird in Echtzeit durchgesetzt, aber in den Monitoring-Diagrammen werden Daten in durchschnittlichen Dashboard-Abstimmungszeiträumen von einer Minute oder mehr zusammengefasst, je nach dem im Monitoring-Dashboard angegebenen Zeitraum.
Vertex AI und die Monitoring-Dashboards verwenden unterschiedliche Systemuhren.
Wenn ein Traffic-Burst über einen Zeitraum von einer Sekunde Ihr Kontingent für Provisioned Throughput überschreitet, wird die gesamte Anfrage als Spillover-Traffic verarbeitet. Die Gesamtauslastung des bereitgestellten Durchsatzes kann jedoch gering erscheinen, wenn die Überwachungsdaten für diese Sekunde im 1-minütigen Abgleichszeitraum gemittelt werden, da die durchschnittliche Auslastung über den gesamten Abgleichszeitraum möglicherweise nicht 100 % überschreitet. Wenn Sie Spillover-Traffic sehen, bedeutet das, dass Ihr Kontingent für bereitgestellten Durchsatz während des Zeitraums, in dem das Kontingent durchgesetzt wurde, vollständig genutzt wurde, als diese spezifischen Anfragen gestellt wurden. Dies gilt unabhängig von der durchschnittlichen Auslastung, die in den Monitoring-Dashboards angezeigt wird.
Beispiel für eine potenzielle Diskrepanz bei Monitoringdaten
In diesem Beispiel werden einige der Abweichungen veranschaulicht, die durch eine falsche Ausrichtung des Zeitraums entstehen. Abbildung 1 zeigt die Durchsatznutzung über einen bestimmten Zeitraum. In dieser Abbildung:
Die blauen Balken stellen den Traffic dar, der als bereitgestellter Durchsatz zugelassen wurde.
Der orangefarbene Balken steht für Traffic, der die Nutzung über das GSU-Limit hinaus treibt und als Spillover verarbeitet wird.
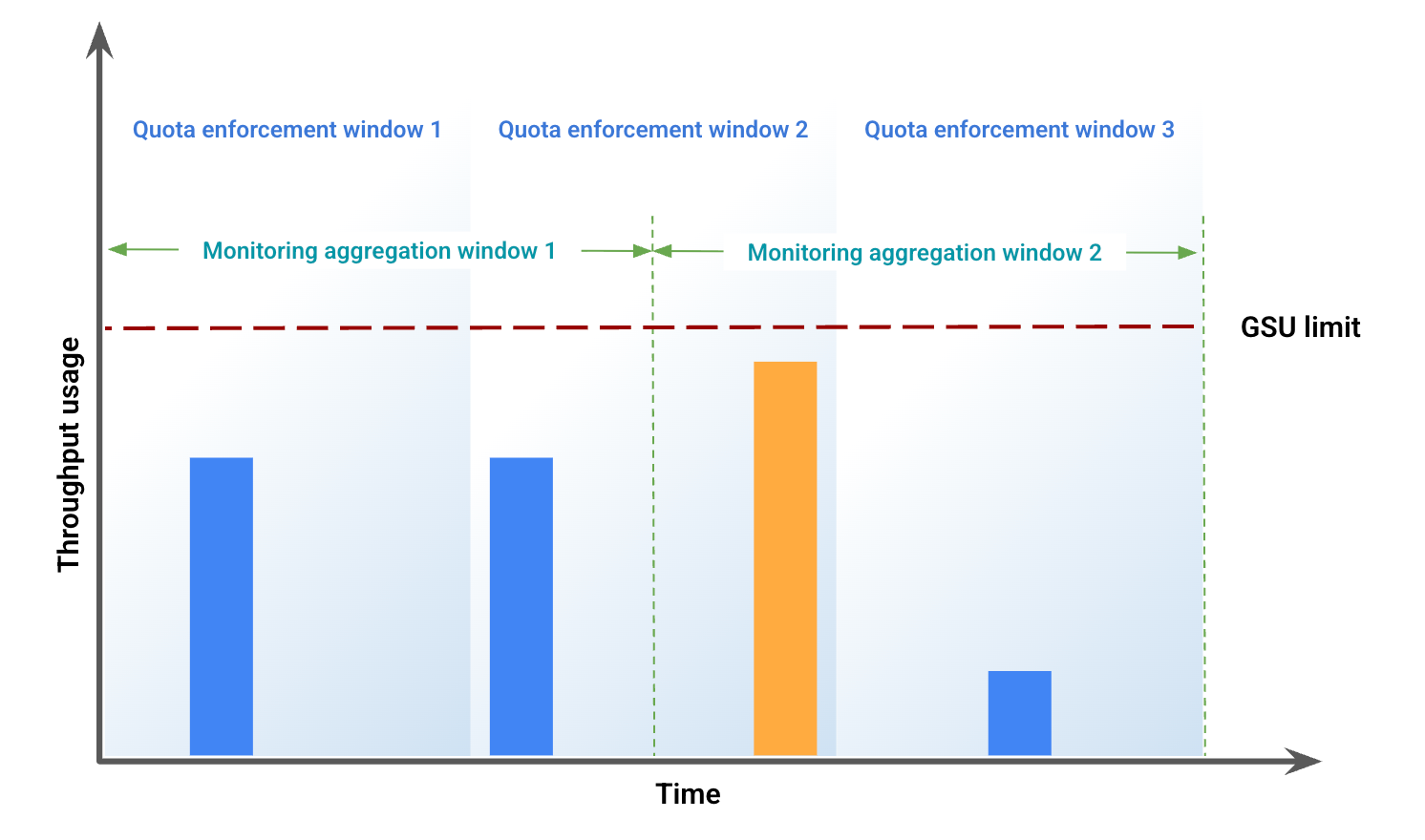
Abbildung 2 zeigt mögliche visuelle Abweichungen aufgrund von Fensterungsfehlern, die auf der Durchsatznutzung basieren. In dieser Abbildung:
Die blaue Linie steht für Traffic mit bereitgestelltem Durchsatz.
Die orangefarbene Linie steht für Spillover-Traffic.
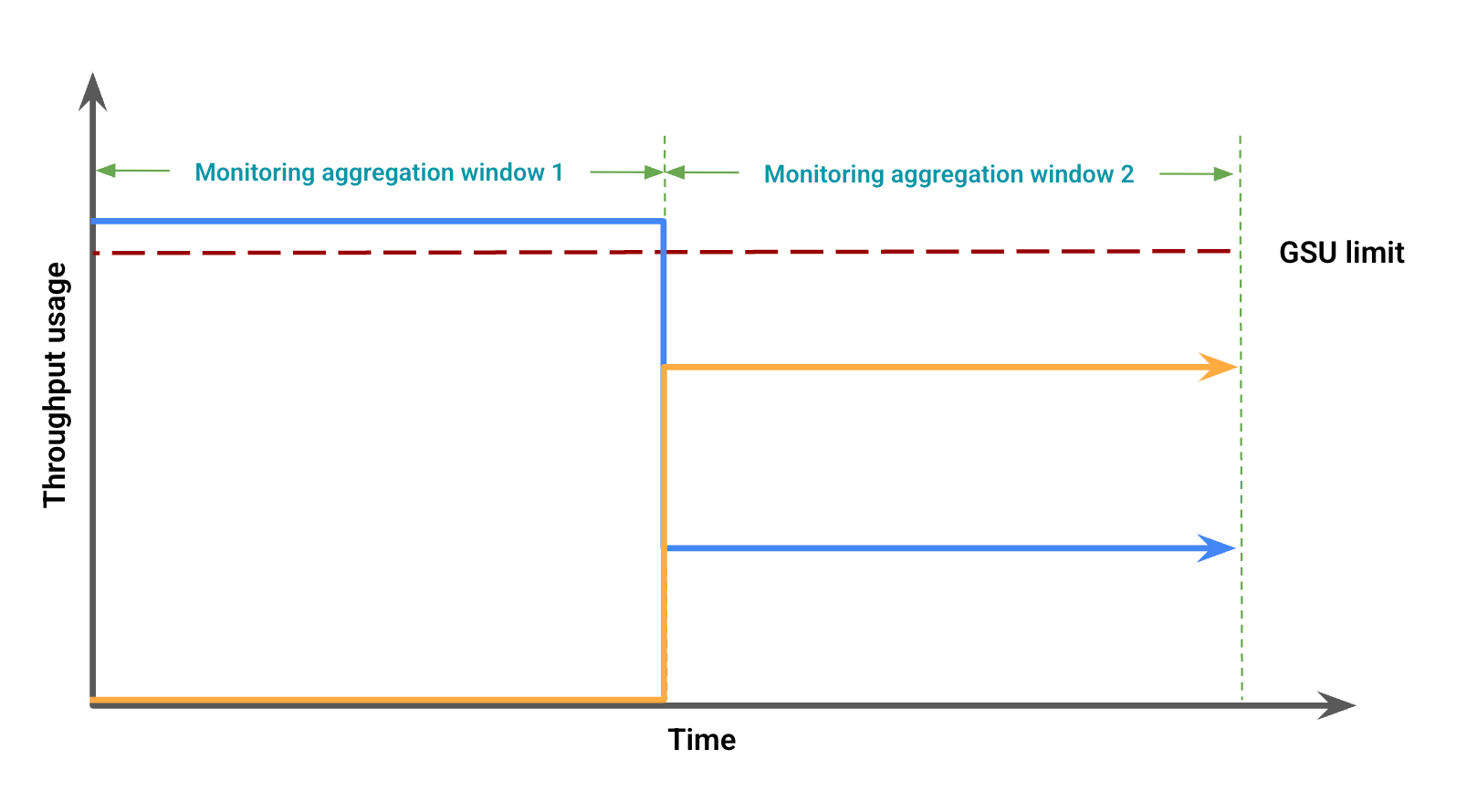
In diesem Fall werden in den Monitoring-Daten möglicherweise Provisioned Throughput-Nutzung ohne Überschreitung für einen Monitoring-Aggregationszeitraum angezeigt, während gleichzeitig die Provisioned Throughput-Nutzung unter dem GSU-Limit mit einer Überschreitung in einem anderen Monitoring-Aggregationszeitraum beobachtet wird.
Fehlerbehebung bei Monitoring-Dashboards
Wenn in Ihren Dashboards unerwartete Überschneidungen oder 429-Fehler auftreten, können Sie die folgenden Schritte ausführen, um das Problem zu beheben:
Heranzoomen: Legen Sie für Ihr Dashboard einen Zeitraum von maximal 12 Stunden fest, um den kleinsten Ausrichtungszeitraum von 1 Minute zu erhalten. Bei großen Zeiträumen werden Spitzenwerte, die zu einer Drosselung führen, ausgeglichen und die Durchschnittswerte für den Abstimmungszeitraum steigen.
Gesamten Traffic prüfen: In den modellbezogenen Dashboards werden dedizierter und Spillover-Traffic als zwei separate Linien dargestellt. Das kann zu dem falschen Schluss führen, dass das Kontingent für den bereitgestellten Durchsatz nicht vollständig genutzt wird und vorzeitig Spillover-Traffic auftritt. Wenn Ihr Traffic das verfügbare Kontingent überschreitet, wird die gesamte Anfrage als Spillover verarbeitet. Eine weitere hilfreiche Visualisierung erhalten Sie, wenn Sie dem Dashboard mit dem Metrics Explorer eine Abfrage hinzufügen und den Token-Durchsatz für das jeweilige Modell und die jeweilige Region einbeziehen. Fügen Sie keine zusätzlichen Aggregationen oder Filter hinzu, um den gesamten Traffic für alle Traffic-Typen (dediziert, Spillover und gemeinsam) zu sehen.
Genmedia-Modelle überwachen
Die Überwachung des bereitgestellten Durchsatzes ist für Veo 3- und Imagen-Modelle nicht verfügbar.
Benachrichtigungen
Nachdem Sie Benachrichtigungen aktiviert haben, können Sie Standardbenachrichtigungen einrichten, um die Nutzung Ihres Traffics besser zu verwalten.
Benachrichtigungen aktivieren
So aktivieren Sie Benachrichtigungen im Dashboard:
Rufen Sie in der Google Cloud Console die Seite Bereitgestellter Durchsatz auf.
Wenn Sie die Auslastung des bereitgestellten Durchsatzes jedes Modells in Ihren Bestellungen aufrufen möchten, wählen Sie den Tab Zusammenfassung der Auslastung aus.
Wählen Sie Empfohlene Benachrichtigungen aus. Die folgenden Benachrichtigungen werden angezeigt:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Sehen Sie sich die Benachrichtigungen an, die Ihnen helfen, Ihren Traffic zu verwalten.
Weitere Details zu Benachrichtigungen ansehen
So rufen Sie weitere Informationen zu Benachrichtigungen auf:
Rufen Sie die Seite Integrationen auf.
Geben Sie im Feld Filter vertex ein und drücken Sie die Eingabetaste. Google Vertex AI wird angezeigt.
Wenn Sie weitere Informationen aufrufen möchten, klicken Sie auf Details ansehen. Der Bereich Google Vertex AI-Details wird angezeigt.
Wählen Sie den Tab Benachrichtigungen aus. Dort können Sie eine Vorlage für eine Benachrichtigungsrichtlinie auswählen.